жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬зҜҮеҶ…е®№д»Ӣз»ҚдәҶвҖңKafkaз”ҹдә§иҖ…дёҺеҸҜйқ жҖ§дҝқиҜҒACKзҡ„ж–№жі•жңүе“ӘдәӣвҖқзҡ„жңүе…ізҹҘиҜҶпјҢеңЁе®һйҷ…жЎҲдҫӢзҡ„ж“ҚдҪңиҝҮзЁӢдёӯпјҢдёҚе°‘дәәйғҪдјҡйҒҮеҲ°иҝҷж ·зҡ„еӣ°еўғпјҢжҺҘдёӢжқҘе°ұи®©е°Ҹзј–еёҰйўҶеӨ§е®¶еӯҰд№ дёҖдёӢеҰӮдҪ•еӨ„зҗҶиҝҷдәӣжғ…еҶөеҗ§пјҒеёҢжңӣеӨ§е®¶д»”з»Ҷйҳ…иҜ»пјҢиғҪеӨҹеӯҰжңүжүҖжҲҗпјҒ
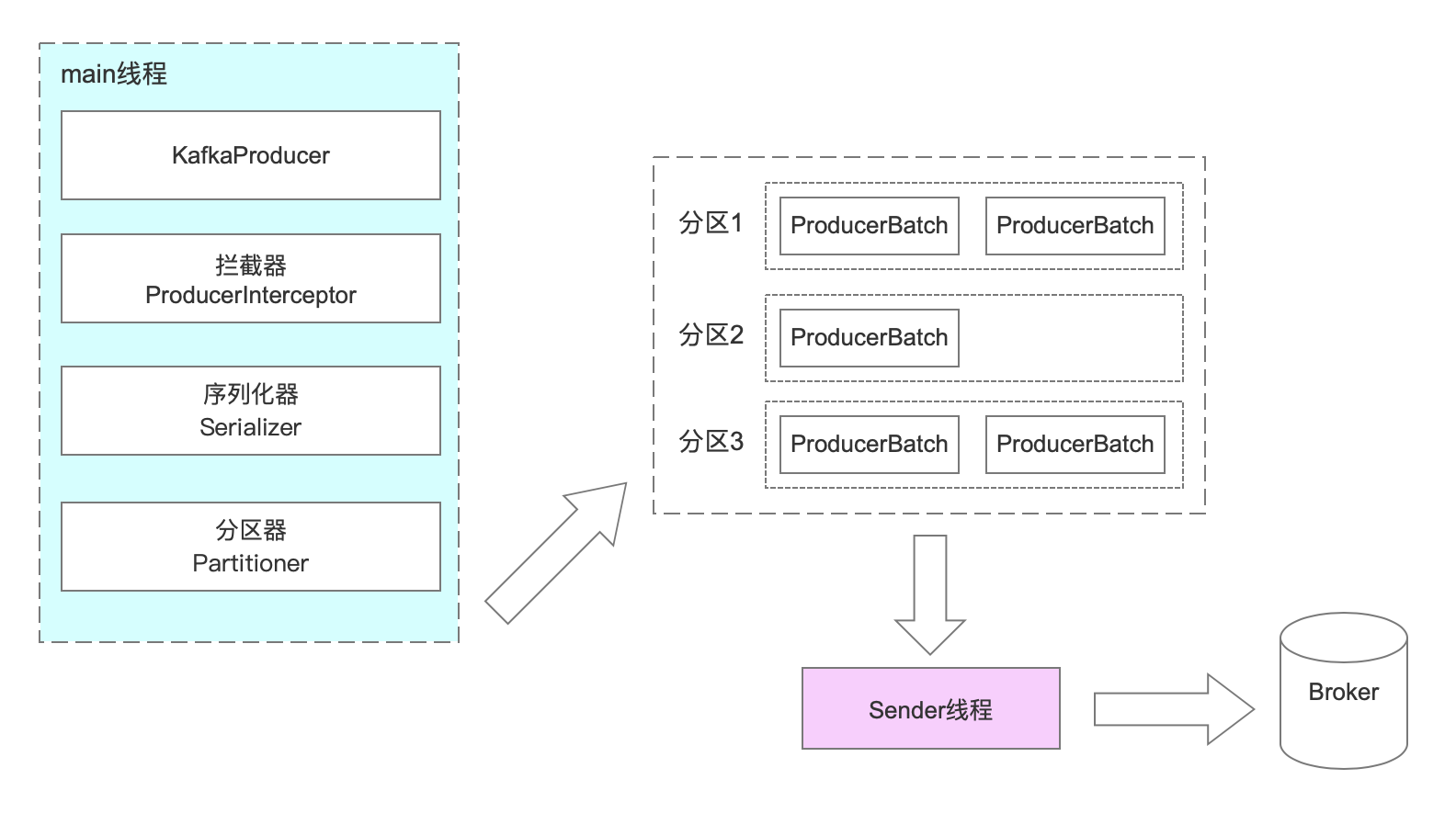
ж¶ҲжҒҜеҸ‘йҖҒзҡ„ж•ҙдҪ“жөҒзЁӢпјҢз”ҹдә§з«Ҝдё»иҰҒз”ұдёӨдёӘзәҝзЁӢеҚҸи°ғиҝҗиЎҢгҖӮеҲҶеҲ«жҳҜmainзәҝзЁӢе’ҢsenderзәҝзЁӢпјҲеҸ‘йҖҒзәҝзЁӢпјүгҖӮ
еңЁKafkaпјҲ2.6.0зүҲжң¬пјүжәҗз ҒдёӯпјҢеҸҜд»ҘзңӢеҲ°гҖӮ
жәҗз Ғең°еқҖпјҡ kafka\clients\src\main\java\org.apache.kafka.clients.producer.KafkaProducer.java жөӢиҜ•е…ҘеҸЈпјҡ KafkaProducerTest.testInvalidGenerationIdAndMemberIdCombinedInSendOffsets()
еңЁеҲӣе»әKafkaProducerж—¶пјҢеңЁ430еҲӣе»әдәҶдёҖдёӘSenderеҜ№иұЎпјҢ并且еҗҜеҠЁдәҶдёҖдёӘIOзәҝзЁӢгҖӮ
this.errors = this.metrics.sensor("errors");
this.sender = newSender(logContext, kafkaClient, this.metadata);
String ioThreadName = NETWORK_THREAD_PREFIX + " | " + clientId;
this.ioThread = new KafkaThread(ioThreadName, this.sender, true);
this.ioThread.start();interceptorзҡ„дҪңз”ЁжҳҜе®һзҺ°ж¶ҲжҒҜзҡ„е®ҡеҲ¶еҢ–пјҢзұ»дјјпјҡspring Interceptor гҖҒMyBatisзҡ„жҸ’件гҖҒQuartzзҡ„зӣ‘еҗ¬еҷЁгҖӮ
@Override
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {
// intercept the record, which can be potentially modified; this method does not throw exceptions
ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record);
return doSend(interceptedRecord, callback);
}еҸҜйҖҡиҝҮе®һзҺ°org.apache.kafka.clients.producer.ProducerInterceptorжҺҘеҸЈејҖеҸ‘иҮӘе®ҡд№үеҷЁгҖӮ
з®ҖеҚ•иҮӘе®ҡд№үдҫӢеӯҗпјҡ
public class CustomInterceptor implements ProducerInterceptor<String, String> {
// еҸ‘йҖҒж¶ҲжҒҜж—¶и§ҰеҸ‘
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
System.out.println("еҸ‘йҖҒж¶ҲжҒҜж—¶и§ҰеҸ‘");
return record;
}
// 收еҲ°жңҚеҠЎз«Ҝзҡ„ACKж—¶и§ҰеҸ‘
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
System.out.println("ж¶ҲжҒҜиў«жңҚеҠЎз«ҜжҺҘ收");
}
@Override
public void close() {
System.out.println("з”ҹдә§иҖ…е…ій—ӯ");
}
// з”Ёй”®еҖјеҜ№й…ҚзҪ®ж—¶и§ҰеҸ‘
@Override
public void configure(Map<String, ?> configs) {
System.out.println("configure...");
}
}
// з”ҹдә§иҖ…дёӯж·»еҠ
List<String> interceptors = new ArrayList<>();
interceptors.add("com.freecloud.plug.kafka.interceptor.CustomInterceptor");
props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, interceptors);byte[] serializedKey;
try {
serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert key of class " + record.key().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG).getName() +
" specified in key.serializer", cce);
}
