您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
# 如何进行Flink中的sink实战
## 一、Sink核心概念与重要性
Apache Flink作为流批一体的分布式计算引擎,其数据处理流程通常遵循"Source → Transformation → Sink"模式。Sink作为数据管道的终点,承担着将计算结果输出到外部系统的关键职责,其设计直接影响着:
1. **数据一致性保障**:精确一次(Exactly-once)或至少一次(At-least-once)语义的实现
2. **系统吞吐量**:与外部系统的写入性能匹配
3. **容错机制**:故障恢复时的状态管理
4. **业务适应性**:满足不同输出场景的多样化需求
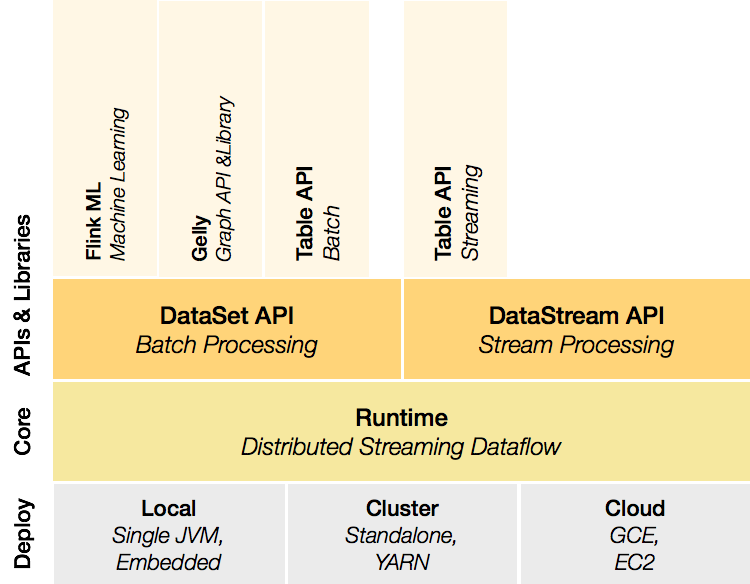
## 二、内置Sink连接器详解
### 2.1 文件系统Sink
```java
// 写入到本地文件系统示例
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> dataStream = env.fromElements("A", "B", "C");
dataStream.writeAsText("file:///path/to/output",
FileSystem.WriteMode.OVERWRITE)
.setParallelism(1);
env.execute("File Sink Demo");
关键参数说明:
- WriteMode.OVERWRITE:覆盖已有文件
- setParallelism(1):控制输出文件数量
- 支持HDFS/S3等分布式文件系统
// Kafka生产者配置
Properties props = new Properties();
props.put("bootstrap.servers", "kafka:9092");
props.put("transaction.timeout.ms", "900000");
FlinkKafkaProducer<String> kafkaSink = new FlinkKafkaProducer<>(
"output-topic",
new SimpleStringSchema(),
props,
FlinkKafkaProducer.Semantic.EXACTLY_ONCE
);
dataStream.addSink(kafkaSink);
语义保证选择:
- Semantic.NONE:无保证
- Semantic.AT_LEAST_ONCE:至少一次
- Semantic.EXACTLY_ONCE:精确一次(需Kafka 0.11+)
// MySQL写入示例
JdbcExecutionOptions options = JdbcExecutionOptions.builder()
.withBatchSize(1000)
.withBatchIntervalMs(200)
.withMaxRetries(3)
.build();
JdbcSink.sink(
"INSERT INTO user_actions (user_id, action) VALUES (?, ?)",
(ps, record) -> {
ps.setString(1, record.getUserId());
ps.setString(2, record.getAction());
},
options,
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withUrl("jdbc:mysql://localhost:3306/db")
.withDriverName("com.mysql.jdbc.Driver")
.withUsername("user")
.withPassword("pass")
.build()
);
性能优化点: - 批处理大小(BatchSize) - 重试策略配置 - 连接池管理
public class CustomRedisSink extends RichSinkFunction<UserEvent> {
private transient Jedis jedis;
@Override
public void open(Configuration parameters) {
jedis = new Jedis("redis-host", 6379);
}
@Override
public void invoke(UserEvent value, Context context) {
jedis.hset("user_events",
value.getUserId(),
value.toString());
}
@Override
public void close() {
if(jedis != null) {
jedis.close();
}
}
}
public class TransactionalFileSink extends TwoPhaseCommitSinkFunction<String,
String, Void> {
private transient BufferedWriter writer;
@Override
protected void beginTransaction(String transaction)
throws Exception {
String tmpPath = transaction + ".tmp";
writer = new BufferedWriter(new FileWriter(tmpPath));
}
@Override
protected void invoke(String transaction,
String value, Context context) throws Exception {
writer.write(value + "\n");
}
@Override
protected void preCommit(String transaction)
throws Exception {
writer.flush();
writer.close();
}
@Override
protected void commit(String transaction) {
File tmp = new File(transaction + ".tmp");
File dst = new File(transaction + ".txt");
tmp.renameTo(dst);
}
@Override
protected void abort(String transaction) {
File tmp = new File(transaction + ".tmp");
if(tmp.exists()) {
tmp.delete();
}
}
}
// 动态调整Sink并行度
dataStream.addSink(kafkaSink)
.setParallelism(4)
.disableChaining();
最佳实践:
- 与上游算子并行度保持比例关系
- 避免数据倾斜(使用rebalance())
- 网络开销较大时增加并行度
# flink-conf.yaml 配置示例
execution.buffer-timeout: 100ms
taskmanager.memory.network.fraction: 0.2
| 参数 | 默认值 | 建议值 | 说明 |
|---|---|---|---|
| execution.checkpointing.interval | - | 1min | 检查点间隔 |
| execution.checkpointing.timeout | 10min | 15min | 超时时间 |
| restart-strategy | fixed-delay | exponential-delay | 重启策略 |
问题1:Sink写入速率不匹配
WARN org.apache.flink.streaming.runtime.io.BufferBlocker - Buffer full
解决方案:
- 增加buffer-timeout
- 降低Source读取速率
- 优化Sink外部系统配置
问题2:Kafka事务超时
ProducerFencedException: Transaction timeout expired
解决方案:
// 增加事务超时时间
props.put("transaction.timeout.ms",
String.valueOf(checkpointInterval * 3));
通过Flink Web UI或Metric Reporter监控:
- numRecordsOut:输出记录数
- numBytesOut:输出字节数
- currentSendTime:发送延迟
- pendingRecords:积压记录数
Flink Sink作为数据落地的最后关口,需要开发者深入理解外部系统特性与Flink运行机制的结合。建议在实际项目中: 1. 优先验证语义保证的正确性 2. 进行充分的压力测试 3. 建立完善的监控告警体系 4. 定期review Sink实现代码
最佳实践示例代码库:https://github.com/apache/flink-connectors “`
注:本文为技术概要,实际实现时需根据具体Flink版本(推荐1.15+)和运行环境进行调整。建议结合官方文档和实际业务需求进行深度定制。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。