жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
1гҖҒCluster ManagerпјҡSparkйӣҶзҫӨзҡ„иө„жәҗз®ЎзҗҶдёӯеҝғ
1>StandaloneжЁЎејҸпјҡCluster ManagerдёәSparkеҺҹз”ҹзҡ„иө„жәҗз®ЎзҗҶеҷЁпјҢз”ұMasterиҠӮзӮ№иҙҹиҙЈиө„жәҗзҡ„еҲҶй…Қпјӣ
2>Haddop YarnжЁЎејҸпјҡCluster Managerз”ұYarnдёӯзҡ„ResearchManagerиҙҹиҙЈиө„жәҗзҡ„еҲҶй…Қ
3>MessosжЁЎејҸпјҡCluster Managerз”ұMessosдёӯзҡ„Messos MasterиҙҹиҙЈиө„жәҗз®ЎзҗҶгҖӮ
2гҖҒWorker NodeпјҡSparkйӣҶзҫӨдёӯеҸҜд»ҘиҝҗиЎҢApplicationд»Јз Ғзҡ„е·ҘдҪңиҠӮзӮ№гҖӮ
3гҖҒExecutorпјҡжҳҜиҝҗиЎҢеңЁе·ҘдҪңиҠӮзӮ№пјҲWorker NodeпјүдёҠзҡ„дёҖдёӘиҝӣзЁӢпјҢиҙҹиҙЈжү§иЎҢе…·дҪ“зҡ„д»»еҠЎ(Task)пјҢ并且иҙҹиҙЈе°Ҷж•°жҚ®еӯҳеңЁеҶ…еӯҳжҲ–иҖ…зЈҒзӣҳдёҠгҖӮ
4гҖҒApplicationпјҡSpark ApplicationпјҢжҳҜз”ЁжҲ·жһ„е»әеңЁ Spark дёҠзҡ„зЁӢеәҸ
еҰӮеӣҫпјҡ
1>еҢ…еҗ«дәҶDriverпјҢе’ҢдёҖжү№еә”з”ЁзӢ¬з«Ӣзҡ„ExecutorиҝӣзЁӢ
2>жҜҸдёҖдёӘApplicationеҢ…еҗ«еӨҡдёӘдҪңдёҡJobпјҢжҜҸдёӘJobеҢ…еҗ«еӨҡдёӘStageйҳ¶ж®өпјҢжҜҸдёӘstageеҢ…еҗ«еӨҡдёӘTaskгҖӮ
3>JobпјҡдҪңдёҡпјҢдёҖдёӘJobеҢ…еҗ«еӨҡдёӘRDDеҸҠдҪңз”ЁдәҺзӣёеә”RDDдёҠзҡ„еҗ„з§Қж“ҚдҪңгҖӮ
4>Stageпјҡйҳ¶ж®өпјҢжҳҜдҪңдёҡзҡ„еҹәжң¬и°ғеәҰеҚ•дҪҚпјҢдёҖдёӘдҪңдёҡдјҡеҲҶдёәеӨҡз»„д»»еҠЎпјҢжҜҸз»„д»»еҠЎиў«з§°дёәвҖңйҳ¶ж®өвҖқгҖӮ
5>TaskSchedulerпјҡд»»еҠЎи°ғеәҰеҷЁ
