жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒдёәеӨ§е®¶еҲҶжһҗдәҶеҰӮдҪ•еҲҶжһҗApache TubeMQж•°жҚ®еҸҜйқ жҖ§зҡ„зӣёе…ізҹҘиҜҶзӮ№пјҢеҶ…е®№иҜҰз»Ҷжҳ“жҮӮпјҢж“ҚдҪңз»ҶиҠӮеҗҲзҗҶпјҢе…·жңүдёҖе®ҡеҸӮиҖғд»·еҖјгҖӮеҰӮжһңж„ҹе…ҙи¶Јзҡ„иҜқпјҢдёҚеҰЁи·ҹзқҖи·ҹйҡҸе°Ҹзј–дёҖиө·жқҘзңӢзңӢпјҢдёӢйқўи·ҹзқҖе°Ҹзј–дёҖиө·ж·ұе…ҘеӯҰд№ вҖңеҰӮдҪ•еҲҶжһҗApache TubeMQж•°жҚ®еҸҜйқ жҖ§вҖқзҡ„зҹҘиҜҶеҗ§гҖӮ
жҲ‘们еңЁApache TubeMQзҡ„йҖӮз”ЁеңәжҷҜжңүд»Ӣз»ҚпјҢTubeMQйҖӮз”ЁдәҺжһҒз«Ҝжғ…еҶөдёӢе®№еҝҚе°‘йҮҸж•°жҚ®дёўеӨұзҡ„дёҡеҠЎеңәжҷҜпјҢйӮЈд№ҲTubeMQеҲ°еә•еңЁд»Җд№Ҳжғ…еҶөдёӢеҸҜиғҪдјҡеҮәзҺ°ж•°жҚ®дёўеӨұпјҹдёәд»Җд№ҲиҰҒиҝҷд№Ҳи®ҫи®ЎпјҹеҗҢзұ»MQеңЁиҝҷж–№йқўжҳҜжҖҺд№ҲеҒҡзҡ„пјҹиҝҷзҜҮж–ҮжЎЈи®ЎеҲ’и§Јзӯ”иҝҷеҮ дёӘй—®йўҳгҖӮ
Apache TubeMQзі»з»ҹж•°жҚ®еӯҳеӮЁйҮҮз”Ёзҡ„жҳҜеҚ•иҠӮзӮ№еӨҡзЈҒзӣҳRAID10зҡ„еүҜжң¬ж–№жЎҲиҝӣиЎҢеӯҳеӮЁпјҢж•°жҚ®еҸӘеңЁеҰӮдёӢеңәжҷҜеӯҳеңЁеҸҜиғҪдёўеӨұжғ…еҶөпјҡ
жңәеҷЁж–ӯз”өпјҢе·ІеӣһеӨҚжҲҗеҠҹдҪҶиҝҳжІЎжңүиў«ж¶Ҳиҙ№дё”еӨ„еңЁеҶ…еӯҳдёӯзҡ„ж•°жҚ®дјҡдёўпјӣжңәеҷЁдёҠзәҝеҗҺпјҢе·ІеӯҳеӮЁеңЁзЈҒзӣҳдёҠзҡ„ж•°жҚ®дёҚеҸ—еҪұе“Қпјӣ
RAID10 holdдёҚдҪҸзҡ„зЈҒзӣҳејӮеёёпјҢе·Іиҝ”еӣһжҲҗеҠҹдҪҶиҝҳжІЎжңүиў«ж¶Ҳиҙ№зҡ„ж•°жҚ®дјҡеҸ—еҪұе“ҚпјӣзЈҒзӣҳдҝ®еӨҚеҗҺпјҢе·ІеӯҳеӮЁдҪҶжІЎжңүжҒўеӨҚеӣһжқҘзҡ„ж•°жҚ®дјҡдёўеӨұпјӣ
RAID10 иғҪholdдҪҸзҡ„ж—ҘеёёеқҸзӣҳпјҢеқҸзӣҳBrokerиҠӮзӮ№зҡ„з”ҹдә§е’Ңж¶Ҳиҙ№дёҚеҸ—еҪұе“Қпјӣ
