жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚвҖңKafka-4.Kafkaе·ҘдҪңжөҒзЁӢеҸҠж–Ү件еӯҳеӮЁжңәеҲ¶зҡ„еҺҹзҗҶжҳҜд»Җд№ҲвҖқпјҢеңЁж—Ҙеёёж“ҚдҪңдёӯпјҢзӣёдҝЎеҫҲеӨҡдәәеңЁKafka-4.Kafkaе·ҘдҪңжөҒзЁӢеҸҠж–Ү件еӯҳеӮЁжңәеҲ¶зҡ„еҺҹзҗҶжҳҜд»Җд№Ҳй—®йўҳдёҠеӯҳеңЁз–‘жғ‘пјҢе°Ҹзј–жҹҘйҳ…дәҶеҗ„ејҸиө„ж–ҷпјҢж•ҙзҗҶеҮәз®ҖеҚ•еҘҪз”Ёзҡ„ж“ҚдҪңж–№жі•пјҢеёҢжңӣеҜ№еӨ§е®¶и§Јзӯ”вҖқKafka-4.Kafkaе·ҘдҪңжөҒзЁӢеҸҠж–Ү件еӯҳеӮЁжңәеҲ¶зҡ„еҺҹзҗҶжҳҜд»Җд№ҲвҖқзҡ„з–‘жғ‘жңүжүҖеё®еҠ©пјҒжҺҘдёӢжқҘпјҢиҜ·и·ҹзқҖе°Ҹзј–дёҖиө·жқҘеӯҰд№ еҗ§пјҒ
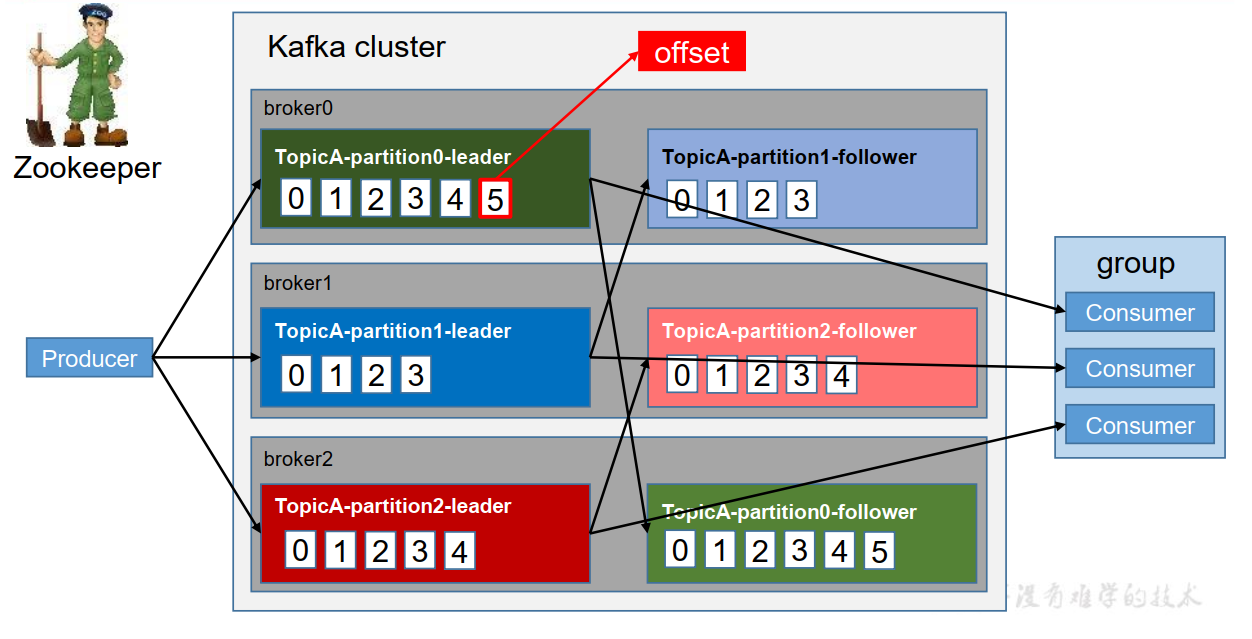
Kafka дёӯж¶ҲжҒҜжҳҜд»Ҙ topic иҝӣиЎҢеҲҶзұ»зҡ„пјҢ з”ҹдә§иҖ…з”ҹдә§ж¶ҲжҒҜпјҢж¶Ҳиҙ№иҖ…ж¶Ҳиҙ№ж¶ҲжҒҜпјҢйғҪжҳҜйқўеҗ‘ topicзҡ„гҖӮ topic жҳҜйҖ»иҫ‘дёҠзҡ„жҰӮеҝөпјҢиҖҢ partition жҳҜзү©зҗҶдёҠзҡ„жҰӮеҝөпјҢжҜҸдёӘ partition еҜ№еә”дәҺдёҖдёӘ log ж–Ү件пјҢиҜҘ log ж–Ү件дёӯеӯҳеӮЁзҡ„е°ұжҳҜ producer з”ҹдә§зҡ„ж•°жҚ®гҖӮ Producer з”ҹдә§зҡ„ж•°жҚ®дјҡиў«дёҚж–ӯиҝҪеҠ еҲ°иҜҘlog ж–Ү件жң«з«ҜпјҢдё”жҜҸжқЎж•°жҚ®йғҪжңүиҮӘе·ұзҡ„ offsetгҖӮ ж¶Ҳиҙ№иҖ…з»„дёӯзҡ„жҜҸдёӘж¶Ҳиҙ№иҖ…пјҢ йғҪдјҡе®һж—¶и®°еҪ•иҮӘе·ұж¶Ҳиҙ№еҲ°дәҶе“ӘдёӘ offsetпјҢд»ҘдҫҝеҮәй”ҷжҒўеӨҚж—¶пјҢд»ҺдёҠж¬Ўзҡ„дҪҚзҪ®з»§з»ӯж¶Ҳиҙ№гҖӮ
