您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
如何进行kafka各原理的剖析,很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
topic如何创建于删除的
topic的创建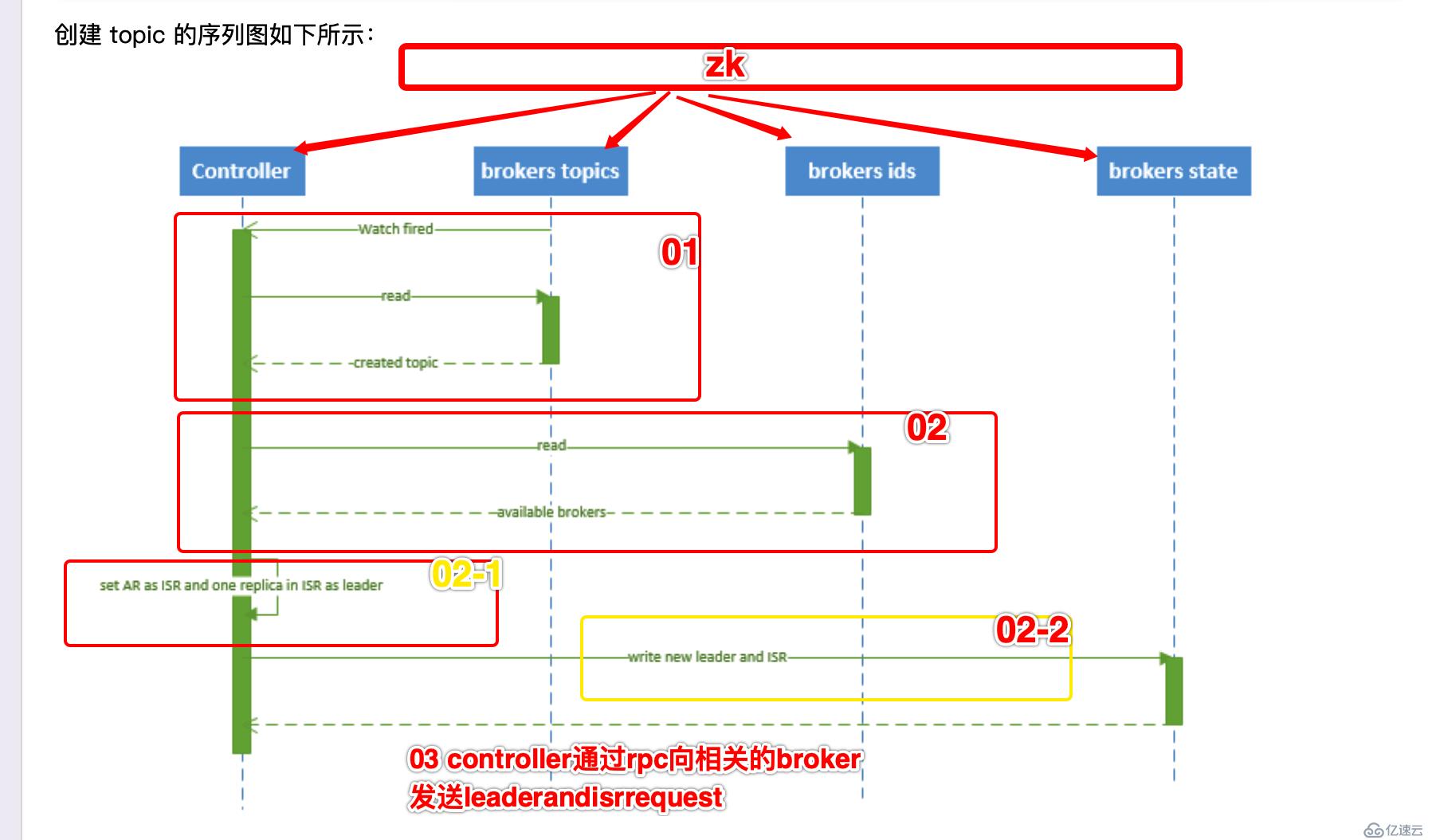
具体流程文字为:
1、 controller 在 ZooKeeper 的 /brokers/topics 节点上注册 watcher,当 topic 被创建,则 controller 会通过 watch 得到该 topic 的 partition/replica 分配。 2、 controller从 /brokers/ids 读取当前所有可用的 broker 列表,对于 set_p 中的每一个 partition: 2.1、 从分配给该 partition 的所有 replica(称为AR)中任选一个可用的 broker 作为新的 leader,并将AR设置为新的 ISR 2.2、 将新的 leader 和 ISR 写入 /brokers/topics/[topic]/partitions/[partition]/state 3、 controller 通过 RPC 向相关的 broker 发送 LeaderAndISRRequest。
注意:此部分 和 partition 的leader选举过程很类似 都是需要 zk参与 相关信息都是记录到zk中
controller在这些过程中启到非常重要的作用。
topic的删除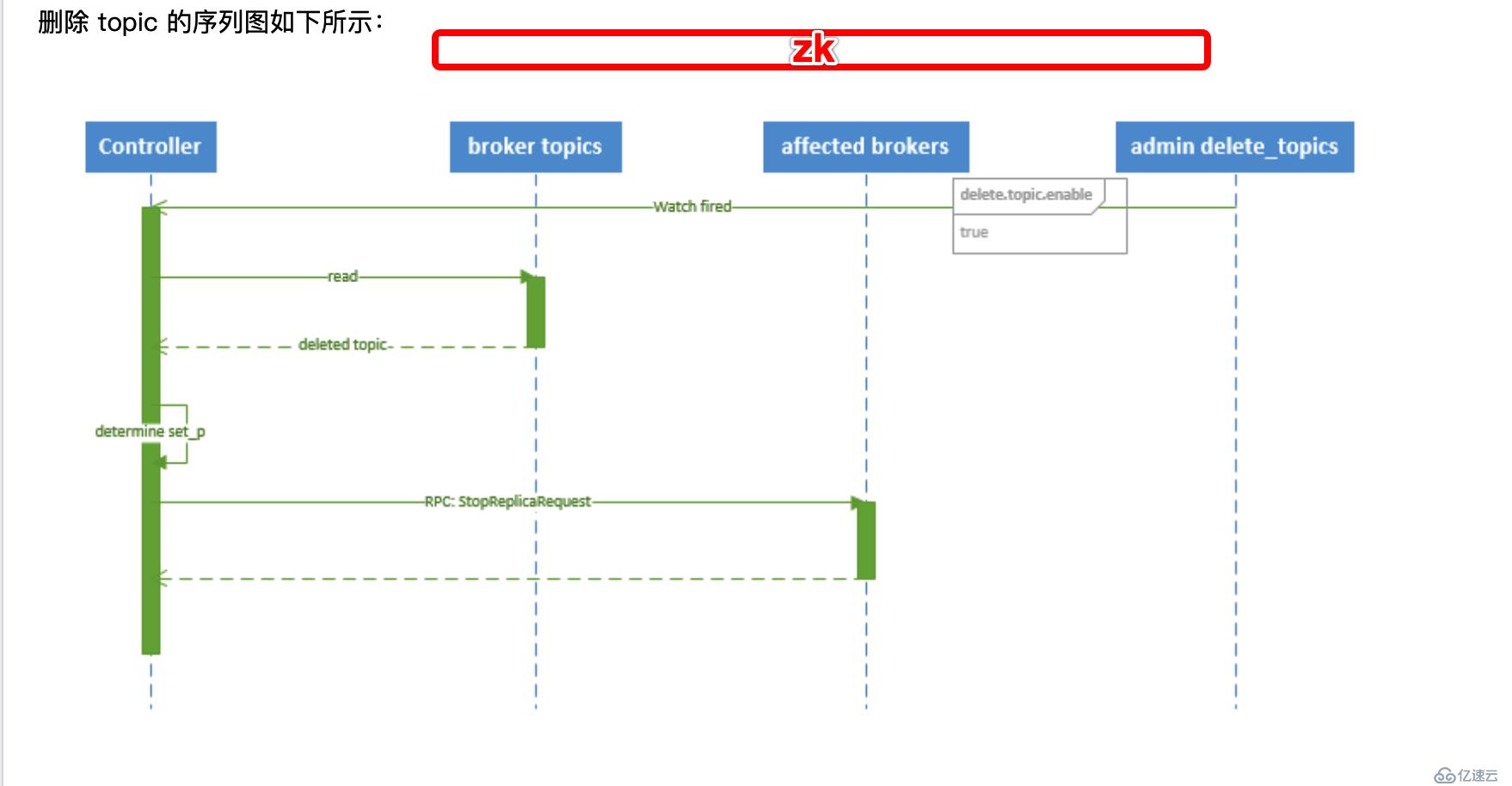
文字过程:
1、 controller 在 zooKeeper 的 /brokers/topics 节点上注册 watcher,当 topic 被删除,则 controller 会通过 watch 得到该 topic 的 partition/replica 分配。 2、 若 delete.topic.enable=false,结束;否则 controller 注册在 /admin/delete_topics 上的 watch 被 fire,controller 通过回调向对应的 broker 发送 StopReplicaRequest。
前面我们讲到的很多的处理故障过程 包括 topic创建删除 partition leader的转换 broker发生故障的过程中如何保证高可用 都涉及到了一个组件 controller,关于kafka中出现的相关概念名词,我会专门的写一个博客,这里先简单的提一下。
Controller:Kafka 集群中的其中一个服务器,用来进行 Leader Election 以及各种 Failover。
