您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
网络分流器|基于复合存储的100Gbps DPI技术

(1)依靠更高性能的服务器或服务器集群来加速DPI吞吐量,由于在报文流上执行多机器或多核的负载均衡非常方便,这种方法很容易达到很高的处理性能,缺点是代价比较大。
(2)依靠更好的软件算法来提高匹配性能,目前研究界普通采用以AC算法作为基础来优化性能,主要有WU-MANBER、SBOM、一次多字节(俗称多步)、BloomFilter等方法,但是DPI过程要求的前后状态转移是关联的,即下一次访问的地址与上一次访问的状态和当前报文字节的内容紧密相关,受限于存储器本身(主要是DDR)的性能,软件优化的空间非常有限。
(3)依靠各种多核NPU自带的匹配引擎来加速,目前国外两大多核NPU巨头Broadcom和Cavium都有在其NPU上内置了DPI加速引擎,如Cavium内置的HFA引擎宣称其单个NPU可以达到24Gbps的处理能力,但是实测性能与宣称性能之间相差巨大。尤其是配置正则表达式规则时,带通配符的规则会对其性能造成十分显著的影响。
总是,虽然研究界和产业界都非常关注深度报文检测,当前DPI技术的技术发展仍然无法赶上相关应用领域的现实要求。
在深度报文检测(DPI)中,首先要将关键字或正则表达式特征编译成有限状态自动机(Finite State Automata,FSA),并将FSA的状态表配置在存储器中。匹配过程中,每处理报文的一个字节都需要至少一次查表,以获取下一次要访问的状态地址。匹配的速度取决于访存次数和每次访存的时延,而对于一个给定的报文,访存次数等于报文负载长度。因此要提高匹配的速度就需要尽量减少每次访存的时延。
在轻量级的网络下,网络链路速率低。如果规则数比较少,可以把每条规则编译成一个FSA,状态表配置在高速存储器中,以获得较高的匹配速度。然而,随着网络带宽的快速增加,10G比特的网络已经开始应用于园区网络中;规则的数目也增加到数百甚至上千条。将每条规则编译成单个FSA的方案已经无法满足性能需求。如果将所有规则编译成一个FSA,可能发生状态爆炸。状态表的规模可能超过数100G字节,远超过目前高速存储器的容量,只能配置在外部磁盘这样的低速存储器中,访存时延大大提高。
DPI技术的关键其实是访存的性能,尤其是随机访存的性能,如果能够设计一种存储结构,既能够支持很高的随机访问性能(如达到几十个Gbps以上),又能够有比较大的容量(如到几十兆的大小),则通过良好的状态表数据结构优化,使得状态表的访问能够相对聚集;然后对访存过程加以优化,如流水化访存、Bank交错、并行化访存等措施来进一步提高访问状态表的效率,则高性能的DPI是可以实现的。
湖南戎腾网络创新团队在国家自然科学基金的支持下,研究出来的高性能DPI技术,借鉴了计算机系统的Cache结构。在计算机系统中,由于局部性原理,可以用先进先出、最近最少使用等替换算法,使Cache有较高的命中率。但是在深度报文检测中,报文的内容却是完全随机的,难以预知下一个要处理的字节内容,会转向哪个状态。选择那些经常被访问的状态存储到高速存储器中是提高性能的关键。戎腾通过独有的马尔科夫预测技术,很好地解决了状态访问的预测问题。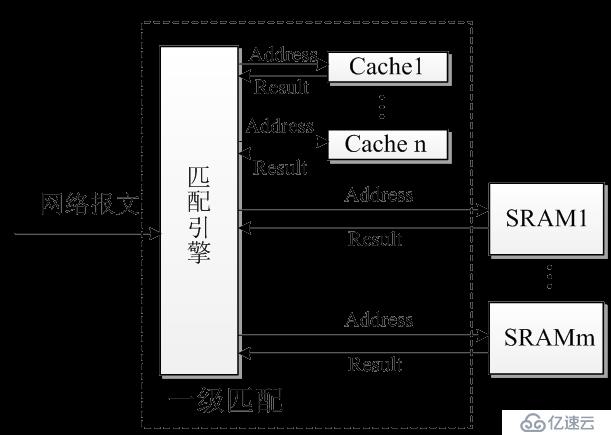
图1 复合存储匹配引擎
整个匹配引擎采用两层甚至三层,通过复合存储及并行和流水技术,解决性能和存储容量之间的矛盾,既能够通过一级匹配引擎的并行达到很高的性能,又能够通过二级存储达到大容量的状态表空间。这种结构既适合于关键字匹配,也适合于正则表达式匹配。
通过我们的分析,辅以软硬一体化流表技术,整体报文处理能力一般是核心匹配引擎4倍的性能。即如果核心匹配引擎能够达到n Gbps的性能,则整体报文处理能力就能够4n Gbps左右的性能,也就是说PET160S系统已经完成可以满足双向100Gbps以太网全带宽的关键字DPI能力,而CNT16S也可以满足实网条件下双向100Gbps以太网(实网条件下,上下行流量不会超过200Gbps*80%)的正则表达式DPI要求。
当前,正在研制基于PCI-E的DPI加速卡,可望于近期在单块PCI加速卡上实现40Gbps左右的关键字匹配性能和20Gbps的正则表达式匹配性能,以硬件加速卡的形式为防火墙、***检测系统、高速网络管控、CDN、运营商信令分析提供硬件加速。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。