з”ұдәҺз”ҹдә§иҖ…з”ҹдә§зҡ„ж¶ҲжҒҜдјҡдёҚж–ӯиҝҪеҠ еҲ° log ж–Ү件жң«е°ҫпјҢ дёәйҳІжӯў log ж–Ү件иҝҮеӨ§еҜјиҮҙж•°жҚ®е®ҡдҪҚж•ҲзҺҮдҪҺдёӢпјҢ Kafka йҮҮеҸ–дәҶеҲҶзүҮе’Ңзҙўеј•жңәеҲ¶пјҢе°ҶжҜҸдёӘ partition еҲҶдёәеӨҡдёӘ segmentгҖӮ жҜҸдёӘ segmentеҜ№еә”дёӨдёӘж–Ү件вҖ”вҖ”вҖң.indexвҖқж–Ү件е’ҢвҖң.logвҖқж–Ү件гҖӮ иҝҷдәӣж–Ү件дҪҚдәҺдёҖдёӘж–Ү件еӨ№дёӢпјҢ иҜҘж–Ү件еӨ№зҡ„е‘ҪеҗҚ规еҲҷдёәпјҡ topic еҗҚз§°+еҲҶеҢәеәҸеҸ·гҖӮдҫӢеҰӮпјҢ first иҝҷдёӘ topic жңүдёүдёӘеҲҶеҢәпјҢеҲҷе…¶еҜ№еә”зҡ„ж–Ү件еӨ№дёә first-0,first-1,first-2
00000000000000000000.index 00000000000000000000.log 00000000000000170410.index 00000000000000170410.log 00000000000000239430.index 00000000000000239430.log
index е’Ң log ж–Ү件д»ҘеҪ“еүҚ segment зҡ„第дёҖжқЎж¶ҲжҒҜзҡ„ offset е‘ҪеҗҚгҖӮдёӢеӣҫдёә index ж–Ү件е’Ң logж–Ү件зҡ„з»“жһ„зӨәж„Ҹеӣҫ
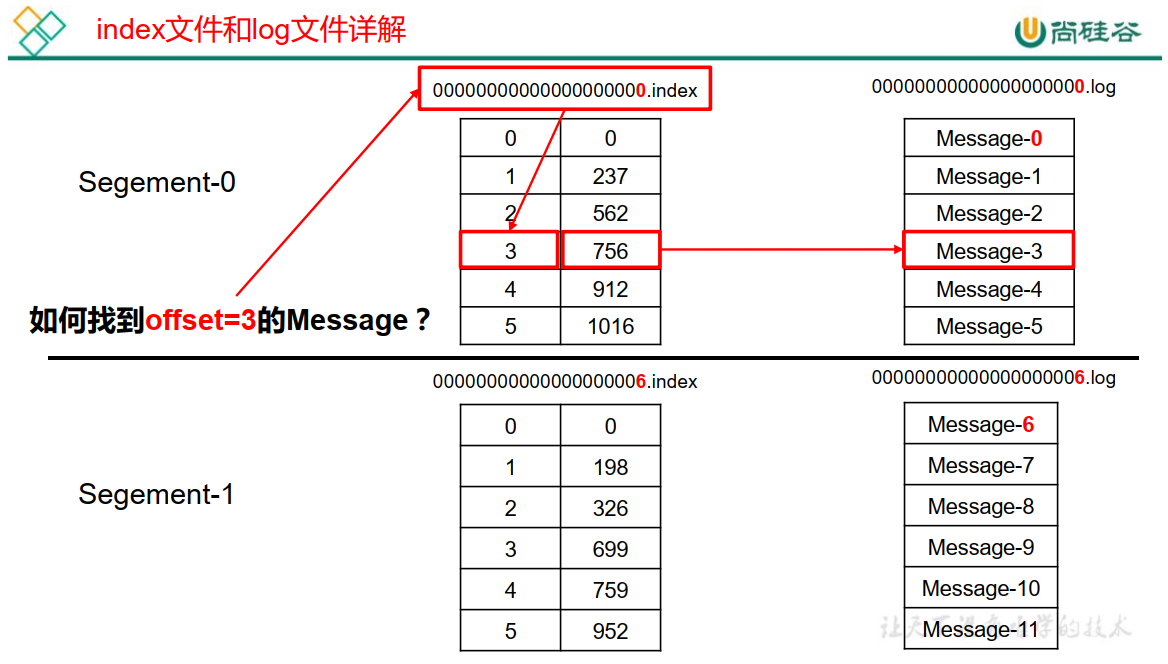