大家有没有想过一个问题,就是如果controller出现了故障,怎么办,如何failover的呢?我们往下看。
首先我们最一个实验,我们在zk中找到controller在哪个broker上,并查看controller_epoch的次数
[zk: localhost:2181(CONNECTED) 14] ls /kafkagroup/controller
controller_epoch controller
[zk: localhost:2181(CONNECTED) 14] ls /kafkagroup/controller
[]
[zk: localhost:2181(CONNECTED) 15] get /kafkagroup/controller
{"version":1,"brokerid":1002,"timestamp":"1566648802297"}
[zk: localhost:2181(CONNECTED) 22] get /kafkagroup/controller_epoch
23我们可以看到当前的controller在1002上 在此之前发了23次controller的切换
我们手动到 1002节点上杀死kafka进程 [hadoop@kafka02-55-12$ jps 11665 Jps 10952 Kafka 11068 ZooKeeperMain 10495 QuorumPeerMain [hadoop@kafka02-55-12$ kill -9 10952 [hadoop@kafka02-55-12$ jps 11068 ZooKeeperMain 11678 Jps 10495 QuorumPeerMain
再看zk上的信息,相关信息已经同步到zk中了
[zk: localhost:2181(CONNECTED) 16] get /kafkagroup/controller
{"version":1,"brokerid":1003,"timestamp":"1566665835022"}
[zk: localhost:2181(CONNECTED) 22] get /kafkagroup/controller_epoch
24
[zk: localhost:2181(CONNECTED) 25] ls /kafkagroup/brokers
[ids, topics, seqid]
[zk: localhost:2181(CONNECTED) 26] ls /kafkagroup/brokers/ids
[1003, 1001]在后台日志中就会看到很多
[hadoop@kafka03-55-13 logs]$ vim state-change.log
