您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
postgres-xl是个好东西?为什么呢?
它可以搞oltp, 抗衡mysql, mysql没有分析函数功能
它可以搞oltp, 抗衡oracle, oracle生态弱, 没法实时
它对json支持好, 抗衡mongodb, mongodb用得人越来越少了。。。
它还恐怖地支持各种语言扩展, java, javascript, r, python, haskell。。。
并且开源免费,简单强大的没朋友。。。
它比greenpulm版本新: 它跟greenpulm本是一家人,都是MPP架构的postgresql集群
但是原生改造, 版本基本上与postgresql一致, greenpulm的版本升不动啊。。。
它比oracle RAC/Teradata便宜,免费使用
它比hadoop省资源,没有GC,基于C语言资源利用率高,并且生态圈丰富,可视化方便
它出道早,版本稳定性强。
postgres-xl分为以下组件:
a. gtm 负责全局事务
b. coordinator 处理分发执行
c. datanode 负责底层处理
datanode跟coordinator都 连接到gtm,
客户端连接到coordinator运行sql,
coordinator使用gtm进行一些事务功能分发给datanode执行
大数据的发展方向
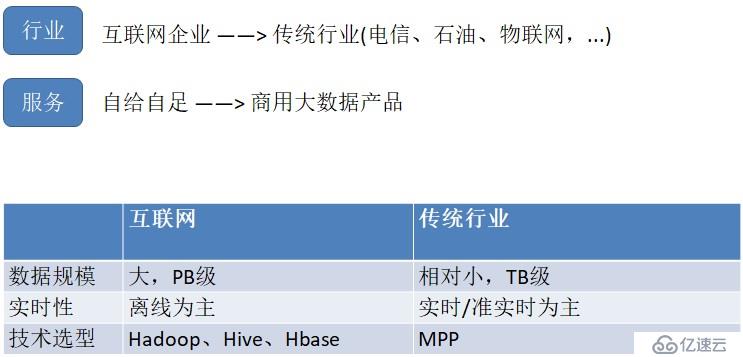
什么是MPP?
MPP (Massively Parallel Processing),即大规模并行处理,是分布式、并行、结构化数据库集群,具备高性能、高可用、高扩展特性,可以为超大规模数据管理提供高性价比的通用计算平台,广泛用于支撑各类数据仓库系统、BI 系统。
MPP架构特征:
•任务并行执行
•数据分布式存储(本地化)
•分布式计算
•横向扩展
思考对比
Oracle集群的特点:每个节点全量存储
Mysql热备的特点:主从,每个节点全量存储
MPP——分布式关系数据库
GreenPlum:基于Postgres XL 8.2进行封装,多年没升级过。
Mysql Cluster:刚出来两年,稳定性和性能比较差。
Postgres XL 与 Postgres LL ,是Postgresql数据库两种集群模式,Postgres XL是当今主流MPP
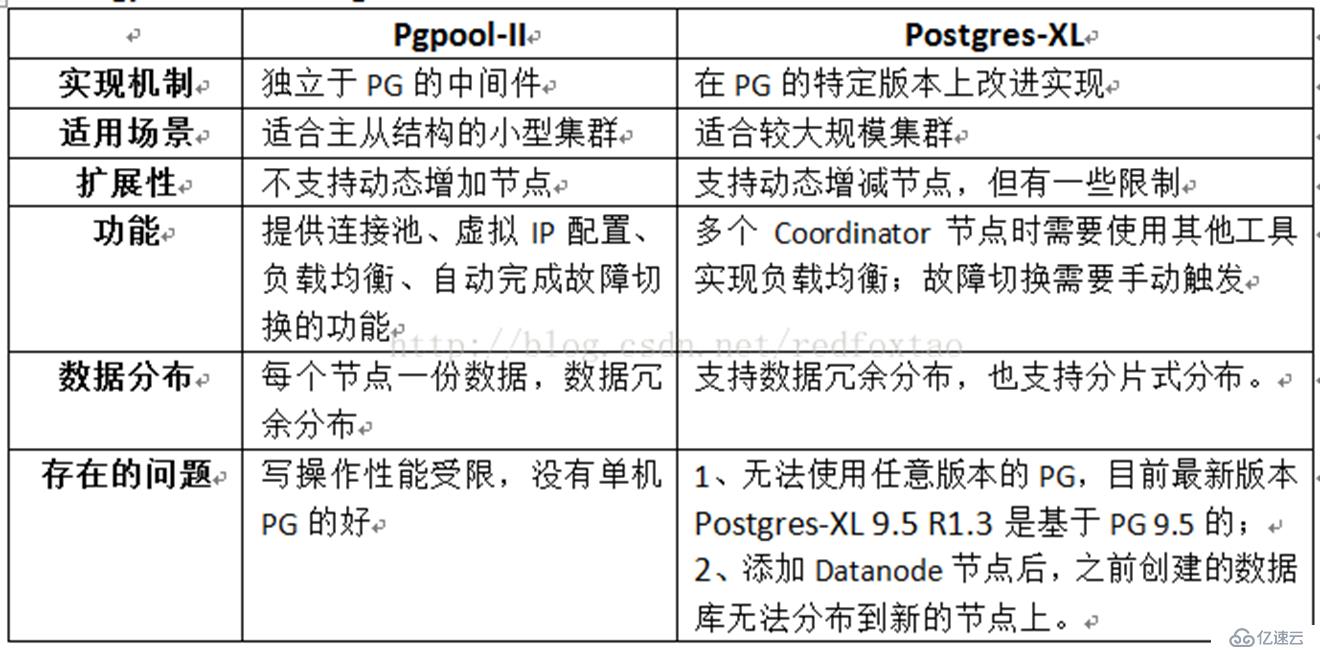
Postgres XL 集群架构

GTM:Global Transaction Manager
Coordinator:协调器
Datanode:数据节点
GTM-Proxy:GTM代理器
组件介绍
Global Transaction Monitor (GTM)
全局事务管理器,确保群集范围内的事务一致性。 GTM负责发放事务ID和快照作为其多版本并发控制的一部分。
集群可选地配置一个备用GTM(GTM Standby),以改进可用性。此外,可以在协调器间配置代理GTM, 可用于改善可扩展性,减少GTM的通信量。
GTM Standby
GTM的备节点,在pgxc,pgxl中,GTM控制所有的全局事务分配,如果出现问题,就会导致整个集群不可用,为了增加可用性,增加该备用节点。当GTM出现问题时,GTM Standby可以升级为GTM,保证集群正常工作。
GTM-Proxy
GTM需要与所有的Coordinators通信,为了降低压力,可以在每个Coordinator机器上部署一个GTM-Proxy。
Coordinator
协调员管理用户会话,并与GTM和数据节点进行交互。协调员解析,产生查询计划,并给语句中的每一个组件发送下一个序列化的全局性计划。
通常此服务和数据节点部署在一起。
正式安装

Note: 其实在生产环境,如果你集群的数量少于20台的话,甚至可以不需要使用gtm-proxy
#1)System Initialization Optimization on every nodes cat >> /etc/security/limits.conf << EOF * hard memlock unlimited * soft memlock unlimited * - nofile 65535 EOF setenforce 0 sed -i 's/^SELINUX=.*$/SELINUX=disabled/' /etc/selinux/config systemctl stop firewalld.service systemctl disable firewalld.service cat >/etc/hosts <<EOF 172.31.1.81 neo4j01 172.31.4.146 neo4j02 172.31.3.178 neo4j03 172.31.8.178 neo4j04 EOF #2)create postgres user on every nodes useradd postgres echo Ad@sd119|passwd --stdin postgres echo 'postgres ALL=(ALL) NOPASSWD: ALL' >>/etc/sudoers ###################################################################### #3)Configure ssh authentication to avoid inputing password for pgxc_ctl(run this commad on every nodes) ###################################################################### su - postgres ssh-keygen -t rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 600 authorized_keys cat ~/.ssh/id_rsa.pub | ssh neo4j01 'cat >> ~/.ssh/authorized_keys' ############################################ #4)Install dependency packages on every nodes# ############################################ sudo yum install -y flex bison readline-devel zlib-devel openjade docbook-style-dsssl gcc bzip2 e2fsprogs-devel uuid-devel libuuid-devel make wget wget -c http://download.cashalo.com/schema/postgres-xl-9.5r1.6.tar.bz2 && tar jxf postgres-xl-9.5r1.6.tar.bz2 cd postgres-xl-9.5r1.6 ./configure --prefix=/home/postgres/pgxl9.5 --with-uuid=ossp --with-uuid=ossp && make && make install && cd