您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》


2.通过Xftp工具将压缩包拉到虚拟机/opt目录下(目录个人随意)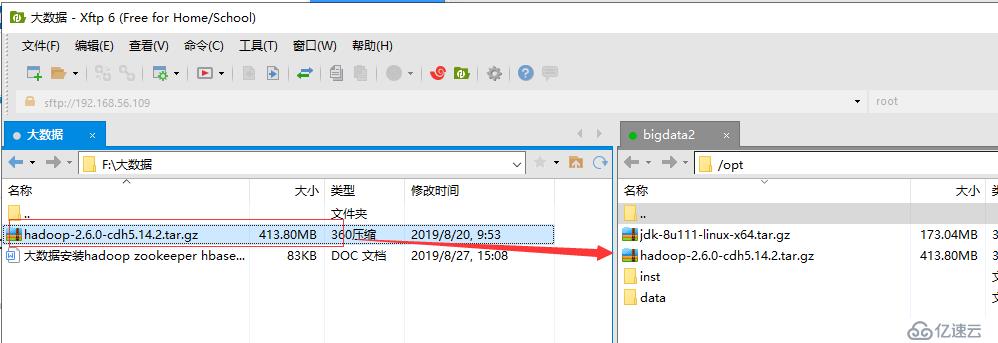
3.解压hadoop压缩包(命令:tar -zxvf hadoop-2.6.0-cdh6.14.2.tar.gz)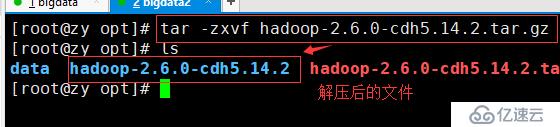
4.这里为了清晰,新建一个文件夹bigdata单独存放解压后的文件,并重命名
新建:mkdir bigdata
移动: mv hadoop-2.6.0-cdh6.14.2 ./bigdata/hadoop260
5.重头:修改配置文件,移动至/etc/hadoop目录下,ls命令,下图中圈选的文件是本次我们需要进行配置的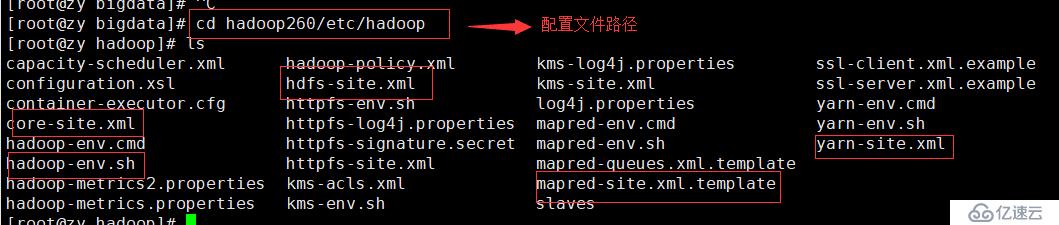
6.配置1:vi hadoop-env.sh修改如下位置,修改成自己JAVA_HOME的路径,可以echo $JAVA_HOME查看,修改完保存退出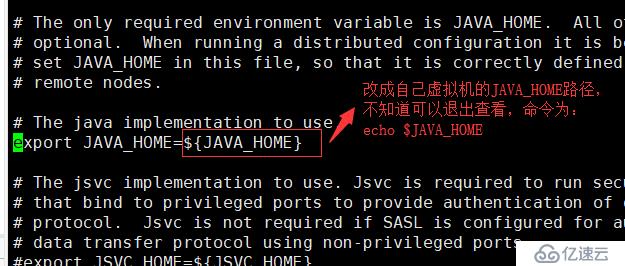
7.配置2:vi core-site.xml修改如下位置
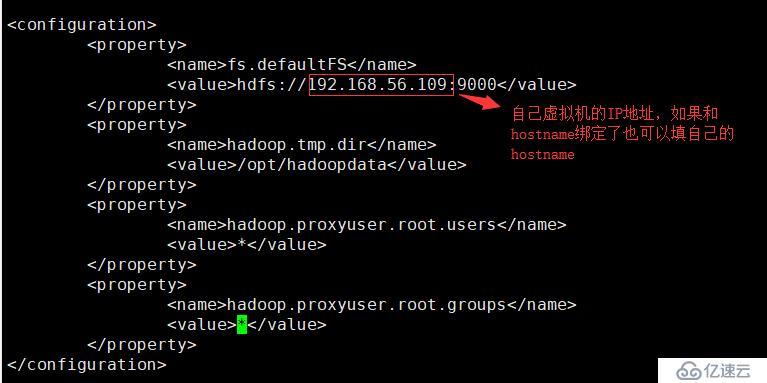
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.56.109:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoopdata</value>
</property>
<property>
<name>hadoop.proxyuser.root.users</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>8.配置3:vi hdfs-site.xml,和上一步一样的标签中加入如下代码
<property>
<name>dfs.replication</name>
<value>1</value>
</property>9.配置4,这个文件需要自己copy,和上一步一样的标签中加入如下代码
命令:cp mapred-site.xml.template mapred-site.xml
配置:vi mapred-site.xml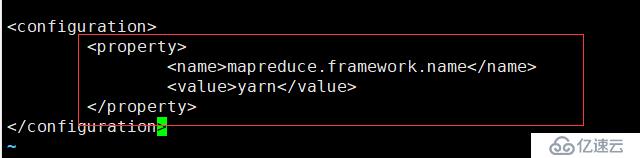
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>10.配置5:vi yarn-site.xml,中间有行注释可以删掉直接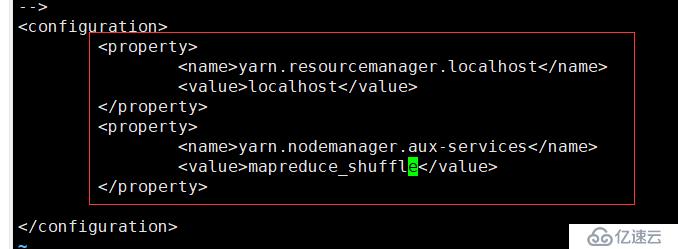
<property>
<name>yarn.resourcemanager.localhost</name>
<value>localhost</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
11.配置六:vi /etc/profile,移动至最后,加入以下代码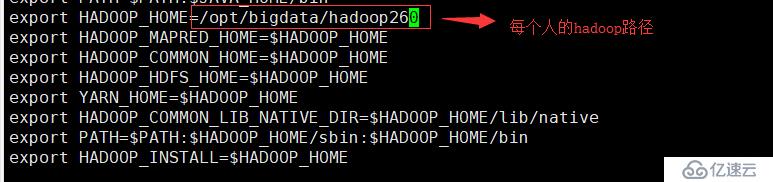
export HADOOP_HOME=/opt/bigdata/hadoop260
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL=$HADOOP_HOME12.激活配置文件:source /etc/profile
13.格式化namenode:hdfs namenode -format
14.运行:start-all.sh,然后每一步都输入yes
15.查看运行情况:jps,如果能查看到如下5个进程,则代表配置运行成功,如果少哪一个,就去检查对应的配置文件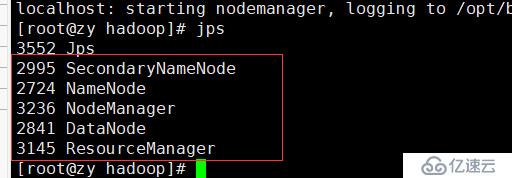
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。