[2019-08-25 01:01:07,886] TRACE [Controller id=1003 epoch=24] Received response {error_code=0} for request UPDATE_METADATA wit
h correlation id 7 sent to broker 10.211.55.13:9092 (id: 1003 rack: null) (state.change.logger)
[hadoop@kafka03-55-13 logs]$ pwd
/data/kafka/kafka-server-logs/logs
state改变的信息
[hadoop@kafka03-55-13 logs]$ tailf controller.log
[2019-08-25 01:05:42,295] TRACE [Controller id=1003] Leader imbalance ratio for broker 1002 is 1.0 (kafka.controller.KafkaCont
roller)
[2019-08-25 01:05:42,295] INFO [Controller id=1003] Starting preferred replica leader election for partitions (kafka.controll
er.KafkaController)
接下来,我们具体的分析一下,他到底内部发生了什么,如何切换的
当 controller 宕机时会触发 controller failover。每个 broker 都会在 zookeeper 的 "/controller" 节点注册 watcher,当 controller 宕机时 zookeeper 中的临时节点消失,所有存活的 broker 收到 fire 的通知,每个 broker 都尝试创建新的 controller path,只有一个竞选成功并当选为 controller。
当新的 controller 当选时,会触发 KafkaController.onControllerFailover 方法,在该方法中完成如下操作:
1、 读取并增加 Controller Epoch。
2、 在 reassignedPartitions Patch(/admin/reassign_partitions) 上注册 watcher。
3、 在 preferredReplicaElection Path(/admin/preferred_replica_election) 上注册 watcher。
4、 通过 partitionStateMachine 在 broker Topics Patch(/brokers/topics) 上注册 watcher。