иҝҷдёӘй—®йўҳд№ҹжҳҜдәӨжөҒжңҖеӨҡзҡ„дёҖдёӘиҜқйўҳпјҢеӨ§е®¶жңҖзӣҙи§Ӯзҡ„ж„ҹеҸ—жҳҜпјҡжңәеҷЁеҫҲе®№жҳ“жҢӮпјҢTubeMQеҸӘжңүеҚ•иҠӮзӮ№пјҢж•°жҚ®зҡ„еҸҜйқ жҖ§жҳҜдёҚй«ҳзҡ„гҖӮиҝҷйҮҢдёӘдәәзҡ„и§ӮзӮ№иҝҳжҳҜеҰӮе…¶д»–еңәеҗҲд»Ӣз»ҚйҮҢдёҖзӣҙиЎЁиҫҫзҡ„пјҡз”Ёж•°жҚ®еҸҜйқ жҖ§жҢҮж ҮжқҘеҸҚеә”зі»з»ҹзҡ„ж•°жҚ®еҸҜйқ жҖ§е…¶е®һжҳҜдёҚеӨӘеҗҲйҖӮпјҢеӣ дёәе®ғеҸӘжҳҜеҸҚжҳ дәҶзі»з»ҹж•°жҚ®еҸҜйқ жҖ§зҡ„жһңпјҢеҜ№еҰӮдҪ•и§ЈеҶіж•°жҚ®еҸҜйқ жҖ§е…¶е®һжІЎжңүеӨӘзӣҙжҺҘзҡ„е…ізі»пјӣд»Һд»Ӣз»Қзҡ„ж•°жҚ®еҸҜиғҪеӯҳеңЁдёўзҡ„еңәжҷҜд»Ӣз»ҚжҲ‘们еҸҜд»ҘзңӢеҲ°пјҢз”ҹдә§зҺҜеўғзҡ„жңәжҲҝжғ…еҶөгҖҒжңҚеҠЎеҷЁзЎ¬д»¶жғ…еҶөпјҢд»ҘеҸҠдёҡеҠЎиғҪеҗҰеҚіж—¶ж¶Ҳиҙ№е®Ңж•°жҚ®зӯүзӣҙжҺҘеҪұе“ҚеҲ°зі»з»ҹзҡ„ж•°жҚ®еҸҜйқ жҖ§пјҢжҳҜиҝҷдәӣеҶ…е®№ж•…йҡңеҜјиҮҙдәҶзі»з»ҹж•°жҚ®еҸҜйқ жҖ§зҡ„й«ҳжҲ–иҖ…дҪҺпјҢеҰӮжһңжІЎжңүдёҠиҝ°иҝҷдәӣй—®йўҳпјҢTubeMQзі»з»ҹзҡ„ж•°жҚ®еҸҜйқ жҖ§е…¶е®һе°ұжҳҜ100%пјҢжүҖд»ҘпјҢжҲ‘们еә”иҜҘйҖҡиҝҮеҜ№еә”зҺҜеўғеҜјиҮҙж•°жҚ®еҸҜиғҪдёўеӨұзҡ„ж•…йҡңзҺҮжҢҮж ҮжқҘиҜ„дј°гҖҒеҲҶжһҗзі»з»ҹзҡ„ж•°жҚ®еҸҜйқ жҖ§пјҢдёӘдәәи§үеҫ—иҝҷдёӘжҳҜж №жң¬гҖӮ
жҢүз…§2019е№ҙжҲ‘们зәҝдёҠзҺҜеўғзҡ„ж•…йҡңж•°жҚ®з»ҹи®ЎпјҢTubeMQйӣҶзҫӨеңЁжҲ‘们зҺҜеўғпјҢе…Ёе№ҙеҜјиҮҙж•°жҚ®еҸҜиғҪдёўеӨұзҡ„ж•…йҡңзҺҮеӨ§жҰӮжҳҜ2.67%пјҡж•ҙдёӘTubeMQйӣҶзҫӨ1500еҸ°жңәеҷЁпјҢж—ҘеқҮжңү35дёҮдәҝжқЎзҡ„ж•°жҚ®жҺҘе…ҘйҮҸеүҚжҸҗдёӢпјҢе…Ёе№ҙеӨ§жҰӮжңү40еҸ°е·ҰеҸізҡ„жңҚеҠЎеҷЁеҮәзҺ°иҝҮжңәеҷЁpingејӮеёёпјҢд»ҘеҸҠRAID10 holdдёҚдҪҸзҡ„зЈҒзӣҳз»„жҚҹеқҸејӮеёёгҖӮдёӘдәәи§үеҫ—жҲ‘们зҺҜеўғзҡ„ж•…йҡңзҺҮжҢҮж ҮиҝҳеҸҜд»ҘеҶҚйҷҚдҪҺпјҢеӣ дёәTubeMQйӣҶзҫӨйҮҢз”Ёзҡ„жңәеҷЁеӨҡжҳҜйҮҚзӮ№дёҡеҠЎз”ЁдәҶеҮ е№ҙеҗҺж·ҳжұ°дёӢжқҘзҡ„дәҢжүӢжңәеҷЁи®ҫеӨҮгҖӮ
