您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要讲解了“pyhon用.groupby()作分组运算实例代码”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“pyhon用.groupby()作分组运算实例代码”吧!
1. 构造数据源,小试一下牛刀
import pandas as pd
df = pd.DataFrame({"品类":["蔬菜","蔬菜","水果","水果","蔬菜","蔬菜","水果","水产","水产","水产"],
"数量":[10,20,30,40,50,60,70,80,90,100]})
df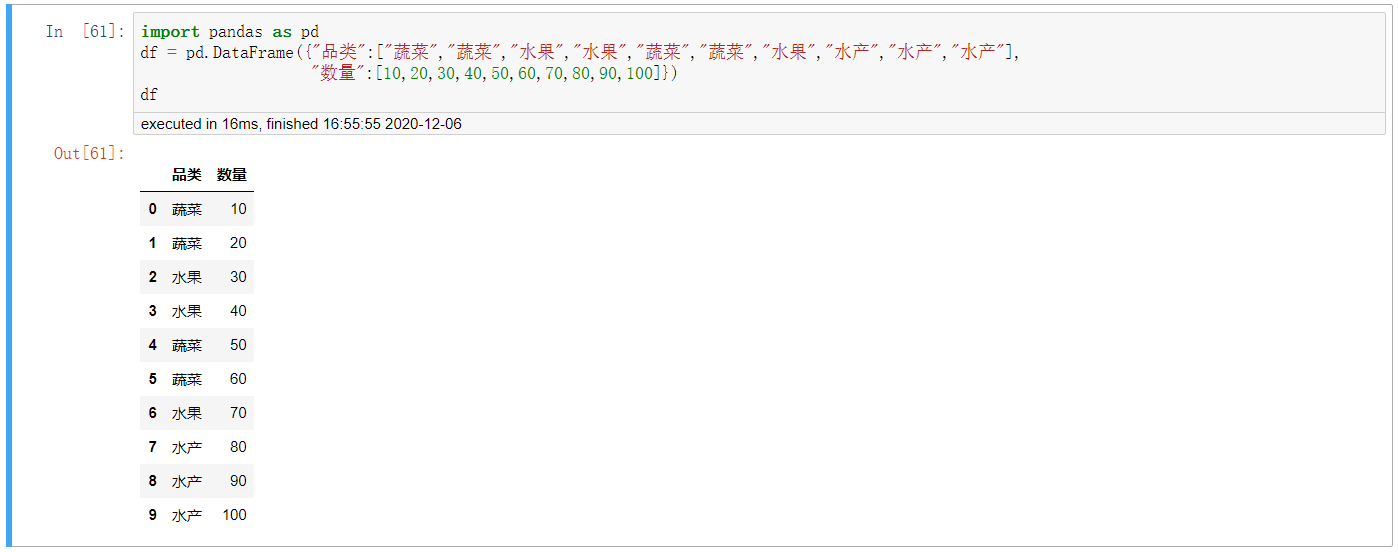
2. 实操,确认方法是否可行