5、 若 delete.topic.enable=true(默认值是 false),则 partitionStateMachine 在 Delete Topic Patch(/admin/delete_topics) 上注册 watcher。
6、 通过 replicaStateMachine在 Broker Ids Patch(/brokers/ids)上注册Watch。
7、 初始化 ControllerContext 对象,设置当前所有 topic,“活”着的 broker 列表,所有 partition 的 leader 及 ISR等。
8、 启动 replicaStateMachine 和 partitionStateMachine。
9、 将 brokerState 状态设置为 RunningAsController。
10、 将每个 partition 的 Leadership 信息发送给所有“活”着的 broker。
11、 若 auto.leader.rebalance.enable=true(默认值是true),则启动 partition-rebalance 线程。
12、 若 delete.topic.enable=true 且Delete Topic Patch(/admin/delete_topics)中有值,则删除相应的Topic。
可以看到,都是在zk上进行交互,controller的从新选举会依次通知 zk中相关的位置 并注册watcher ,在此过程中 就会发送 partition的leader的选举,还会发生partition-rebalanced 删除无用的topic等一系列操作(因为我们这里是直接考虑的最糟糕的情况就是broker宕机了一个,然而宕机的这台上就是controller)
consumer是如何消费消息的
重要概念:每个 Consumer 都划归到一个逻辑 Consumer Group 中,一个 Partition 只能被同一个 Consumer Group 中的一个 Consumer 消费,但可以被不同的 Consumer Group 消费。
若 Topic 的 Partition 数量为 p,Consumer Group 中订阅此 Topic 的 Consumer 数量为 c, 则:
p < c: 会有 c - p 个 consumer闲置,造成浪费
p > c: 一个 consumer 对应多个 partition
p = c: 一个 consumer 对应一个 partition
应该合理分配 Consumer 和 Partition 的数量,避免造成资源倾斜,
本人建议最好 Partiton 数目是 Consumer 数目的整数倍。