йҷҚжҲҗжң¬пјҡ еӨ§е®¶йғҪзҹҘйҒ“пјҢиҰҒиҫҫеҲ°е®Ңе…Ё100%зҡ„ж•°жҚ®еҸҜйқ жҖ§жҳҜйқһеёёиҖ—иҙ№жҲҗжң¬зҡ„пјҢдёҖдёӘMQз®ЎйҒ“иҰҒеҒҡжҲҗзұ»дјјеӨӘз©әйЈһиҲ№и®ҫи®Ўж ·жһ„йҖ еӨҡеҘ—зӢ¬з«ӢиҠӮзӮ№зҡ„еҶ—дҪҷж•°жҚ®еӨҮд»ҪпјҢжқҘдҝқиҜҒж•°жҚ®дёҚдёўпјӣиҖҢд»ҺжҲ‘们зҡ„еҲҶжһҗжқҘзңӢпјҢйҖҡиҝҮMQдј йҖ’зҡ„дёҡеҠЎж•°жҚ®пјҢ90%е·ҰеҸізҡ„ж•°жҚ®жҳҜеҸҜд»Ҙе®№и®ёжһҒз«Ҝжғ…еҶөдёӢдёўеӨұе°‘йҮҸж•°жҚ®зҡ„пјҢжңү10%е·ҰеҸізҡ„ж•°жҚ®жҳҜиҰҒжұӮдёҖжқЎйғҪдёҚиғҪдёўпјҢжҜ”еҰӮдәӨжҳ“жөҒж°ҙпјҢж¶үеҸҠеҲ°й’ұзӣёе…ізҡ„ж—Ҙеҝ—ж•°жҚ®зӯүпјӣеҰӮжһңжҲ‘们е°Ҷиҝҷ10%зҡ„й«ҳеҸҜйқ ж•°жҚ®еҚ•зӢ¬жӢҺеҮәжқҘеӨ„зҗҶзҡ„иҜқпјҢжҲ‘们е°ұеҸҜд»ҘиҠӮзәҰеӨ§йҮҸзҡ„жҲҗжң¬пјҢеҹәдәҺиҝҷдёӘжҖқи·ҜпјҢTubeMQиҙҹиҙЈе®ҢжҲҗиҰҒжұӮй«ҳжҖ§иғҪгҖҒжһҒз«Ҝжғ…еҶөдёӢе®№и®ёж•°жҚ®е°‘йҮҸдёўеӨұзҡ„ж•°жҚ®жңҚеҠЎгҖӮ 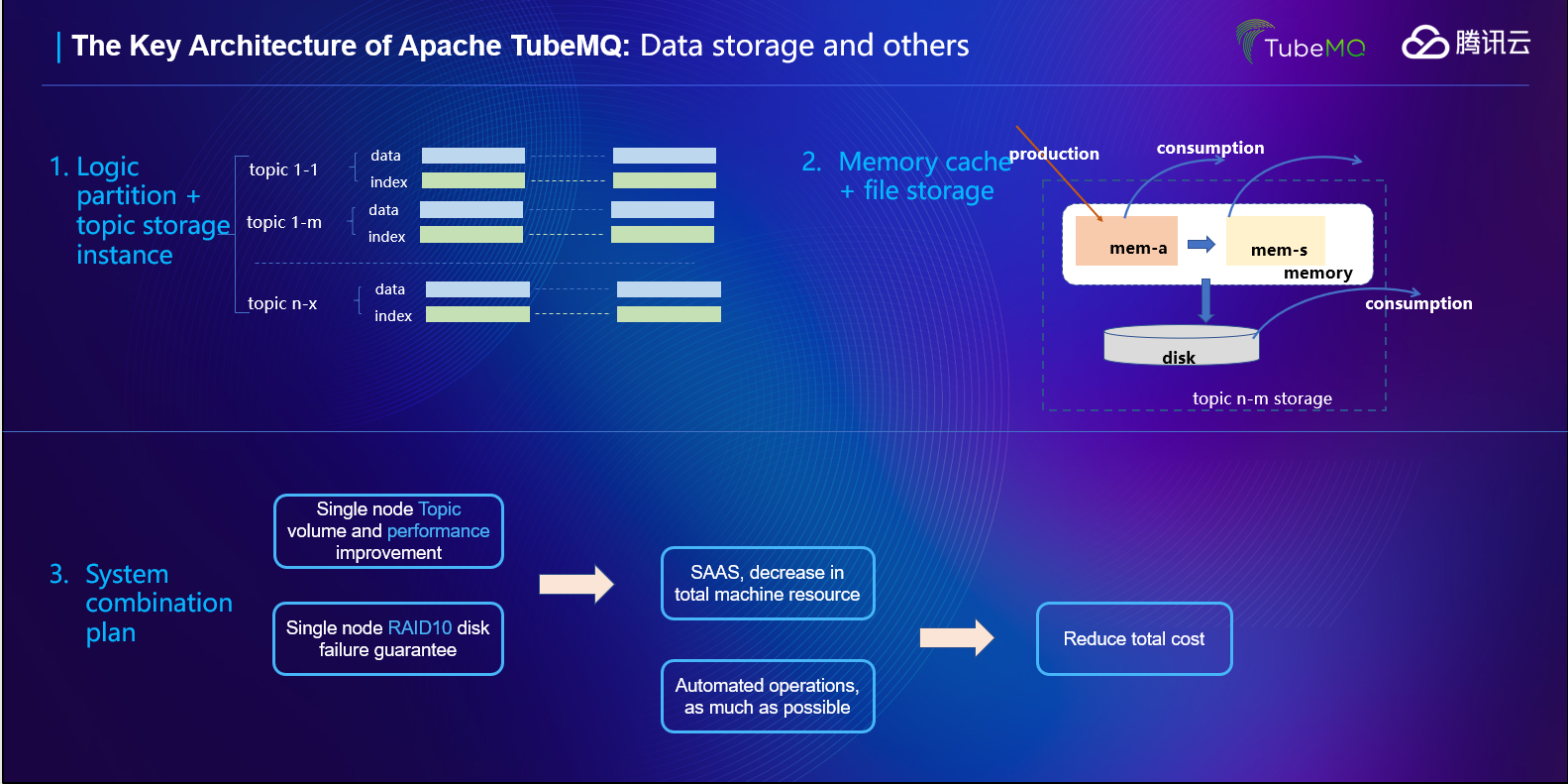
еҰӮдёҠеӣҫзӨәпјҢйҷӨдәҶж–№жЎҲдёҠзҡ„иҖғйҮҸеӨ–пјҢжҲ‘们еңЁTubeMQзҡ„еӯҳеӮЁж–№жЎҲи®ҫи®ЎдёҠд№ҹжҳҜеҒҡдәҶд»”з»Ҷзҡ„ж–ҹй…ҢпјҡжҲ‘们жҢүз…§Topicз»ҙеәҰиҝӣиЎҢдәҶж•°жҚ®е’Ңзҙўеј•зҡ„组件пјӣжҲ‘们еңЁж–Ү件д№ӢдёҠеҶҚеҸ еҠ дәҶдёҖеұӮеҶ…еӯҳеӯҳеӮЁдҪңдёәзЈҒзӣҳж–Ү件еӯҳеӮЁзҡ„延申гҖӮдҪҶжҲ‘们еҸҲжІЎжңүеӣ дёәдёҡеҠЎе®№еҝҚе°‘йҮҸдёўеӨұиҖҢе®Ңе…Ёзҡ„ж— жүҖйЎҫеҝҢпјҢжҜ”еҰӮпјҡжҲ‘们数жҚ®з”ҹдә§йҮҮз”Ёзҡ„жҳҜQoS1ж–№жЎҲпјӣжҲ‘们зҡ„ж•°жҚ®еӯҳеӮЁжҳҜжңүејәеҲ¶зҡ„зј“еӯҳеҲ·зӣҳпјҲжҢүжқЎгҖҒжҢүж—¶й—ҙгҖҒжҢүsizeпјүжҺ§еҲ¶зҡ„еҲ·зӣҳжҺ§еҲ¶пјӣжҲ‘们зҡ„зЈҒзӣҳж•…йҡңжҳҜжңүжңҚеҠЎз«ҜеҹәдәҺиҝҗиҗҘзӯ–з•Ҙзҡ„BrokerиҠӮзӮ№иҮӘеҠЁеҸӘиҜ»жҲ–иҖ…дёӢзәҝз®ЎжҺ§пјҲServiceStatusHolderпјүпјӣз”ҹдә§з«Ҝй’ҲеҜ№BrokerиҠӮзӮ№зҡ„жңҚеҠЎиҙЁйҮҸд№ҹжҳҜжңүиҮӘеҠЁејӮеёёиҠӮзӮ№ж„ҹзҹҘе’Ңз®—жі•еұҸи”ҪпјҢзӯүзӯүзӯүзӯүпјҢд»ҘжӯӨжқҘиҫҫеҲ°й«ҳжҖ§иғҪеҗҢж—¶е°ҪеҸҜиғҪзҡ„жҸҗй«ҳж•°жҚ®зҡ„еҸҜйқ жҖ§пјҢйҷҚдҪҺж•°жҚ®дёўеӨұзҡ„еҸҜиғҪгҖӮ
иғҪйҷҚеӨҡе°‘жҲҗжң¬пјҹ жӢҝеӨ–йғЁеӨҡдёӘдҪҝз”ЁKafkaзҡ„еҺӮе•Ҷе·Із»Ҹе…¬ејҖзҡ„иҝҗиҗҘж•°жҚ®жқҘзңӢпјҢ1дёҮдәҝж—ҘеқҮжҺҘе…ҘйҮҸпјҢKafkaеӨ§жҰӮйңҖиҰҒ200 ~ 300еҸ°дёҮе…ҶжңәпјҢжҢүз…§2019е№ҙзҡ„иҝҗиҗҘж•°жҚ®пјҢTubeMQеӨ§жҰӮ40 ~ 50еҸ°дёҮе…ҶжңәпјӣиҝҷйҮҢиҝҳеҢ…еҗ«дёҖдәӣеҸҜд»ҘеҢәеҲҶзҡ„зү№ж®Ҡжғ…еҶөпјҢжҜ”еҰӮзӢ¬з«ӢйӣҶзҫӨгҖҒзү№е®ҡдёҡеҠЎд»Ҫж•°зҡ„дёҚеҗҢзӯүпјҢдҪҶжңәеҷЁзҡ„жҲҗжң¬жҢҮж Үж•°жҚ®зҡ„жҜ”еҖјеә”иҜҘжҳҜзӣёе·®дёҚеӨ§зҡ„гҖӮеҰӮжһңжҠҠиҝҷдәӣж•°жҚ®жҢҮж ҮжҚўз®—жҲҗй’ұзҡ„иҜқпјҢиҝҷдёӘиҠӮзәҰзҡ„жҲҗжң¬д»…жңҚеҠЎеҷЁжҲҗжң¬йғҪеҸҜд»Ҙд»ҘдәҝеҚ•дҪҚ жқҘи®Ўз®—гҖӮ
д№ҹжңүдәәдјҡиҜҙпјҢжҳҜдёҚжҳҜжҲ‘жӢҝKafkaзҡ„еҚ•еүҜжң¬иҝӣиЎҢдёҡеҠЎжңҚеҠЎпјҢе°ұеҸҜд»ҘиҫҫеҲ°TubeMQдёҖж ·зҡ„жҲҗжң¬ж•ҲжһңдәҶпјҹжҲ‘жғіиЎЁиҫҫзҡ„жҳҜпјҢеҰӮжһңеҸҜд»Ҙзҡ„иҜқпјҢжҲ‘们е°ұдёҚдјҡиҖ—иҙ№иҝҷд№Ҳй•ҝзҡ„ж—¶й—ҙе’Ңиө„жәҗеҺ»ж”№иҝӣTubeMQпјҢзӣҙжҺҘдҪҝз”ЁKafkaеҚ•еүҜжң¬ж–№жЎҲдәҶпјҢеңЁжҲ‘们ејҖжәҗеҲқжңҹеҒҡиҝҮдёҖд»Ҫе…Ёйқўзҡ„еҚ•Brokerзҡ„жҖ§иғҪеҺӢжөӢеҜ№жҜ”жҖ»з»“жҠҘе‘Ҡtubemq_perf_test_vs_KafkaпјҢеӨ§е®¶еҸҜд»ҘеңЁдёҠйқўжүҫеҲ°еҜ№еә”зҡ„е…·дҪ“е·®ејӮгҖӮ
