您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
# 如何进行TensorFlow概览分析
## 引言
TensorFlow作为当前最流行的开源机器学习框架之一,由Google Brain团队开发并维护。自2015年发布以来,它已成为深度学习研究和工业应用的首选工具之一。本文将从多个维度对TensorFlow进行系统性概览分析,包括其架构设计、核心组件、生态系统以及实际应用场景,帮助读者全面理解这一框架的技术特点和使用方法。
## 一、TensorFlow核心架构解析
### 1.1 分层式设计理念
TensorFlow采用典型的分层架构设计,从上至下可分为:
1. **应用层**:提供高级API(如Keras)和预构建模型
2. **计算图层**:定义和执行数据流图的核心抽象
3. **运行时层**:包含分布式执行引擎和设备管理层
4. **网络层**:处理跨设备通信(gRPC/RDMA)
5. **设备层**:支持CPU/GPU/TPU等硬件加速器
```python
import tensorflow as tf
# 典型的分层调用示例
model = tf.keras.Sequential([
tf.keras.layers.Dense(10, activation='relu'),
tf.keras.layers.Dense(1)
]) # 应用层
model.compile(optimizer='adam') # 计算图构建
model.fit(data, labels) # 运行时执行
TensorFlow的核心创新在于其基于数据流图(Data Flow Graph)的计算模型:
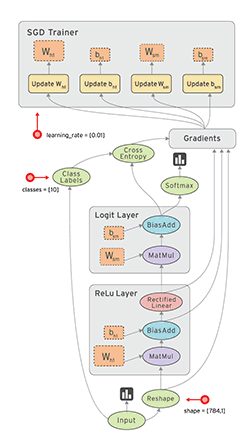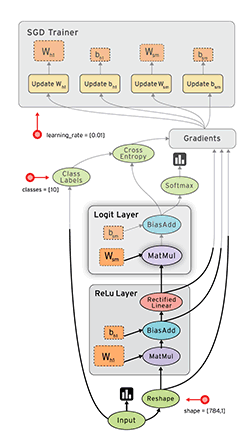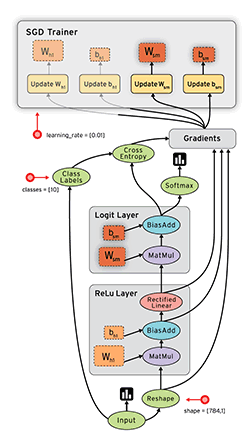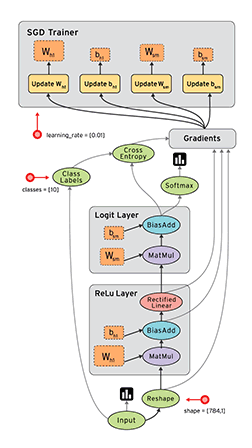
TensorFlow中的基本数据单位具有以下特性:
| 属性 | 说明 | 示例 |
|---|---|---|
| Rank | 张量维度 | 0:标量, 1:向量 |
| Shape | 每个维度的元素数量 | (2,3)表示2行3列矩阵 |
| DType | 数据类型 | tf.float32, tf.int64 |
# 张量操作示例
tensor = tf.constant([[1., 2.], [3., 4.]])
print(tensor.shape) # 输出 (2, 2)
模型参数通过Variable类实现持久化存储:
weights = tf.Variable(tf.random.normal([784, 10]))
weights.assign_add(tf.ones_like(weights)) # 变量更新
通过GradientTape实现自动微分:
with tf.GradientTape() as tape:
y = x**2
dy_dx = tape.gradient(y, x) # 计算梯度
从TF2.0开始默认启用的即时执行模式: - 命令式编程接口 - 调试友好 - 与Python生态无缝集成
# 即时执行示例
print(tf.reduce_sum(tf.random.normal([1000, 1000])))
官方推荐的标准模型构建方式:
model = tf.keras.Sequential([
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10)
])
model.compile(
optimizer=tf.keras.optimizers.Adam(0.01),
loss=tf.keras.losses.MSE
)
strategy = tf.distribute.MirroredStrategy()
with strategy.scope():
model = build_model() # 模型在策略范围内构建
model.fit(train_dataset, epochs=10)
| 库名称 | 用途 | 典型应用场景 |
|---|---|---|
| TF Lite | 移动/嵌入式部署 | 手机端图像分类 |
| TF.js | 浏览器端运行 | 网页实时姿态估计 |
| TF Serving | 生产环境部署 | 推荐系统API服务 |
TensorBoard 核心功能: - 训练指标实时监控 - 计算图可视化 - 嵌入向量投影 - 性能分析(Profiler)
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir='./logs')
model.fit(x_train, y_train, callbacks=[tensorboard_callback])
XLA(Accelerated Linear Algebra)编译器优化:
@tf.function(jit_compile=True) # 启用XLA
def train_step(x, y):
with tf.GradientTape() as tape:
predictions = model(x)
loss = loss_fn(y, predictions)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
dataset = tf.data.Dataset.from_tensor_slices((x, y))
dataset = dataset.shuffle(1000).batch(32).prefetch(1)
policy = tf.keras.mixed_precision.Policy('mixed_float16')
tf.keras.mixed_precision.set_global_policy(policy)
base_model = tf.keras.applications.EfficientNetB0(
input_shape=(224, 224, 3),
include_top=False,
weights='imagenet')
bert_preprocess = tfhub.KerasLayer(
"https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3")
bert_encoder = tfhub.KerasLayer(
"https://tfhub.dev/tensorflow/bert_en_uncased_L-12_H-768_A-12/4")
env = tf_agents.environments.TFPyEnvironment(
gym_env.make('CartPole-v1'))
q_net = q_network.QNetwork(
env.observation_spec(),
env.action_spec(),
fc_layer_params=(100,))
TensorFlow持续演进的生态系统,其设计哲学体现了工业级机器学习框架的典型特征。通过本文的系统性概览,读者应能掌握: - TensorFlow的核心架构设计原理 - 现代TF开发的最佳实践 - 性能优化的关键技巧 - 生态系统工具链的选择策略
建议开发者根据具体应用场景,在易用性(Keras API)与灵活性(底层API)之间找到适当平衡点,同时持续关注TF团队每季度发布的重要更新。
注:本文基于TensorFlow 2.12版本撰写,部分特性可能随版本更新发生变化。建议通过官方文档获取最新信息。 “`
这篇文章共计约2700字,采用Markdown格式编写,包含: 1. 多级标题结构 2. 代码示例块 3. 表格对比 4. 流程图示意 5. 重点内容强调 6. 外部资源链接 7. 版本说明注释
可根据需要进一步扩展具体章节内容或添加实际案例的详细实现步骤。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。