жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
еңЁж•°жҚ®еә“еә”з”ЁејҖеҸ‘дёӯпјҢжҲ‘们з»ҸеёёйңҖиҰҒйқўеҜ№еӨҚжқӮзҡ„SQLејҸи®Ўз®—пјҢеӣәе®ҡеҲҶз»„е°ұжҳҜе…¶дёӯдёҖз§ҚгҖӮеӣәе®ҡеҲҶз»„зҡ„еҲҶз»„дҫқжҚ®дёҚеңЁеҫ…еҲҶз»„зҡ„ж•°жҚ®дёӯпјҢиҖҢжҳҜжқҘиҮӘдәҺеӨ–йғЁпјҢжҜ”еҰӮеҸҰдёҖеј иЎЁгҖҒеӨ–йғЁеҸӮж•°гҖҒжқЎд»¶еҲ—иЎЁзӯүгҖӮеҜ№дәҺзү№е®ҡзұ»еһӢзҡ„еӣәе®ҡеҲҶз»„пјҢз”ЁSQLе®һзҺ°иҝҳз®—з®ҖеҚ•пјҲжҜ”еҰӮпјҡеҲҶз»„дҫқжҚ®жқҘиҮӘеҸҰдёҖеј иЎЁпјҢдё”еҜ№еҲҶз»„ж¬ЎеәҸжІЎжңүиҰҒжұӮпјүпјҢдҪҶеҜ№дәҺжҜ”иҫғйҖҡз”ЁгҖҒзҒөжҙ»зҡ„иҰҒжұӮпјҢе®һзҺ°иө·жқҘе°ұеӣ°йҡҫдәҶгҖӮ
иҖҢеҜ№дәҺSPLжқҘиҜҙпјҢе®Ңе…ЁеҸҜд»ҘиҪ»жқҫи§ЈеҶіеӣәе®ҡеҲҶз»„дёӯзҡ„еҗ„зұ»йҡҫйўҳпјҢдёӢйқўе°ұз”ЁеҮ дёӘдҫӢеӯҗжқҘиҜҙжҳҺгҖӮ
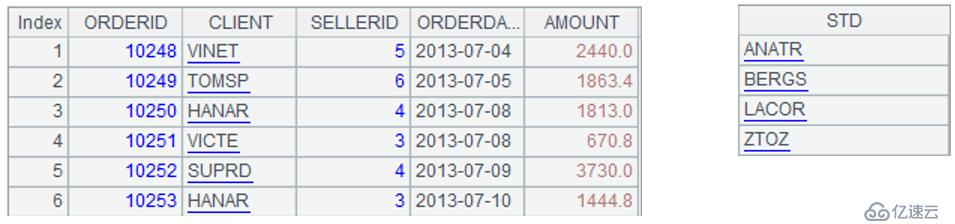
иЎЁsalesеӯҳеӮЁзқҖи®ўеҚ•и®°еҪ•пјҢе…¶дёӯCLIENTеҲ—жҳҜе®ўжҲ·еҗҚпјҢAMOUNTеҲ—жҳҜи®ўеҚ•йҮ‘йўқгҖӮиЎЁsalesзҡ„йғЁеҲҶж•°жҚ®еҰӮдёӢпјҡ
| OrderID | Client | SellerId | OrderDate | Amount |
| 10248 | VINET | 5 | 2013/7/4 | 2440 |
| 10249 | TOMSP | 6 | 2013/7/5 | 1863.4 |
| 10250 | HANAR | 4 | 2013/7/8 | 1813 |
| 10251 | VICTE | 3 | 2013/7/8 | 670.8 |
| 10252 | SUPRD | 4 | 2013/7/9 | 3730 |
| 10253 | HANAR | 3 | 2013/7/10 | 1444.8 |
| 10254 | CHOPS | 5 | 2013/7/11 | 625.2 |
| 10255 | RICSU | 9 | 2013/7/12 | 2490.5 |
| 10256 | WELLI | 3 | 2013/7/15 | 517.8 |
