жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
е°Ҹзј–з»ҷеӨ§е®¶еҲҶдә«дёҖдёӢstormеҰӮдҪ•е®һзҺ°еҚ•жңәзүҲе®үиЈ…пјҢзӣёдҝЎеӨ§йғЁеҲҶдәәйғҪиҝҳдёҚжҖҺд№ҲдәҶи§ЈпјҢеӣ жӯӨеҲҶдә«иҝҷзҜҮж–Үз« з»ҷеӨ§е®¶еҸӮиҖғдёҖдёӢпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеӨ§жңү收иҺ·пјҢдёӢйқўи®©жҲ‘们дёҖиө·еҺ»дәҶи§ЈдёҖдёӢеҗ§пјҒ
StormжҳҜдёҖдёӘеҲҶеёғејҸзҡ„гҖҒй«ҳе®№й”ҷзҡ„е®һж—¶и®Ўз®—зі»з»ҹгҖӮ
StormеҜ№дәҺе®һж—¶и®Ўз®—зҡ„зҡ„ж„Ҹд№үзӣёеҪ“дәҺHadoopеҜ№дәҺжү№еӨ„зҗҶзҡ„ж„Ҹд№үгҖӮHadoopдёәжҲ‘们жҸҗдҫӣдәҶMapе’ҢReduceеҺҹиҜӯпјҢдҪҝжҲ‘们еҜ№ж•°жҚ®иҝӣиЎҢжү№еӨ„зҗҶеҸҳзҡ„йқһеёёзҡ„з®ҖеҚ•е’ҢдјҳзҫҺгҖӮеҗҢж ·пјҢStormд№ҹеҜ№ж•°жҚ®зҡ„е®һж—¶и®Ўз®—жҸҗдҫӣдәҶз®ҖеҚ•Spoutе’ҢBoltеҺҹиҜӯгҖӮ
StormйҖӮз”Ёзҡ„еңәжҷҜпјҡ
1гҖҒжөҒж•°жҚ®еӨ„зҗҶпјҡStormеҸҜд»Ҙз”ЁжқҘз”ЁжқҘеӨ„зҗҶжәҗжәҗдёҚж–ӯзҡ„ж¶ҲжҒҜпјҢ并е°ҶеӨ„зҗҶд№ӢеҗҺзҡ„з»“жһңдҝқеӯҳеҲ°жҢҒд№…еҢ–д»ӢиҙЁдёӯгҖӮ
2гҖҒеҲҶеёғејҸRPCпјҡз”ұдәҺStormзҡ„еӨ„зҗҶ组件йғҪжҳҜеҲҶеёғејҸзҡ„пјҢиҖҢдё”еӨ„зҗҶ延иҝҹйғҪжһҒдҪҺпјҢжүҖд»ҘеҸҜд»ҘStormеҸҜд»ҘеҒҡдёәдёҖдёӘйҖҡз”Ёзҡ„еҲҶеёғејҸRPCжЎҶжһ¶жқҘдҪҝз”ЁгҖӮ
еңЁиҝҷдёӘж•ҷзЁӢйҮҢйқўжҲ‘们е°ҶеӯҰд№ еҰӮдҪ•еҲӣе»әTopologies, 并且жҠҠtopologiesйғЁзҪІеҲ°stormзҡ„йӣҶзҫӨйҮҢйқўеҺ»гҖӮJavaе°ҶжҳҜжҲ‘们主иҰҒзҡ„зӨәиҢғиҜӯиЁҖпјҢ дёӘеҲ«дҫӢеӯҗдјҡдҪҝз”Ёpythonд»Ҙжј”зӨәstormзҡ„еӨҡиҜӯиЁҖзү№жҖ§гҖӮ
иҝҷдёӘж•ҷзЁӢдҪҝз”Ёstorm-starterйЎ№зӣ®йҮҢйқўзҡ„дҫӢеӯҗгҖӮжҲ‘жҺЁиҚҗдҪ 们дёӢиҪҪиҝҷдёӘйЎ№зӣ®зҡ„д»Јз Ғ并且и·ҹзқҖж•ҷзЁӢдёҖиө·еҒҡгҖӮе…ҲиҜ»дёҖдёӢпјҡй…ҚзҪ®stormејҖеҸ‘зҺҜеўғе’Ңж–°е»әдёҖдёӘstromйЎ№зӣ®иҝҷдёӨзҜҮж–Үз« жҠҠдҪ зҡ„жңәеҷЁи®ҫзҪ®еҘҪгҖӮ
stormзҡ„йӣҶзҫӨиЎЁйқўдёҠзңӢе’Ңhadoopзҡ„йӣҶзҫӨйқһеёёеғҸгҖӮдҪҶжҳҜеңЁHadoopдёҠйқўдҪ иҝҗиЎҢзҡ„жҳҜMapReduceзҡ„Job, иҖҢеңЁStormдёҠйқўдҪ иҝҗиЎҢзҡ„жҳҜTopologyгҖӮе®ғ们жҳҜйқһеёёдёҚдёҖж ·зҡ„ вҖ” дёҖдёӘе…ій”®зҡ„еҢәеҲ«жҳҜпјҡ дёҖдёӘMapReduce JobжңҖз»Ҳдјҡз»“жқҹпјҢ иҖҢдёҖдёӘTopologyиҝҗж°ёиҝңиҝҗиЎҢпјҲйҷӨйқһдҪ жҳҫејҸзҡ„жқҖжҺүд»–пјүгҖӮ
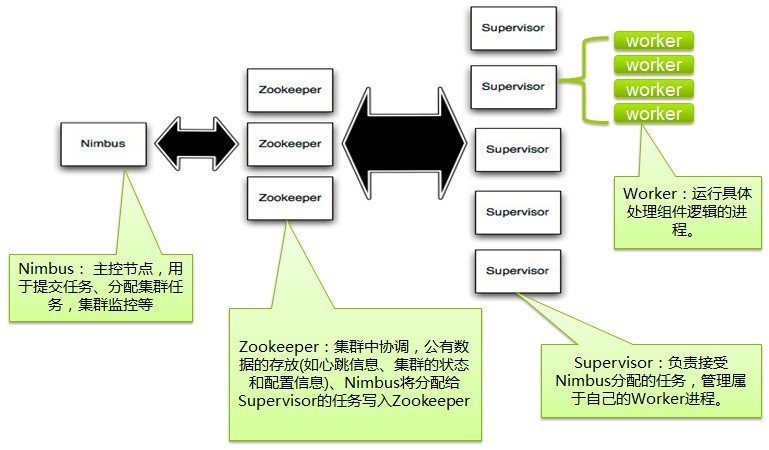
еңЁStormзҡ„йӣҶзҫӨйҮҢйқўжңүдёӨз§ҚиҠӮзӮ№пјҡ жҺ§еҲ¶иҠӮзӮ№(master node)е’Ңе·ҘдҪңиҠӮзӮ№(worker node)гҖӮжҺ§еҲ¶иҠӮзӮ№дёҠйқўиҝҗиЎҢдёҖдёӘеҗҺеҸ°зЁӢеәҸпјҡ NimbusпјҢ е®ғзҡ„дҪңз”Ёзұ»дјјHadoopйҮҢйқўзҡ„JobTrackerгҖӮNimbusиҙҹиҙЈеңЁйӣҶзҫӨйҮҢйқўеҲҶеёғд»Јз ҒпјҢеҲҶй…Қе·ҘдҪңз»ҷжңәеҷЁпјҢ 并且зӣ‘жҺ§зҠ¶жҖҒгҖӮ
жҜҸдёҖдёӘе·ҘдҪңиҠӮзӮ№дёҠйқўиҝҗиЎҢдёҖдёӘеҸ«еҒҡSupervisorзҡ„иҠӮзӮ№пјҲзұ»дјј TaskTrackerпјүгҖӮSupervisorдјҡзӣ‘еҗ¬еҲҶй…Қз»ҷе®ғйӮЈеҸ°жңәеҷЁзҡ„е·ҘдҪңпјҢж №жҚ®йңҖиҰҒ еҗҜеҠЁ/е…ій—ӯе·ҘдҪңиҝӣзЁӢгҖӮжҜҸдёҖдёӘе·ҘдҪңиҝӣзЁӢжү§иЎҢдёҖдёӘTopologyпјҲзұ»дјј Jobпјүзҡ„дёҖдёӘеӯҗйӣҶпјӣдёҖдёӘиҝҗиЎҢзҡ„Topologyз”ұиҝҗиЎҢеңЁеҫҲеӨҡжңәеҷЁдёҠзҡ„еҫҲеӨҡе·ҘдҪңиҝӣзЁӢ WorkerпјҲзұ»дјј Childпјүз»„жҲҗгҖӮ
storm topologyз»“жһ„
boltеҸҜд»ҘжҺҘ收任ж„ҸеӨҡдёӘиҫ“е…ҘstreamпјҢ дҪңдёҖдәӣеӨ„зҗҶпјҢ жңүдәӣboltеҸҜиғҪиҝҳдјҡеҸ‘е°„дёҖдәӣж–°зҡ„streamгҖӮдёҖдәӣеӨҚжқӮзҡ„жөҒиҪ¬жҚўпјҢ жҜ”еҰӮд»ҺдёҖдәӣtweetйҮҢйқўи®Ўз®—еҮәзғӯй—ЁиҜқйўҳпјҢ йңҖиҰҒеӨҡдёӘжӯҘйӘӨпјҢ д»ҺиҖҢд№ҹе°ұйңҖиҰҒеӨҡдёӘboltгҖӮ BoltеҸҜд»ҘеҒҡд»»дҪ•дәӢжғ…: иҝҗиЎҢеҮҪж•°пјҢ иҝҮж»Өtuple, еҒҡдёҖдәӣиҒҡеҗҲпјҢ еҒҡдёҖдәӣеҗҲ并д»ҘеҸҠи®ҝй—®ж•°жҚ®еә“зӯүзӯүгҖӮ
BoltеӨ„зҗҶиҫ“е…Ҙзҡ„StreamпјҢ并дә§з”ҹж–°зҡ„иҫ“еҮәStreamгҖӮBoltеҸҜд»Ҙжү§иЎҢиҝҮж»ӨгҖҒеҮҪж•°ж“ҚдҪңгҖҒJoinгҖҒж“ҚдҪңж•°жҚ®еә“зӯүд»»дҪ•ж“ҚдҪңгҖӮBoltжҳҜдёҖдёӘиў«еҠЁзҡ„и§’иүІпјҢе…¶жҺҘеҸЈдёӯжңүдёҖдёӘexecute(Tuple input)ж–№жі•пјҢеңЁжҺҘ收еҲ°ж¶ҲжҒҜд№ӢеҗҺдјҡи°ғз”ЁжӯӨеҮҪж•°пјҢз”ЁжҲ·еҸҜд»ҘеңЁжӯӨж–№жі•дёӯжү§иЎҢиҮӘе·ұзҡ„еӨ„зҗҶйҖ»иҫ‘гҖӮ
topologyз»“жһ„