вҖң.indexвҖқж–Ү件еӯҳеӮЁеӨ§йҮҸзҡ„зҙўеј•дҝЎжҒҜпјҢвҖң.logвҖқж–Ү件еӯҳеӮЁеӨ§йҮҸзҡ„ж•°жҚ®пјҢзҙўеј•ж–Ү件дёӯзҡ„е…ғж•°жҚ®жҢҮеҗ‘еҜ№еә”ж•°жҚ®ж–Ү件дёӯ message зҡ„зү©зҗҶеҒҸ移ең°еқҖгҖӮ
1. еҲҶеҢәзҡ„еҺҹеӣ
ж–№дҫҝеңЁйӣҶзҫӨдёӯжү©еұ•пјҢжҜҸдёӘ Partition еҸҜд»ҘйҖҡиҝҮи°ғж•ҙд»ҘйҖӮеә”е®ғжүҖеңЁзҡ„жңәеҷЁпјҢиҖҢдёҖдёӘ topicеҸҲеҸҜд»ҘжңүеӨҡдёӘ Partition з»„жҲҗпјҢеӣ жӯӨж•ҙдёӘйӣҶзҫӨе°ұеҸҜд»ҘйҖӮеә”д»»ж„ҸеӨ§е°Ҹзҡ„ж•°жҚ®дәҶпјӣ
еҸҜд»ҘжҸҗй«ҳ并еҸ‘пјҢеӣ дёәеҸҜд»Ҙд»Ҙ Partition дёәеҚ•дҪҚиҜ»еҶҷдәҶгҖӮ
2. еҲҶеҢәзҡ„еҺҹеҲҷ
жҲ‘们йңҖиҰҒе°Ҷ producer еҸ‘йҖҒзҡ„ж•°жҚ®е°ҒиЈ…жҲҗдёҖдёӘ ProducerRecord еҜ№иұЎгҖӮ 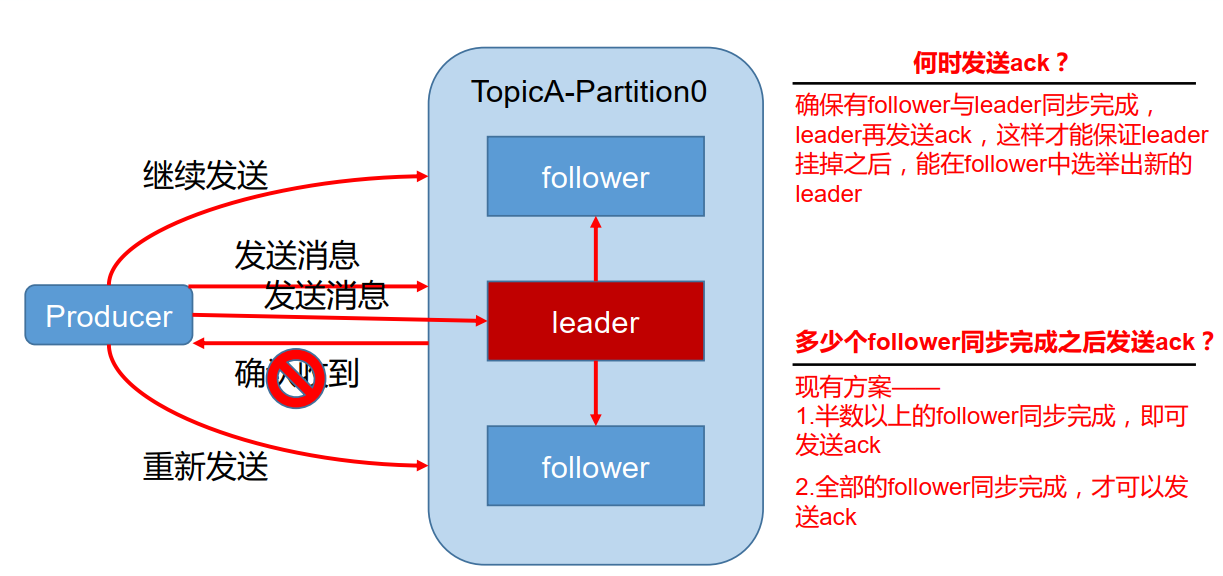
еүҜжң¬ж•°жҚ®еҗҢжӯҘзӯ–з•Ҙ
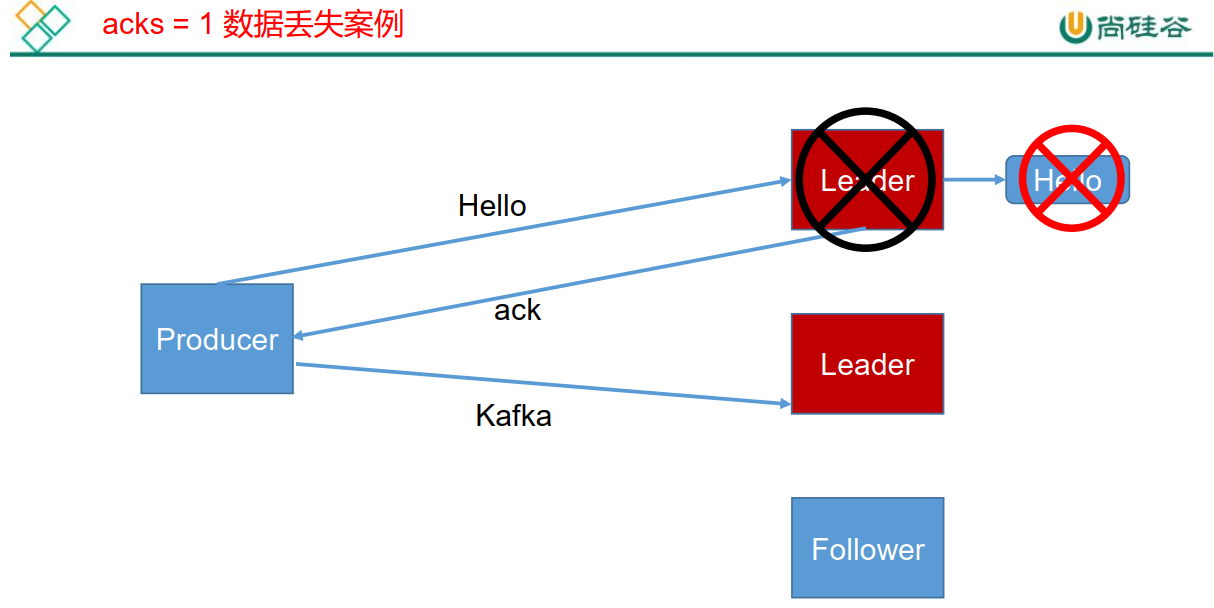
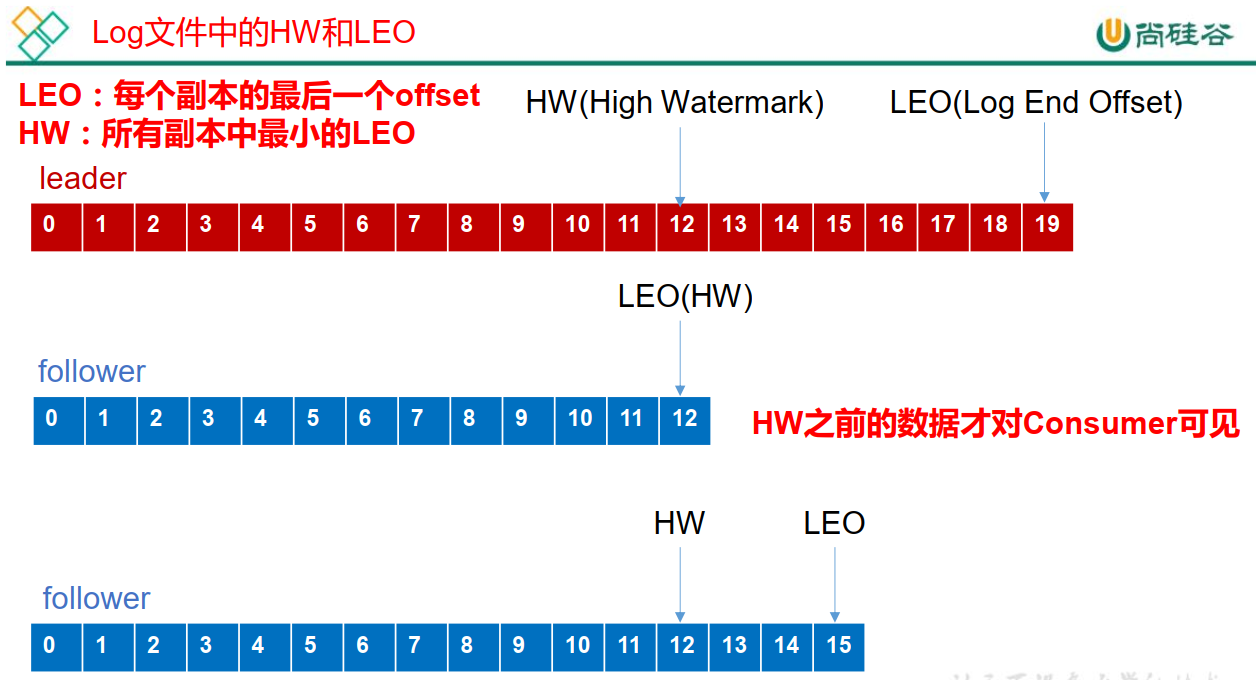
LEOпјҡжҢҮзҡ„жҳҜжҜҸдёӘеүҜжң¬жңҖеӨ§зҡ„ offsetпјӣ
HWпјҡжҢҮзҡ„жҳҜж¶Ҳиҙ№иҖ…иғҪи§ҒеҲ°зҡ„жңҖеӨ§зҡ„ offsetпјҢ ISR йҳҹеҲ—дёӯжңҖе°Ҹзҡ„ LEOгҖӮ