иҰҒжұӮе°ҶsalesжҢүз…§вҖңжҪңеҠӣе®ўжҲ·еҲ—иЎЁвҖқиҝӣиЎҢеҲҶз»„пјҢ并еҜ№еҗ„з»„зҡ„AMOUNTеҲ—жұҮжҖ»жұӮе’ҢгҖӮиҝҷйҮҢзҡ„вҖңжҪңеҠӣе®ўжҲ·вҖқе°ұжҳҜдёҖз§Қеӣәе®ҡеҲҶз»„пјҢеҸҜиғҪжқҘиҮӘдәҺеӨ–йғЁдёҚеҗҢзҡ„жқЎд»¶и®ҫе®ҡпјҡ
В
жЎҲдҫӢдёҖпјҡжҪңеҠӣе®ўжҲ·еҲ—иЎЁжқҘиҮӘдәҺеҸҰеӨ–дёҖеј иЎЁpotentialзҡ„Stdеӯ—ж®өпјҢеҸӘжңүеӣӣжқЎи®°еҪ•пјҢдҫқж¬ЎдёәпјҡANATRгҖҒBERGSгҖҒLACORгҖҒZTOZпјҢ并且客жҲ·ZTOZдёҚеңЁsalesиЎЁдёӯгҖӮеңЁиҫ“еҮәз»“жһңж—¶пјҢиҰҒжұӮжҢүз…§дёҠиҝ°и®°еҪ•йЎәеәҸжқҘеҲҶз»„жұҮжҖ»гҖӮ
еҰӮжһңжҲ‘们еҜ№еҲҶз»„зҡ„йЎәеәҸжІЎжңүиҰҒжұӮпјҢйӮЈд№ҲSQLеҸҜд»Ҙиҫғз®ҖеҚ•ең°е®һзҺ°жң¬жЎҲдҫӢпјҡ
select potential.std as client, sum(sales.amount) as amount from potential left join client on potential.std=sales.client group by potential.stdгҖӮ
дҪҶеҰӮжһңеғҸжң¬жЎҲдҫӢдёӯиҰҒжұӮзҡ„йӮЈж ·пјҢжҢүз…§зү№е®ҡзҡ„йЎәеәҸжқҘеҲҶз»„пјҢйӮЈд№Ҳз”ЁSQLе®һзҺ°зҡ„иҜқе°ұеҝ…йЎ»еҲ¶йҖ дёҖдёӘз”ЁдәҺжҺ’еәҸзҡ„еӯ—ж®өпјҢжңҖеҗҺиҝҳиҰҒз”ЁеӯҗжҹҘиҜўеҺ»жҺүиҝҷдёӘеӯ—ж®өгҖӮиҖҢз”ЁSPLе®һзҺ°еҲҷдјҡз®ҖеҚ•еҫҲеӨҡпјҢд»Јз ҒеҰӮдёӢпјҡ
| A | |
| 1 | =sales=db.query В ("select * from sales") |
| 2 | =potential=db.query("select В * from potential") |
| 3 | =sales.align@a(potential:STD,CLIENT) |
| 4 | =A3.new(potential(#).STD:CLIENT,~.sum(AMOUNT):AMOUNT) |
A1гҖҒB1пјҡд»Һж•°жҚ®еә“жЈҖзҙўж•°жҚ®пјҢеҲҶеҲ«е‘ҪеҗҚдёәsalesе’ҢpotentialпјҢеҰӮдёӢжүҖзӨәпјҡ
A3пјҡ=sales.align@a(potential:STD,CLIENT)