topologyйҮҢйқўзҡ„жҜҸдёҖдёӘиҠӮзӮ№йғҪжҳҜ并иЎҢиҝҗиЎҢзҡ„гҖӮ еңЁдҪ зҡ„topologyйҮҢйқўпјҢ дҪ еҸҜд»ҘжҢҮе®ҡжҜҸдёӘиҠӮзӮ№зҡ„并иЎҢеәҰпјҢ stormеҲҷдјҡеңЁйӣҶзҫӨйҮҢйқўеҲҶй…ҚйӮЈд№ҲеӨҡзәҝзЁӢжқҘеҗҢж—¶и®Ўз®—гҖӮ
дёҖдёӘtopologyдјҡдёҖзӣҙиҝҗиЎҢзӣҙеҲ°дҪ жҳҫејҸеҒңжӯўе®ғгҖӮstormиҮӘеҠЁйҮҚж–°еҲҶй…ҚдёҖдәӣиҝҗиЎҢеӨұиҙҘзҡ„д»»еҠЎпјҢ 并且stormдҝқиҜҒдҪ дёҚдјҡжңүж•°жҚ®дёўеӨұпјҢ еҚідҪҝеңЁдёҖдәӣжңәеҷЁж„ҸеӨ–еҒңжңә并且ж¶ҲжҒҜиў«дёўжҺүзҡ„жғ…еҶөдёӢгҖӮ
stormдҪҝз”ЁtupleжқҘдҪңдёәе®ғзҡ„ж•°жҚ®жЁЎеһӢгҖӮжҜҸдёӘtupleжҳҜдёҖе ҶеҖјпјҢжҜҸдёӘеҖјжңүдёҖдёӘеҗҚеӯ—пјҢ并且жҜҸдёӘеҖјеҸҜд»ҘжҳҜд»»дҪ•зұ»еһӢпјҢ еңЁжҲ‘зҡ„зҗҶи§ЈйҮҢйқўдёҖдёӘtupleеҸҜд»ҘзңӢдҪңдёҖдёӘжІЎжңүж–№жі•зҡ„javaеҜ№иұЎгҖӮжҖ»дҪ“жқҘзңӢпјҢstormж”ҜжҢҒжүҖжңүзҡ„еҹәжң¬зұ»еһӢгҖҒеӯ—з¬ҰдёІд»ҘеҸҠеӯ—иҠӮж•°з»„дҪңдёәtupleзҡ„еҖјзұ»еһӢгҖӮдҪ д№ҹеҸҜд»ҘдҪҝз”ЁдҪ иҮӘе·ұе®ҡд№үзҡ„зұ»еһӢжқҘдҪңдёәеҖјзұ»еһӢпјҢ еҸӘиҰҒдҪ е®һзҺ°еҜ№еә”зҡ„еәҸеҲ—еҢ–еҷЁ(serializer)гҖӮ
дёҖдёӘTupleд»ЈиЎЁж•°жҚ®жөҒдёӯзҡ„дёҖдёӘеҹәжң¬зҡ„еӨ„зҗҶеҚ•е…ғпјҢдҫӢеҰӮдёҖжқЎcookieж—Ҙеҝ—пјҢе®ғеҸҜд»ҘеҢ…еҗ«еӨҡдёӘFieldпјҢжҜҸдёӘFieldиЎЁзӨәдёҖдёӘеұһжҖ§гҖӮ

Tupleжң¬жқҘеә”иҜҘжҳҜдёҖдёӘKey-Valueзҡ„MapпјҢз”ұдәҺеҗ„дёӘ组件й—ҙдј йҖ’зҡ„tupleзҡ„еӯ—ж®өеҗҚз§°е·Із»ҸдәӢе…Ҳе®ҡд№үеҘҪдәҶпјҢжүҖд»ҘTupleеҸӘйңҖиҰҒжҢүеәҸеЎ«е…Ҙеҗ„дёӘValueпјҢжүҖд»Ҙе°ұжҳҜдёҖдёӘValue ListгҖӮ
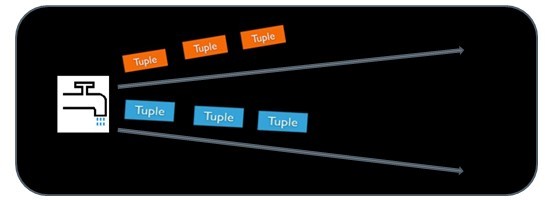
дёҖдёӘжІЎжңүиҫ№з•Ңзҡ„гҖҒжәҗжәҗдёҚж–ӯзҡ„гҖҒиҝһз»ӯзҡ„TupleеәҸеҲ—е°ұз»„жҲҗдәҶStreamгҖӮ
topologyйҮҢйқўзҡ„жҜҸдёӘиҠӮзӮ№еҝ…йЎ»е®ҡд№үе®ғиҰҒеҸ‘е°„зҡ„tupleзҡ„жҜҸдёӘеӯ—ж®өгҖӮ жҜ”еҰӮдёӢйқўиҝҷдёӘboltе®ҡд№үе®ғжүҖеҸ‘е°„зҡ„tupleеҢ…еҗ«дёӨдёӘеӯ—ж®өпјҢзұ»еһӢеҲҶеҲ«жҳҜ: doubleе’ҢtripleгҖӮ
publicclassDoubleAndTripleBoltimplementsIRichBolt {
privateOutputCollectorBase _collector;
@Override
publicvoidprepare(Map conf, TopologyContext context, OutputCollectorBase collector) {
_collector = collector;
}
@Override
publicvoidexecute(Tuple input) {
intval = input.getInteger(0);
_collector.emit(input,newValues(val*2, val*3));
_collector.ack(input);
}
@Override
publicvoidcleanup() {
}
@Override
publicvoiddeclareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(newFields("double","triple"));
}
}declareOutputFieldsж–№жі•е®ҡд№үиҰҒиҫ“еҮәзҡ„еӯ—ж®ө пјҡ ["double", "triple"]гҖӮиҝҷдёӘboltзҡ„е…¶е®ғйғЁеҲҶжҲ‘们жҺҘдёӢжқҘдјҡи§ЈйҮҠгҖӮ
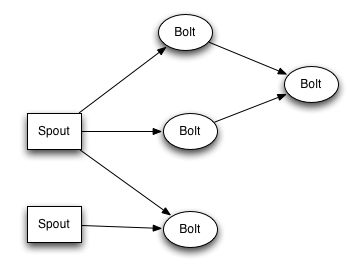
и®©жҲ‘们жқҘзңӢдёҖдёӘз®ҖеҚ•зҡ„topologyзҡ„дҫӢеӯҗпјҢ жҲ‘们зңӢдёҖдёӢstorm-starterйҮҢйқўзҡ„ExclamationTopology:
TopologyBuilder builder =newTopologyBuilder(); builder.setSpout(1,newTestWordSpout(),10); builder.setBolt(2,newExclamationBolt(),3) .shuffleGrouping(1); builder.setBolt(3,newExclamationBolt(),2) .shuffleGrouping(2);
иҝҷдёӘTopologyеҢ…еҗ«дёҖдёӘSpoutе’ҢдёӨдёӘBoltгҖӮSpoutеҸ‘е°„еҚ•иҜҚпјҢ жҜҸдёӘboltеңЁжҜҸдёӘеҚ•иҜҚеҗҺйқўеҠ дёӘвҖқ!!!вҖқгҖӮиҝҷдёүдёӘиҠӮзӮ№иў«жҺ’жҲҗдёҖжқЎзәҝ: spoutеҸ‘е°„еҚ•иҜҚз»ҷ第дёҖдёӘboltпјҢ 第дёҖдёӘbolt然еҗҺжҠҠеӨ„зҗҶеҘҪзҡ„еҚ•иҜҚеҸ‘е°„з»ҷ第дәҢдёӘboltгҖӮеҰӮжһңspoutеҸ‘е°„зҡ„еҚ•иҜҚжҳҜ["bob"]е’Ң["john"], йӮЈд№Ҳ第дәҢдёӘboltдјҡеҸ‘е°„["bolt!!!!!!"]е’Ң["john!!!!!!"]еҮәжқҘгҖӮ
жҲ‘们дҪҝз”ЁsetSpoutе’ҢsetBoltжқҘе®ҡд№үTopologyйҮҢйқўзҡ„иҠӮзӮ№гҖӮиҝҷдәӣж–№жі•жҺҘ收жҲ‘们жҢҮе®ҡзҡ„дёҖдёӘidпјҢ дёҖдёӘеҢ…еҗ«еӨ„зҗҶйҖ»иҫ‘зҡ„еҜ№иұЎ(spoutжҲ–иҖ…bolt), д»ҘеҸҠдҪ жүҖйңҖиҰҒзҡ„并иЎҢеәҰгҖӮ
иҝҷдёӘеҢ…еҗ«еӨ„зҗҶзҡ„еҜ№иұЎеҰӮжһңжҳҜspoutйӮЈд№ҲиҰҒе®һзҺ°IRichSpoutзҡ„жҺҘеҸЈпјҢ еҰӮжһңжҳҜboltпјҢйӮЈд№Ҳе°ұиҰҒе®һзҺ°IRichBoltжҺҘеҸЈ.
