您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本文所有相关链接pdf:https://163.53.94.133/assets/uploads/files/tf-ceg-case3.pdf

Kubernetes命名空间是“虚拟化”Kubernetes集群的一种内置方式。虽然目前尚无人讨论如何使用命名空间以及在何处使用命名空间,但是如果没有网络范围内的命名空间隔离能力,集群虚拟化将无法完成。
Tungsten Fabric Kubernetes CNI插件包括对isolated命名空间的支持。部署到隔离的命名空间中的应用程序无法访问其所在的命名空间之外的任何Pod,其他命名空间的应用程序也无法访问它的Pod和Services。
一种Kubernetes的部署方法,是每个开发团队部署单独的Kubernetes集群,在这种情况下,集群虚拟化和命名空间隔离几乎没有好处。
但是,由于未使用的容量是零散的,因此该方法可能导致资源使用效率低下。每个集群都有自己的可用容量,其他集群中运行的应用程序无法使用这些可用容量。此外,随着集群数量的增加,它引入了保持统一所需要的操作开销。最后,启动新集群需要花费时间,这可能会使事情变慢。
命名空间是解决这些问题的好方法,因为这有助于减少集群的数量,共享备用容量并且可以快速创建。这还可以提供一个隔离级别,基础架构团队将负责集群的管理,而各个开发人员团队则在自己的命名空间中进行操作。
在处理集群虚拟化时,需要解决三个问题:
(1)谁可以访问虚拟集群(RBAC);
(2)每个虚拟集群可以使用多少计算资源;
(3)虚拟集群中的应用程序允许哪些网络通信。
用于Kubernetes的Tungsten Fabric CNI插件旨在通过本节将要讨论的命名空间隔离以及下一节将介绍的网络策略来解决问题(3)。从法规遵从性的角度来看,这特别有用。PCI合规性就是一个很好的例子,因为它鼓励工作负载隔离。
当寻求实现PCI合规性时,重点关注的领域之一是缩小范围。范围缩小的目的是隔离所有可能影响信用卡信息处理的系统,这些系统被称为“持卡人数据环境”(Cardholder Data Environment,CDE)。
任何工作负载或设备,都可以以任何方式与属于CDE的系统进行交互。网络分段对于实现所需的隔离至关重要,以减少为PCI合规性而考虑的系统数量。
Kubernetes命名空间和基础的容器化平台Kubernetes编排器,可提供减少容器化工作负载的PCI范围所需的计算隔离。Kubernetes还提供了有关存储隔离的解决方案的一部分。但是,Kubernetes当前没有为此目的提供足够的网络隔离或检查。
用于Kubernetes的Tungsten Fabric CNI插件不仅提供了Kubernetes感知命名空间的网络隔离功能,还使管理团队能够通过控制网络功能虚拟化(NFV)实例的流量来检查所有进入或离开命名空间的网络流量。这使得下面的情况称为可能:根据必须被允许进出隔离CDE的通信类型的要求,来调整数据流检查的级别。
让我们来看一个使用Kubernetes命名空间进行网络隔离的示例。在此用例中,我们将部署示例应用程序的两个副本,一个副本部署到默认命名空间中,另一个部署到一个新的隔离命名空间中。然后,我们将看到Tungsten Fabric如何实施网络通信隔离,如下图所示: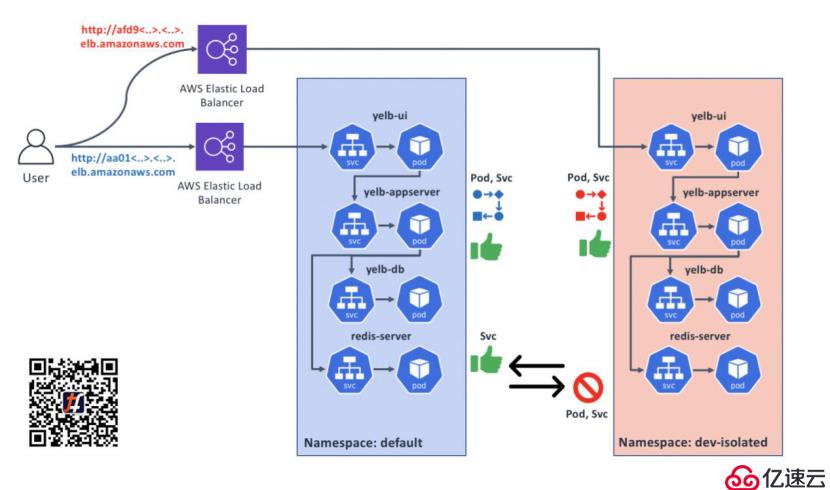
在开始之前,有必要快速浏览Kubernetes文档页面,该页面解释了如何使用命名空间,包括我们需要知道的命令。
全部完成后,确保您位于沙箱控制节点上,以root用户身份登录,并且位于正确的目录中:
#确认您是root账户
whoami | grep root || sudo -s
#切换到清单目录
cd /home/centos/yelb/deployments/platformdeployment/Kubernetes/yaml
接下来,创建一个新清单,以描述我们新的隔离命名空间: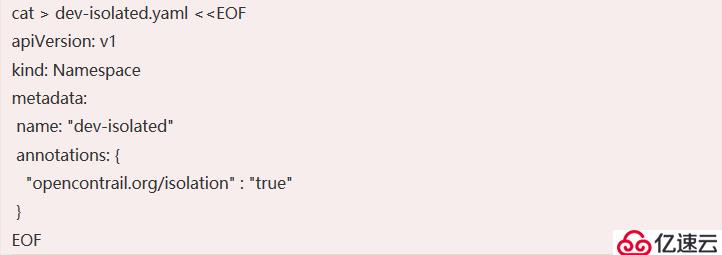
这将创建一个名为dev-isolated.yaml的文件,它包括以上内容。请注意annotations部分——这将告诉Tungsten Fabric隔离新的命名空间。