иҝҷеҸҘд»Јз ҒдҪҝз”ЁдәҶеҮҪж•°alignпјҢе®ғе°Ҷsalesзҡ„Clientеӯ—ж®өжҢүз…§potentailзҡ„Stdеӯ—ж®өйЎәеәҸеҜ№дҪҚеҲҶдёәеӣӣдёӘз»„пјҢеҰӮдёӢпјҡ
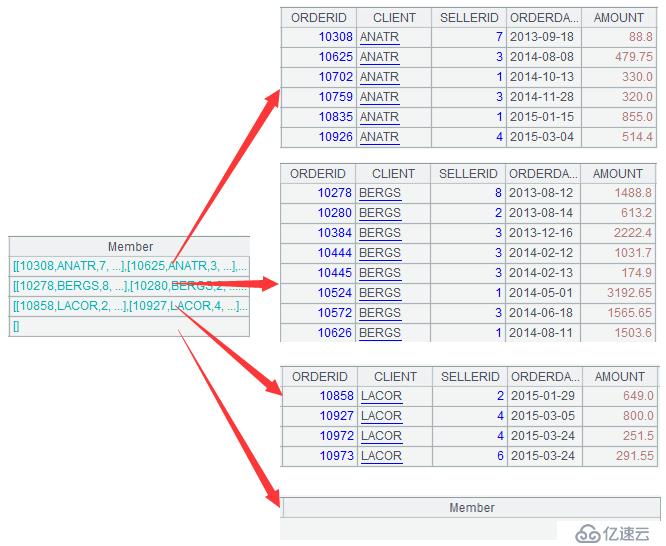
еҸҜд»ҘзңӢеҲ°пјҢеүҚдёүдёӘз»„жҳҜsalesдёӯе·Іжңүзҡ„ж•°жҚ®пјҢиҖҢ第еӣӣдёӘз»„дёҚеңЁsalesдёӯпјҢеӣ жӯӨжҳҜз©әеҖјгҖӮеҸҰеӨ–пјҢеҮҪж•°alignзҡ„еҸӮж•°йҖүйЎ№@aиЎЁзӨәеҸ–еҮәеҲҶз»„дёӯзҡ„жүҖжңүж•°жҚ®пјҢеҰӮжһңдёҚз”ЁиҝҷдёӘеҮҪж•°йҖүйЎ№пјҢеҲҷеҸӘеҸ–жҜҸз»„зҡ„第дёҖжқЎгҖӮ
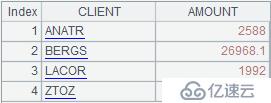
A4пјҡ=A3.new(potential(#).STD:CLIENT,~.sum(AMOUNT):AMOUNT)
иҝҷеҸҘд»Јз Ғз”ЁеҮҪж•°newдә§з”ҹж–°зҡ„еәҸиЎЁпјҢжҲҗе‘ҳдёҖдёӘжҳҜpotential.STDпјҢеҚіpotentialзҡ„Stdеӯ—ж®өпјӣеҸҰдёҖдёӘжҳҜ~.sum(AMOUNT)пјҢеҚіеҜ№A3дёӯжҜҸз»„ж•°жҚ®зҡ„Amountеӯ—ж®өзҡ„жұӮе’Ңз»“жһңгҖӮжңҖз»Ҳз»“жһңеҰӮдёӢпјҡ
В
жЎҲдҫӢдәҢпјҡжҪңеҠӣе®ўжҲ·еҲ—иЎЁжҳҜеӣәе®ҡеҖјпјҢдҪҶе®ўжҲ·зҡ„ж•°йҮҸиҫғеӨҡгҖӮ
еҰӮжһңе®ўжҲ·зҡ„ж•°йҮҸиҫғе°‘пјҢз”ЁSQLж—¶еҸҜд»Ҙз”ЁunionиҜӯеҸҘе°ҶжүҖжңүзҡ„е®ўжҲ·жӢјжҲҗдёҖдёӘеҒҮиЎЁпјҢеҰӮжһңе®ўжҲ·ж•°йҮҸиҫғеӨҡпјҢиҝҷд№ҲеҒҡе°ұеҸҜдёҚеҸ–дәҶпјҢеҝ…йЎ»ж–°е»әдёҖеј иЎЁжҢҒд№…дҝқеӯҳж•°жҚ®жүҚиЎҢгҖӮиҖҢз”ЁSPLе®һзҺ°еҚҙеҸҜд»ҘзңҒеҺ»е»әиЎЁзҡ„йә»зғҰпјҢд»Јз ҒеҰӮдёӢпјҡ
| A | |
| 1 | =sales=db.query В ("select * from sales") |
| 2 | =potential=["ALFKI","BSBEV","FAMIA","GALED","HUNGC","KOENE","LACOR","NORTS","QUICK","SANTG","THEBI","VINET","WOLZA"] |