df.sort_values(["品类", "数量"],ascending=[1,0],inplace=True) df_grouped = df.groupby(["品类"]).head(2) df_grouped
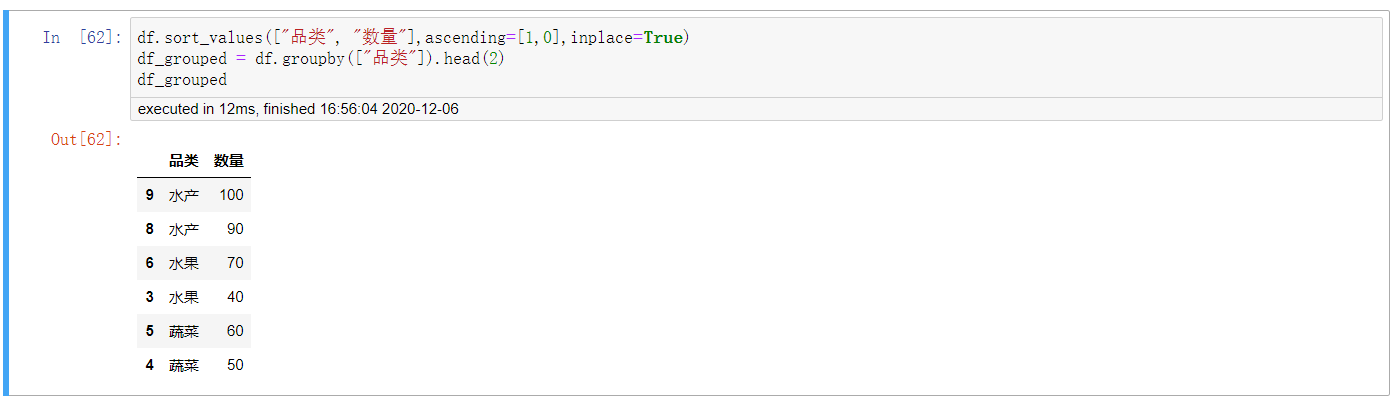
显然可行
2. 1 | 0,True or False,“真” 或 “假”
import pandas as pd
df1 = pd.DataFrame({"品类":["蔬菜","蔬菜","水果","水果","蔬菜","蔬菜","水果","水产","水产","水产"],
"数量":[10,20,30,40,50,60,70,80,90,100]})
df1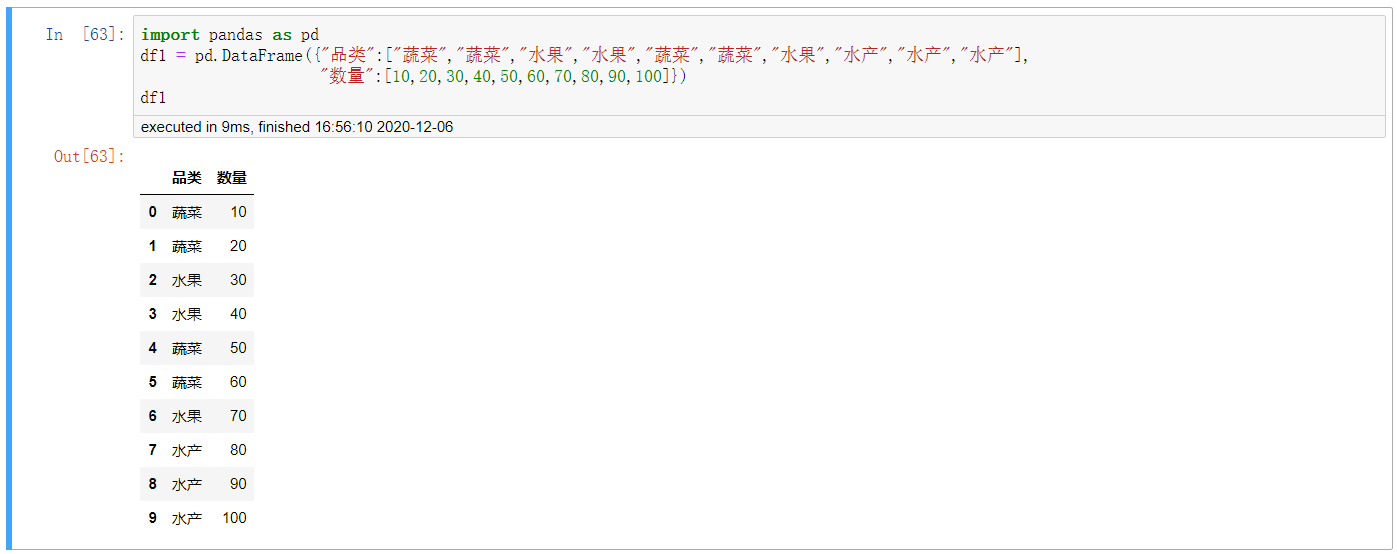
df.sort_values(["品类", "数量"],ascending=[True, False],inplace=True) df1_grouped = df.groupby(["品类"]).head(3) df1_grouped