contrib/ && make && make install #5)Configuring environment variables on every nodes cat >>/home/postgres/.bashrc <<EOF export PGHOME=/home/postgres/pgxl9.5 export LD_LIBRARY_PATH=\$PGHOME/lib:\$LD_LIBRARY_PATH export PATH=\$PGHOME/bin:\$PATH EOF source /home/postgres/.bashrc #6)create data dirsctory on every nodes mkdir -p /home/postgres/data/ #7) just run command pgxc_ctl on neo4j01 pgxc_ctl # then input command prepare prepare # finally run q to exit q #8) Edit file pgxc_ctl.conf (just do int on neo4j01) vim /home/postgres/pgxc_ctl/pgxc_ctl.conf ########################################### #!/usr/bin/env bash pgxcInstallDir=/home/postgres/pgxl9.5 pgxlDATA=/home/postgres/data #---- OVERALL ----------------------------------------------------------------------------- # pgxcOwner=postgres # owner of the Postgres-XC databaseo cluster. Here, we use this # both as linus user and database user. This must be # the super user of each coordinator and datanode. pgxcUser=postgres # OS user of Postgres-XC owner tmpDir=/tmp # temporary dir used in XC servers localTmpDir=$tmpDir # temporary dir used here locally configBackup=n # If you want config file backup, specify y to this value. #configBackupHost=pgxc-linker # host to backup config file #configBackupDir=$HOME/pgxc # Backup directory #configBackupFile=pgxc_ctl.bak # Backup file name --> Need to synchronize when original changed. #---- GTM ------------------------------------------------------------------------------------ # GTM is mandatory. You must have at least (and only) one GTM master in your Postgres-XC cluster. # If GTM crashes and you need to reconfigure it, you can do it by pgxc_update_gtm command to update # GTM master with others. Of course, we provide pgxc_remove_gtm command to remove it. This command # will not stop the current GTM. It is up to the operator. #---- GTM Master ----------------------------------------------- #---- Overall ---- gtmName=gtm1 gtmMasterServer=neo4j01 gtmMasterPort=6666 gtmMasterDir=$pgxlDATA/gtm1 #---- Configuration --- gtmExtraConfig=none # Will be added gtm.conf for both Master and Slave (done at initilization only) gtmMasterSpecificExtraConfig=none # Will be added to Master's gtm.conf (done at initialization only) #---- GTM Slave ----------------------------------------------- # Because GTM is a key component to maintain database consistency, you may want to configure GTM slave # for backup. #---- Overall ------ gtmSlave=y # Specify y if you configure GTM Slave. Otherwise, GTM slave will not be configured and # all the following variables will be reset. gtmSlaveName=gtm2 gtmSlaveServer=neo4j02 # value none means GTM slave is not available. Give none if you don't configure GTM Slave. gtmSlavePort=6666 # Not used if you don't configure GTM slave. gtmSlaveDir=$pgxlDATA/gtm2 # Not used if you don't configure GTM slave. # Please note that when you have GTM failover, then there will be no slave available until you configure the slave # again. (pgxc_add_gtm_slave function will handle it) #---- Configuration ---- gtmSlaveSpecificExtraConfig=none # Will be added to Slave's gtm.conf (done at initialization only) #---- GTM Proxy ------------------------------------------------------------------------------------------------------- # GTM proxy will be selected based upon which server each component runs on. # When fails over to the slave, the slave inherits its master's gtm proxy. It should be # reconfigured based upon the new location. # # To do so, slave should be restarted. So pg_ctl promote -> (edit postgresql.conf and recovery.conf) -> pg_ctl restart # # You don't have to configure GTM Proxy if you dont' configure GTM slave or you are happy if every component connects # to GTM Master directly. If you configure GTL slave, you must configure GTM proxy too. #---- Shortcuts ------ gtmProxyDir=$pgxlDATA/gtm_proxy #---- Overall ------- gtmProxy=n # Specify y if you conifugre at least one GTM proxy. You may not configure gtm proxies # only when you dont' configure GTM slaves. # If you specify this value not to y, the following parameters will be set to default empty values. # If we find there're no valid Proxy server names (means, every servers are specified # as none), then gtmProxy value will be set to "n" and all the entries will be set to # empty values. #gtmProxyNames=(gtm_pxy1 gtm_pxy2 gtm_pxy3 gtm_pxy4) # No used if it is not configured #gtmProxyServers=(neo4j01 neo4j02 neo4j03 neo4j04) # Specify none if you dont' configure it. #gtmProxyPorts=(6660 6666 6666 6666) # Not used if it is not configured. #gtmProxyDirs=($gtmProxyDir $gtmProxyDir $gtmProxyDir $gtmProxyDir) # Not used if it is not configured. #---- Configuration ---- gtmPxyExtraConfig=none # Extra configuration parameter for gtm_proxy. Coordinator section has an example. gtmPxySpecificExtraConfig=(none none none none) #---- Coordinators ---------------------------------------------------------------------------------------------------- #---- shortcuts ---------- coordMasterDir=$pgxlDATA/coord coordSlaveDir=$pgxlDATA/coord_slave coordArchLogDir=$pgxlDATA/coord_archlog #---- Overall ------------ coordNames=(coord1 coord2 coord3 coord4) # Master and slave use the same name coordPorts=(5432 5432 5432 5432) # Master ports poolerPorts=(6667 6667 6667 6667) # Master pooler ports #coordPgHbaEntries=(192.168.29.0/24) # Assumes that all the coordinator (master/slave) accepts coordPgHbaEntries=(0.0.0.0/0) # the same connection # This entry allows only $pgxcOwner to connect. # If you'd like to setup another connection, you should # supply these entries through files specified below. # Note: The above parameter is extracted as "host all all 0.0.0.0/0 trust". If you don't want # such setups, specify the value () to this variable and suplly what you want using coordExtraPgHba # and/or coordSpecificExtraPgHba variables. #coordPgHbaEntries=(::1/128) # Same as above but for IPv6 addresses #---- Master ------------- coordMasterServers=(neo4j01 neo4j02 neo4j03 neo4j04) # none means this master is not available coordMasterDirs=($coordMasterDir $coordMasterDir $coordMasterDir $coordMasterDir) coordMaxWALsernder=0 # max_wal_senders: needed to configure slave. If zero value is specified, # it is expected to supply this parameter explicitly by external files # specified in the following. If you don't configure slaves, leave this value to zero. coordMaxWALSenders=($coordMaxWALsernder $coordMaxWALsernder $coordMaxWALsernder $coordMaxWALsernder) # max_wal_senders configuration for each coordinator. #---- Slave ------------- coordSlave=n # Specify y if you configure at least one coordiantor slave. Otherwise, the following # configuration parameters will be set to empty values. # If no effective server names are found (that is, every servers are specified as none), # then coordSlave value will be set to n and all the following values will be set to # empty values. #coordSlaveSync=y # Specify to connect with synchronized mode. #coordSlaveServers=(node07 node08 node09 node06) # none means this slave is not available #coordSlavePorts=(20004 20005 20004 20005) # Master ports #coordSlavePoolerPorts=(20010 20011 20010 20011) # Master pooler ports #coordSlaveDirs=($coordSlaveDir $coordSlaveDir $coordSlaveDir $coordSlaveDir) #coordArchLogDirs=($coordArchLogDir $coordArchLogDir $coordArchLogDir $coordArchLogDir) #---- Configuration files--- # Need these when you'd like setup specific non-default configuration # These files will go to corresponding files for the master. # You may supply your bash script to setup extra config lines and extra pg_hba.conf entries # Or you may supply these files manually. coordExtraConfig=coordExtraConfig # Extra configuration file for coordinators. # This file will be added to all the coordinators' # postgresql.conf # Pleae note that the following sets up minimum parameters which you may want to change. # You can put your postgresql.conf lines here. cat > $coordExtraConfig <<EOF #================================================ # Added to all the coordinator postgresql.conf # Original: $coordExtraConfig log_destination = 'stderr' logging_collector = on log_directory = 'pg_log' listen_addresses = '*' max_connections = 50 EOF # Additional Configuration file for specific coordinator master. # You can define each setting by similar means as above. coordSpecificExtraConfig=(none none none none) coordExtraPgHba=none # Extra entry for pg_hba.conf. This file will be added to all the coordinators' pg_hba.conf coordSpecificExtraPgHba=(none none none none) #----- Additional Slaves ----- # # Please note that this section is just a suggestion how we extend the configuration for # multiple and cascaded replication. They're not used in the current version. # #coordAdditionalSlaves=n # Additional slave can be specified as follows: where you #coordAdditionalSlaveSet=(cad1) # Each specifies set of slaves. This case, two set of slaves are # # configured #cad1_Sync=n # All the slaves at "cad1" are connected with asynchronous mode. # # If not, specify "y" # # The following lines specifies detailed configuration for each # # slave tag, cad1. You can define cad2 similarly. #cad1_Servers=(node08 node09 node06 node07) # Hosts #cad1_dir=$HOME/pgxc/nodes/coord_slave_cad1 #cad1_Dirs=($cad1_dir $cad1_dir $cad1_dir $cad1_dir) #cad1_ArchLogDir=$HOME/pgxc/nodes/coord_archlog_cad1 #cad1_ArchLogDirs=($cad1_ArchLogDir $cad1_ArchLogDir $cad1_ArchLogDir $cad1_ArchLogDir) #---- Datanodes ------------------------------------------------------------------------------------------------------- #---- Shortcuts -------------- datanodeMasterDir=$pgxlDATA/dn_master datanodeSlaveDir=$pgxlDATA/dn_slave datanodeArchLogDir=$pgxlDATA/datanode_archlog #---- Overall --------------- #primaryDatanode=datanode1 # Primary Node. # At present, xc has a priblem to issue ALTER NODE against the primay node. Until it is fixed, the test will be done # without this feature. primaryDatanode=dn1 # Primary Node. datanodeNames=(dn1 dn2 dn3 dn4) datanodePorts=(5433 5433 5433 5433) # Master ports datanodePoolerPorts=(6668 6668 6668 6668) # Master pooler ports datanodePgHbaEntries=(0.0.0.0/0) # Assumes that all the coordinator (master/slave) accepts # the same connection # This list sets up pg_hba.conf for $pgxcOwner user. # If you'd like to setup other entries, supply them # through extra configuration files specified below. # Note: The above parameter is extracted as "host all all 0.0.0.0/0 trust". If you don't want # such setups, specify the value () to this variable and suplly what you want using datanodeExtraPgHba # and/or datanodeSpecificExtraPgHba variables. #datanodePgHbaEntries=(::1/128) # Same as above but for IPv6 addresses #---- Master ---------------- datanodeMasterServers=(neo4j01 neo4j02 neo4j03 neo4j04) # none means this master is not available. # This means that there should be the master but is down. # The cluster is not operational until the master is # recovered and ready to run. datanodeMasterDirs=($datanodeMasterDir $datanodeMasterDir $datanodeMasterDir $datanodeMasterDir) datanodeMaxWalSender=0 # max_wal_senders: needed to configure slave. If zero value is # specified, it is expected this parameter is explicitly supplied # by external configuration files. # If you don't configure slaves, leave this value zero. datanodeMaxWALSenders=($datanodeMaxWalSender $datanodeMaxWalSender $datanodeMaxWalSender $datanodeMaxWalSender) # max_wal_senders configuration for each datanode #---- Slave ----------------- datanodeSlave=n # Specify y if you configure at least one coordiantor slave. Otherwise, the following # configuration parameters will be set to empty values. # If no effective server names are found (that is, every servers are specified as none), # then datanodeSlave value will be set to n and all the following values will be set to # empty values. #datanodeSlaveServers=(node07 node08 node09 node06) # value none means this slave is not available #datanodeSlavePorts=(20008 20009 20008 20009) # value none means this slave is not available #datanodeSlavePoolerPorts=(20012 20013 20012 20013) # value none means this slave is not available #datanodeSlaveSync=y # If datanode slave is connected in synchronized mode #datanodeSlaveDirs=($datanodeSlaveDir $datanodeSlaveDir $datanodeSlaveDir $datanodeSlaveDir) #datanodeArchLogDirs=( $datanodeArchLogDir $datanodeArchLogDir $datanodeArchLogDir $datanodeArchLogDir ) # ---- Configuration files --- # You may supply your bash script to setup extra config lines and extra pg_hba.conf entries here. # These files will go to corresponding files for the master. # Or you may supply these files manually. datanodeExtraConfig=none # Extra configuration file for datanodes. This file will be added to all the # datanodes' postgresql.conf datanodeSpecificExtraConfig=(none