您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
# 怎么分析Apache Flink框架
## 目录
1. [引言](#引言)
2. [Flink核心架构解析](#flink核心架构解析)
2.1 [运行时架构](#运行时架构)
2.2 [任务调度模型](#任务调度模型)
2.3 [状态管理机制](#状态管理机制)
3. [编程模型剖析](#编程模型剖析)
3.1 [DataStream API](#datastream-api)
3.2 [Table API & SQL](#table-api--sql)
3.3 [状态与容错编程](#状态与容错编程)
4. [性能优化策略](#性能优化策略)
4.1 [反压机制](#反压机制)
4.2 [内存管理](#内存管理)
4.3 [并行度调优](#并行度调优)
5. [生产环境实践](#生产环境实践)
5.1 [部署模式对比](#部署模式对比)
5.2 [监控与调优](#监控与调优)
5.3 [典型问题排查](#典型问题排查)
6. [生态整合能力](#生态整合能力)
7. [未来发展趋势](#未来发展趋势)
8. [结论](#结论)
---
## 引言
Apache Flink作为第四代分布式流处理引擎,以其**精确一次(Exactly-Once)**的状态一致性保障和**低延迟高吞吐**的特性成为实时计算领域的标杆。本文将深入剖析其设计哲学、实现原理及最佳实践。
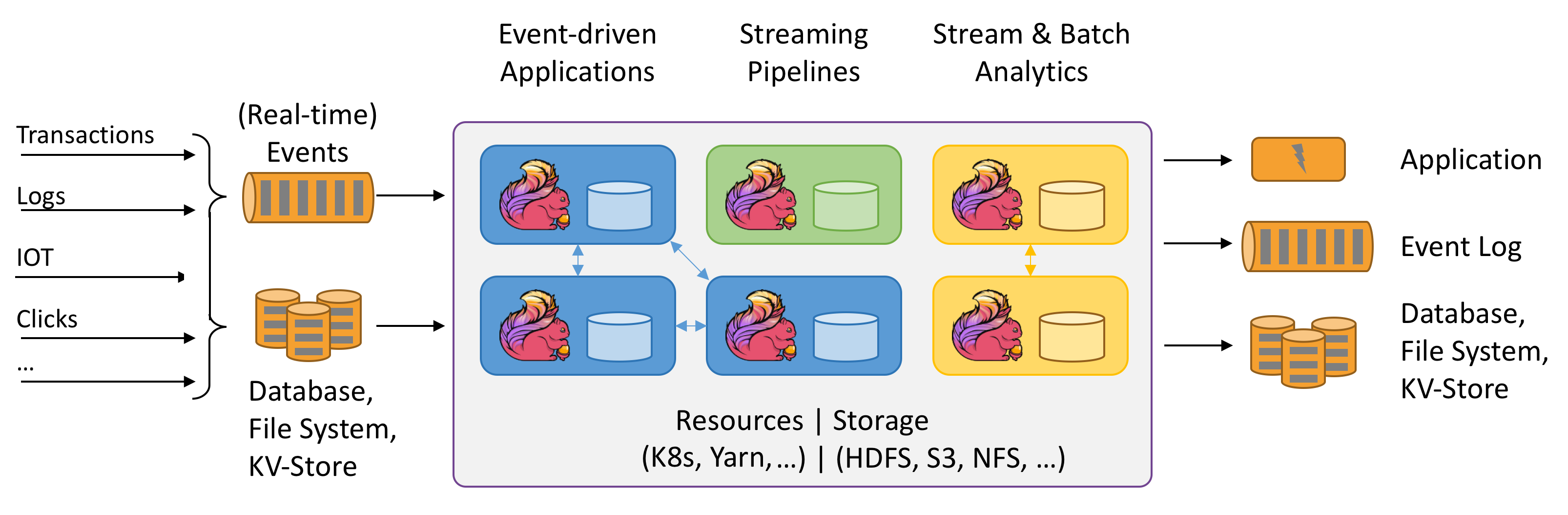
---
## Flink核心架构解析
### 运行时架构
```java
// 伪代码展示JobManager与TaskManager交互
public class JobManager {
public void scheduleTask(TaskDeploymentDescriptor tdd) {
// 协调检查点、故障恢复等
}
}
public class TaskManager {
public void executeTask(Task task) {
// 执行实际数据处理
}
}
| 调度策略 | 特点 | 适用场景 |
|---|---|---|
| Eager调度 | 启动时分配全部资源 | 流处理作业 |
| 懒调度(Lazy) | 分阶段申请资源 | 批处理作业 |
# 状态后端配置示例(RocksDB)
state.backend: rocksdb
state.backend.rocksdb.ttl.compaction.filter.enabled: true
状态类型对比: 1. Keyed State:与Key绑定的分区状态 2. Operator State:算子级别状态 3. Broadcast State:广播状态模式
DataStream<String> stream = env
.addSource(new KafkaSource<>())
.keyBy(event -> event.getUserId())
.window(TumblingEventTimeWindows.of(Time.minutes(5)))
.process(new FraudDetector());
-- 流SQL示例
SELECT
user_id,
COUNT(*) AS click_count
FROM clicks
GROUP BY
user_id,
HOP(ts, INTERVAL '5' SECOND, INTERVAL '1' HOUR)
优化器原理: - Blink Planner的CBO优化 - 动态表到流表的转换

处理方案: 1. 网络缓冲池动态调整 2. 本地策略:缓存超时/丢弃
| 内存区域 | 占比 | 调优参数 |
|---|---|---|
| 框架内存 | 15% | taskmanager.memory.framework.heap.size |
| 任务内存 | 70% | taskmanager.memory.task.heap.size |
| 网络缓冲 | 15% | taskmanager.memory.network.fraction |
# Standalone模式启动命令
./bin/start-cluster.sh
# YARN Session模式
./bin/flink run -m yarn-cluster -yn 4 -ys 8 -yjm 2048 -ytm 4096
关键指标监控:
- numRecordsIn/Out
- currentInputWatermark
- pendingCheckpointSize
| 系统类型 | 连接器 | 特点 |
|---|---|---|
| 消息队列 | Kafka/Pulsar | 精确一次语义支持 |
| 数据库 | JDBC/HBase | 幂等写入实现 |
| 文件系统 | S3/HDFS | 流式写入支持 |
Flink通过其精巧的架构设计,在保证高可靠性的同时实现了亚秒级延迟。掌握其核心原理需要深入理解: - 分布式快照机制 - 事件时间处理模型 - 资源弹性调度
“Flink不是简单的流处理系统,而是数据流操作系统” —— 官方技术白皮书 “`
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。