byte[] serializedValue;
try {
serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert value of class " + record.value().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG).getName() +
" specified in value.serializer", cce);
}
еңЁkafkaй’ҲеҜ№дёҚеҗҢзҡ„ж•°жҚ®зұ»еһӢеҒҡдәҶзӣёеә”зҡ„еәҸеҲ—еҢ–е·Ҙе…·гҖӮеҰӮйңҖиҮӘе®ҡд№үе®һзҺ°org.apache.kafka.common.serialization.SerializerжҺҘеҸЈгҖӮ
int partition = partition(record, serializedKey, serializedValue, cluster);
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey, serializedValue, headers, interceptCallback, remainingWaitMs, true, nowMs);
// RecordAccumulatorжң¬иҙЁжҳҜдёҖдёӘConcurrentMapпјҡ
private final ConcurrentMap<TopicPartition, Deque<ProducerBatch>> batches;
дёҖдёӘpartitionдёҖдёӘBatchгҖӮbatchж»ЎдәҶд№ӢеҗҺпјҢдјҡе”ӨйҶ’SenderзәҝзЁӢеҸ‘йҖҒж¶ҲжҒҜгҖӮ
if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);
this.sender.wakeup();
}з”ҹдә§иҖ…еҸ‘йҖҒдёҖжқЎж¶ҲжҒҜеҲ°жңҚеҠЎеҷЁеҰӮдҪ•зЎ®дҝқжңҚеҠЎеҷЁж”¶еҲ°ж¶ҲжҒҜпјҹеҰӮжһңеңЁеҸ‘йҖҒиҝҮзЁӢдёӯзҪ‘з»ңеҮәдәҶй—®йўҳпјҢжҲ–иҖ…kafkaжңҚеҠЎеҷЁжҺҘ收зҡ„ж—¶еҖҷеҮәдәҶй—®йўҳпјҢиҝҷдёӘж¶ҲжҒҜеҸ‘йҖҒеӨұиҙҘдәҶпјҢз”ҹдә§иҖ…жҳҜдёҚзҹҘйҒ“зҡ„гҖӮ
жүҖд»ҘkafkaжңҚеҠЎз«ҜйңҖиҰҒдҪҝз”ЁдёҖз§Қе“Қеә”е®ўжҲ·з«Ҝзҡ„ж–№ејҸпјҢеҸӘжңүеңЁжңҚеҠЎз«ҜзЎ®и®Өд»ҘеҗҺпјҢз”ҹдә§иҖ…жүҚеҸ‘дёҖдёӢжқЎж¶ҲжҒҜпјҢеҗҰеҲҷйҮҚж–°еҸ‘йҖҒж•°жҚ®гҖӮ