жңҖеҗҺдёҖдёӘжҢҮе®ҡ并иЎҢеәҰзҡ„еҸӮж•°жҳҜеҸҜйҖүзҡ„гҖӮе®ғиЎЁзӨәйӣҶзҫӨйҮҢйқўйңҖиҰҒеӨҡе°‘дёӘthreadжқҘдёҖиө·жү§иЎҢиҝҷдёӘиҠӮзӮ№гҖӮеҰӮжһңдҪ еҝҪз•Ҙе®ғйӮЈд№ҲstormдјҡеҲҶй…ҚдёҖдёӘзәҝзЁӢжқҘжү§иЎҢиҝҷдёӘиҠӮзӮ№гҖӮ
setBoltж–№жі•иҝ”еӣһдёҖдёӘInputDeclarerеҜ№иұЎпјҢ иҝҷдёӘеҜ№иұЎжҳҜз”ЁжқҘе®ҡд№үBoltзҡ„иҫ“е…ҘгҖӮ иҝҷйҮҢ第дёҖдёӘBoltеЈ°жҳҺе®ғиҰҒиҜ»еҸ–spoutжүҖеҸ‘е°„зҡ„жүҖжңүзҡ„tuple вҖ” дҪҝз”Ёshuffle groupingгҖӮиҖҢ第дәҢдёӘboltеЈ°жҳҺе®ғиҜ»еҸ–第дёҖдёӘboltжүҖеҸ‘е°„зҡ„tupleгҖӮshuffle groupingиЎЁзӨәжүҖжңүзҡ„tupleдјҡиў«йҡҸжңәзҡ„еҲҶеҸ‘з»ҷboltзҡ„жүҖжңүtaskгҖӮз»ҷtaskеҲҶеҸ‘tupleзҡ„зӯ–з•ҘжңүеҫҲеӨҡз§ҚпјҢеҗҺйқўдјҡд»Ӣз»ҚгҖӮ
еҰӮжһңдҪ жғіз¬¬дәҢдёӘboltиҜ»еҸ–spoutе’Ң第дёҖдёӘboltжүҖеҸ‘е°„зҡ„жүҖжңүзҡ„tupleпјҢ йӮЈд№ҲдҪ еә”иҜҘиҝҷж ·е®ҡд№ү第дәҢдёӘbolt:
builder.setBolt(3,newExclamationBolt(),5) .shuffleGrouping(1) .shuffleGrouping(2);
и®©жҲ‘们ж·ұе…Ҙең°зңӢдёҖдёӢиҝҷдёӘtopologyйҮҢйқўзҡ„spoutе’ҢboltжҳҜжҖҺд№Ҳе®һзҺ°зҡ„гҖӮSpoutиҙҹиҙЈеҸ‘е°„ж–°зҡ„tupleеҲ°иҝҷдёӘtopologyйҮҢйқўжқҘгҖӮTestWordSpoutд»Һ["nathan", "mike", "jackson", "golda", "bertels"]йҮҢйқўйҡҸжңәйҖүжӢ©дёҖдёӘеҚ•иҜҚеҸ‘е°„еҮәжқҘгҖӮTestWordSpoutйҮҢйқўзҡ„nextTuple()ж–№жі•жҳҜиҝҷж ·е®ҡд№үзҡ„пјҡ
publicvoidnextTuple() {
Utils.sleep(100);
finalString[] words =newString[] {"nathan","mike",
"jackson","golda","bertels"};
finalRandom rand =newRandom();
finalString word = words[rand.nextInt(words.length)];
_collector.emit(newValues(word));
}еҸҜд»ҘзңӢеҲ°пјҢе®һзҺ°еҫҲз®ҖеҚ•гҖӮ
ExclamationBoltжҠҠвҖқ!!!вҖқжӢјжҺҘеҲ°иҫ“е…ҘtupleеҗҺйқўгҖӮжҲ‘们жқҘзңӢдёӢExclamationBoltзҡ„е®Ңж•ҙе®һзҺ°гҖӮ
publicstaticclassExclamationBoltimplementsIRichBolt {
OutputCollector _collector;
publicvoidprepare(Map conf, TopologyContext context,
OutputCollector collector) {
_collector = collector;
}
publicvoidexecute(Tuple tuple) {
_collector.emit(tuple,newValues(tuple.getString(0) +"!!!"));
_collector.ack(tuple);
}
publicvoidcleanup() {
}
publicvoiddeclareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(newFields("word"));
}
}prepareж–№жі•жҸҗдҫӣз»ҷboltдёҖдёӘOutputcollectorз”ЁжқҘеҸ‘е°„tupleгҖӮBoltеҸҜд»ҘеңЁд»»дҪ•ж—¶еҖҷеҸ‘е°„tuple вҖ” еңЁprepare, executeжҲ–иҖ…cleanupж–№жі•йҮҢйқў, жҲ–иҖ…з”ҡиҮіеңЁеҸҰдёҖдёӘзәҝзЁӢйҮҢйқўејӮжӯҘеҸ‘е°„гҖӮиҝҷйҮҢprepareж–№жі•еҸӘжҳҜз®ҖеҚ•ең°жҠҠOutputCollectorдҪңдёәдёҖдёӘзұ»еӯ—ж®өдҝқеӯҳдёӢжқҘз»ҷеҗҺйқўexecuteж–№жі•дҪҝз”ЁгҖӮ
executeж–№жі•д»Һboltзҡ„дёҖдёӘиҫ“е…ҘжҺҘ收tuple(дёҖдёӘboltеҸҜиғҪжңүеӨҡдёӘиҫ“е…Ҙжәҗ). ExclamationBoltиҺ·еҸ–tupleзҡ„第дёҖдёӘеӯ—ж®өпјҢеҠ дёҠвҖқ!!!вҖқд№ӢеҗҺеҶҚеҸ‘е°„еҮәеҺ»гҖӮеҰӮжһңдёҖдёӘboltжңүеӨҡдёӘиҫ“е…ҘжәҗпјҢдҪ еҸҜд»ҘйҖҡиҝҮи°ғз”ЁTuple#getSourceComponentж–№жі•жқҘзҹҘйҒ“е®ғжҳҜжқҘиҮӘе“ӘдёӘиҫ“е…Ҙжәҗзҡ„гҖӮ
executeж–№жі•йҮҢйқўиҝҳжңүе…¶е®ғдёҖдәӣдәӢжғ…еҖјеҫ—дёҖжҸҗпјҡ иҫ“е…Ҙtupleиў«дҪңдёәemitж–№жі•зҡ„第дёҖдёӘеҸӮж•°пјҢ并且иҫ“е…ҘtupleеңЁжңҖеҗҺдёҖиЎҢиў«ackгҖӮиҝҷдәӣе‘ўйғҪжҳҜStormеҸҜйқ жҖ§APIзҡ„дёҖйғЁеҲҶпјҢеҗҺйқўдјҡи§ЈйҮҠгҖӮ
cleanupж–№жі•еңЁboltиў«е…ій—ӯзҡ„ж—¶еҖҷи°ғз”ЁпјҢ е®ғеә”иҜҘжё…зҗҶжүҖжңүиў«жү“ејҖзҡ„иө„жәҗгҖӮдҪҶжҳҜйӣҶзҫӨдёҚдҝқиҜҒиҝҷдёӘж–№жі•дёҖе®ҡдјҡиў«жү§иЎҢгҖӮжҜ”еҰӮжү§иЎҢtaskзҡ„жңәеҷЁdownжҺүдәҶпјҢйӮЈд№Ҳж №жң¬е°ұжІЎжңүеҠһжі•жқҘи°ғз”ЁйӮЈдёӘж–№жі•гҖӮcleanupи®ҫи®Ўзҡ„ж—¶еҖҷжҳҜиў«з”ЁжқҘеңЁlocal modeзҡ„ж—¶еҖҷжүҚиў«и°ғз”Ё(д№ҹе°ұжҳҜиҜҙеңЁдёҖдёӘиҝӣзЁӢйҮҢйқўжЁЎжӢҹж•ҙдёӘstormйӣҶзҫӨ), 并且дҪ жғіеңЁе…ій—ӯдёҖдәӣtopologyзҡ„ж—¶еҖҷйҒҝе…Қиө„жәҗжі„жјҸгҖӮ