пјҲ1пјүfollower ж•…йҡң follower еҸ‘з”ҹж•…йҡңеҗҺдјҡиў«дёҙж—¶иёўеҮә ISRпјҢеҫ…иҜҘ follower жҒўеӨҚеҗҺпјҢ follower дјҡиҜ»еҸ–жң¬ең°зЈҒзӣҳи®°еҪ•зҡ„дёҠж¬Ўзҡ„ HWпјҢ并е°Ҷ log ж–Ү件й«ҳдәҺ HW зҡ„йғЁеҲҶжҲӘеҸ–жҺүпјҢд»Һ HW ејҖе§Ӣеҗ‘ leader иҝӣиЎҢеҗҢжӯҘгҖӮзӯүиҜҘ follower зҡ„ LEO еӨ§дәҺзӯүдәҺиҜҘ Partition зҡ„ HWпјҢеҚі follower иҝҪдёҠ leader д№ӢеҗҺпјҢе°ұеҸҜд»ҘйҮҚж–°еҠ е…Ҙ ISR дәҶгҖӮ
пјҲ2пјүleaderж•…йҡң leader еҸ‘з”ҹж•…йҡңд№ӢеҗҺпјҢдјҡд»Һ ISR дёӯйҖүеҮәдёҖдёӘж–°зҡ„ leaderпјҢд№ӢеҗҺпјҢдёәдҝқиҜҒеӨҡдёӘеүҜжң¬д№Ӣй—ҙзҡ„ж•°жҚ®дёҖиҮҙжҖ§пјҢ е…¶дҪҷзҡ„ follower дјҡе…Ҳе°Ҷеҗ„иҮӘзҡ„ log ж–Ү件й«ҳдәҺ HW зҡ„йғЁеҲҶжҲӘжҺүпјҢ然еҗҺд»Һж–°зҡ„ leader еҗҢжӯҘж•°жҚ®гҖӮ
жіЁж„Ҹпјҡ иҝҷеҸӘиғҪдҝқиҜҒеүҜжң¬д№Ӣй—ҙзҡ„ж•°жҚ®дёҖиҮҙжҖ§пјҢ并дёҚиғҪдҝқиҜҒж•°жҚ®дёҚдёўеӨұжҲ–иҖ…дёҚйҮҚеӨҚгҖӮ
е°ҶжңҚеҠЎеҷЁзҡ„ ACK зә§еҲ«и®ҫзҪ®дёә-1пјҢеҸҜд»ҘдҝқиҜҒ Producer еҲ° Server д№Ӣй—ҙдёҚдјҡдёўеӨұж•°жҚ®пјҢеҚі AtLeast Once иҜӯд№үгҖӮзӣёеҜ№зҡ„пјҢе°ҶжңҚеҠЎеҷЁ ACK зә§еҲ«и®ҫзҪ®дёә 0пјҢеҸҜд»ҘдҝқиҜҒз”ҹдә§иҖ…жҜҸжқЎж¶ҲжҒҜеҸӘдјҡиў«еҸ‘йҖҒдёҖж¬ЎпјҢеҚі At Most Once иҜӯд№үгҖӮ