在consumer消费的过程中如何把partition分配给consumer?
也可以理解为consumer发生rebalance的过程是如何的?
生产过程中 Broker 要分配 Partition,消费过程这里,也要分配 Partition 给消费者。
类似 Broker 中选了一个 Controller 出来,消费也要从 Broker 中选一个 Coordinator,用于分配 Partition。// Coordinator 和 Controller 都是一个概念,协调者 组织者
当 Partition 或 Consumer 数量发生变化时,比如增加 Consumer,减少 Consumer(主动或被动),增加 Partition,都会进行 consumer的Rebalance。//发生rebalance发生在consumer端
见图: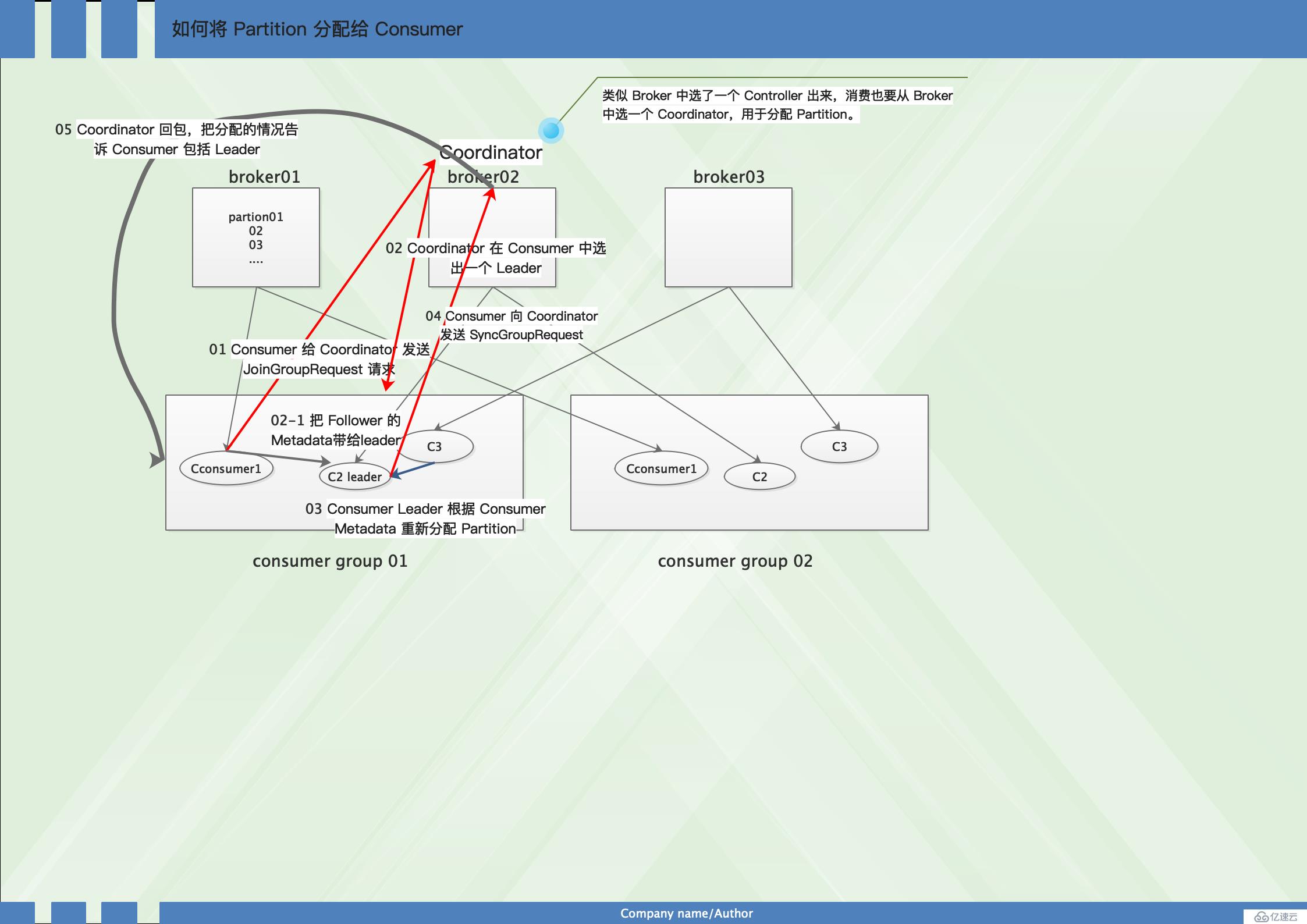
文字信息为:
1、Consumer 给 Coordinator 发送 JoinGroupRequest 请求。这时其他 Consumer 发 Heartbeat 请求过来时,Coordinator 会告诉他们,要 Rebalance了。其他 Consumer 也发送 JoinGroupRequest 请求。
2、Coordinator 在 Consumer 中选出一个 Leader,其他作为 Follower,通知给各个 Consumer,对于 Leader,还会把 Follower 的 Metadata 带给它。
3、Consumer Leader 根据 Consumer Metadata 重新分配 Partition。
4、Consumer 向 Coordinator 发送 SyncGroupRequest,其中 Leader 的 SyncGroupRequest 会包含分配的情况。
5、Coordinator 回包,把分配的情况告诉 Consumer,包括 Leader。
小结:
消费组与分区重平衡
可以看到,当新的消费者加入消费组,它会消费一个或多个分区,而这些分区之前是由其他消费者负责的;另外,当消费者离开消费组(比如重启、宕机等)时,它所消费的分区会分配给其他分区。这种现象称为重平衡(rebalance)。
重平衡是 Kafka 一个很重要的性质,这个性质保证了高可用和水平扩展。
不过也需要注意到,在重平衡期间,所有消费者都不能消费消息,因此会造成整个消费组短暂的不可用。而且,将分区进行重平衡也会导致原来的消费者状态过期,从而导致消费者需要重新更新状态,这段期间也会降低消费性能。
文字过程实例:
消费者通过定期发送心跳(hearbeat)到一个作为组协调者(group coordinator)的 broker 来保持在消费组内存活。这个 broker 不是固定的,每个消费组都可能不同。当消费者拉取消息或者提交时,便会发送心跳。