жңҖеҗҺпјҢdeclareOutputFieldsе®ҡд№үдёҖдёӘеҸ«еҒҡвҖқwordвҖқзҡ„еӯ—ж®өзҡ„tupleгҖӮ
д»Ҙlocal modeиҝҗиЎҢExclamationTopology
и®©жҲ‘们зңӢзңӢжҖҺд№Ҳд»Ҙlocal modeиҝҗиЎҢExclamationToplogyгҖӮ
stormзҡ„иҝҗиЎҢжңүдёӨз§ҚжЁЎејҸ: жң¬ең°жЁЎејҸе’ҢеҲҶеёғејҸжЁЎејҸ. еңЁжң¬ең°жЁЎејҸдёӯпјҢ stormз”ЁдёҖдёӘиҝӣзЁӢйҮҢйқўзҡ„зәҝзЁӢжқҘжЁЎжӢҹжүҖжңүзҡ„spoutе’Ңbolt. жң¬ең°жЁЎејҸеҜ№ејҖеҸ‘е’ҢжөӢиҜ•жқҘиҜҙжҜ”иҫғжңүз”ЁгҖӮ дҪ иҝҗиЎҢstorm-starterйҮҢйқўзҡ„topologyзҡ„ж—¶еҖҷе®ғ们е°ұжҳҜд»Ҙжң¬ең°жЁЎејҸиҝҗиЎҢзҡ„пјҢ дҪ еҸҜд»ҘзңӢеҲ°topologyйҮҢйқўзҡ„жҜҸдёҖдёӘ组件еңЁеҸ‘е°„д»Җд№Ҳж¶ҲжҒҜгҖӮ
еңЁеҲҶеёғејҸжЁЎејҸдёӢпјҢ stormз”ұдёҖе ҶжңәеҷЁз»„жҲҗгҖӮеҪ“дҪ жҸҗдәӨtopologyз»ҷmasterзҡ„ж—¶еҖҷпјҢ дҪ еҗҢж—¶д№ҹжҠҠtopologyзҡ„д»Јз ҒжҸҗдәӨдәҶгҖӮmasterиҙҹиҙЈеҲҶеҸ‘дҪ зҡ„д»Јз Ғ并且иҙҹиҙЈз»ҷдҪ зҡ„topolgoyеҲҶй…Қе·ҘдҪңиҝӣзЁӢгҖӮеҰӮжһңдёҖдёӘе·ҘдҪңиҝӣзЁӢжҢӮжҺүдәҶпјҢ masterиҠӮзӮ№дјҡжҠҠи®ӨдёәйҮҚж–°еҲҶй…ҚеҲ°е…¶е®ғиҠӮзӮ№гҖӮе…ідәҺеҰӮдҪ•еңЁдёҖдёӘйӣҶзҫӨдёҠйқўиҝҗиЎҢtopologyпјҢ дҪ еҸҜд»ҘзңӢзңӢRunning topologies on a production clusterж–Үз« гҖӮ
дёӢйқўжҳҜд»Ҙжң¬ең°жЁЎејҸиҝҗиЎҢExclamationTopologyзҡ„д»Јз Ғ:
Config conf =newConfig();
conf.setDebug(true);
conf.setNumWorkers(2);
LocalCluster cluster =newLocalCluster();
cluster.submitTopology("test", conf, builder.createTopology());
Utils.sleep(10000);
cluster.killTopology("test");
cluster.shutdown();йҰ–е…ҲпјҢ иҝҷдёӘд»Јз Ғе®ҡд№үйҖҡиҝҮе®ҡд№үдёҖдёӘLocalClusterеҜ№иұЎжқҘе®ҡд№үдёҖдёӘиҝӣзЁӢеҶ…зҡ„йӣҶзҫӨгҖӮжҸҗдәӨtopologyз»ҷиҝҷдёӘиҷҡжӢҹзҡ„йӣҶзҫӨе’ҢжҸҗдәӨtopologyз»ҷеҲҶеёғејҸйӣҶзҫӨжҳҜдёҖж ·зҡ„гҖӮйҖҡиҝҮи°ғз”ЁsubmitTopologyж–№жі•жқҘжҸҗдәӨtopologyпјҢ е®ғжҺҘеҸ—дёүдёӘеҸӮж•°пјҡиҰҒиҝҗиЎҢзҡ„topologyзҡ„еҗҚеӯ—пјҢдёҖдёӘй…ҚзҪ®еҜ№иұЎд»ҘеҸҠиҰҒиҝҗиЎҢзҡ„topologyжң¬иә«гҖӮ
topologyзҡ„еҗҚеӯ—жҳҜз”ЁжқҘе”ҜдёҖеҢәеҲ«дёҖдёӘtopologyзҡ„пјҢиҝҷж ·дҪ 然еҗҺеҸҜд»Ҙз”ЁиҝҷдёӘеҗҚеӯ—жқҘжқҖжӯ»иҝҷдёӘtopologyзҡ„гҖӮеүҚйқўе·Із»ҸиҜҙиҝҮдәҶпјҢ дҪ еҝ…йЎ»жҳҫејҸзҡ„жқҖжҺүдёҖдёӘtopologyпјҢ еҗҰеҲҷе®ғдјҡдёҖзӣҙиҝҗиЎҢгҖӮ
ConfеҜ№иұЎеҸҜд»Ҙй…ҚзҪ®еҫҲеӨҡдёңиҘҝпјҢ дёӢйқўдёӨдёӘжҳҜжңҖеёёи§Ғзҡ„пјҡ
TOPOLOGY_WORKERS(setNumWorkers) е®ҡд№үдҪ еёҢжңӣйӣҶзҫӨеҲҶй…ҚеӨҡе°‘дёӘе·ҘдҪңиҝӣзЁӢз»ҷдҪ жқҘжү§иЎҢиҝҷдёӘtopology. topologyйҮҢйқўзҡ„жҜҸдёӘ组件дјҡиў«йңҖиҰҒзәҝзЁӢжқҘжү§иЎҢгҖӮжҜҸдёӘ组件еҲ°еә•з”ЁеӨҡе°‘дёӘзәҝзЁӢжҳҜйҖҡиҝҮsetBoltе’ҢsetSpoutжқҘжҢҮе®ҡзҡ„гҖӮиҝҷдәӣзәҝзЁӢйғҪиҝҗиЎҢеңЁе·ҘдҪңиҝӣзЁӢйҮҢйқў. жҜҸдёҖдёӘе·ҘдҪңиҝӣзЁӢеҢ…еҗ«дёҖдәӣиҠӮзӮ№зҡ„дёҖдәӣе·ҘдҪңзәҝзЁӢгҖӮжҜ”еҰӮпјҢ еҰӮжһңдҪ жҢҮе®ҡ300дёӘзәҝзЁӢпјҢ60дёӘиҝӣзЁӢпјҢ йӮЈд№ҲжҜҸдёӘе·ҘдҪңиҝӣзЁӢйҮҢйқўиҰҒжү§иЎҢ6дёӘзәҝзЁӢпјҢ иҖҢиҝҷ6дёӘзәҝзЁӢеҸҜиғҪеұһдәҺдёҚеҗҢзҡ„组件(Spout, Bolt)гҖӮдҪ еҸҜд»ҘйҖҡиҝҮи°ғж•ҙжҜҸдёӘ组件зҡ„并иЎҢеәҰд»ҘеҸҠиҝҷдәӣзәҝзЁӢжүҖеңЁзҡ„иҝӣзЁӢж•°йҮҸжқҘи°ғж•ҙtopologyзҡ„жҖ§иғҪгҖӮ
TOPOLOGY_DEBUG(setDebug), еҪ“е®ғиў«и®ҫзҪ®жҲҗtrueзҡ„иҜқпјҢ stormдјҡи®°еҪ•дёӢжҜҸдёӘ组件жүҖеҸ‘е°„зҡ„жҜҸжқЎж¶ҲжҒҜгҖӮиҝҷеңЁжң¬ең°зҺҜеўғи°ғиҜ•topologyеҫҲжңүз”ЁпјҢ дҪҶжҳҜеңЁзәҝдёҠиҝҷд№ҲеҒҡзҡ„иҜқдјҡеҪұе“ҚжҖ§иғҪзҡ„гҖӮ
ж„ҹе…ҙи¶Јзҡ„иҜқеҸҜд»ҘеҺ»зңӢзңӢConfеҜ№иұЎзҡ„JavadocеҺ»зңӢзңӢtopologyзҡ„жүҖжңүй…ҚзҪ®гҖӮ
еҸҜд»ҘзңӢзңӢеҲӣе»әдёҖдёӘж–°stormйЎ№зӣ®еҺ»зңӢзңӢжҖҺд№Ҳй…ҚзҪ®ејҖеҸ‘зҺҜеўғд»ҘдҪҝдҪ иғҪеӨҹд»Ҙжң¬ең°жЁЎејҸиҝҗиЎҢtopology.