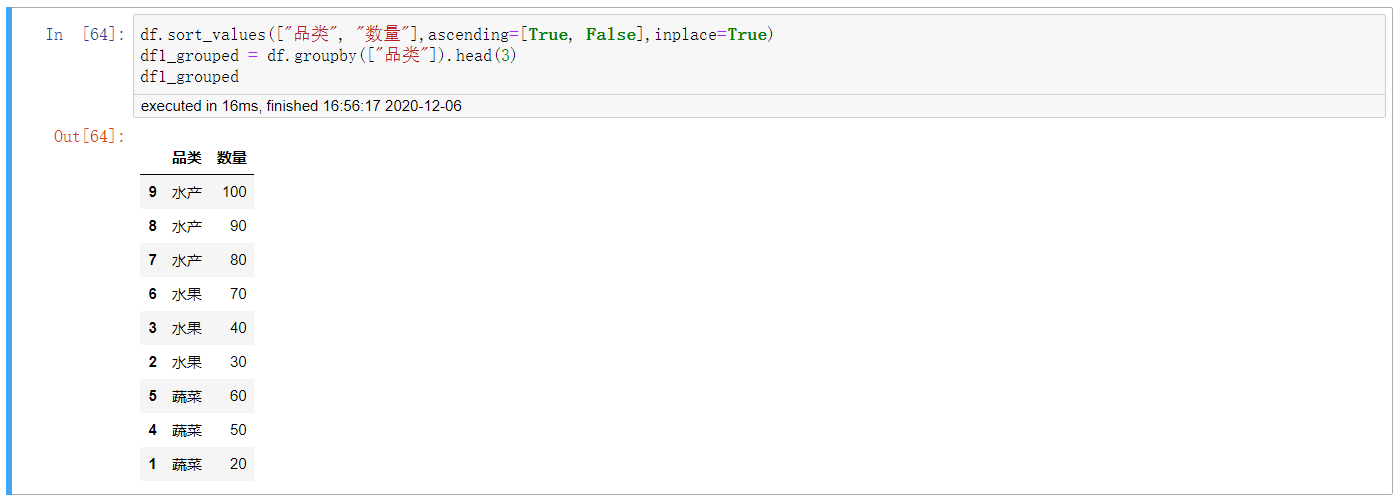
3. 再多加一点层次索引
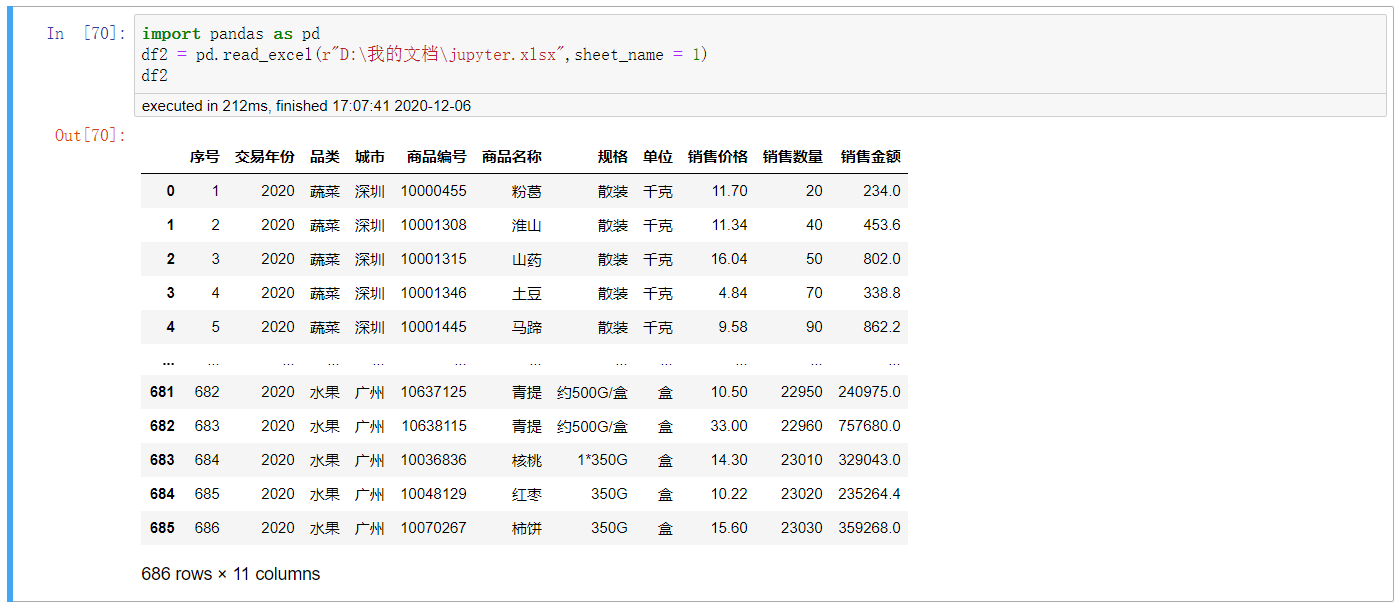
import pandas as pd df2 = pd.read_excel(r"D:\我的文档\jupyter.xlsx",sheet_name = 1) df2
df2.sort_values(["品类", "销售数量"],ascending=[True, False],inplace=True) df2_grouped = df2.groupby(["品类"]).head(3) df2_grouped
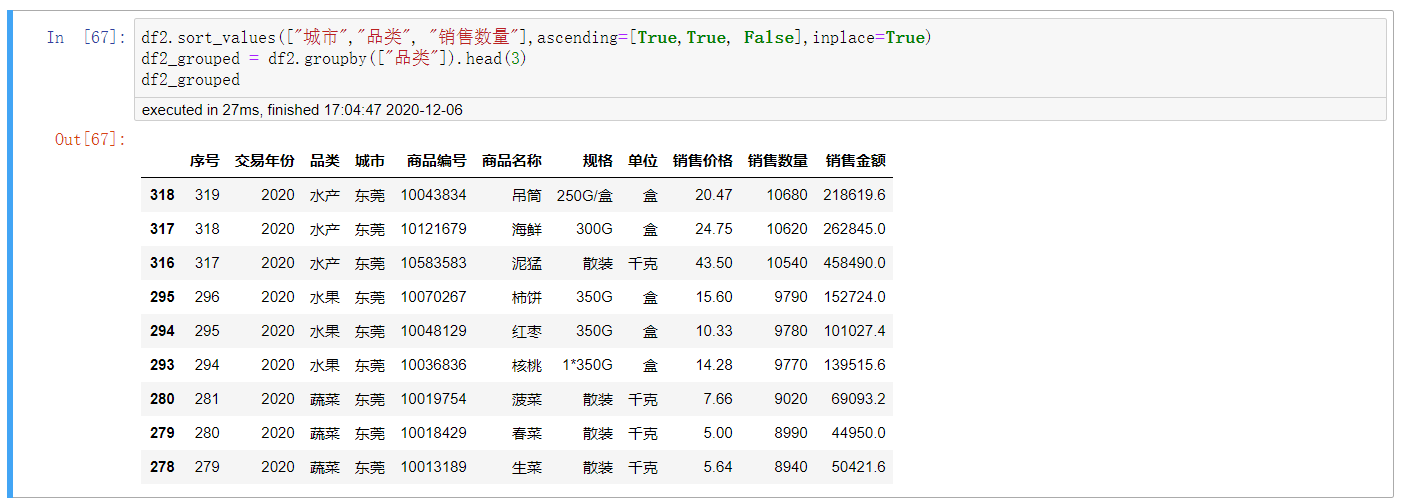