At Least Once еҸҜд»ҘдҝқиҜҒж•°жҚ®дёҚдёўеӨұпјҢдҪҶжҳҜдёҚиғҪдҝқиҜҒж•°жҚ®дёҚйҮҚеӨҚпјӣзӣёеҜ№зҡ„пјҢ At Least OnceеҸҜд»ҘдҝқиҜҒж•°жҚ®дёҚйҮҚеӨҚпјҢдҪҶжҳҜдёҚиғҪдҝқиҜҒж•°жҚ®дёҚдёўеӨұгҖӮ дҪҶжҳҜпјҢеҜ№дәҺдёҖдәӣйқһеёёйҮҚиҰҒзҡ„дҝЎжҒҜпјҢжҜ”еҰӮиҜҙдәӨжҳ“ж•°жҚ®пјҢдёӢжёёж•°жҚ®ж¶Ҳиҙ№иҖ…иҰҒжұӮж•°жҚ®ж—ўдёҚйҮҚеӨҚд№ҹдёҚдёўеӨұпјҢеҚі Exactly Once иҜӯд№үгҖӮ еңЁ 0.11 зүҲжң¬д»ҘеүҚзҡ„ KafkaпјҢеҜ№жӯӨжҳҜж— иғҪдёәеҠӣзҡ„пјҢеҸӘиғҪдҝқиҜҒж•°жҚ®дёҚдёўеӨұпјҢеҶҚеңЁдёӢжёёж¶Ҳиҙ№иҖ…еҜ№ж•°жҚ®еҒҡе…ЁеұҖеҺ»йҮҚгҖӮеҜ№дәҺеӨҡдёӘдёӢжёёеә”з”Ёзҡ„жғ…еҶөпјҢжҜҸдёӘйғҪйңҖиҰҒеҚ•зӢ¬еҒҡе…ЁеұҖеҺ»йҮҚпјҢиҝҷе°ұеҜ№жҖ§иғҪйҖ жҲҗдәҶеҫҲеӨ§еҪұе“ҚгҖӮ
0.11 зүҲжң¬зҡ„ KafkaпјҢеј•е…ҘдәҶдёҖйЎ№йҮҚеӨ§зү№жҖ§пјҡе№ӮзӯүжҖ§гҖӮжүҖи°“зҡ„е№ӮзӯүжҖ§е°ұжҳҜжҢҮ Producer дёҚи®әеҗ‘ Server еҸ‘йҖҒеӨҡе°‘ж¬ЎйҮҚеӨҚж•°жҚ®пјҢ Server з«ҜйғҪеҸӘдјҡжҢҒд№…еҢ–дёҖжқЎгҖӮе№ӮзӯүжҖ§з»“еҗҲ At Least Once иҜӯд№үпјҢе°ұжһ„жҲҗдәҶ Kafka зҡ„ Exactly Once иҜӯд№үгҖӮеҚіпјҡ
At Least Once + е№ӮзӯүжҖ§ = Exactly Once