иҝҗиЎҢдёӯзҡ„Topologyдё»иҰҒз”ұд»ҘдёӢдёүдёӘ组件组жҲҗзҡ„пјҡ
Worker processesпјҲиҝӣзЁӢпјү
Executors (threads)пјҲзәҝзЁӢпјү
Tasks
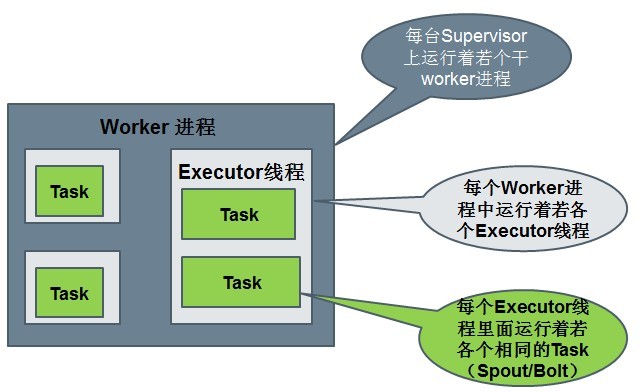
SpoutжҲ–иҖ…Boltзҡ„TaskдёӘж•°дёҖж—ҰжҢҮе®ҡд№ӢеҗҺе°ұдёҚиғҪж”№еҸҳдәҶпјҢиҖҢExecutorзҡ„ж•°йҮҸеҸҜд»Ҙж №жҚ®жғ…еҶөжқҘиҝӣиЎҢеҠЁжҖҒзҡ„и°ғж•ҙгҖӮй»ҳи®Өжғ…еҶөдёӢ# executor = #tasksеҚідёҖдёӘExecutorдёӯиҝҗиЎҢзқҖдёҖдёӘTask
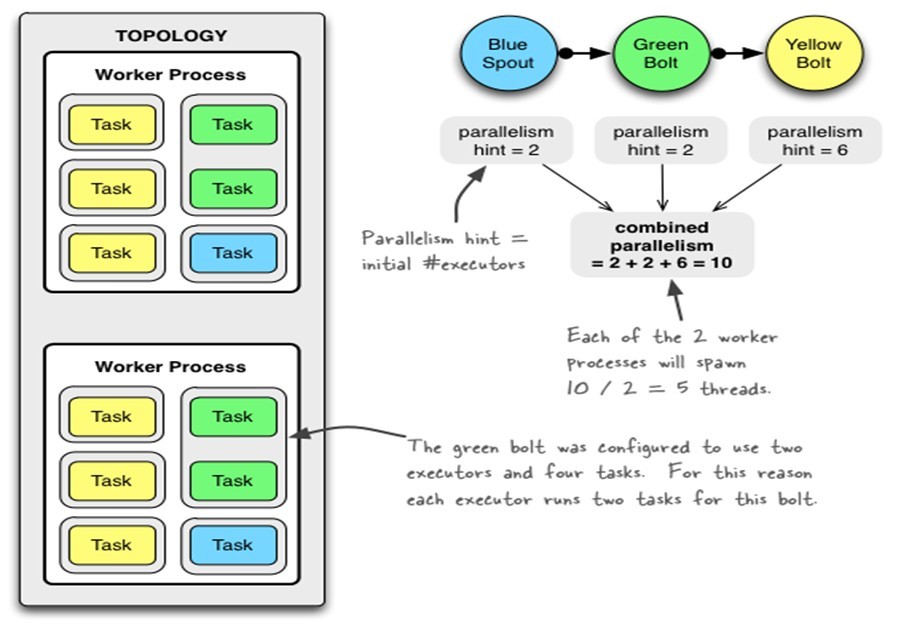
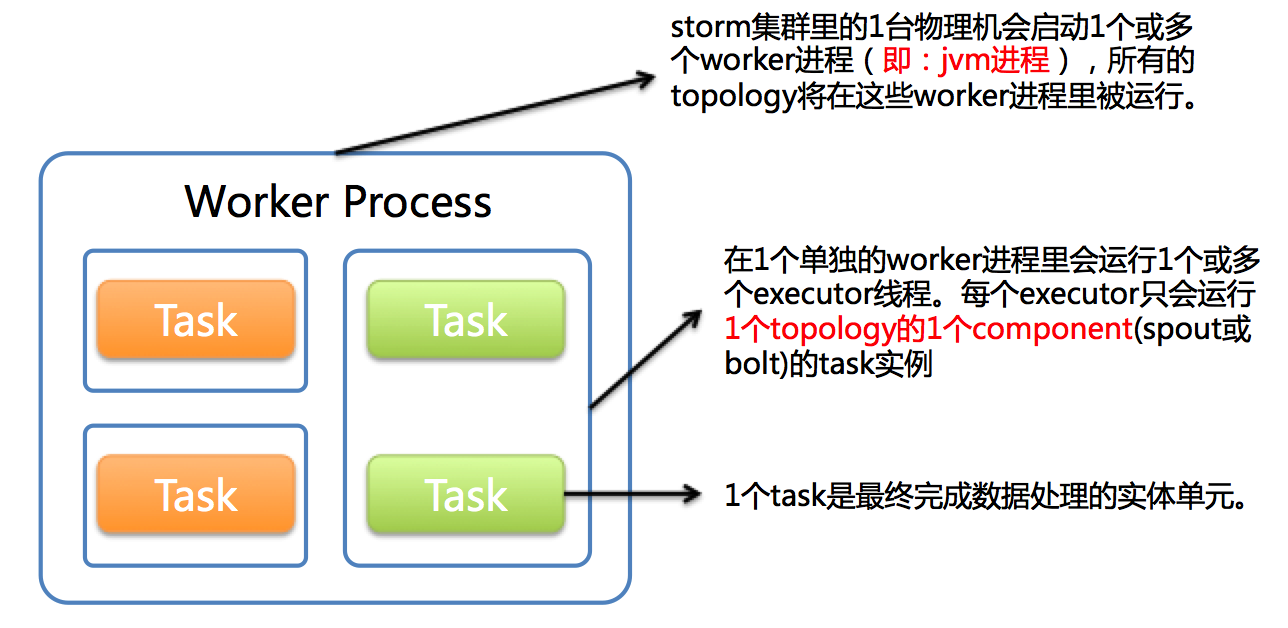
1дёӘworkerиҝӣзЁӢжү§иЎҢзҡ„жҳҜ1дёӘtopologyзҡ„еӯҗйӣҶпјҲжіЁпјҡдёҚдјҡеҮәзҺ°1дёӘworkerдёәеӨҡдёӘtopologyжңҚеҠЎпјүгҖӮ1дёӘworkerиҝӣзЁӢдјҡеҗҜеҠЁ1дёӘжҲ–еӨҡдёӘexecutorзәҝзЁӢжқҘжү§иЎҢ1дёӘtopologyзҡ„component(spoutжҲ–bolt)гҖӮеӣ жӯӨпјҢ1дёӘиҝҗиЎҢдёӯзҡ„topologyе°ұжҳҜз”ұйӣҶзҫӨдёӯеӨҡеҸ°зү©зҗҶжңәдёҠзҡ„еӨҡдёӘworkerиҝӣзЁӢз»„жҲҗзҡ„гҖӮ
executorжҳҜ1дёӘиў«workerиҝӣзЁӢеҗҜеҠЁзҡ„еҚ•зӢ¬зәҝзЁӢгҖӮжҜҸдёӘexecutorеҸӘдјҡиҝҗиЎҢ1дёӘtopologyзҡ„1дёӘcomponent(spoutжҲ–bolt)зҡ„task(set)пјҲжіЁпјҡtaskеҸҜд»ҘжҳҜ1дёӘжҲ–еӨҡдёӘпјҢstormй»ҳи®ӨжҳҜ1дёӘcomponentеҸӘз”ҹжҲҗ1дёӘtaskпјҢexecutorзәҝзЁӢйҮҢдјҡеңЁжҜҸж¬ЎеҫӘзҺҜйҮҢйЎәеәҸи°ғз”ЁжүҖжңүtaskе®һдҫӢпјүгҖӮ
taskжҳҜжңҖз»ҲиҝҗиЎҢspoutжҲ–boltдёӯд»Јз Ғзҡ„еҚ•е…ғпјҲжіЁпјҡ1дёӘtaskеҚідёәspoutжҲ–boltзҡ„1дёӘе®һдҫӢпјҢexecutorзәҝзЁӢеңЁжү§иЎҢжңҹй—ҙдјҡи°ғз”ЁиҜҘtaskзҡ„nextTupleжҲ–executeж–№жі•пјүгҖӮtopologyеҗҜеҠЁеҗҺпјҢ1дёӘcomponent(spoutжҲ–bolt)зҡ„taskж•°зӣ®жҳҜеӣәе®ҡдёҚеҸҳзҡ„пјҢдҪҶиҜҘcomponentдҪҝз”Ёзҡ„executorзәҝзЁӢж•°еҸҜд»ҘеҠЁжҖҒи°ғж•ҙпјҲдҫӢеҰӮпјҡ1дёӘexecutorзәҝзЁӢеҸҜд»Ҙжү§иЎҢиҜҘcomponentзҡ„1дёӘжҲ–еӨҡдёӘtaskе®һдҫӢпјүгҖӮиҝҷж„Ҹе‘ізқҖпјҢеҜ№дәҺ1дёӘcomponentеӯҳеңЁиҝҷж ·зҡ„жқЎд»¶пјҡ#threads<=#tasksпјҲеҚіпјҡзәҝзЁӢж•°е°ҸдәҺзӯүдәҺtaskж•°зӣ®пјүгҖӮй»ҳи®Өжғ…еҶөдёӢtaskзҡ„ж•°зӣ®зӯүдәҺexecutorзәҝзЁӢж•°зӣ®пјҢеҚі1дёӘexecutorзәҝзЁӢеҸӘиҝҗиЎҢ1дёӘtaskгҖӮ
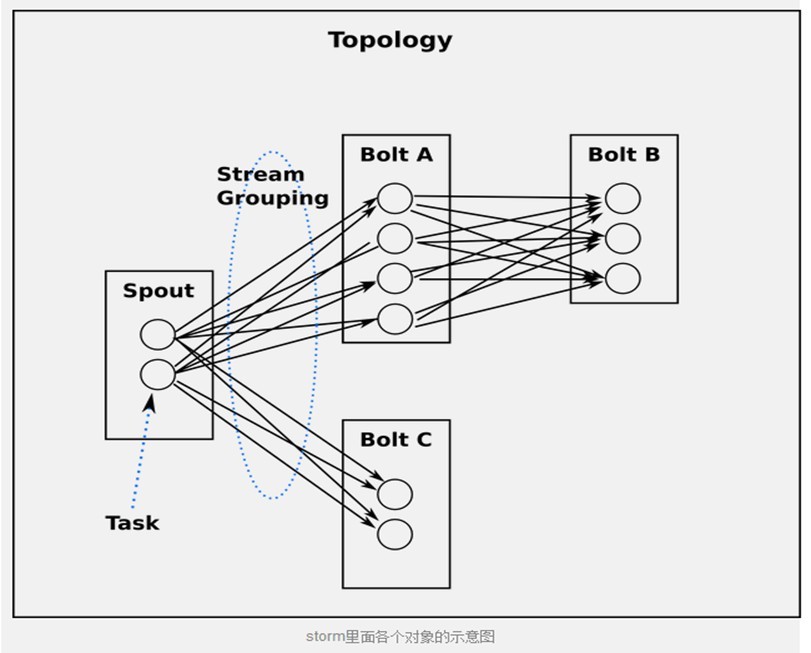
д»Һtaskи§’еәҰжқҘзңӢtopology
еҪ“Bolt Aзҡ„дёҖдёӘtaskиҰҒеҸ‘йҖҒдёҖдёӘtupleз»ҷBolt BпјҢ е®ғеә”иҜҘеҸ‘йҖҒз»ҷBolt Bзҡ„е“ӘдёӘtaskе‘ўпјҹ
stream groupingдё“й—Ёеӣһзӯ”иҝҷз§Қй—®йўҳзҡ„гҖӮеңЁжҲ‘们ж·ұе…Ҙз ”з©¶дёҚеҗҢзҡ„stream groupingд№ӢеүҚпјҢ и®©жҲ‘们зңӢдёҖдёӢstorm-starterйҮҢйқўзҡ„еҸҰеӨ–дёҖдёӘtopologyгҖӮWordCountTopologyиҜ»еҸ–дёҖдәӣеҸҘеӯҗпјҢ иҫ“еҮәеҸҘеӯҗйҮҢйқўжҜҸдёӘеҚ•иҜҚеҮәзҺ°зҡ„ж¬Ўж•°.