иҝҷйҮҢжғіиЎЁиҫҫзҡ„жҳҜпјҢе®һйҷ…дёҠпјҢTubeMQзі»з»ҹжң¬иә«зҡ„ж•°жҚ®еҸҜйқ жҖ§е…¶е®һ并дёҚдҪҺгҖӮиҝҷйҮҢеӨ§е®¶жңүжІЎжңүжғіиҝҮпјҢеҗ„дёӘMQпјҢеңЁеӨҡеүҜжң¬ж–№жЎҲдёӢпјҢзі»з»ҹж•°жҚ®еҸҜйқ жҖ§еҸҲжңүеӨҡй«ҳе‘ўпјҹ
Kafkaпјҡ д»ҘжҲ‘дёӘдәәеҲҶжһҗзҡ„и§ӮзӮ№пјҢеңЁй«ҳжҖ§иғҪеңәжҷҜдёӢKafkaзҡ„еӨҡеүҜжң¬ж–№жЎҲд№ҹеҸӘжҳҜе°ҪеҠӣиҖҢдёәзҡ„дҝқиҜҒж•°жҚ®еӨҡеүҜжң¬еӯҳеӮЁдёҚдёўгҖӮ
KafkaеүҜжң¬жңәеҲ¶йҖҡиҝҮдёҖдёӘARйӣҶеҗҲд»ҘеҸҠISRйӣҶеҗҲжқҘиҜҶеҲ«е’ҢеҢәеҲҶеүҜжң¬д»Ҫж•°д»ҘеҸҠеңЁзәҝеҗҢжӯҘеүҜжң¬ж•°пјҢйҖҡиҝҮreplica.lag.time.max.msеҸӮж•°и®°еҪ•еҗ„дёӘеүҜжң¬жңҖиҝ‘еҗҢжӯҘзҡ„ж—¶й—ҙжқҘеҲӨе®ҡеҗ„дёӘFollowerжҳҜеҗҰд»ҚдёҺLeaderеӨ„дәҺеҗҢжӯҘеңЁзәҝпјӣеңЁ0.9XзүҲжң¬д№ӢеүҚKafkaиҝҳжңүеҸҰеӨ–дёҖдёӘе·Із»ҸеҺ»жҺүзҡ„replica.lag.max.messagesеҸӮж•°пјҢFollowerеүҜжң¬ж»һеҗҺLeaderеүҜжң¬зҡ„ж¶ҲжҒҜж•°пјҢз»“еҗҲиө·жқҘеҲӨе®ҡеӨұж•ҲеүҜжң¬гҖӮзәҝдёҠиҝҗиЎҢж—¶KafkaеҸҲйҖҡиҝҮISRзҡ„дёӘж•°еҸҠиҜ·жұӮзҡ„еүҜжң¬еә”зӯ”дёӘж•°дҝқиҜҒж•°жҚ®еӨҡдёӘиҠӮзӮ№еӯҳеӮЁпјҡжңҚеҠЎеҷЁз«ҜйҖҡиҝҮmin.insync.replicasжқҘзЎ®дҝқISRйҮҢжңҖе°‘еӨ„дәҺеҗҢжӯҘзҠ¶жҖҒзҡ„еүҜжң¬дёӘж•°пјҢе®ўжҲ·з«ҜеҸҜд»ҘжҢҮе®ҡиҜ·жұӮзҡ„AckдёӘж•°пјҲ0пјҡдёҚеә”зӯ”пјҢ1пјҡLeaderеӯҳеӮЁеҚіOKпјҢ-1пјҡжүҖжңүISRиҠӮзӮ№йғҪеә”зӯ”пјүз»“еҗҲиө·жқҘзЎ®дҝқж•°жҚ®еҸҜд»Ҙиў«еӨҡдёӘеүҜжң¬жүҖжҺҘ收гҖӮ
д»ҺиҝҷдёӘжңәеҲ¶зҡ„и®ҫи®ЎжҲ‘们еҸҜд»ҘеҫҲжё…жҷ°зҡ„зңӢеҲ°пјҢеҚідҪҝжҳҜKafkaзҡ„и®ҫи®ЎиҖ…пјҢд№ҹжҳҜеҫҲжё…жҘҡж•°жҚ®еҫҲжңүеҸҜиғҪжІЎжңүд»ҺLeaderеҗҢжӯҘеҲ°еҗ„дёӘFollowerпјҢеӯҳеңЁеӨҚеҲ¶дёҚеҸҠж—¶зҡ„жғ…еҶөпјҢжүҖд»Ҙе°ҶISRиҜҶеҲ«з”ұпјҲж»һеҗҺжқЎж•°пјҢеҗҢжӯҘж—¶й—ҙпјүж”№дёәдәҶпјҲеҗҢжӯҘж—¶й—ҙпјүпјҢеӣ дёәж»һеҗҺйҮҸеӨӘеӨ§еҪұе“ҚеҲ°дәҶISRеүҜжң¬ж•°зҡ„еҲӨе®ҡгҖӮиҖҢиҝҷдёӘISRзҡ„еүҜжң¬ж•°еҸҲеҪұе“ҚеҲ°дәҶеҜ№еә”Topicзҡ„еҶҷе…ҘпјҢеҰӮжһңTopicзҡ„ISRдёӘж•°дёә0пјҢеҺҹз”ҹKafkaжҳҜж— жі•еҶҷе…Ҙж¶ҲжҒҜзҡ„пјӣдёәжӯӨKafkaеҸҲеўһеҠ дәҶдёҖдёӘunclean.leader.election.enableеҸӮж•°пјҢе…Ғи®ёжңӘеӨ„дәҺеҗҢжӯҘзҠ¶жҖҒзҡ„TopicеүҜжң¬еҸҜд»ҘйҖүдёәLeaderеҜ№еӨ–жңҚеҠЎпјҢеҒҡе°ҪеҠӣиҖҢдёәзҡ„жңҚеҠЎгҖӮ
д»ҺеҰӮдёҠеҲҶжһҗпјҢеңЁеӨ§ж•°жҚ®еңәжҷҜдёӢKafkaзҡ„иҝҷз§ҚеүҜжң¬жңәеҲ¶пјҢеҸҜд»Ҙж»Ўи¶іеӣһжәҜж¶Ҳиҙ№дёҡеҠЎйңҖиҰҒпјҢдё»еүҜжң¬жүҖеңЁжңәеҷЁж•…йҡңеҗҺпјҢе·Із»ҸеҗҢжӯҘеҲ°еүҜжң¬зҡ„ж•°жҚ®еҸҜд»Ҙиў«еӣһжәҜдёҡеҠЎж¶Ҳиҙ№еҲ°пјҢдҪҶжҳҜпјҢз”ұдәҺдёҠиҝ°й—®йўҳеӯҳеңЁж•°жҚ®дёўзҡ„й—®йўҳпјҢеҜ№дәҺиҰҒжұӮеӣһжәҜ并дҝқиҜҒж•°жҚ®дёҚдёўзҡ„еңәжҷҜж— жі•ж»Ўи¶іпјӣеҗҢж—¶пјҢиҝҷз§Қж–№жЎҲиө„жәҗж¶ҲиҖ—еӨ§еҲ©з”ЁзҺҮйқһеёёзҡ„дҪҺпјҢжҢүз…§2еүҜжң¬зҡ„й…ҚзҪ®пјҢиө„жәҗеўһеҠ дәҶиҮіе°‘1еҖҚгҖҒзҪ‘з»ңеёҰе®ҪдёӢйҷҚ1/2пјҢеҗҢж—¶дёәдәҶйҒҝе…Қ2еүҜжң¬еҪўжҲҗISRдёә0зҡ„жғ…еҶөпјҢдҪҝз”Ёж–№еҫҲжңүеҸҜиғҪй…ҚзҪ®3еүҜжң¬пјҢд»ҺиҖҢиө„жәҗеўһеҠ жӣҙеӨҡиҖҢиө„жәҗеҲ©з”ЁзҺҮеҲҷжӣҙдҪҺпјҢз”ЁеҰӮжӯӨй«ҳзҡ„жҲҗжң¬з»ҙзі»зҡ„еҚҙжҳҜдёҖдёӘдёҚеҸҜйқ зҡ„ж•°жҚ®жңҚеҠЎпјҢж–№жЎҲ并дёҚе»үд»·жңүж•ҲпјӣжңҖеҗҺпјҢKafkaеңЁеҲҶеҢәж— еүҜжң¬еӯҳжҙ»ж—¶йҳ»еЎһз”ҹдә§жөҒйҮҸзӣҙжҺҘжҺү0пјҢиҝҷеҜ№еӨ§жөҒйҮҸзҺҜеўғзҡ„дёҡеҠЎдёӘдәәи§үеҫ—жҳҜж— жі•жҺҘеҸ—зҡ„пјҢиҖҢеҚідҪҝйҮҮз”Ёй…ҚзҪ®3еүҜжң¬жЁЎејҸпјҢеӣ дёә3еүҜжң¬дҝқжҙ»жҳҜеҠЁжҖҒзҡ„пјҢжһҒз«Ҝжғ…еҶөдёӢд»Қ然еӯҳеңЁз”ҹдә§еҸ—йҳ»й—®йўҳгҖӮ
