您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要讲解了“Flink任务调优的方法是什么”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Flink任务调优的方法是什么”吧!
Flink 提供的 Metrics 可以在 Flink 内部收集一些指标,通过这些指标让开发人员更好地理解作业或集群的状态。由于集群运行后很难发现内部的实际状况,跑得慢或快,是否异常等,开发人员无法实时查看所有的 Task 日志,比如作业很大或者有很多作业的情况下,该如何处理?此时 Metrics 可以很好的帮助开发人员了解作业的当前状况。
我们通过上述的指标定位问题时,基本可以通过延迟与吞吐指标可以对任务的性能进行精准的判断,精确的找到问题发生的代码位置。 一般这些位置会出现以下错误:
Operator的并发数(parallelism)不合理
CPU(core)不合理
堆内存(heap_memory)等参数设置不合理
并行度的设置不合理
State的设置不合理
checkpoint的设置不合理
我们在设置这些参数时要注意:
并行度(parallelism):保证足够的并行度,并行度也不是越大越好,太多会加重数据在多个solt/task manager之间数据传输压力,包括序列化和反序列化带来的压力。
CPU:CPU资源是task manager上的solt共享的,注意监控CPU的使用。
内存:内存是分solt隔离使用的,注意存储大state的时候,内存要足够。
网络:大数据处理,flink节点之间数据传输会很多,服务器网卡尽量使用万兆网卡。
Flink 内部是基于 producer-consumer 模型来进行消息传递的,Flink的反压设计也是基于这个模型。Flink 使用了高效有界的分布式阻塞队列,就像 Java 通用的阻塞队列(BlockingQueue)一样。下游消费者消费变慢,上游就会受到阻塞。
在实践中,很多情况下的反压是由于数据倾斜造成的,这点我们可以通过 Web UI 各个 SubTask 的 Records Sent 和 Record Received 来确认,另外 Checkpoint detail 里不同 SubTask 的 State size 也是一个分析数据倾斜的有用指标。
Flink 1.11 版本中对于 Flink 反压问题本身做了一些优化,例如使用Unaligned Checkpoint + rocksdb生成Checkpoint,使用rocksdb缓存checkpoint, 并且从原来的全量生成改为增量生成的方式, 速度更快。
另外还需要注意的是,用户代码的执行效率问题(频繁被阻塞或者性能问题)和TaskManager 的内存以及 GC 问题。
官网给出的参数如下:
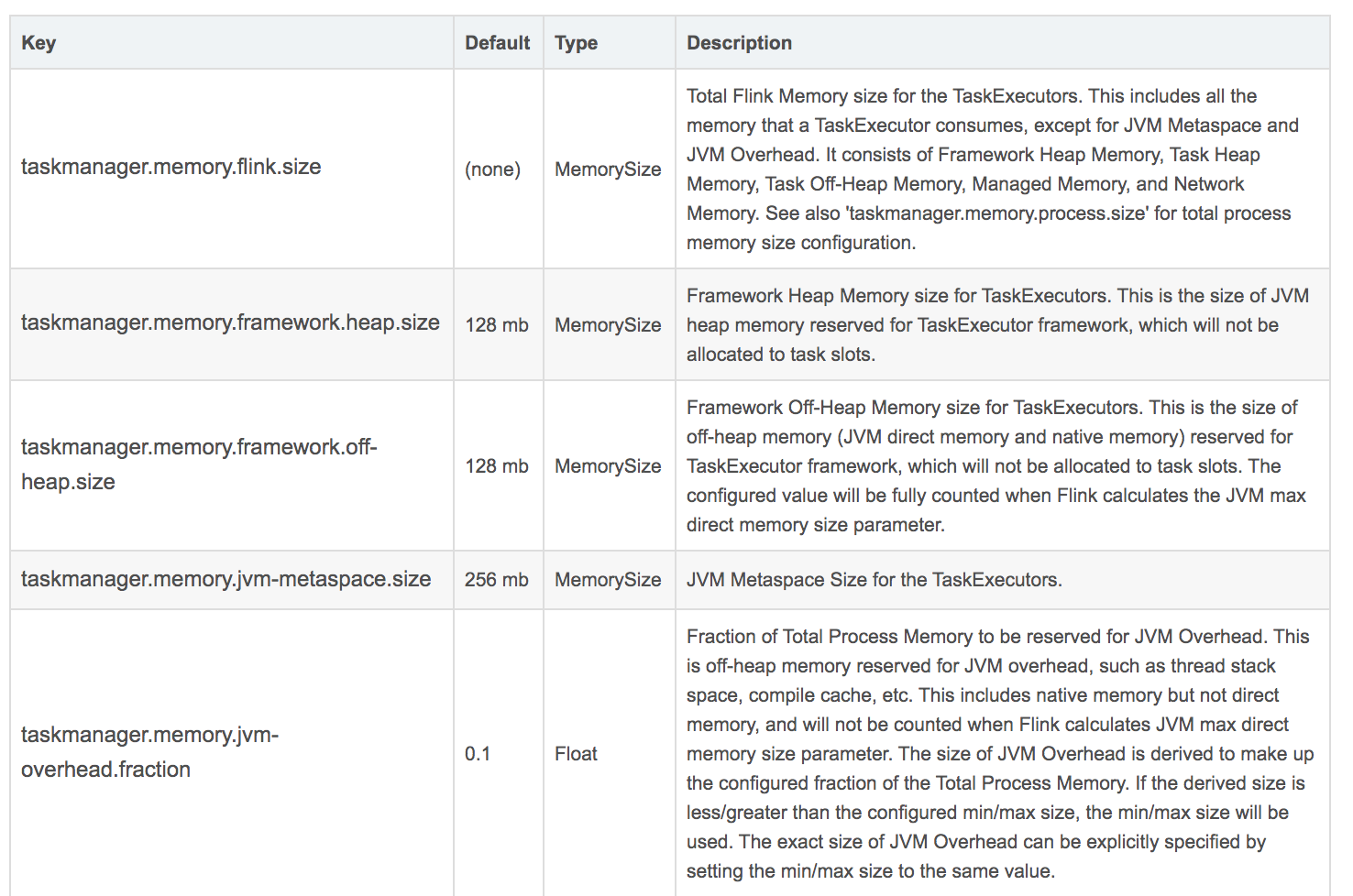
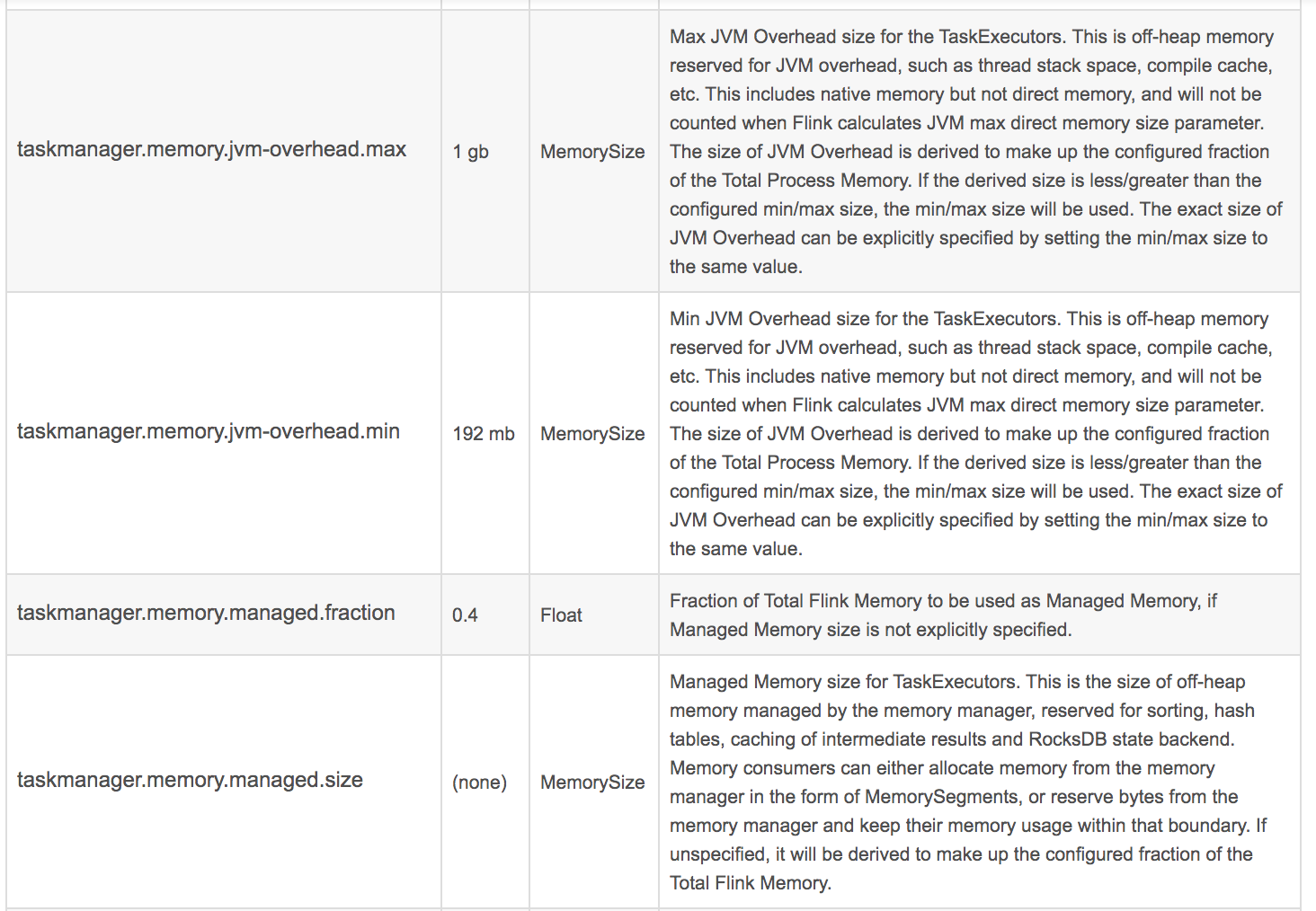
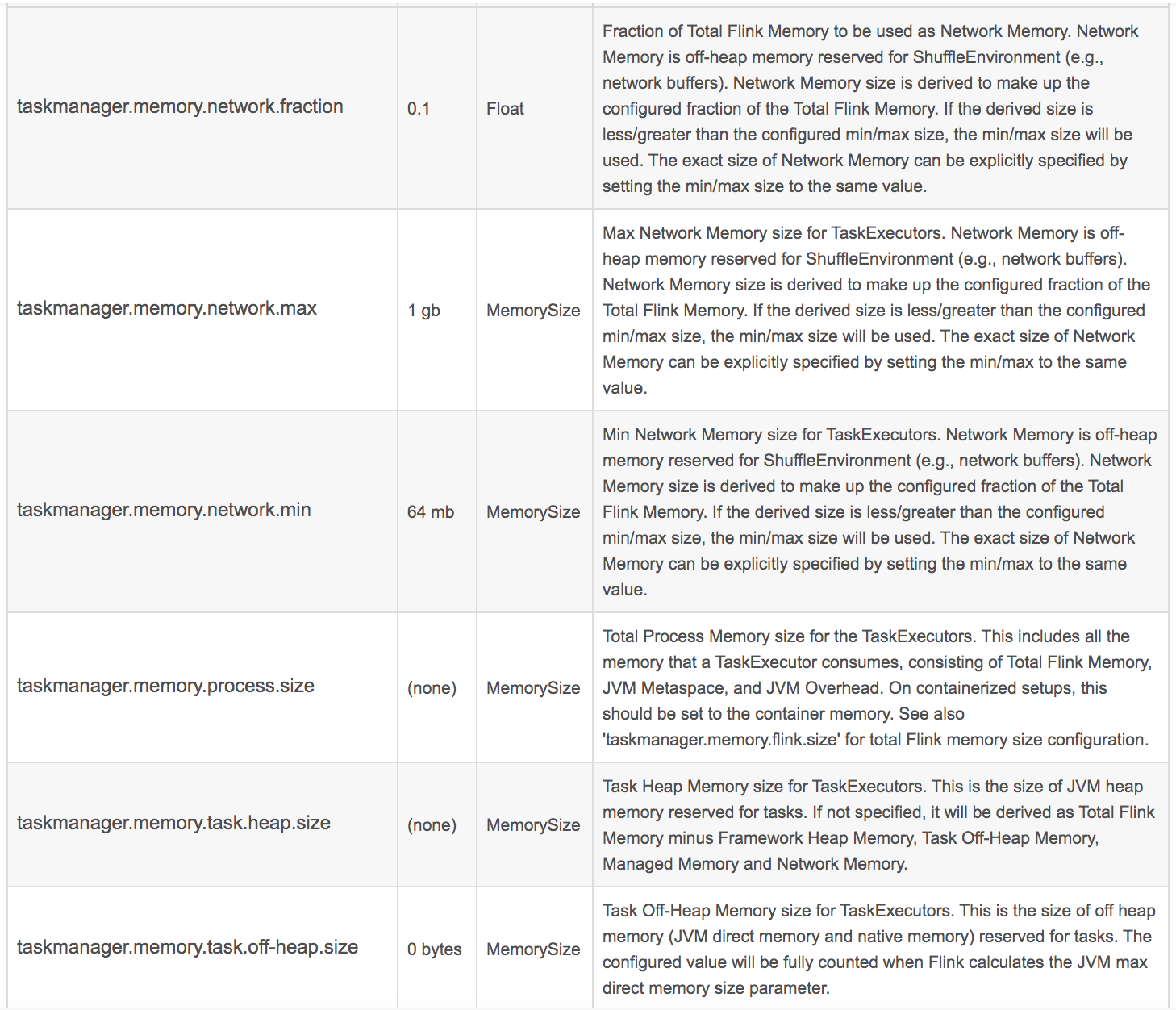
这里面最重要的几个:
taskmanager.memory.process.size: 512m taskmanager.memory.framework.heap.size: 64m taskmanager.memory.framework.off-heap.size: 64m taskmanager.memory.jvm-metaspace.size: 64m taskmanager.memory.jvm-overhead.fraction: 0.2 taskmanager.memory.jvm-overhead.min: 16m taskmanager.memory.jvm-overhead.max: 64m taskmanager.memory.network.fraction: 0.1 taskmanager.memory.network.min: 1mb taskmanager.memory.network.max: 256mb
他们各自的意思,需要大家去查询以下官方文档。
JVM本身配置的主要参数无非以下这些:
堆设置 -Xms :初始堆大小 -Xmx :最大堆大小 -XX:NewSize=n :设置年轻代大小 -XX:NewRatio=n: 设置年轻代和年老代的比值。如:为3,表示年轻代与年老代比值为1:3,年轻代占整个年轻代年老代和的1/4 -XX:SurvivorRatio=n :年轻代中Eden区与两个Survivor区的比值。注意Survivor区有两个。如:3,表示Eden:Survivor=3:2,一个Survivor区占整个年轻代的1/5 -XX:MaxPermSize=n :设置持久代大小 收集器设置 -XX:+UseSerialGC :设置串行收集器 -XX:+UseParallelGC :设置并行收集器 -XX:+UseParalledlOldGC :设置并行年老代收集器 -XX:+UseConcMarkSweepGC :设置并发收集器 垃圾回收统计信息 -XX:+PrintHeapAtGC GC的heap详情 -XX:+PrintGCDetails GC详情 -XX:+PrintGCTimeStamps 打印GC时间信息 -XX:+PrintTenuringDistribution 打印年龄信息等 -XX:+HandlePromotionFailure 老年代分配担保(true or false) 并行收集器设置 -XX:ParallelGCThreads=n :设置并行收集器收集时使用的CPU数。并行收集线程数。 -XX:MaxGCPauseMillis=n :设置并行收集最大暂停时间 -XX:GCTimeRatio=n :设置垃圾回收时间占程序运行时间的百分比。公式为1/(1+n) 并发收集器设置 -XX:+CMSIncrementalMode :设置为增量模式。适用于单CPU情况。 -XX:ParallelGCThreads=n :设置并发收集器年轻代收集方式为并行收集时,使用的CPU数。并行收集线程数
我们可以利用一些简单的JVM日志分析工具看出JVM设置的参数问题出在哪里。
感谢各位的阅读,以上就是“Flink任务调优的方法是什么”的内容了,经过本文的学习后,相信大家对Flink任务调优的方法是什么这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。