如果消费者超过一定时间没有发送心跳,那么它的会话(session)就会过期,组协调者会认为该消费者已经宕机,然后触发重平衡。可以看到,从消费者宕机到会话过期是有一定时间的,这段时间内该消费者的分区都不能进行消息消费;通常情况下,我们可以进行优雅关闭,这样消费者会发送离开的消息到组协调者,这样组协调者可以立即进行重平衡而不需要等待会话过期。
在 0.10.1 版本,Kafka 对心跳机制进行了修改,将发送心跳与拉取消息进行分离,这样使得发送心跳的频率不受拉取的频率影响。另外更高版本的 Kafka 支持配置一个消费者多长时间不拉取消息但仍然保持存活,这个配置可以避免活锁(livelock)。活锁,是指应用没有故障但是由于某些原因不能进一步消费。
接下来思考一个问题,consumer是如何取消息的 Consumer Fetch Message
Consumer 采用"拉模式"消费消息,这样 Consumer 可以自行决定消费的行为。
Consumer 调用 Poll(duration)从服务器拉取消息。拉取消息的具体行为由下面的配置项决定:
#consumer.properties #消费者最多 poll 多少个 record max.poll.records=500 #消费者 poll 时 partition 返回的最大数据量 max.partition.fetch.bytes=1048576 #Consumer 最大 poll 间隔 #超过此值服务器会认为此 consumer failed #并将此 consumer 踢出对应的 consumer group max.poll.interval.ms=300000
小结:
1、在 Partition 中,每个消息都有一个 Offset。新消息会被写到 Partition 末尾(最新的一个 Segment 文件末尾), 每个 Partition 上的消息是顺序消费的,不同的 Partition 之间消息的消费顺序是不确定的。
2、若一个 Consumer 消费多个 Partition, 则各个 Partition 之前消费顺序是不确定的,但在每个 Partition 上是顺序消费。
3、若来自不同 Consumer Group 的多个 Consumer 消费同一个 Partition,则各个 Consumer 之间的消费互不影响,每个 Consumer 都会有自己的 Offset。
举个官方小栗子: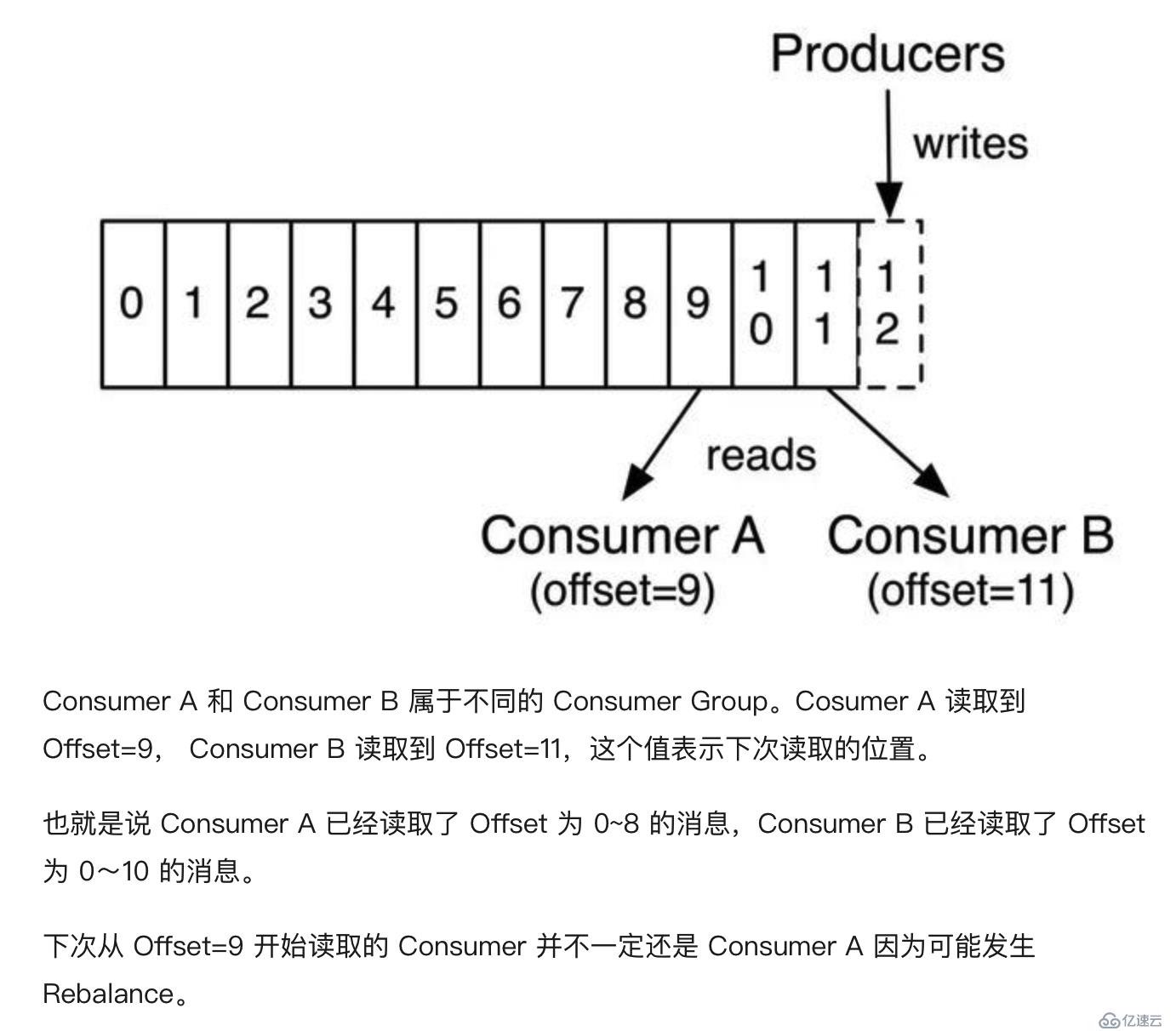
Offset 如何保存?
Consumer 消费 Partition 时,需要保存 Offset 记录当前消费位置。