继续创建该命名空间,并向Kubernetes配置文件添加相关内容,以便我们可以访问它:
#创建新的命名空间:
kubectl create -f dev-isolated.yaml
让我们快速浏览一下新的命名空间:
注意Annotations字段;这向Tungsten Fabric CNI插件发出信号,它需要以不同的方式对待此命名空间。
我们可以简单地将此注释添加到现有命名空间以使其隔离吗?不幸的是没有,因为Tungsten必须做很多额外的工作才能设置一个隔离的新命名空间。更具体地说,必须创建一组单独的虚拟网络,此命名空间中的应用程序Pod将连接到该虚拟网络。
这样可以确保将网络隔离保持在底层水平上,而不是简单地通过流量过滤器之类的较弱方法。
接下来,我们将示例应用程序部署到已创建的隔离命名空间中:
kubectl create --namespace dev-isolated -f cnawebapp-loadbalancer.yaml
一旦应用程序pod启动,我们应该能够像上面用例1中所描述的那样从Internet访问我们的应用程序。
接下来,我们需要一些东西进行比较和对比;因此,将示例应用程序的另一个副本部署到default命名空间中:
kubectl create -f cnawebapp-loadbalancer.yaml
现在,我们有两个应用程序副本。一个在没有隔离的default命名空间中运行,另一个在dev-isolated命名空间中运行。
我们期望的行为有:
1.非隔离命名空间中的Pod和服务,应该可以从非隔离命名空间中的其他Pod(例如default和kube-system)访问;
2.非隔离命名空间中的服务,应该可以从隔离命名空间中运行的Pod访问;
3.隔离命名空间中的Pod和服务,只能从相同命名空间中的Pod访问;
4.对于以上的情况有个例外:在隔离的命名空间里的LoadBalancer的服务可以被外部世界访问。
我们将逐个验证这些行为。
我们知道Pod可以与在default命名空间中的服务通信——这就是示例应用程序的工作方式。但是跨命名空间呢?由于我们位于沙箱中,因此可以使用kube-system命名空间中的一个Pod来尝试访问在default非隔离命名空间中运行的应用程序中的Pods和Services :
#获得kube-system pods里的tiller-deploy的名字:
src_pod=$(kubectl get pods --namespace kube-system | grep tiller | awk '{print $1}')
#找到“default”命名空间里的“yelb-ui”pod的IP:
dst_pod_ip=$(kubectl get pods -o wide | grep yelb-ui | awk '{print $6}')
#让tiller-deploy去ping yelb-ui:
kubectl exec --namespace kube-system -it ${src_pod} ping ${dst_pod_ip}
最后一条命令的输出应类似于:
PING 10.47.255.246 (10.47.255.246): 56 data bytes
64 bytes from 10.47.255.246: seq=0 ttl=63 time=1.291 ms
64 bytes from 10.47.255.246: seq=1 ttl=63 time=0.576 ms
用^ C取消命令。
这确认了非隔离命名空间中的Pod可以相互到达。
#获得运行在“default”命名空间里的“yelb-ui”服务的集群IP地址:
default_yelb_ui_ip=$(kubectl get svc --namespace default -o wide | grep yelb-ui | awk '{print $3'})
#获得"dev-isolated" 命名空间的"yelb-appserver" Pod的名字
src_pod2=$(kubectl get pods --namespace dev-isolated | grep yelb-appserver | awk '{print $1}')
