您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要介绍“Python怎么爬取腾讯视频弹幕”,在日常操作中,相信很多人在Python怎么爬取腾讯视频弹幕问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”Python怎么爬取腾讯视频弹幕”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
Python 3.6
Pycharm
jieba
wordcloud
安装Python并添加到环境变量,pip安装需要的相关模块即可。
选择 <欢乐喜剧人 第七季> 爬取网友发送的弹幕信息
复制网页中的弹幕,再开发者工具里面进行搜索。
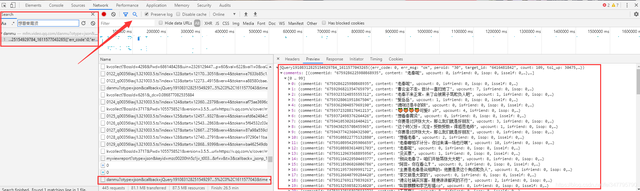
这里面就有对应的弹幕数据。这个url地址有一个小特点,链接包含着 danmu 所以大胆尝试一下,过滤搜索一下 danmu 这个关键词,看一下是否有像类似的内容

循环遍历就可以实现爬取整个视频的弹幕了。
在这里想问一下,你觉得请求这个url地址给你返回的数据是什么样的数据?给大家三秒考虑时间。
1 …2…3…
好的,现在公布答案了,它是一个 字符串 你没有听错。如果你直接获取 respons.json() 那你会出现报错
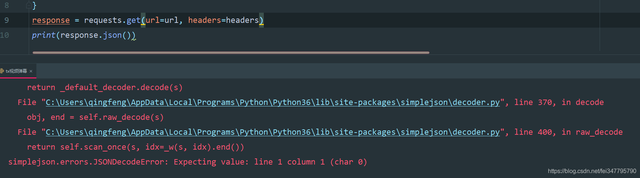
那如何才能让它编程json数据呢,毕竟json数据更好提取数据。
第一种方法
正则匹配提取中间的数据部分的数据
导入json模块,字符串转json数据
import requests
import re
import json
import pprint
url = 'https://mfm.video.qq.com/danmu?otype=json&callback=jQuery19108312825154929784_1611577043265&target_id=6416481842%26vid%3Dt0035rsjty9&session_key=30475%2C0%2C1611577043×tamp=105&_=1611577043296'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
result = re.findall('jQuery19108312825154929784_1611577043265\((.*?)\)', response.text)[0]
json_data = json.loads(result)
pprint.pprint(json_data)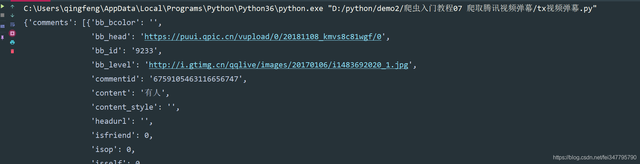
第二种方法
删除链接中的 callback=jQuery19108312825154929784_1611577043265 就可以直接使用 response.json()
import requests
import pprint
url = 'https://mfm.video.qq.com/danmu?otype=json&target_id=6416481842%26vid%3Dt0035rsjty9&session_key=30475%2C0%2C1611577043×tamp=105&_=1611577043296'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
# result = re.findall('jQuery19108312825154929784_1611577043265\((.*?)\)', response.text)[0]
json_data = response.json()
pprint.pprint(json_data)这样也可以,而且可以让代码更加简单。
小知识点:
pprint 是格式化输出模块,让类似json数据输出的效果更加好看
import requests
for page in range(15, 150, 15):
url = 'https://mfm.video.qq.com/danmu'
params = {
'otype': 'json',
'target_id': '6416481842&vid=t0035rsjty9',
'session_key': '30475,0,1611577043',
'timestamp': page,
'_': '1611577043296',
}
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=url, params=params, headers=headers)
json_data = response.json()
contents = json_data['comments']
for i in contents:
content = i['content']
with open('喜剧人弹幕.txt', mode='a', encoding='utf-8') as f:
f.write(content)
f.write('\n')
print(content)到此,关于“Python怎么爬取腾讯视频弹幕”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。