Offset 可以选择自动提交或调用 Consumer 的 commitSync() 或 commitAsync() 手动提交,相关配置为:
#是否自动提交 offset enable.auto.commit=true #自动提交间隔。enable.auto.commit=true 时有效 auto.commit.interval.ms=5000 //enable.auto.commit 的默认值是 true;就是默认采用自动提交的机制。 auto.commit.interval.ms 的默认值是 5000,单位是毫秒。5 秒
Offset 保存在名叫 __consumeroffsets 的 Topic 中。写消息的 Key 由 GroupId、Topic、Partition 组成,Value 是 Offset。
一般情况下,每个 Key 的 Offset 都是缓存在内存中,查询的时候不用遍历 Partition,如果没有缓存,第一次就会遍历 Partition 建立缓存,然后查询返回
__consumeroffsets 的 Partition 数量由下面的 Server 配置决定:
offsets.topic.num.partitions=50
默然的consumeroffsets是没有repale副本的 需要我们通过在一开始的参数指定,或者通过后期的增加 consumeroffsets 的副本json的方式动态添加
auto.create.topics.enable=true default.replication.factor=2 num.partitions=3
经过测试上面的3个参数虽然在搭建好kafak的时候第一次指定了,但是 consumeroffsets副本数还是1个,这个的关键在于,配置文件中需要指定
kafka配置文件关于此参数解释如下:
############################# Internal Topic Settings ############################# 内部主题设置
#组元数据内部主题“consumer_offsets”和“transaction_state”的复制因子
#对于除开发测试之外的任何其他内容,建议使用大于1的值以确保可用性,例如设置成3。
The replication factor for the group metadata internal topics "__consumer_offsets" and "transaction_state"
For anything other than development testing, a value greater than 1 is recommended for to ensure availability such as 3.