6>Taskпјҡд»»еҠЎпјҢиҝҗиЎҢеңЁExecutorдёҠзҡ„е·ҘдҪңеҚ•е…ғпјҢжҳҜExecutorдёӯзҡ„дёҖдёӘзәҝзЁӢгҖӮ
5гҖҒDriver Programпјҡй©ұеҠЁзЁӢеәҸ
1>иҝҗиЎҢеә”з”ЁApplicationзҡ„ main() 方法并且еҲӣе»әдәҶ SparkContextпјӣ
2>Driver еҲҶдёә main() ж–№жі•е’Ң SparkContextдёӨйғЁеҲҶгҖӮ6гҖҒDAGпјҡжҳҜDirected Acyclic GraphпјҲжңүеҗ‘ж— зҺҜеӣҫпјү
1>з”ЁдәҺеҸҚжҳ RDDд№Ӣй—ҙзҡ„дҫқиө–е…ізі»гҖӮ
2>е·ҘдҪңеҶ…е®№еҰӮеӣҫпјҡ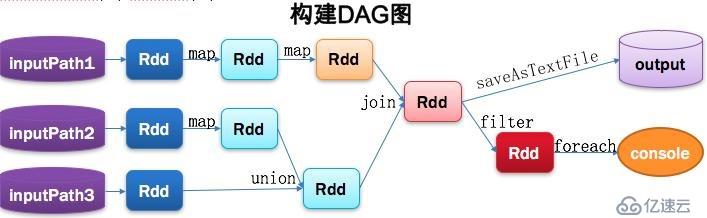
7гҖҒDAGSchedulerпјҡжңүеҗ‘ж— зҺҜеӣҫи°ғеәҰеҷЁ
1>еҹәдәҺDAGеҲ’еҲҶStageпјҢ并д»ҘTaskSetзҡ„еҪўеҠҝжҸҗдәӨStageз»ҷTaskSchedulerпјӣ
2>иҙҹиҙЈе°ҶдҪңдёҡжӢҶеҲҶжҲҗдёҚеҗҢйҳ¶ж®өзҡ„е…·жңүдҫқиө–е…ізі»зҡ„еӨҡжү№д»»еҠЎпјӣ
3>и®Ўз®—дҪңдёҡе’Ңд»»еҠЎзҡ„дҫқиө–е…ізі»пјҢеҲ¶е®ҡи°ғеәҰйҖ»иҫ‘гҖӮ
4>еңЁSparkContextеҲқе§ӢеҢ–зҡ„иҝҮзЁӢдёӯиў«е®һдҫӢеҢ–пјҢдёҖдёӘSparkContextеҜ№еә”еҲӣе»әдёҖдёӘDAGScheduler
5>е·ҘдҪңеҶ…е®№еҰӮеӣҫпјҡ
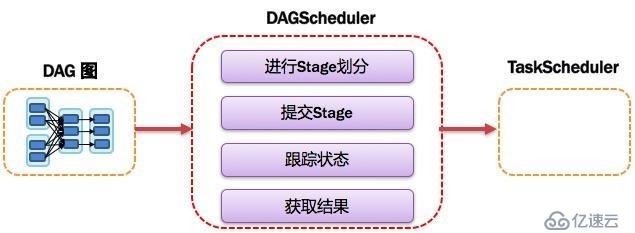
е®ҳж–№жөҒзЁӢеҰӮеӣҫпјҡ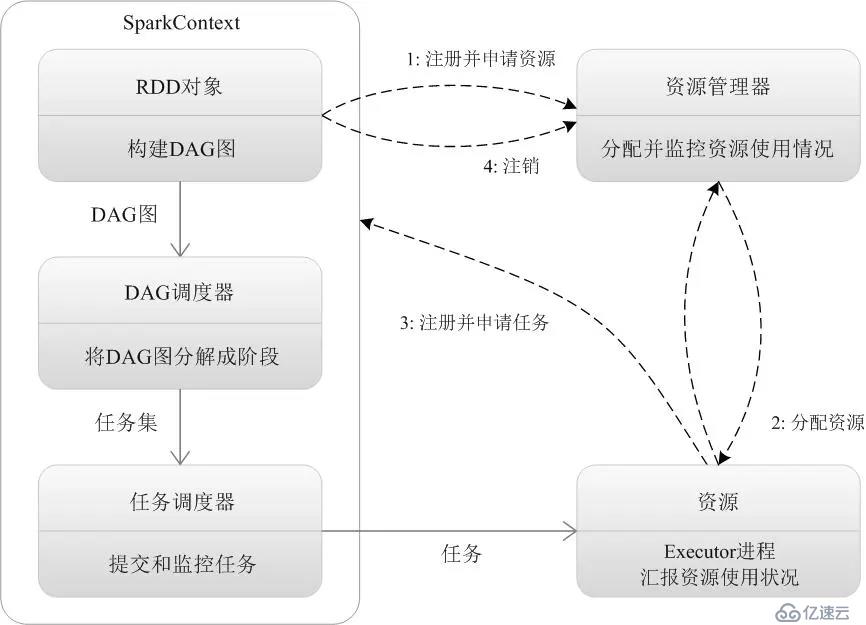
дёӢйқўпјҢжҲ‘们еҜ№жҜҸдёҖжӯҘеҒҡиҜҰз»ҶиҜҙжҳҺпјҡ
1гҖҒе®ўжҲ·з«ҜжҸҗдәӨдҪңдёҡпјҡspark-submit
2гҖҒеҲӣе»әеә”з”ЁпјҢиҝҗиЎҢApplicationеә”з”ЁзЁӢеәҸзҡ„mainеҮҪж•°пјҢеҲӣе»әSparkContextеҜ№иұЎпјҲеҮҶеӨҮSparkеә”з”ЁзЁӢеәҸзҡ„иҝҗиЎҢзҺҜеўғпјүпјҢ并иҙҹиҙЈдёҺCluster ManagerиҝӣиЎҢдәӨдә’гҖӮ
