您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
1.1.1core-site.xml(工具模块)
包括Hadoop常用的工具类,由原来的Hadoopcore部分更名而来。主要包括系统配置工具Configuration、远程过程调用RPC、序列化机制和Hadoop抽象文件系统FileSystem等。它们为在通用硬件上搭建云计算环境提供基本的服务,并为运行在该平台上的软件开发提供了所需的API。
1.1.2hdfs-site.xml(数据存储模块)
分布式文件系统,提供对应用程序数据的高吞吐量,高伸缩性,高容错性的访问。是Hadoop体系中数据存储管理的基础。它是一个高度容错的系统,能检测和应对硬件故障,用于在低成本的通用硬件上运行。HDFS简化了文件的一致性模型,通过流式数据访问,提供高吞吐量应用程序数据访问功能,适合带有大型数据集的应用程序。
namenode+ datanode + secondarynode
1.1.3mapred-site.xml(数据处理模块)
基于YARN的大型数据集并行处理系统。是一种计算模型,用以进行大数据量的计算。Hadoop的MapReduce实现,和Common、HDFS一起,构成了Hadoop发展初期的三个组件。MapReduce将应用划分为Map和Reduce两个步骤,其中Map对数据集上的独立元素进行指定的操作,生成键-值对形式中间结果。Reduce则对中间结果中相同“键”的所有“值”进行规约,以得到最终结果。MapReduce这样的功能划分,非常适合在大量计算机组成的分布式并行环境里进行数据处理。
1.1.4yarn-site.xml(作业调度+资源管理平台)
任务调度和集群资源管理
resourcemanager + nodemanager
1.2hadoop 五大节点:
1.2.1NameNode(管理节点)
Namenode 管理着文件系统的命令空间(Namespace)。它维护着文件系统树(filesystemtree)以及文件树中所有的文件和文件夹的元数据(metadata),元数据包括编辑日志(edits)和镜像文件(fsimage)。管理这些信息的文件有两个,分别是Namespace 镜像文件(fsimage)和编辑日志文件(edits),编辑日志主要是记录对hdfs进行的修改.镜像文件主要是记录hdfs的文件树形结构.这些信息被Cache在RAM中,当然,这两个文件也会被持久化存储在本地硬盘。Namenode记录着每个文件中各个块所在的数据节点的位置信息,但是他并不持久化存储这些信息,因为这些信息会在系统启动时从数据节点重建。
1.2.2DataNode(工作节点)
Datanode是文件系统的工作节点,他们根据客户端或者是namenode的调度存储和检索数据,并且定期向namenode发送他们所存储的块(block)的列表。
没有namenode,文件系统是无法使用的.事实上,如果运行namenode服务的服务器坏掉,文件系统上的所有文件将会丢失.因为我们不知道如何根据DataNode的块进行重建文件.所有,对NameNode进行容错冗余机制是非常重要的.
集群中的从节点服务器都运行一个DataNode后台程序,这个后台程序负责把HDFS数据块读写到本地的文件系统。当需要通过客户端读/写某个数据时,先由NameNode告诉客户端去哪个DataNode进行具体的读/写操作,然后,客户端直接与这个DataNode服务器上的后台程序进行通信,并且对相关的数据块进行读/写操作。
1.2.3secondary NameNode(相当于MySQL数据库中主从复制的从节点)
Secondary NameNode是一个用来监控HDFS状态的辅助后台程序。和NameNode一样,每个集群都有一个Secondary NameNode,并且部署在一个单独的服务器上。Secondary NameNode不同于NameNode,它不接受或者记录任何实时的数据变化,但是,它会与NameNode进行通信,以便定期地保存HDFS元数据的快照。由于NameNode是单点的,通过Secondary NameNode的快照功能,可以将NameNode的宕机时间和数据损失降低到最小。同时,如果NameNode发生问题,Secondary NameNode可以及时地作为备用NameNode使用。
1.2.4ResourceManager
ResourceManage 即资源管理,在YARN中,ResourceManager负责集群中所有资源的统一管理和分配,它接收来自各个节点(NodeManager)的资源汇报信息,并把这些信息按照一定的策略分配给各个应用程序(实际上是ApplicationManager)。
RM包括Scheduler(定时调度器)和ApplicationManager(应用管理器)。Schedular负责向应用程序分配资源,它不做监控以及应用程序的状态跟踪,并且不保证会重启应用程序本身或者硬件出错而执行失败的应用程序。ApplicationManager负责接受新的任务,协调并提供在ApplicationMaster容器失败时的重启功能.每个应用程序的AM负责项Scheduler申请资源,以及跟踪这些资源的使用情况和资源调度的监控
1.2.5Nodemanager
NM是ResourceManager在slave机器上的代理,负责容器管理,并监控它们的资源使用情况,以及向ResourceManager/Scheduler提供资源使用报告
HDFS文件存储机制:
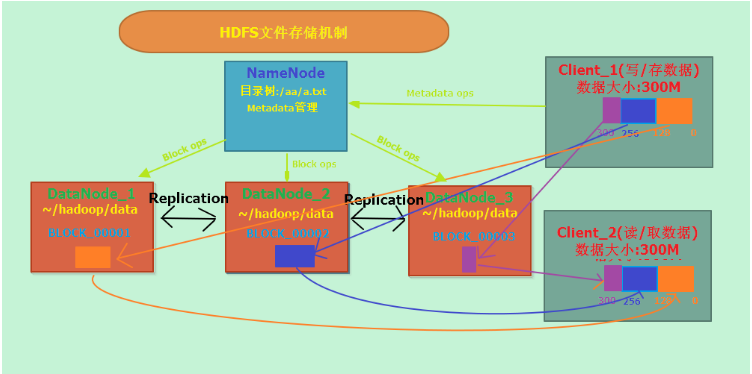
HDFS集群分为两大角色:NameNode、DataNode、(secondary NameNode)
NameNode负责管理整个文件系统的元数据
DataNode负责管理用户的文件数据块
文件会按照固定的大小切成若干块后分布式存储在若干台DataNode上
每一个文件块可以有多个副本,并存放在不同的DataNode上
DataNode会定期向NameNode汇报自身所保存的文件block信息,而NameNode则会负责保持文件的副本数量
HDFS的内部工作机制对客户端保持透明,客户端请求访问HDFS都是通过向NameNode申请来进行
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。