иҰҒеҗҜз”Ёе№ӮзӯүжҖ§пјҢеҸӘйңҖиҰҒе°Ҷ Producer зҡ„еҸӮж•°дёӯ enable.idompotence и®ҫзҪ®дёә true еҚіеҸҜгҖӮ Kafkaзҡ„е№ӮзӯүжҖ§е®һзҺ°е…¶е®һе°ұжҳҜе°ҶеҺҹжқҘдёӢжёёйңҖиҰҒеҒҡзҡ„еҺ»йҮҚж”ҫеңЁдәҶж•°жҚ®дёҠжёёгҖӮејҖеҗҜе№ӮзӯүжҖ§зҡ„ Producer еңЁеҲқе§ӢеҢ–зҡ„ж—¶еҖҷдјҡиў«еҲҶй…ҚдёҖдёӘ PIDпјҢеҸ‘еҫҖеҗҢдёҖ Partition зҡ„ж¶ҲжҒҜдјҡйҷ„еёҰ Sequence NumberгҖӮиҖҢBroker з«ҜдјҡеҜ№<PID, Partition, SeqNumber>еҒҡзј“еӯҳпјҢеҪ“е…·жңүзӣёеҗҢдё»й”®зҡ„ж¶ҲжҒҜжҸҗдәӨж—¶пјҢ Broker еҸӘдјҡжҢҒд№…еҢ–дёҖжқЎгҖӮ
дҪҶжҳҜ PID йҮҚеҗҜе°ұдјҡеҸҳеҢ–пјҢеҗҢж—¶дёҚеҗҢзҡ„ Partition д№ҹе…·жңүдёҚеҗҢдё»й”®пјҢжүҖд»Ҙе№ӮзӯүжҖ§ж— жі•дҝқиҜҒи·ЁеҲҶеҢәи·ЁдјҡиҜқзҡ„ Exactly OnceгҖӮ
Kafka зҡ„ producer з”ҹдә§ж•°жҚ®пјҢиҰҒеҶҷе…ҘеҲ° log ж–Ү件дёӯпјҢеҶҷзҡ„иҝҮзЁӢжҳҜдёҖзӣҙиҝҪеҠ еҲ°ж–Ү件жң«з«ҜпјҢдёәйЎәеәҸеҶҷгҖӮ е®ҳзҪ‘жңүж•°жҚ®иЎЁжҳҺпјҢеҗҢж ·зҡ„зЈҒзӣҳпјҢйЎәеәҸеҶҷиғҪеҲ° 600M/sпјҢиҖҢйҡҸжңәеҶҷеҸӘжңү 100K/sгҖӮиҝҷдёҺзЈҒзӣҳзҡ„жңәжў°жңәжһ„жңүе…іпјҢйЎәеәҸеҶҷд№ӢжүҖд»Ҙеҝ«пјҢжҳҜеӣ дёәе…¶зңҒеҺ»дәҶеӨ§йҮҸзЈҒеӨҙеҜ»еқҖзҡ„ж—¶й—ҙгҖӮ
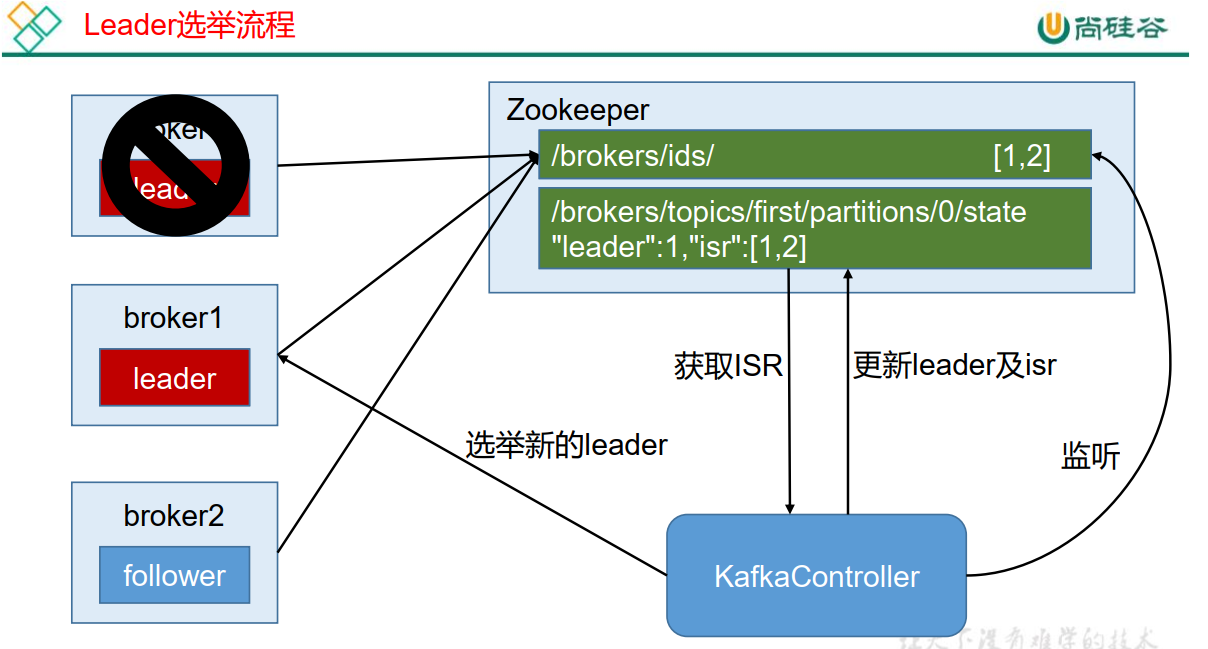