Pulsarпјҡ д»ҘжҲ‘дёӘдәәзҡ„еҲҶжһҗи§ӮзӮ№пјҢеҸҜд»ҘдҝқиҜҒж•°жҚ®дёҚдёўпјҢдҪҶеӨ§ж•°жҚ®еңәжҷҜдёӢжҳҜжңүеҪұе“Қзҡ„гҖӮ
PulsarйҮҮз”ЁдәҶзұ»дјјRaftеҚҸи®®жЁЎејҸпјҢеӨҡж•°еүҜжң¬еҶҷжҲҗеҠҹеҚіиҝ”еӣһжҲҗеҠҹпјҢ并且жҳҜйҮҮз”Ёзҡ„жңҚеҠЎеҷЁдё»еҠЁPushиҜ·жұӮеҲ°еҗ„дёӘBookeeperеүҜжң¬иҠӮзӮ№зҡ„жЁЎејҸгҖӮиҝҷз§Қе®һж—¶зҡ„еӨҡеүҜжң¬еҗҢжӯҘж–№жЎҲеҸҜд»Ҙж»Ўи¶із»қеӨ§еӨҡж•°зҡ„й«ҳеҸҜйқ дёҡеҠЎйңҖиҰҒпјҢз”ЁжҲ·зҡ„зңјзқӣжҳҜйӣӘдә®зҡ„пјҢжҲ‘жғіиҝ‘жңҹзҡ„PulsarзҒ«зғӯпјҢд№ҹжҳҜдёҺе®ғж»Ўи¶ідәҶеёӮеңәдёҠиҝҷж–№йқўдёҡеҠЎйңҖжұӮжңүе…ізі»гҖӮдёҚиҝҮпјҢеҰӮжһңжҠҠе®ғж”ҫзҪ®еңЁеӨ§ж•°жҚ®еңәжҷҜдёӢпјҢдёҠеҚғзҡ„TopicдёҠдёҮзҡ„Partitionж—¶пјҢиҝҷз§ҚеӨҡеүҜжң¬ж–№жЎҲе°ұйңҖиҰҒиҖ—иҙ№еӨ§йҮҸзҡ„жңәеҷЁиө„жәҗгҖӮжүҖд»ҘпјҢжҲ‘们TEGж•°жҚ®е№іеҸ°йғЁеҜ№дәҺй«ҳеҸҜйқ зҡ„ж•°жҚ®пјҢдҪҝз”Ёзҡ„жҳҜPulsarеҜ№еҶ…иҝӣиЎҢжңҚеҠЎпјӣеҗҢж—¶жҲ‘们д№ҹе°ҶжҲ‘们еҜ№Pulsarзҡ„ж”№иҝӣжҚҗзҢ®з»ҷзӨҫеҢәгҖӮ
TubeMQпјҡ е°ұеҰӮе…¶йҖӮз”ЁеңәжҷҜд»Ӣз»ҚпјҢTubeMQе°ұжҳҜдёәдәҶж»Ўи¶іеңЁе®№еҝҚжһҒз«Ҝжғ…еҶөдёӢе…Ғи®ёж•°жҚ®е°‘йҮҸдёўеӨұзҡ„дёҡеҠЎж•°жҚ®дёҠжҠҘз®ЎйҒ“йңҖжұӮпјҢз»“еҗҲдёҡеҠЎжҲҗжң¬гҖҒж•°жҚ®еҸҜйқ жҖ§зҡ„иҰҒжұӮиө°дәҶдёҖжқЎдёҚдёҖж ·зҡ„иҮӘз ”и·ҜпјҢй’ҲеҜ№иҮҙе‘ҪејӮеёёеңЁзі»з»ҹеҸҜйқ жҖ§дёҠд№ҹиҫҫеҲ°дәҶдёҚдёҖж ·зҡ„ж•Ҳжһңпјҡ
еҸӘиҰҒTopicеҲҶй…Қзҡ„BrokerйӣҶеҗҲйҮҢиҝҳжңүд»»ж„ҸдёҖеҸ°Brokerеӯҳжҙ»пјҢиҜҘTopicзҡ„еҜ№еӨ–жңҚеҠЎйғҪеҸҜз”Ёпјӣ