3гҖҒйҖҡиҝҮSparkContextеҗ‘Cluster manager(Master)жіЁеҶҢпјҢ并申иҜ·йңҖиҰҒиҝҗиЎҢзҡ„Executorиө„жәҗгҖӮ
4гҖҒCluster managerжҢүиө„жәҗеҲҶй…Қзӯ–з•ҘиҝӣиЎҢеҲҶй…ҚгҖӮ
5гҖҒCluster managerеҗ‘еҲҶй…ҚеҘҪзҡ„Worker NodeеҸ‘йҖҒпјҢеҗҜеҠЁExecutorиҝӣзЁӢжҢҮд»ӨгҖӮ
6гҖҒWorker NodeжҺҘ收еҲ°жҢҮд»ӨеҗҺпјҢеҗҜеҠЁExecutorиҝӣзЁӢгҖӮ
7гҖҒExecutorиҝӣзЁӢеҸ‘йҖҒеҝғи·із»ҷCluster managerгҖӮ
8гҖҒDriverзЁӢеәҸзҡ„SparkContextпјҢжһ„е»әжҲҗDAGеӣҫгҖӮ
9гҖҒSparkContextиҝӣдёҖжӯҘпјҢе°ҶDAGеӣҫеҲҶи§ЈжҲҗStageйҳ¶ж®өпјҲеҚід»»еҠЎйӣҶTaskSetпјүгҖӮ
10гҖҒSparkContextиҝӣдёҖжӯҘпјҢе°ҶStageйҳ¶ж®өпјҲTaskSetпјүеҸ‘йҖҒз»ҷд»»еҠЎи°ғеәҰеҷЁпјҲTaskSchedulerпјүгҖӮ
11гҖҒExecutorеҗ‘TaskSchedulerз”іиҜ·д»»еҠЎ(Task)гҖӮ
12гҖҒTaskSchedulerе°ҶTaskд»»еҠЎеҸ‘ж”ҫз»ҷExecutorиҝҗиЎҢпјҢSparkContextеҗҢж—¶е°ҶApplicationеә”з”Ёд»Јз ҒеҸ‘ж”ҫз»ҷExecutorгҖӮ
13гҖҒExecutorиҝҗиЎҢеә”з”Ёд»Јз ҒпјҢDriverиҝӣиЎҢжү§иЎҢд»»еҠЎзӣ‘жҺ§гҖӮ
14гҖҒExecurotиҝҗиЎҢд»»еҠЎе®ҢжҜ•еҗҺпјҢеҗ‘DriverеҸ‘йҖҒд»»еҠЎе®ҢжҲҗдҝЎеҸ·гҖӮ
15гҖҒDriverиҙҹиҙЈе°ҶSparkContextе…ій—ӯпјҢ并еҗ‘Cluster managerеҸ‘йҖҒжіЁй”ҖдҝЎеҸ·гҖӮ
15гҖҒCluster manager收еҲ°Driverзҡ„жіЁй”ҖдҝЎеҸ·еҗҺпјҢеҗ‘Worker NodeеҸ‘йҖҒйҮҠж”ҫиө„жәҗдҝЎеҸ·гҖӮ
16гҖҒWorker NodeеҜ№еә”зҡ„ExecutorзЁӢеәҸеҒңжӯўиҝҗиЎҢпјҢиө„жәҗйҮҠж”ҫгҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