offsets.topic.replication.factor=2
transaction.state.log.replication.factor=2
transaction.state.log.min.isr=2
//关于这3个参数,可以在修改kafka程序中指定的 consumer_offsets 的副本数
然后@上海-马吉辉 说只要num.partitions=3,__consumer_offsets副本数就是3,我测试不是 还是1
所以还是以offsets.topic.replication.factor参数控制为准
如果不是第一次启动kafka 那几个配置只有在初次启动生效的。 apache kafka 下载下来应该都默认是 1 吧,2.* 也是 1 啊。
可以这样修改
先停止kafka集群,删除每个broker data目录下所有consumeroffsets*
然后删除zookeeper下rmr /kafkatest/brokers/topics/consumer_offsets 然后重启kafka
消费一下,这个__consumer_offsets就会创建了
注意:是在第一次消费时,才创建这个topic的,不是broker集群启动就创建,还有那个trancation_state topic也是第一次使用事务的时候才会创建
小结:在生产上,没人去删zk里的内容,危险系数大,还是推荐动态扩副本,只要把json写对就好
控制 __consumer_offsets 的副本数 的关键参数为这3个。
Offset 保存在哪个分区上,即 __consumeroffsets 的分区机制,可以表示为
groupId.hashCode() mode groupMetadataTopicPartitionCount
groupMetadataTopicPartitionCount 是上面配置的分区数。因为一个 Partition 只能被同一个 Consumer Group 的一个 Consumer 消费,因此可以用 GroupId 表示此 Consumer 消费 Offeset 所在分区。
Kafka 中的可靠性保证有如下四点:
1、对于一个分区来说,它的消息是有序的。如果一个生产者向一个分区先写入消息A,然后写入消息B,那么消费者会先读取消息A再读取消息B。
2、当消息写入所有in-sync状态的副本后,消息才会认为已提交(committed)。这里的写入有可能只是写入到文件系统的缓存,不一定刷新到磁盘。生产者可以等待不同时机的确认,比如等待分区主副本写入即返回,后者等待所有in-sync状态副本写入才返回。
3、一旦消息已提交,那么只要有一个副本存活,数据不会丢失。
4、消费者只能读取到已提交的消息。
看到这里,我们对kafka有了全新的认识 ,kafka到底为什么这么厉害,下面总结了11点
1、批量处理
2、客户端优化
3、日志格式优化
4、日志编码
5、消息压缩
6、建立索引
7、分区
8、一致性
9、顺序写盘
10、页缓存 *
11、零拷贝
有关内存映射:
即便是顺序写入硬盘,硬盘的访问速度还是不可能追上内存。所以Kafka的数据并不是实时的写入硬盘,它充分利用了现代操作系统分页存储来利用内存提高I/O效率。 Memory Mapped Files(后面简称mmap)也被翻译成内存映射文件,它的工作原理是直接利用操作系统的Page来实现文件到物理内存的直接映射。完成映射之后你对物理内存的操作会被同步到硬盘上(操作系统在适当的时候)。 通过mmap,进程像读写硬盘一样读写内存,也不必关心内存的大小有虚拟内存为我们兜底。 mmap其实是Linux中的一个用来实现内存映射的函数,在Java NIO中可用MappedByteBuffer来实现内存映射。
Kafka消息压缩
生产者发送压缩消息,是把多个消息批量发送,把多个消息压缩成一个wrapped message来发送。和普通的消息一样,在磁盘上的数据和从producer发送来到broker的数据格式一模一样,发送给consumer的数据也是同样的格式。
看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注亿速云行业资讯频道,感谢您对亿速云的支持。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。