df2.sort_values(["城市","品类", "销售数量"],ascending=[True,True, False],inplace=True) df2_grouped = df2.groupby(["品类"]).head(3) df2_grouped
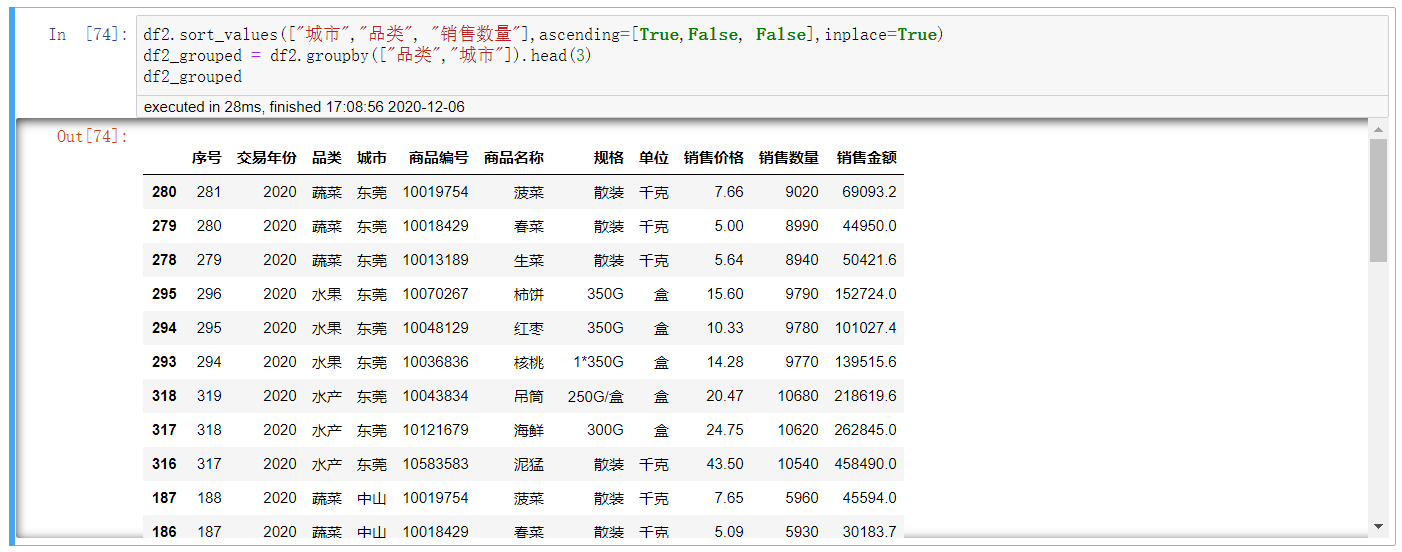
df2.sort_values(["城市","品类", "销售数量"],ascending=[True,False, False],inplace=True) df2_grouped = df2.groupby(["品类","城市"]).head(3) df2_grouped
感谢各位的阅读,以上就是“pyhon用.groupby()作分组运算实例代码”的内容了,经过本文的学习后,相信大家对pyhon用.groupby()作分组运算实例代码这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。