#在“yelb-appserver”运行“curl” ,尝试访问“default”命名空间的服务IP:
kubectl exec -it -n dev-isolated ${src_pod2} -- /usr/bin/curl http://${default_yelb_ui_ip}
我们应该在yelb-ui主页上看到大约10行HTML代码,这表明dev-isolated命名空间中的Pod 可以与非隔离default命名空间中的服务通信。
现在,让我们尝试从同一个tiller-deploy Pod去ping 运行在dev-isolated命名空间的yelb-ui Pod:
#获得位于“dev-isolated”命名空间的“yelb-ui”pod 的IP:
isolated_pod_ip=$(kubectl get pods --namespace dev-isolated -o wide | grep yelb-ui | awk '{print $6}')
#..尝试ping它:
kubectl exec --namespace kube-system -it ${src_pod} ping ${isolated_pod_ip}
您应该看到该命令被“卡住”了,没有显示任何响应,因为这次我们正尝试达到某些无法达到的目的地,Tungsten Fabric正在阻止这一访问。
按^ C取消命令。
再多试一下——尝试从位于default命名空间的yelb Pods去ping隔离的yelb Pods和服务。一切都按预期工作了吗?
但是,如果我们无法访问它,那么在一个隔离的命名空间中运行应用程序就没有多大意义了。因此,在独立命名空间本dev-isolated的yelb副本应通过LoadBalancer Service yelb-ui 供Internet使用。让我们测试一下:
kubectl get svc --namespace dev-isolated -o wide | grep yelb-ui | awk '{print $4}'
它应该显示类似afd9047c2915911e9b411026463a4a33-777914712.us-west-1.elb.amazonaws.com 的结果;将您的浏览器指向它,看看我们的应用程序是否可被加载!
一旦进行了足够的测试,可以随时清理:
#删除两个“yelb”副本:
kubectl delete -f cnawebapp-loadbalancer.yaml
kubectl delete --namespace dev-isolated -f cnawebapp-loadbalancer.yaml
#删除独立的命名空间和它的清单:
kubectl delete -f dev-isolated.yaml
rm -f dev-isolated.yaml
Kubernetes命名空间已被设计为虚拟化Kubernetes集群的一种方式。没有网络,任何虚拟化都是不完整的,而Tungsten Fabric对隔离命名空间的支持提供了此功能。
但是,在您需要在命名空间中实施应用程序网络安全策略时,隔离的命名空间提供的粒度可能较粗。
也有一些更精细的控件,我们将在用例4的文章中进行详细介绍。
MORE
更多TF+K8s文章
第一篇:TF Carbide 评估指南--准备篇
第二篇:通过Kubernetes的服务进行基本应用程序连接
第三篇:通过Kubernetes Ingress进行高级外部应用程序连接
关于Tungsten Fabric:
Tungsten Fabric项目是一个开源项目协议,它基于标准协议开发,并且提供网络虚拟化和网络安全所必需的所有组件。项目的组件包括:SDN控制器,虚拟路由器,分析引擎,北向API的发布,硬件集成功能,云编排软件和广泛的REST API。
关于TF中文社区:
TF中文社区由中国的一群关注和热爱SDN的志愿者自发发起,有技术老鸟,市场老炮,也有行业专家,资深用户。将作为连接社区与中国的桥梁,传播资讯,提交问题,组织活动,联合一切对多云互联网络有兴趣的力量,切实解决云网络建设过程中遇到的问题。

关注微信:TF中文社区 
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。