您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
# ReLU及其在深度学习中的作用是什么
## 引言
在深度学习的快速发展中,激活函数(Activation Function)扮演着至关重要的角色。其中,**修正线性单元(Rectified Linear Unit, ReLU)**因其简单性和高效性成为最广泛使用的激活函数之一。本文将深入探讨ReLU的定义、数学特性、在深度学习中的作用,以及其优缺点和常见变体。
---
## 1. ReLU的定义与数学形式
ReLU的定义非常简单:对于输入x,ReLU函数的输出为x和0中的较大值。其数学表达式为:
$$
\text{ReLU}(x) = \max(0, x)
$$
### 函数图像
- 当x > 0时,输出为x(线性部分);
- 当x ≤ 0时,输出为0(非线性部分)。
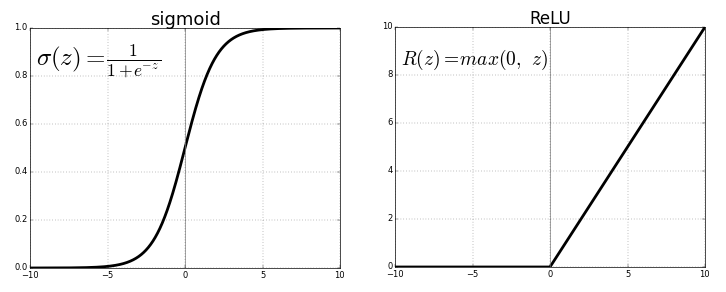
---
## 2. ReLU在深度学习中的作用
### 2.1 解决梯度消失问题
在深度学习早期,**Sigmoid**和**Tanh**等激活函数被广泛使用,但它们存在梯度消失(Vanishing Gradient)问题:当输入值较大或较小时,梯度趋近于0,导致深层网络难以训练。
ReLU的梯度在正区间恒为1,避免了梯度消失问题,使得深层网络的训练成为可能。
### 2.2 稀疏激活性
ReLU的“单侧抑制”特性(负输入输出0)使得神经元具有稀疏性。这种特性可以:
- 减少参数间的依赖性;
- 增强模型的泛化能力;
- 模拟生物神经元的“全有或全无”特性。
### 2.3 计算高效性
相比Sigmoid和Tanh需要计算指数或三角函数,ReLU仅需简单的阈值判断,计算速度更快,尤其适合大规模数据训练。
### 2.4 加速收敛
实验表明,ReLU能够显著加快随机梯度下降(SGD)的收敛速度。例如,在ImageNet数据集上,使用ReLU的CNN比使用Tanh的收敛速度快数倍。
---
## 3. ReLU的局限性及改进
尽管ReLU表现优异,但它也存在一些问题,催生了多种改进版本:
### 3.1 Dying ReLU问题
当输入为负时,ReLU输出0且梯度为0,导致神经元“死亡”(不再更新权重)。解决方案包括:
- **Leaky ReLU**:允许负区间有微小斜率(如0.01x)。
$$ \text{LeakyReLU}(x) = \begin{cases}
x & \text{if } x > 0 \\
\alpha x & \text{otherwise}
\end{cases} $$
- **Parametric ReLU (PReLU)**:将α作为可学习参数。
### 3.2 非零均值输出
ReLU的输出均值不为0,可能影响训练稳定性。改进方案如:
- **Exponential Linear Unit (ELU)**:在负区间使用指数函数平滑过渡。
$$ \text{ELU}(x) = \begin{cases}
x & \text{if } x > 0 \\
\alpha(e^x - 1) & \text{otherwise}
\end{cases} $$
### 3.3 其他变体
- **Swish**:结合ReLU和Sigmoid特性(Google Brain提出)。
$$ \text{Swish}(x) = x \cdot \sigma(\beta x) $$
- **GELU**:高斯误差线性单元(用于BERT、GPT等模型)。
$$ \text{GELU}(x) = x \cdot \Phi(x) $$
---
## 4. ReLU在不同网络中的应用
### 4.1 卷积神经网络(CNN)
- ReLU是CNN的标配激活函数,尤其在AlexNet、ResNet等经典模型中表现突出。
- 与批归一化(BatchNorm)结合,进一步稳定训练过程。
### 4.2 循环神经网络(RNN)
- 传统RNN中,Tanh更常见,但LSTM/GRU的门控机制中也可使用ReLU变体。
### 4.3 生成对抗网络(GAN)
- 生成器和判别器中广泛使用Leaky ReLU以避免梯度稀疏问题。
---
## 5. 实验对比:ReLU vs 其他激活函数
| 激活函数 | 优点 | 缺点 |
|------------|-------------------------------|-------------------------------|
| Sigmoid | 输出范围(0,1),适合概率输出 | 梯度消失,计算成本高 |
| Tanh | 输出均值0,收敛更快 | 梯度消失问题仍存在 |
| ReLU | 计算快,缓解梯度消失 | Dying ReLU问题 |
| Leaky ReLU | 解决Dying ReLU | 需调参α |
---
## 6. 总结
ReLU以其简洁性、高效性和实用性成为深度学习的基石之一。尽管存在局限性,但其变体(如Leaky ReLU、Swish)不断推动模型性能的提升。未来,随着神经网络架构的演进,激活函数的设计仍将是研究热点。
---
## 参考文献
1. Nair, V., & Hinton, G. E. (2010). "Rectified Linear Units Improve Restricted Boltzmann Machines." *ICML*.
2. He, K., et al. (2015). "Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification." *CVPR*.
3. Ramachandran, P., et al. (2017). "Searching for Activation Functions." *arXiv:1710.05941*.
注:实际使用时,需补充图像链接或替换为本地路径。此文档为Markdown格式,可直接用于支持MathJax的平台(如GitHub、Jupyter Notebook等)。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。