TopologyBuilder builder =newTopologyBuilder();
builder.setSpout(1,newRandomSentenceSpout(),5);
builder.setBolt(2,newSplitSentence(),8)
.shuffleGrouping(1);
builder.setBolt(3,newWordCount(),12)
.fieldsGrouping(2,newFields("word"));SplitSentenceеҜ№дәҺеҸҘеӯҗйҮҢйқўзҡ„жҜҸдёӘеҚ•иҜҚеҸ‘е°„дёҖдёӘж–°зҡ„tuple, WordCountеңЁеҶ…еӯҳйҮҢйқўз»ҙжҠӨдёҖдёӘеҚ•иҜҚ->ж¬Ўж•°зҡ„mappingпјҢ WordCountжҜҸ收еҲ°дёҖдёӘеҚ•иҜҚпјҢ е®ғе°ұжӣҙж–°еҶ…еӯҳйҮҢйқўзҡ„з»ҹи®ЎзҠ¶жҖҒгҖӮ
жңүеҘҪеҮ з§ҚдёҚеҗҢзҡ„stream grouping:
жңҖз®ҖеҚ•зҡ„groupingжҳҜshuffle grouping, е®ғйҡҸжңәеҸ‘з»ҷд»»дҪ•дёҖдёӘtaskгҖӮдёҠйқўдҫӢеӯҗйҮҢйқўRandomSentenceSpoutе’ҢSplitSentenceд№Ӣй—ҙз”Ёзҡ„е°ұжҳҜshuffle grouping, shuffle groupingеҜ№еҗ„дёӘtaskзҡ„tupleеҲҶй…Қзҡ„жҜ”иҫғеқҮеҢҖгҖӮ
дёҖз§Қжӣҙжңүи¶Јзҡ„groupingжҳҜfields grouping, SplitSentenceе’ҢWordCountд№Ӣй—ҙдҪҝз”Ёзҡ„е°ұжҳҜfields grouping, иҝҷз§ҚgroupingжңәеҲ¶дҝқиҜҒзӣёеҗҢfieldеҖјзҡ„tupleдјҡеҺ»еҗҢдёҖдёӘtaskпјҢ иҝҷеҜ№дәҺWordCountжқҘиҜҙйқһеёёе…ій”®пјҢеҰӮжһңеҗҢдёҖдёӘеҚ•иҜҚдёҚеҺ»еҗҢдёҖдёӘtaskпјҢ йӮЈд№Ҳз»ҹи®ЎеҮәжқҘзҡ„еҚ•иҜҚж¬Ўж•°е°ұдёҚеҜ№дәҶгҖӮ
fields groupingжҳҜstreamеҗҲ并пјҢstreamиҒҡеҗҲд»ҘеҸҠеҫҲеӨҡе…¶е®ғеңәжҷҜзҡ„еҹәзЎҖгҖӮеңЁиғҢеҗҺе‘ўпјҢ fields groupingдҪҝз”Ёзҡ„дёҖиҮҙжҖ§е“ҲеёҢжқҘеҲҶй…Қtupleзҡ„гҖӮ
иҝҳжңүдёҖдәӣе…¶е®ғзұ»еһӢзҡ„stream grouping. дҪ еҸҜд»ҘеңЁConceptsдёҖз« йҮҢжӣҙиҜҰз»Ҷзҡ„дәҶи§ЈгҖӮ
дёӢйқўжҳҜдёҖдәӣеёёз”Ёзҡ„ вҖңи·Ҝз”ұйҖүжӢ©вҖқ жңәеҲ¶пјҡ
Stormзҡ„GroupingеҚіж¶ҲжҒҜзҡ„PartitionжңәеҲ¶гҖӮеҪ“дёҖдёӘTupleиў«еҸ‘йҖҒж—¶пјҢеҰӮдҪ•зЎ®е®ҡе°Ҷе®ғеҸ‘йҖҒдёӘжҹҗдёӘпјҲдәӣпјүTaskжқҘеӨ„зҗҶпјҹпјҹ
l ShuffleGroupingпјҡйҡҸжңәйҖүжӢ©дёҖдёӘTaskжқҘеҸ‘йҖҒгҖӮ
l FiledGroupingпјҡж №жҚ®TupleдёӯFieldsжқҘеҒҡдёҖиҮҙжҖ§hashпјҢзӣёеҗҢhashеҖјзҡ„Tupleиў«еҸ‘йҖҒеҲ°зӣёеҗҢзҡ„TaskгҖӮ
l AllGroupingпјҡе№ҝж’ӯеҸ‘йҖҒпјҢе°ҶжҜҸдёҖдёӘTupleеҸ‘йҖҒеҲ°жүҖжңүзҡ„TaskгҖӮ
l GlobalGroupingпјҡжүҖжңүзҡ„Tupleдјҡиў«еҸ‘йҖҒеҲ°жҹҗдёӘBoltдёӯзҡ„idжңҖе°Ҹзҡ„йӮЈдёӘTaskгҖӮ
l NoneGroupingпјҡдёҚе…іеҝғTupleеҸ‘йҖҒз»ҷе“ӘдёӘTaskжқҘеӨ„зҗҶпјҢзӯүд»·дәҺShuffleGroupingгҖӮ
l DirectGroupingпјҡзӣҙжҺҘе°ҶTupleеҸ‘йҖҒеҲ°жҢҮе®ҡзҡ„TaskжқҘеӨ„зҗҶгҖӮ
BoltеҸҜд»ҘдҪҝз”Ёд»»дҪ•иҜӯиЁҖжқҘе®ҡд№үгҖӮз”Ёе…¶е®ғиҜӯиЁҖе®ҡд№үзҡ„boltдјҡиў«еҪ“дҪңеӯҗиҝӣзЁӢ(subprocess)жқҘжү§иЎҢпјҢ stormдҪҝз”ЁJSONж¶ҲжҒҜйҖҡиҝҮstdin/stdoutжқҘе’ҢиҝҷдәӣsubprocessйҖҡдҝЎгҖӮиҝҷдёӘйҖҡдҝЎеҚҸи®®жҳҜдёҖдёӘеҸӘжңү100иЎҢзҡ„еә“пјҢ stormеӣўйҳҹз»ҷиҝҷдәӣеә“ејҖеҸ‘дәҶеҜ№еә”зҡ„Ruby, Pythonе’ҢFancyзүҲжң¬гҖӮ
дёӢйқўжҳҜWordCountTopologyйҮҢйқўзҡ„SplitSentenceзҡ„е®ҡд№ү:
publicstaticclassSplitSentenceextendsShellBoltimplementsIRichBolt {
publicSplitSentence() {
super("python","splitsentence.py");
}
publicvoiddeclareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(newFields("word"));
}
}SplitSentence继жүҝиҮӘShellBolt并且声жҳҺиҝҷдёӘBoltз”ЁpythonжқҘиҝҗиЎҢпјҢ并且еҸӮж•°жҳҜ: splitsentence.pyгҖӮдёӢйқўжҳҜsplitsentence.pyзҡ„е®ҡд№ү:
importstorm
classSplitSentenceBolt(storm.BasicBolt):
defprocess(self, tup):
words=tup.values[0].split(" ")
forwordinwords:
storm.emit([word])
SplitSentenceBolt().run()жӣҙеӨҡжңүе…із”Ёе…¶е®ғиҜӯиЁҖе®ҡд№үSpoutе’ҢBoltзҡ„дҝЎжҒҜпјҢ д»ҘеҸҠз”Ёе…¶е®ғиҜӯиЁҖжқҘеҲӣе»әtopologyзҡ„ дҝЎжҒҜеҸҜд»ҘеҸӮи§Ғ: Using non-JVM languages with Storm.
еңЁиҝҷдёӘж•ҷзЁӢзҡ„еүҚйқўпјҢжҲ‘们跳иҝҮдәҶжңүе…іtupleзҡ„дёҖдәӣзү№еҫҒгҖӮиҝҷдәӣзү№еҫҒе°ұжҳҜstormзҡ„еҸҜйқ жҖ§APIпјҡ stormеҰӮдҪ•дҝқиҜҒspoutеҸ‘еҮәзҡ„жҜҸдёҖдёӘtupleйғҪиў«е®Ңж•ҙеӨ„зҗҶгҖӮзңӢзңӢгҖҠstormеҰӮдҪ•дҝқиҜҒж¶ҲжҒҜдёҚдёўеӨұгҖӢд»Ҙжӣҙж·ұе…ҘдәҶи§Јstormзҡ„еҸҜйқ жҖ§API.