Kafka йӣҶзҫӨдёӯжңүдёҖдёӘ broker дјҡиў«йҖүдёҫдёә ControllerпјҢиҙҹиҙЈз®ЎзҗҶйӣҶзҫӨ broker зҡ„дёҠдёӢзәҝпјҢжүҖжңү topic зҡ„еҲҶеҢәеүҜжң¬еҲҶй…Қе’Ң leader йҖүдёҫзӯүе·ҘдҪңгҖӮ
Controller зҡ„з®ЎзҗҶе·ҘдҪңйғҪжҳҜдҫқиө–дәҺ Zookeeper зҡ„гҖӮ
д»ҘдёӢдёә partition зҡ„ leader йҖүдёҫиҝҮзЁӢпјҡ
Kafka д»Һ 0.11 зүҲжң¬ејҖе§Ӣеј•е…ҘдәҶдәӢеҠЎж”ҜжҢҒгҖӮдәӢеҠЎеҸҜд»ҘдҝқиҜҒ Kafka еңЁ Exactly Once иҜӯд№үзҡ„еҹәзЎҖдёҠпјҢз”ҹдә§е’Ңж¶Ҳиҙ№еҸҜд»Ҙи·ЁеҲҶеҢәе’ҢдјҡиҜқпјҢиҰҒд№Ҳе…ЁйғЁжҲҗеҠҹпјҢиҰҒд№Ҳе…ЁйғЁеӨұиҙҘгҖӮ
дёәдәҶе®һзҺ°и·ЁеҲҶеҢәи·ЁдјҡиҜқзҡ„дәӢеҠЎпјҢйңҖиҰҒеј•е…ҘдёҖдёӘе…ЁеұҖе”ҜдёҖзҡ„ Transaction IDпјҢ并е°Ҷ ProducerиҺ·еҫ—зҡ„PID е’ҢTransaction ID з»‘е®ҡгҖӮиҝҷж ·еҪ“Producer йҮҚеҗҜеҗҺе°ұеҸҜд»ҘйҖҡиҝҮжӯЈеңЁиҝӣиЎҢзҡ„ TransactionID иҺ·еҫ—еҺҹжқҘзҡ„ PIDгҖӮдёәдәҶз®ЎзҗҶ TransactionпјҢ Kafka еј•е…ҘдәҶдёҖдёӘж–°зҡ„组件 Transaction CoordinatorгҖӮ Producer е°ұжҳҜйҖҡиҝҮе’Ң Transaction Coordinator дәӨдә’иҺ·еҫ— Transaction ID еҜ№еә”зҡ„д»»еҠЎзҠ¶жҖҒгҖӮ Transaction Coordinator иҝҳиҙҹиҙЈе°ҶдәӢеҠЎжүҖжңүеҶҷе…Ҙ Kafka зҡ„дёҖдёӘеҶ…йғЁ TopicпјҢиҝҷж ·еҚідҪҝж•ҙдёӘжңҚеҠЎйҮҚеҗҜпјҢз”ұдәҺдәӢеҠЎзҠ¶жҖҒеҫ—еҲ°дҝқеӯҳпјҢиҝӣиЎҢдёӯзҡ„дәӢеҠЎзҠ¶жҖҒеҸҜд»Ҙеҫ—еҲ°жҒўеӨҚпјҢд»ҺиҖҢ继з»ӯиҝӣиЎҢгҖӮ