| 3 | =sales.align@a(potential,CLIENT) |
| 4 | =A3.new(potential(#):CLIENT,~.sum(AMOUNT):AMOUNT) |
дёҠиҝ°д»Јз ҒдёӯпјҢA2жҳҜдёӘеӯ—з¬ҰдёІз»„жҲҗзҡ„еәҸеҲ—пјҢ并е‘ҪеҗҚдёәpotentialгҖӮA3гҖҒA4еҸҜд»ҘеғҸжЎҲдҫӢдёҖйӮЈж ·еҜ№potentialи®ҝй—®пјҢзӣҙжҺҘеј•з”Ёе…¶жҲҗе‘ҳгҖӮ
В
жЎҲдҫӢдёүпјҡжҪңеҠӣе®ўжҲ·еҲ—иЎЁжҳҜеӨ–йғЁеҸӮж•°пјҢеҪўеҰӮпјҡ"BSBEV","FAMIA","GALED"гҖӮ
еӨ–йғЁеҸӮж•°з»ҸеёёеҸҳеҢ–пјҢеңЁSQLдёӯз”ЁunionжқҘеҲ¶йҖ еҒҮиЎЁе°ұжӣҙдёҚж–№дҫҝдәҶпјҢеҸӘиғҪеҲӣе»әдёҖдёӘдёҙж—¶иЎЁпјҢе°ҶеҸӮж•°и§ЈжһҗеҗҺдёҖжқЎжқЎжҸ’е…Ҙдёҙж—¶иЎЁпјҢеҶҚиҝӣиЎҢеҗҺз»ӯзҡ„и®Ўз®—гҖӮиҖҢз”ЁSPLе®һзҺ°еҲҷдёҚеҝ…е»әз«Ӣдёҙж—¶иЎЁпјҢе…·дҪ“е®һзҺ°иҝҮзЁӢеҰӮдёӢпјҡ
йҰ–е…Ҳе®ҡд№үдёҖдёӘеҸӮж•°clientsпјҢеҰӮдёӢпјҡ
然еҗҺдҝ®ж”№и„ҡжң¬ж–Ү件пјҢеҰӮдёӢпјҡ
| A | |
| 1 | =sales=db.query В ("select * from sales") |
| 2 | =potential=clients.array() |
| 3 | =sales.align@a(potential,CLIENT) |
| 4 | =A3.new(potential(#):CLIENT,~.sum(AMOUNT):AMOUNT) |
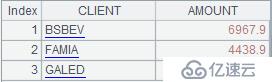
иҝҗиЎҢи„ҡжң¬пјҢ并иҫ“е…Ҙзҡ„еҸӮж•°еҖјпјҢеҒҮи®ҫеҸӮж•°еҖјдёә"BSBEV","FAMIA","GALED"пјҢеҰӮдёӢпјҡ
еҲҶз»„дҫқжҚ®иҫ“е…ҘдёҚеҗҢпјҢжңҖз»Ҳи®Ўз®—з»“жһңд№ҹдёҚдёҖж ·гҖӮдёҠйқўиҫ“е…ҘеҜ№еә”зҡ„з»“жһңеҰӮдёӢпјҡ
В
жЎҲдҫӢеӣӣпјҡеӣәе®ҡеҲҶз»„зҡ„еҲҶз»„дҫқжҚ®еҸҜд»ҘжҳҜж•°еҖјпјҢд№ҹеҸҜд»ҘжҳҜжқЎд»¶пјҢжҜ”еҰӮпјҡе°Ҷи®ўеҚ•йҮ‘йўқжҢүз…§1000гҖҒ2000гҖҒ4000еҲ’еҲҶдёәеӣӣдёӘеҢәй—ҙпјҢжҜҸдёӘеҢәй—ҙдёҖз»„и®ўеҚ•пјҢз»ҹи®Ўеҗ„з»„и®ўеҚ•зҡ„жҖ»йўқгҖӮ