еҹәдәҺ第1зӮ№пјҢеҸӘиҰҒйӣҶзҫӨйҮҢжүҖжңүзҡ„TopicйғҪиҝҳжңүд»»ж„ҸдёҖеҸ°Brokerеӯҳжҙ»пјҢж•ҙдёӘйӣҶзҫӨзҡ„TopicеҜ№еӨ–жңҚеҠЎйғҪжҳҜеҸҜз”Ёпјӣ
еҚідҪҝз®ЎжҺ§иҠӮзӮ№Masterе…ЁйғЁжҢӮжҺүпјҢйӣҶзҫӨйҮҢж–°еўһзҡ„з”ҹдә§гҖҒж¶Ҳиҙ№дјҡеҸ—еҪұе“ҚпјҢдҪҶе·ІжіЁеҶҢдәҶзҡ„з”ҹдә§гҖҒж¶Ҳиҙ№дёҚеҸ—еҪұе“ҚпјҢд»ҚеҸҜ继з»ӯз”ҹдә§е’Ңж¶Ҳиҙ№пјӣ
TubeMQеҹәдәҺжңүжҚҹжңҚеҠЎзҡ„еүҚжҸҗдёӢйҮҮз”Ёе°ҪеҸҜиғҪдҝқиҜҒж•°жҚ®дёҚдёўгҖҒжңҚеҠЎдёҚеҸ—йҳ»зҡ„жҖқи·ҜиҝӣиЎҢи®ҫи®ЎпјҢеҠӣжұӮж–№жЎҲз®ҖеҚ•з»ҙжҠӨз®ҖдҫҝпјҡTubeMQзҡ„и®ҫи®ЎйҮҢпјҢеҲҶеҢәж•…йҡң并дёҚеҪұе“ҚTopicзҡ„ж•ҙдҪ“еҜ№еӨ–жңҚеҠЎпјҢеҸӘиҰҒTopicжңүдёҖдёӘеҲҶеҢәеӯҳжҙ»пјҢж•ҙдҪ“зҡ„еҜ№еӨ–жңҚеҠЎе°ұдёҚдјҡеҸ—йҳ»пјӣTubeMQзҡ„ж•°жҚ®ж—¶е»¶P99еҸҜд»ҘеҒҡеҲ°жҜ«з§’зә§пјҢиҝҷж ·дҝқиҜҒдәҶдёҡеҠЎеҸҜд»Ҙе°ҪеҸҜиғҪеҝ«зҡ„ж¶Ҳиҙ№е®Ңж•°жҚ®пјҢеҒҡеҲ°е°ҪеҸҜиғҪдёҚдёўпјӣTubeMQзӢ¬жңүзҡ„ж•°жҚ®еӯҳеӮЁж–№жЎҲи®ҫи®ЎжҖ§иғҪиҰҒжҜ”Kafkaзҡ„TPSиҮіе°‘й«ҳеҮә50%д»ҘдёҠпјҲжңүдәӣжңәеһӢдёҠиҝҳжҳҜзҝ»еҖҚзҡ„ж•ҲжһңпјүпјҢеҗҢж—¶еҖҹеҠ©еӯҳеӮЁж–№жЎҲзҡ„дёҚеҗҢпјҢеҚ•жңәе®№зәізҡ„Topicж•°е’ҢеҲҶеҢәж•°жӣҙеӨҡпјҢиҝӣиҖҢеҸҜд»ҘдҪҝеҫ—йӣҶзҫӨ规模жӣҙеӨ§пјҢеҮҸе°‘з»ҙжҠӨжҲҗжң¬гҖӮиҝҷдәӣдёҚдёҖж ·зҡ„иҖғиҷ‘е’Ңе®һзҺ°з»“еҗҲиө·жқҘд»ҺиҖҢдҪҝеҫ—TubeMQеҒҡеҲ°дҪҺжҲҗжң¬пјҢй«ҳжҖ§иғҪпјҢй«ҳзЁіе®ҡжҖ§еҹәзЎҖгҖӮ
е…ідәҺвҖңеҰӮдҪ•еҲҶжһҗApache TubeMQж•°жҚ®еҸҜйқ жҖ§вҖқе°ұд»Ӣз»ҚеҲ°иҝҷдәҶ,жӣҙеӨҡзӣёе…іеҶ…е®№еҸҜд»ҘжҗңзҙўдәҝйҖҹдә‘д»ҘеүҚзҡ„ж–Үз« пјҢеёҢжңӣиғҪеӨҹеё®еҠ©еӨ§е®¶зӯ”з–‘и§Јжғ‘пјҢиҜ·еӨҡеӨҡж”ҜжҢҒдәҝйҖҹдә‘зҪ‘з«ҷпјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