йӮЈд»Җд№Ҳж—¶еҖҷжүҚз®—жҺҘ收жҲҗеҠҹпјҹеӣ дёәж¶ҲжҒҜеӯҳеӮЁеңЁдёҚеҗҢзҡ„brokerйҮҢпјҢжүҖд»ҘжҳҜеңЁеҶҷе…ҘеҲ°зЈҒзӣҳд№ӢеҗҺе“Қеә”з”ҹдә§иҖ…гҖӮ
еңЁеҲҶеёғејҸеңәжҷҜдёӯпјҢеҸӘжңүдёҖдёӘbrokerеҶҷе…ҘжҲҗеҠҹиҝҳжҳҜдёҚеӨҹзҡ„пјҢеҰӮжһңжңүеӨҡдёӘеүҜжң¬пјҢfollowerд№ҹиҰҒеҶҷе…ҘжҲҗеҠҹжүҚиЎҢгҖӮ
жңҚеҠЎз«ҜеҸ‘йҖҒACKз»ҷз”ҹдә§иҖ…дёҖиҲ¬жңүд»ҘдёӢеҮ з§Қзӯ–з•ҘгҖӮ
еҸӘиҰҒleaderжҲҗеҠҹжҺҘ收е°ұеҸҜд»ҘпјҢдјҡдә§з”ҹеүҜжң¬дёҺleaderдёҚдёҖиҮҙжғ…еҶөпјҢеҰӮжһңleaderеҮәй—®йўҳеҸҜиғҪдјҡеҮәзҺ°ж•°жҚ®дёўеӨұйЈҺйҷ©гҖӮе®ўжҲ·з«Ҝзӯүеҫ…ж—¶й—ҙжңҖзҹӯгҖӮ
йңҖиҰҒеҚҠж•°д»ҘдёҠзҡ„followerиҠӮзӮ№е®ҢжҲҗеҗҢжӯҘпјҢиҝҷз§Қж–№ејҸе®ўжҲ·з«Ҝзӯүеҫ…зҡ„ж—¶й—ҙжҜ”дёҠиҫ№зЁҚй•ҝдёҖзӮ№пјҢдҪҶеҸҜд»ҘзЎ®дҝқеӨ§йғЁеҲҶеңәжҷҜдёҚеҮәй—®йўҳгҖӮ
йңҖиҰҒжүҖжңүfollwerе…ЁйғЁе®ҢжҲҗеҗҢжӯҘпјҢе®ўжҲ·з«Ҝзӯүеҫ…ж—¶й—ҙжңҖй•ҝпјҢдҪҶеҰӮжһңиҠӮзӮ№жҢӮжҺүзҡ„еҪұе“ҚзӣёеҜ№жқҘиҜҙжңҖе°ҸпјҢеӣ дёәжүҖжңүиҠӮзӮ№зҡ„ж•°жҚ®йғҪжҳҜе®Ңж•ҙзҡ„гҖӮ
kafkaзҡ„ACKеә”зӯ”жңәеҲ¶е°ұдҪҝз”ЁдәҶд»ҘдёҠдёүз§Қж–№ејҸгҖӮеҸҜд»ҘйҖҡиҝҮй…ҚзҪ®acksеҸӮж•°иҝӣиЎҢй…ҚзҪ®гҖӮ
дёҠиҫ№з¬¬дёүз§Қж–№ејҸеҰӮжһңдҝқиҜҒжүҖжңүfollowerеҗҢжӯҘж•°жҚ®жҲҗеҠҹпјҹ
еҒҮи®ҫleaderжҺҘ收еҲ°ж•°жҚ®пјҢжүҖжңүfollowerйғҪејҖе§ӢеҗҢжӯҘж•°жҚ®пјҢдҪҶжҳҜжңүдёҖдёӘfollowerеҮәдәҶй—®йўҳпјҢжІЎеҠһжі•д»ҺleaderеҗҢжӯҘж•°жҚ®пјҢжҢүиҝҷдёӘ规еҲҷпјҢleaderе°ұиҰҒдёҖзӣҙзӯүеҫ…пјҢж— жі•иҝ”еӣһackпјҢжҲҗдәҶе®ізҫӨд№Ӣ马гҖӮ
жүҖд»ҘжҲ‘们иҜҘеҰӮжһңи§ЈеҶіиҝҷдёӘй—®йўҳе‘ўпјҹжҺҘдёӢжқҘжҲ‘们жҠҠ规еҲҷдҝ®ж”№дёҖдёӢпјҢдёҚжҳҜжүҖжңүfollowerйғҪжңүжқғеҲ©и®©leaderзӯүеҫ…пјҢиҖҢжҳҜеҸӘжңүйӮЈдәӣжӯЈеёёе·ҘдҪңзҡ„followerеҗҢжӯҘж•°жҚ®зҡ„ж—¶еҖҷжүҚдјҡзӯүеҫ…гҖӮ