none none none) datanodeExtraPgHba=none # Extra entry for pg_hba.conf. This file will be added to all the datanodes' postgresql.conf datanodeSpecificExtraPgHba=(none none none none) #----- Additional Slaves ----- datanodeAdditionalSlaves=n # Additional slave can be specified as follows: where you # datanodeAdditionalSlaveSet=(dad1 dad2) # Each specifies set of slaves. This case, two set of slaves are # configured # dad1_Sync=n # All the slaves at "cad1" are connected with asynchronous mode. # If not, specify "y" # The following lines specifies detailed configuration for each # slave tag, cad1. You can define cad2 similarly. # dad1_Servers=(node08 node09 node06 node07) # Hosts # dad1_dir=$HOME/pgxc/nodes/coord_slave_cad1 # dad1_Dirs=($cad1_dir $cad1_dir $cad1_dir $cad1_dir) # dad1_ArchLogDir=$HOME/pgxc/nodes/coord_archlog_cad1 # dad1_ArchLogDirs=($cad1_ArchLogDir $cad1_ArchLogDir $cad1_ArchLogDir $cad1_ArchLogDir) #---- WAL archives ------------------------------------------------------------------------------------------------- walArchive=n # If you'd like to configure WAL archive, edit this section. ####################################################### #8) when u first time to setup cluster(run it just on neo4j01) pgxc_ctl -c /home/postgres/pgxc_ctl/pgxc_ctl.conf init all #9) start cluster(run it just on neo4j01) pgxc_ctl -c /home/postgres/pgxc_ctl/pgxc_ctl.conf start all #10) stop cluster(run it just on neo4j01) pgxc_ctl -c /home/postgres/pgxc_ctl/pgxc_ctl.conf stop all #11) check every one is running(run it just on neo4j01) pgxc_ctl monitor all #12) view System Table (run it just on neo4j01) psql -p5432 select * from pgxc_node;
postgres-XL 下存在两种数据表,分别是replication表和distribute表
REPLICATION复制表:各个datanode节点中,表的数据完全相同,也就是说,插入数据时,会分别在每个datanode节点插入相同数据。读数据时,只需要读任意一个datanode节点上的数据。小表采用。
建表语法:
postgres=# create table rep(col1 int,col2 int)distribute by replication;
DISTRIBUTE表 :会将插入的数据,按照拆分规则,分配到不同的datanode节点中存储,也就是sharding技术。每个datanode节点只保存了部分数据,通过coordinate节点可以查询完整的数据视图。分布式存储,大表采用,默认
postgres=# CREATE TABLE dist(col1 int, col2 int) DISTRIBUTE BY HASH(col1);
如何验证分布式存储?
分别插入100行数据:
postgres=# INSERT INTO rep SELECT generate_series(1,100), generate_series(101, 200); postgres=# INSERT INTO dist SELECT generate_series(1,100), generate_series(101, 200);
psql -p 5432,通过Coordinater 访问查询完整的数据视图;
psql -p 5433,5433是Datanode的端口,此时只访问该单个节点
如何链接到指定的数据库呢?看下面的例子
psql -p 5432 aa ,aa为指定的库名,不指定时默认是postgres库,相当于hive里的default库
查询这个分布表数据在每个节点的分布:
postgres=# SELECT xc_node_id, count(*) FROM dist GROUP BY xc_node_id; xc_node_id | count ------------+------- -700122826 | 19 352366662 | 27 -560021589 | 23 823103418 | 31 (4 rows)
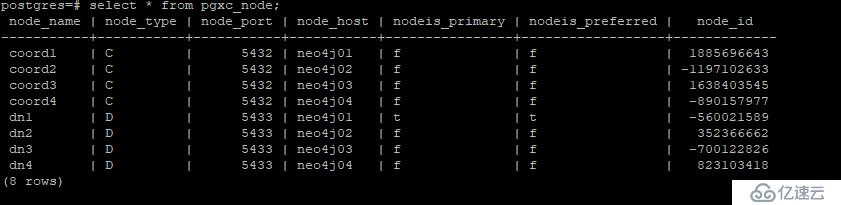
查询每个节点的ID信息
postgres=# select * from pgxc_node;
我们再来看看复制表
postgres=# select xc_node_id,count(*) from rep group by xc_node_id; xc_node_id | count ------------+------- -560021589 | 100 (1 row)
因为我们是在neo4j01节点上查询的,所以显示的id就是neo4j01节点的id;同理,如果我们是在其它节点查询的话那就显示其它节点的id。也就是说当我们查询复制表的时候,它只会走一个节点,不会走多个节点。针对这个特点,如果未来数据量很大,我们查询的时候,可以走负载均衡。
https://www.cnblogs.com/sfnz/p/7908380.html
Psql是PostgreSQL的一个命令行交互式客户端工具。PostgreSQL 一些命令、用法、语法,在Postgres xl集群都是通用的。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。