Stormе…Ғи®ёз”ЁжҲ·еңЁSpoutдёӯеҸ‘е°„дёҖдёӘж–°зҡ„жәҗTupleж—¶дёәе…¶жҢҮе®ҡдёҖдёӘMessageIdпјҢиҝҷдёӘMessageIdеҸҜд»ҘжҳҜд»»ж„Ҹзҡ„ObjectеҜ№иұЎгҖӮеӨҡдёӘжәҗTupleеҸҜд»Ҙе…ұз”ЁеҗҢдёҖдёӘMessageIdпјҢиЎЁзӨәиҝҷеӨҡдёӘжәҗTupleеҜ№з”ЁжҲ·жқҘиҜҙжҳҜеҗҢдёҖдёӘж¶ҲжҒҜеҚ•е…ғгҖӮStormзҡ„еҸҜйқ жҖ§жҳҜжҢҮStormдјҡе‘ҠзҹҘз”ЁжҲ·жҜҸдёҖдёӘж¶ҲжҒҜеҚ•е…ғжҳҜеҗҰеңЁдёҖдёӘжҢҮе®ҡзҡ„ж—¶й—ҙеҶ…иў«е®Ңе…ЁеӨ„зҗҶгҖӮе®Ңе…ЁеӨ„зҗҶзҡ„ж„ҸжҖқжҳҜиҜҘMessageIdз»‘е®ҡзҡ„жәҗTupleд»ҘеҸҠз”ұиҜҘжәҗTupleиЎҚз”ҹзҡ„жүҖжңүTupleйғҪз»ҸиҝҮдәҶTopologyдёӯжҜҸдёҖдёӘеә”иҜҘеҲ°иҫҫзҡ„Boltзҡ„еӨ„зҗҶгҖӮ
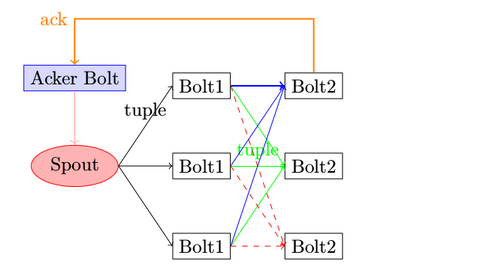
ackжңәеҲ¶еҚіпјҢ spoutеҸ‘йҖҒзҡ„жҜҸдёҖжқЎж¶ҲжҒҜпјҢ
еңЁи§„е®ҡзҡ„ж—¶й—ҙеҶ…пјҢspout收еҲ°Ackerзҡ„ackе“Қеә”пјҢеҚіи®ӨдёәиҜҘtuple иў«еҗҺз»ӯboltжҲҗеҠҹеӨ„зҗҶ
еңЁи§„е®ҡзҡ„ж—¶й—ҙеҶ…пјҢжІЎжңү收еҲ°Ackerзҡ„ackе“Қеә”tupleпјҢе°ұи§ҰеҸ‘failеҠЁдҪңпјҢеҚіи®ӨдёәиҜҘtupleеӨ„зҗҶеӨұиҙҘпјҢ
жҲ–иҖ…收еҲ°AckerеҸ‘йҖҒзҡ„failе“Қеә”tupleпјҢд№ҹи®ӨдёәеӨұиҙҘпјҢи§ҰеҸ‘failеҠЁдҪң
еҸҰеӨ–AckжңәеҲ¶иҝҳеёёз”ЁдәҺйҷҗжөҒдҪңз”Ёпјҡ дёәдәҶйҒҝе…ҚspoutеҸ‘йҖҒж•°жҚ®еӨӘеҝ«пјҢиҖҢboltеӨ„зҗҶеӨӘж…ўпјҢеёёеёёи®ҫзҪ®pendingж•°пјҢеҪ“spoutжңүзӯүдәҺжҲ–и¶…иҝҮpendingж•°зҡ„tupleжІЎжңү收еҲ°ackжҲ–failе“Қеә”ж—¶пјҢи·іиҝҮжү§иЎҢnextTupleпјҢ д»ҺиҖҢйҷҗеҲ¶spoutеҸ‘йҖҒж•°жҚ®гҖӮ
йҖҡиҝҮconf.put(Config.TOPOLOGY_MAX_SPOUT_PENDING, pending);и®ҫзҪ®spout pendж•°гҖӮ
еңЁSpoutдёӯз”ұmessage 1з»‘е®ҡзҡ„tuple1е’Ңtuple2еҲҶеҲ«з»ҸиҝҮbolt1е’Ңbolt2зҡ„еӨ„зҗҶпјҢ然еҗҺз”ҹжҲҗдәҶдёӨдёӘж–°зҡ„TupleпјҢ并жңҖз»ҲжөҒеҗ‘дәҶbolt3гҖӮеҪ“bolt3еӨ„зҗҶе®Ңд№ӢеҗҺпјҢз§°message 1иў«е®Ңе…ЁеӨ„зҗҶдәҶгҖӮ
Stormдёӯзҡ„жҜҸдёҖдёӘTopologyдёӯйғҪеҢ…еҗ«жңүдёҖдёӘAcker组件гҖӮAcker组件зҡ„д»»еҠЎе°ұжҳҜи·ҹиёӘд»ҺSpoutдёӯжөҒеҮәзҡ„жҜҸдёҖдёӘmessageIdжүҖз»‘е®ҡзҡ„Tupleж ‘дёӯзҡ„жүҖжңүTupleзҡ„еӨ„зҗҶжғ…еҶөгҖӮеҰӮжһңеңЁз”ЁжҲ·и®ҫзҪ®зҡ„жңҖеӨ§и¶…ж—¶ж—¶й—ҙеҶ…иҝҷдәӣTupleжІЎжңүиў«е®Ңе…ЁеӨ„зҗҶпјҢйӮЈд№ҲAckerдјҡе‘ҠиҜүSpoutиҜҘж¶ҲжҒҜеӨ„зҗҶеӨұиҙҘпјҢзӣёеҸҚеҲҷдјҡе‘ҠзҹҘSpoutиҜҘж¶ҲжҒҜеӨ„зҗҶжҲҗеҠҹгҖӮ
йӮЈд№ҲAckerжҳҜеҰӮдҪ•и®°еҪ•Tupleзҡ„еӨ„зҗҶз»“жһңе‘ўпјҹпјҹ
A xor A = 0.
A xor BвҖҰxor B xor A = 0пјҢе…¶дёӯжҜҸдёҖдёӘж“ҚдҪңж•°еҮәзҺ°дё”д»…еҮәзҺ°дёӨж¬ЎгҖӮ
еңЁSpoutдёӯпјҢStormзі»з»ҹдјҡдёәз”ЁжҲ·жҢҮе®ҡзҡ„MessageIdз”ҹжҲҗдёҖдёӘеҜ№еә”зҡ„64дҪҚзҡ„ж•ҙж•°пјҢдҪңдёәж•ҙдёӘTuple Treeзҡ„RootIdгҖӮRootIdдјҡиў«дј йҖ’з»ҷAckerд»ҘеҸҠеҗҺз»ӯзҡ„BoltжқҘдҪңдёәиҜҘж¶ҲжҒҜеҚ•е…ғзҡ„е”ҜдёҖж ҮиҜҶгҖӮеҗҢж—¶пјҢж— и®әSpoutиҝҳжҳҜBoltжҜҸж¬Ўж–°з”ҹжҲҗдёҖдёӘTupleж—¶пјҢйғҪдјҡиөӢдәҲиҜҘTupleдёҖдёӘе”ҜдёҖзҡ„64дҪҚж•ҙж•°зҡ„IdгҖӮ
еҪ“SpoutеҸ‘е°„е®ҢжҹҗдёӘMessageIdеҜ№еә”зҡ„жәҗTupleд№ӢеҗҺпјҢе®ғдјҡе‘ҠиҜүAckerиҮӘе·ұеҸ‘е°„зҡ„RootIdд»ҘеҸҠз”ҹжҲҗзҡ„йӮЈдәӣжәҗTupleзҡ„IdгҖӮиҖҢеҪ“BoltеӨ„зҗҶе®ҢдёҖдёӘиҫ“е…ҘTuple并дә§з”ҹеҮәж–°зҡ„Tupleж—¶пјҢд№ҹдјҡе‘ҠзҹҘAckerиҮӘе·ұеӨ„зҗҶзҡ„иҫ“е…ҘTupleзҡ„Idд»ҘеҸҠж–°з”ҹжҲҗзҡ„йӮЈдәӣTupleзҡ„IdгҖӮAckerеҸӘйңҖиҰҒеҜ№иҝҷдәӣIdиҝӣиЎҢејӮжҲ–иҝҗз®—пјҢе°ұиғҪеҲӨж–ӯеҮәиҜҘRootIdеҜ№еә”зҡ„ж¶ҲжҒҜеҚ•е…ғжҳҜеҗҰжҲҗеҠҹеӨ„зҗҶе®ҢжҲҗдәҶгҖӮ
spout еңЁеҸ‘йҖҒж•°жҚ®зҡ„ж—¶еҖҷеёҰдёҠmsgid
и®ҫзҪ®ackerж•°иҮіе°‘еӨ§дәҺ0пјӣConfig.setNumAckers(conf, ackerParal);
еңЁboltдёӯе®ҢжҲҗеӨ„зҗҶtupleж—¶пјҢжү§иЎҢOutputCollector.ack(tuple), еҪ“еӨұиҙҘеӨ„зҗҶж—¶пјҢжү§иЎҢOutputCollector.fail(tuple); ** жҺЁиҚҗдҪҝз”ЁIBasicBoltпјҢ еӣ дёәIBasicBolt иҮӘеҠЁе°ҒиЈ…дәҶOutputCollector.ack(tuple), еӨ„зҗҶеӨұиҙҘж—¶пјҢиҜ·жҠӣеҮәFailedExceptionпјҢеҲҷиҮӘеҠЁжү§иЎҢOutputCollector.fail(tuple)
жңү2з§ҚйҖ”еҫ„
spoutеҸ‘йҖҒж•°жҚ®жҳҜдёҚеёҰдёҠmsgid
и®ҫзҪ®ackerж•°зӯүдәҺ0
зҺҜеўғпјҡcentos 6.4
е®үиЈ…жӯҘйӘӨиҜ·еҸӮиҖғпјҡhttp://blog.sina.com.cn/s/blog_546abd9f0101cce8.html
иҰҒжіЁж„ҸдёҠйқўзҡ„жң¬ең°жЁЎејҸиҝҗиЎҢWordCountе…¶е®һ并没жңүдҪҝз”ЁеҲ°дёҠиҝ°е®үиЈ…зҡ„е·Ҙе…·пјҢеҸӘжҳҜдёҖдёӘstormзҡ„иҷҡжӢҹзҺҜеўғдёӢжөӢиҜ•demoгҖӮйӮЈжҲ‘们жҖҺж ·е°ҶзЁӢеәҸиҝҗиЎҢеңЁеҲҡеҲҡжҗӯе»әзҡ„еҚ•жңәзүҲзҡ„зҺҜеўғйҮҢйқўе‘ўпјҢ
еҫҲз®ҖеҚ•пјҢе®ҳж–№зҡ„дҫӢеӯҗпјҡ
жіЁж„ҸзңӢе®ҳж–№е®һдҫӢдёӯWordCountTopologyзұ»еҰӮжһңдёҚеёҰеҸӮж•°е…¶е®һжҳҜжү§иЎҢзҡ„жң¬ең°жЁЎејҸпјҢд№ҹе°ұжҳҜеҲҡиҜҙзҡ„иҷҡжӢҹзҡ„зҺҜеўғпјҢеёҰдёҠеҸӮж•°е°ұжҳҜе°ҶjarеҸ‘йҖҒеҲ°дәҶstormжү§иЎҢдәҶгҖӮ
йҰ–е…Ҳеј„еҘҪзҺҜеўғпјҡ
еҗҜеҠЁzookeeperпјҡ
