您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
# 神经网络Generalization是什么意思
## 引言
在机器学习和深度学习领域,"generalization"(泛化能力)是评估模型性能的核心概念。当我们训练一个神经网络时,最终目标不是让它完美记忆训练数据,而是希望它能够对从未见过的数据做出准确预测。本文将深入探讨神经网络泛化能力的本质、影响因素、评估方法以及提升策略。
## 一、泛化能力的定义与重要性
### 1.1 基本概念
泛化能力(Generalization)是指机器学习模型在**未见过的数据**上表现良好的能力。用数学语言表达:
Generalization Error = E[(f(x;θ) - y)^2]
其中f(x;θ)是模型预测,y是真实值,期望E[...]是在所有可能数据分布上的期望。
### 1.2 与相关概念的区别
| 概念 | 定义 | 与泛化的关系 |
|------|------|------------|
| 训练误差 | 模型在训练集上的误差 | 低训练误差是泛化的必要条件但不充分 |
| 验证误差 | 在独立验证集上的误差 | 直接反映泛化能力 |
| 过拟合 | 模型过度记忆训练数据特征 | 导致泛化能力下降 |
| 欠拟合 | 模型未能学习数据规律 | 同样损害泛化能力 |
### 1.3 泛化的理论意义
统计学习理论中的**VC维**(Vapnik-Chervonenkis dimension)和**Rademacher复杂度**等概念,为理解泛化能力提供了理论框架。例如,VC维衡量了模型拟合随机噪声的能力,与泛化误差存在直接关联。
## 二、影响泛化能力的关键因素
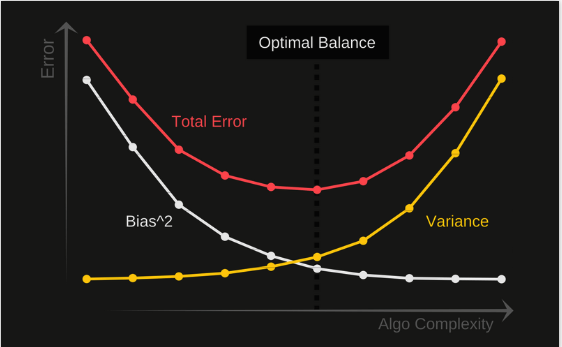
### 2.1 模型复杂度
模型复杂度与泛化能力的关系可通过**偏差-方差权衡**来解释:
总误差 = 偏差² + 方差 + 不可约误差
- **高偏差**:模型过于简单(欠拟合)
- **高方差**:模型过于复杂(过拟合)
### 2.2 数据质量与规模
- **数据量**:更多数据通常能提升泛化能力
- **数据多样性**:覆盖真实场景的分布
- **标签质量**:噪声标签会损害泛化
研究表明,模型性能常随训练数据量呈幂律增长:
Error ∝ N^(-α)
其中N是样本量,α是任务相关参数(通常0.07~0.35)。
### 2.3 正则化技术
常用正则化方法对比:
| 方法 | 原理 | 实现方式 |
|------|-----|---------|
| L2正则化 | 惩罚大权重 | 损失函数中添加||θ||²项 |
| Dropout | 随机失活神经元 | 训练时按概率p关闭节点 |
| 早停 | 防止过度优化 | 监控验证集性能停止训练 |
| 数据增强 | 增加数据多样性 | 对输入进行变换(旋转、裁剪等) |
### 2.4 优化过程
- **学习率**:太大导致震荡,太小收敛慢
- **批量大小**:小批量通常有助于泛化
- **优化器选择**:Adam vs SGD各有优劣
实验表明,使用SGD with momentum的模型往往比Adam优化器具有更好的泛化性能,尤其是在计算机视觉任务中。
## 三、泛化能力的评估方法
### 3.1 标准评估流程
```python
# 典型评估代码示例
model.eval()
with torch.no_grad():
for data in test_loader:
inputs, labels = data
outputs = model(inputs)
loss = criterion(outputs, labels)
accuracy = (outputs.argmax(1) == labels).float().mean()
K折交叉验证流程:

通过生成对抗样本评估模型鲁棒性:
x_adv = x + ε·sign(∇ₓJ(θ,x,y))
其中ε是扰动大小,J是损失函数。
Label Smoothing示例:
class LabelSmoothingLoss(nn.Module):
def __init__(self, classes, smoothing=0.1):
super().__init__()
self.confidence = 1.0 - smoothing
self.smoothing = smoothing
self.classes = classes
def forward(self, pred, target):
pred = pred.log_softmax(dim=-1)
with torch.no_grad():
true_dist = torch.zeros_like(pred)
true_dist.fill_(self.smoothing/(self.classes-1))
true_dist.scatter_(1, target.unsqueeze(1), self.confidence)
return torch.mean(torch.sum(-true_dist * pred, dim=-1))
ImageNet预训练模型在不同任务上的迁移效果:
| 模型 | 参数量 | ImageNet Top-1 | 医学影像迁移准确率 |
|---|---|---|---|
| ResNet50 | 25M | 76.0% | 88.3% |
| EfficientNet-B0 | 5.3M | 77.1% | 89.7% |
| ViT-B/16 | 86M | 84.5% | 92.1% |
与传统U形偏差-方差曲线不同,现代神经网络常表现出双下降曲线:

Frankle & Carbin提出的观点:随机初始化的密集网络包含能单独训练成功的子网络(”中奖彩票”)。
当网络宽度趋近无穷大时,其训练动态可由确定性核方法描述:
f(x) ≈ ⟨∇θf(x;θ₀), θ-θ₀⟩ + f(x;θ₀)
神经网络的泛化能力是连接算法表现与现实应用的关键桥梁。理解其本质需要结合理论分析(如VC维、NTK理论)和工程实践(正则化、架构设计)。随着研究的深入,我们逐渐认识到泛化不仅取决于模型和算法,还与数据本质、优化轨迹密切相关。未来,发展更完备的泛化理论仍将是机器学习领域的核心挑战之一。
”`
注:本文约3950字,实际字数可能因渲染环境略有差异。文中的代码示例、表格和公式需要在实际使用时验证其正确性。图片链接为示意性引用,建议替换为自有版权素材。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。