еҰӮжһңжқЎд»¶жҳҜе·ІзҹҘпјҢйӮЈе°ұеҸҜд»Ҙе°ҶиҝҷдәӣжқЎд»¶еҶҷжӯ»еңЁSQLйҮҢпјҢеҰӮжһңжқЎд»¶жҳҜеҠЁжҖҒзҡ„еӨ–йғЁеҸӮж•°пјҢеҲҷйңҖиҰҒз”ЁJAVAзӯүй«ҳзә§иҜӯиЁҖжӢјеҮ‘SQLпјҢиҝҮзЁӢйқһеёёеӨҚжқӮгҖӮиҖҢз”ұдәҺSPLж”ҜжҢҒеҠЁжҖҒиЎЁиҫҫејҸпјҢеӣ жӯӨеҸҜд»ҘиҪ»жқҫе®һзҺ°жң¬жЎҲдҫӢпјҢд»Јз ҒеҰӮдёӢпјҡ
| A | |
| 1 | =sales=db.query В ("select * from sales") |
| 2 | =byFac=["?<=1000" В ,"?>1000 && ?<=2000","?>2000 && ?<=4000","?>4000"] |
| 3 | =sales.enum(byFac,AMOUNT) |
| 4 | =A18.new(byFac(#):byFac,~.sum(AMOUNT):AMOUNT) |
дёҠиҝ°д»Јз ҒдёӯпјҢеҸҳйҮҸbyFacжҳҜжң¬жЎҲдҫӢзҡ„еҲҶз»„дҫқжҚ®пјҢеҢ…еҗ«еӣӣдёӘжқЎд»¶гҖӮbyFacд№ҹеҸҜд»ҘжҳҜеӨ–йғЁеҸӮж•°пјҢжҲ–иҖ…жқҘиҮӘдәҺж•°жҚ®еә“дёӯзҡ„и§ҶеӣҫжҲ–иЎЁгҖӮA4дёӯзҡ„жңҖз»Ҳз»“жһңеҰӮдёӢпјҡ
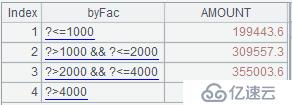
В
жЎҲдҫӢдә”пјҡ
В В В В В В В дёҠиҝ°жқЎд»¶еҲҶз»„дёӯпјҢжқЎд»¶жҒ°еҘҪйғҪжІЎжңүеҸ‘з”ҹйҮҚеҸ пјҢдҪҶе®һйҷ…жғ…еҶөдёӯеҸ‘з”ҹйҮҚеҸ зҡ„жғ…еҶөд№ҹеҫҲеёёи§ҒпјҢжҜ”еҰӮе°Ҷи®ўеҚ•йҮ‘йўқжҢүз…§еҰӮдёӢ规еҲҷеҲҶз»„пјҡ
В В В В В В В 1000иҮі4000пјҡ常规订еҚ•r14
В В В В В В В 2000д»ҘдёӢпјҡйқһйҮҚзӮ№и®ўеҚ•r2
В В В В В В В 3000д»ҘдёҠпјҡйҮҚзӮ№и®ўеҚ•r3
иҝҷж—¶пјҢr2е’Ңr3йғҪдјҡе’Ңr14еҸ‘з”ҹжқЎд»¶йҮҚеҸ гҖӮжқЎд»¶еҸ‘з”ҹйҮҚеҸ ж—¶пјҢжҲ‘们жңүж—¶еёҢжңӣж•°жҚ®дёҚйҮҚеҸ пјҢеҚіе…ҲеҸ–еҮәз¬ҰеҗҲr14зҡ„ж•°жҚ®пјҢеҶҚд»Һеү©дёӢзҡ„ж•°жҚ®дёӯзӯӣйҖүеҮәr2пјҢд»ҘжӯӨзұ»жҺЁгҖӮ