дёҠиҝ°дәӢеҠЎжңәеҲ¶дё»иҰҒжҳҜд»Һ Producer ж–№йқўиҖғиҷ‘пјҢеҜ№дәҺ Consumer иҖҢиЁҖпјҢдәӢеҠЎзҡ„дҝқиҜҒе°ұдјҡзӣёеҜ№иҫғејұпјҢе°Өе…¶ж—¶ж— жі•дҝқиҜҒ Commit зҡ„дҝЎжҒҜиў«зІҫзЎ®ж¶Ҳиҙ№гҖӮиҝҷжҳҜз”ұдәҺ Consumer еҸҜд»ҘйҖҡиҝҮ offset и®ҝй—®д»»ж„ҸдҝЎжҒҜпјҢиҖҢдё”дёҚеҗҢзҡ„ Segment File з”ҹе‘Ҫе‘ЁжңҹдёҚеҗҢпјҢеҗҢдёҖдәӢеҠЎзҡ„ж¶ҲжҒҜеҸҜиғҪдјҡеҮәзҺ°йҮҚеҗҜеҗҺиў«еҲ йҷӨзҡ„жғ…еҶөгҖӮ
еҲ°жӯӨпјҢе…ідәҺвҖңKafka-4.Kafkaе·ҘдҪңжөҒзЁӢеҸҠж–Ү件еӯҳеӮЁжңәеҲ¶зҡ„еҺҹзҗҶжҳҜд»Җд№ҲвҖқзҡ„еӯҰд№ е°ұз»“жқҹдәҶпјҢеёҢжңӣиғҪеӨҹи§ЈеҶіеӨ§е®¶зҡ„з–‘жғ‘гҖӮзҗҶи®әдёҺе®һи·өзҡ„жҗӯй…ҚиғҪжӣҙеҘҪзҡ„её®еҠ©еӨ§е®¶еӯҰд№ пјҢеҝ«еҺ»иҜ•иҜ•еҗ§пјҒиӢҘжғіз»§з»ӯеӯҰд№ жӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢиҜ·з»§з»ӯе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–дјҡ继з»ӯеҠӘеҠӣдёәеӨ§е®¶еёҰжқҘжӣҙеӨҡе®һз”Ёзҡ„ж–Үз« пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