жҠҠйӮЈдәӣжӯЈеёёе’ҢleaderдҝқжҢҒеҗҢжӯҘзҡ„еүҜжң¬з»ҙжҠӨиө·жқҘпјҢж”ҫеҲ°дёҖдёӘеҠЁжҖҒsetйҮҢпјҢиҝҷдёӘе°ұеҸ«еҒҡin-sync replica set (ISR)гҖӮеҸӘиҰҒISRйҮҢйқўзҡ„followerеҗҢжӯҘе®Ңж•°жҚ®д№ӢеҗҺпјҢе°ұеҸҜд»Ҙз»ҷе®ўжҲ·з«ҜеҸ‘йҖҒACKгҖӮ
еҜ№дәҺз»ҸеёёеҮәй—®йўҳзҡ„followerеҸҜд»Ҙи®ҫе®ҡreplica.lag.time.max.ms=30пјҲй»ҳи®Ө30з§’пјүпјҢеҰӮжһңи¶…иҝҮй…ҚзҪ®ж—¶й—ҙжүҚдјҡд»Һisrдёӯеү”йҷӨгҖӮ
| еҸӮж•° | иҜҙжҳҺ |
|---|---|
| acks = 0 | ProducerдёҚзӯүеҫ…brokerзҡ„ackпјҢbrokderдёҖжҺҘ收еҲ°иҝҳжІЎеҶҷе…ҘзЈҒзӣҳе°ұиҝ”еӣһпјҢеҪ“brokderж•…йҡңж—¶жңүеҸҜиғҪдёўеӨұж•°жҚ®пјӣ |
| acks = 1 | Producerзӯүеҫ…brokderзҡ„ackпјҢpartitionзҡ„leaderжҲҗеҠҹиҗҪзӣҳеҗҺиҝ”еӣһackпјҢеҰӮжһңеңЁfollowerеҗҢжӯҘжҲҗеҠҹеүҚleaderж•…йҡңпјҢе°ҶдјҡдёўеӨұж•°жҚ®пјӣ |
| acks = -1 | producerзӯүеҫ…brokderзҡ„ackпјҢpartitionзҡ„leaderе’Ңfollowerе…ЁйғЁжҲҗеҠҹиҗҪзӣҳеҗҺжүҚиҝ”еӣһackпјӣ |
д»ҘдёҠдёүз§ҚжңәеҲ¶жҖ§иғҪдҫқж¬ЎйҖ’еҮҸпјҲproducerеҗһеҗҗйҮҸйҷҚдҪҺпјүпјҢж•°жҚ®еҒҘеЈ®жҖ§еҲҷдҫқж¬ЎйҖ’еўһгҖӮе®һйҷ…ејҖеҸ‘дёӯеҸҜж №жҚ®дёҚеҗҢеңәжҷҜйҖүжӢ©дёҚеҗҢзҡ„зӯ–з•ҘгҖӮ
вҖңKafkaз”ҹдә§иҖ…дёҺеҸҜйқ жҖ§дҝқиҜҒACKзҡ„ж–№жі•жңүе“ӘдәӣвҖқзҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢдәҶпјҢж„ҹи°ўеӨ§е®¶зҡ„йҳ…иҜ»гҖӮеҰӮжһңжғідәҶи§ЈжӣҙеӨҡиЎҢдёҡзӣёе…ізҡ„зҹҘиҜҶеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–е°ҶдёәеӨ§е®¶иҫ“еҮәжӣҙеӨҡй«ҳиҙЁйҮҸзҡ„е®һз”Ёж–Үз« пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