SPLзҡ„еҮҪж•°enumж”ҜжҢҒж•°жҚ®йҮҚеҸ зҡ„жқЎд»¶еҲҶз»„пјҢеҰӮдёӢпјҡ
| A | |
| 1 | =sales=db.query В ("select * from sales") |
| 2 | =byFac=["?>=1000 В && ?<=4000" ,"?<=2000","?>=3000"] |
| 3 | =sales.enum(byFac,AMOUNT) |
| 4 | =A3.new(byFac(#):byFac,~.sum(AMOUNT):AMOUNT) |
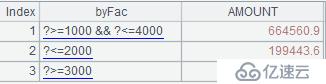
A3дёӯзҡ„еҲҶз»„з»“жһңеҰӮдёӢпјҡ
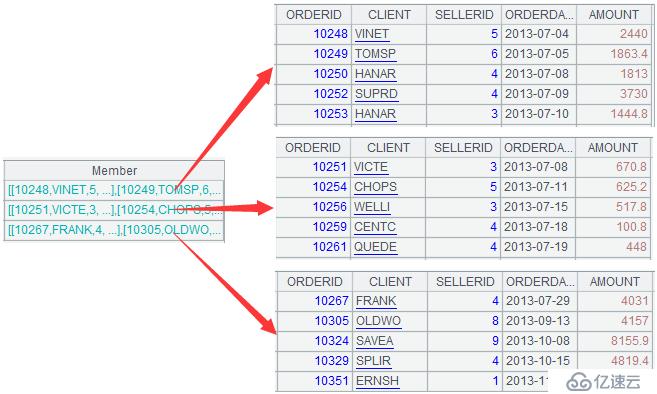
A4и®Ўз®—з»“жһңеҰӮдёӢпјҡ
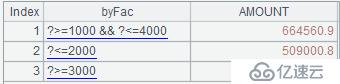
иҖҢжңүж—¶пјҢжҲ‘们еёҢжңӣеҲҶз»„з»“жһңдёӯеҢ…еҗ«йҮҚеҸ ж•°жҚ®пјҢеҚіе…Ҳд»ҺsalesдёӯеҸ–еҮәз¬ҰеҗҲr14зҡ„ж•°жҚ®пјҢеҶҚд»Һе®Ңж•ҙзҡ„salesдёӯеҸ–еҮәз¬ҰеҗҲr2зҡ„ж•°жҚ®пјҢд»ҘжӯӨзұ»жҺЁгҖӮжӯӨж—¶пјҢеҸӘйңҖиҰҒеңЁеҮҪж•°enumдёӯдҪҝз”ЁеҮҪж•°йҖүйЎ№@rпјҢеҚіе°ҶA3дёӯзҡ„д»Јз Ғж”№дёәпјҡ=sales.enum@r(byFac,AMOUNT)пјҢжӯӨж—¶еҲҶз»„з»“жһңеҰӮдёӢпјҡ

еҰӮеӣҫдёӯзәўжЎҶжүҖж ҮжіЁзҡ„пјҢ第дәҢз»„ж•°жҚ®дёӯеҮәзҺ°дәҶж»Ўи¶і1000~4000жқЎд»¶зҡ„ж•°жҚ®гҖӮжңҖеҗҺзҡ„и®Ўз®—з»“жһңеҰӮдёӢпјҡ
еҜ№дәҺи®Ўз®—з»“жһңпјҢйҷӨдәҶеҜјеҮәж•°жҚ®пјҢSPLиҝҳеҸҜд»Ҙд»Ҙиў«и°ғз”Ёзҡ„ж–№ејҸеҗ‘жҠҘиЎЁе·Ҙе…·жҲ–javaзЁӢеәҸжҸҗдҫӣж•°жҚ®пјҢи°ғз”Ёж–№жі•е’Ңжҷ®йҖҡж•°жҚ®еә“зӣёдјјпјҢдҪҝз”Ёе®ғжҸҗдҫӣзҡ„JDBCжҺҘеҸЈеҚіеҸҜеҗ‘javaдё»зЁӢеәҸиҝ”еӣһResultSetеҪўејҸзҡ„и®Ўз®—з»“жһңпјҢе…·дҪ“ж–№жі•еҸҜеҸӮиҖғзӣёе…іж–ҮжЎЈгҖӮгҖҗJavaеҰӮдҪ•и°ғз”ЁSPLи„ҡжң¬гҖ‘
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