/usr/local/zookeeper/bin/zkServer.sh еҚ•жңәзүҲзӣҙжҺҘеҗҜеҠЁпјҢдёҚз”Ёдҝ®ж”№д»Җд№Ҳй…ҚзҪ®пјҢеҰӮйӣҶзҫӨе°ұйңҖиҰҒдҝ®ж”№zoo.cfgеҸҰдёҖзҜҮж–Үз« дјҡи®ІеҲ°гҖӮ
й…ҚзҪ®stormпјҡ
ж–Ү件еңЁ/usr/local/storm/conf/storm.yaml
еҶ…е®№пјҡ
storm.zookeeper.servers:
- 127.0.0.1
storm.zookeeper.port: 2181
nimbus.host: "127.0.0.1"
storm.local.dir: "/tmp/storm"
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
иҝҷдёӘи„ҡжң¬ж–Ү件еҶҷзҡ„дёҚе’Ӣең°пјҢжүҖд»ҘеңЁй…ҚзҪ®ж—¶дёҖе®ҡжіЁж„ҸеңЁжҜҸдёҖйЎ№зҡ„ејҖе§Ӣж—¶иҰҒеҠ з©әж јпјҢеҶ’еҸ·еҗҺд№ҹеҝ…йЎ»иҰҒеҠ з©әж јпјҢеҗҰеҲҷstormе°ұдёҚи®ӨиҜҶиҝҷдёӘй…ҚзҪ®ж–Ү件дәҶгҖӮ
иҜҙжҳҺдёҖдёӢпјҡstorm.local.dirиЎЁзӨәstormйңҖиҰҒз”ЁеҲ°зҡ„жң¬ең°зӣ®еҪ•гҖӮnimbus.hostиЎЁзӨәйӮЈдёҖеҸ°жңәеҷЁжҳҜmasterжңәеҷЁпјҢеҚіnimbusгҖӮstorm.zookeeper.serversиЎЁзӨәе“ӘеҮ еҸ°жңәеҷЁжҳҜzookeeperжңҚеҠЎеҷЁгҖӮstorm.zookeeper.portиЎЁзӨәzookeeperзҡ„з«ҜеҸЈеҸ·пјҢиҝҷйҮҢдёҖе®ҡиҰҒдёҺzookeeperй…ҚзҪ®зҡ„з«ҜеҸЈеҸ·дёҖиҮҙпјҢеҗҰеҲҷдјҡеҮәзҺ°йҖҡдҝЎй”ҷиҜҜпјҢеҲҮи®°еҲҮи®°гҖӮеҪ“然дҪ д№ҹеҸҜд»Ҙй…Қsuperevisor.slot.portпјҢsupervisor.slots.portsиЎЁзӨәsupervisorиҠӮзӮ№зҡ„ж§Ҫж•°пјҢе°ұжҳҜжңҖеӨҡиғҪи·‘еҮ дёӘworkerиҝӣзЁӢпјҲжҜҸдёӘsproutжҲ–boltй»ҳи®ӨеҸӘеҗҜеҠЁдёҖдёӘworkerпјҢдҪҶжҳҜеҸҜд»ҘйҖҡиҝҮconfдҝ®ж”№жҲҗеӨҡдёӘпјүгҖӮ
жү§иЎҢпјҡ
# bin/storm nimbusпјҲеҗҜеҠЁдё»иҠӮзӮ№пјү
# bin/storm supervisorпјҲеҗҜеҠЁд»ҺиҠӮзӮ№пјү
жү§иЎҢе‘Ҫд»Өпјҡ# storm jar StormStarter.jar storm.starter.WordCountTopology test
жӯӨе‘Ҫд»Өзҡ„дҪңз”Ёе°ұжҳҜз”Ёstormе°ҶjarеҸ‘йҖҒз»ҷstormеҺ»жү§иЎҢпјҢеҗҺйқўзҡ„testжҳҜе®ҡд№үзҡ„toplogyеҗҚз§°гҖӮ
жҗһе®ҡпјҢд»»еҠЎе°ұеҸ‘йҖҒеҲ°stormдёҠиҝҗиЎҢиө·жқҘдәҶпјҢиҝҳеҸҜд»ҘйҖҡиҝҮе‘Ҫд»Өпјҡ
# bin/storm ui
然еҗҺжү§иЎҢ jps дјҡзңӢеҲ° 3 дёӘиҝӣзЁӢпјҡzookeeper гҖҒnimbusгҖҒ supervisor
еҗҜеҠЁuiпјҢеҸҜд»ҘйҖҡиҝҮжөҸи§ҲеҷЁпјҢ ip:8080/ жҹҘзңӢиҝҗиЎҢiжғ…еҶөгҖӮ
й…ҚзҪ®еҗҺпјҢжү§иЎҢ storm jar sm.jar main.java.TopologyMain words.txt
д№ҹи®ёдјҡжҠҘпјҡjava.lang.NoClassDefFoundError: clojure.core.protocols$seq_reduce
иҝҷжҳҜз”ұдәҺжҲ‘дҪҝз”ЁдәҶ oracle JDK 1.7 зҡ„зјҳж•…пјҢжҚўжҲҗ open JDK 1.6 е°ұжӯЈеёёдәҶпјҢ
su -c "yum install java-1.6.0-openjdk-devel"
е…·дҪ“еҸӮиҖғпјҡhttps://github.com/technomancy/leiningen/issues/676
жөӢиҜ•д»Јз Ғпјҡ
https://github.com/storm-book/examples-ch02-getting_started
иҝҗиЎҢз»“жһңпјҡ
storm jar sm.jar main.java.TopologyMain words.txt ... 6020 [main] INFO backtype.storm.messaging.loader - Shutdown receiving-thread: [Getting-Started-Toplogie-1-1374946750, 4] 6020 [main] INFO backtype.storm.daemon.worker - Shut down receive thread 6020 [main] INFO backtype.storm.daemon.worker - Terminating zmq context 6020 [main] INFO backtype.storm.daemon.worker - Shutting down executors OK:is 6021 [main] INFO backtype.storm.daemon.executor - Shutting down executor word-counter:[2 2] OK:an OK:storm OK:simple 6023 [Thread-16] INFO backtype.storm.util - Async loop interrupted! OK:application OK:but OK:very OK:powerfull OK:really OK: OK:StOrm OK:is OK:great 6038 [Thread-15] INFO backtype.storm.util - Async loop interrupted! -- Word Counter [word-counter-2] -- really: 1 but: 1 application: 1 is: 2 great: 2 are: 1 test: 1 simple: 1 an: 1 powerfull: 1 storm: 3 very: 1 6043 [main] INFO backtype.storm.daemon.executor - Shut down executor word-counter:[2 2] 6044 [main] INFO backtype.storm.daemon.executor - Shutting down executor word-normalizer:[3 3] 6045 [Thread-18] INFO backtype.storm.util - Async loop interrupted! 6052 [Thread-17] INFO backtype.storm.util - Async loop interrupted! 6056 [main] INFO backtype.storm.daemon.executor - Shut down executor word-normalizer:[3 3] 6056 [main] INFO backtype.storm.daemon.executor - Shutting down executor word-reader:[4 4] 6058 [Thread-19] INFO backtype.storm.util - Async loop interrupted! ...
д»ҘдёҠжҳҜвҖңstormеҰӮдҪ•е®һзҺ°еҚ•жңәзүҲе®үиЈ…вҖқиҝҷзҜҮж–Үз« зҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒзӣёдҝЎеӨ§е®¶йғҪжңүдәҶдёҖе®ҡзҡ„дәҶи§ЈпјҢеёҢжңӣеҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүжүҖеё®еҠ©пјҢеҰӮжһңиҝҳжғіеӯҰд№ жӣҙеӨҡзҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