您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要讲解了“mmseg4j-1.9 solr4的bug怎么处理 ”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“mmseg4j-1.9 solr4的bug怎么处理 ”吧!
目前 中文分词mmseg4j 在 solr4 下是不能正常工作的。
解决方法可简单了, 只是solr4 接口有点变化 。
中文分词mmseg4插件的作者 没及时的跟上"solr4 接口"变化。 虽然分词算法是对的,添加的文档不能建索引。
源码80M读是读不懂的。在源码里猜测查找 不能新建索引这个的原因,比较费劲,差点没找到,结果还是“凑巧”给找到了。
bug描述:
(1)java.lang.RuntimeException: java.lang.NoSuchMethodError: org.apache.l
ucene.analysis.Tokenizer.reset
报错信息:
http://code.google.com/p/mmseg4j/issues/detail?id=31 我是在分词测试时碰到这样的错误的。
解决方法:
这里的这个文件里的setReader 是新版solr4提供的。旧的接口reset 已经过期。
(2)
不能建索引 的相关描述:http://code.google.com/p/mmseg4j/issues/detail?id=38
原因:MMSegTokenizer 还是按以前版本的的solr 接口的。
MMSegTokenizer 在solr 里是缓存的,它和词库都是启动时就缓存了。 在后续有新的的短语要分词时,就会调用这个MMSegTokenizer.reset 方法把新词传进来,传给MMSegTokenizer。 但新版solr4里已经不调用这个reset方法了(也就是上图显示的那个reset方法),而是调用setReader ,这样MMSegTokenizer 实际分词的对象mmSeg就得不到新数据。于是 我加了下面的hack 代码,让mmSeg能得到新数据。
解决方法:
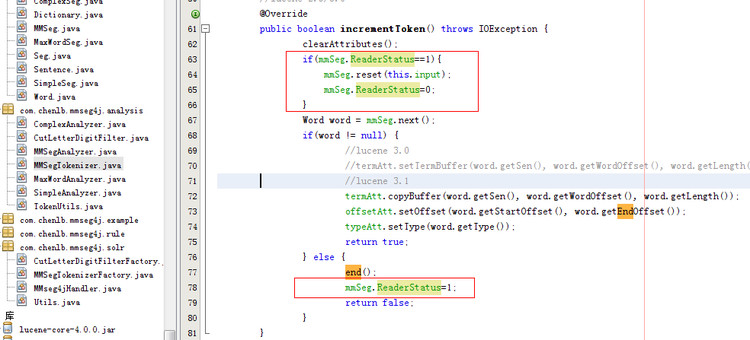
找到MMSegTokenizer.java 这个文件打开 上图 框里的内容是我新加的。 自己找到mmSeg对象加上一个ReaderStatus 属性默认值填0。
然后编译这个包。再放到solr 里去。重启tomcat 就能工作了。
感谢各位的阅读,以上就是“mmseg4j-1.9 solr4的bug怎么处理 ”的内容了,经过本文的学习后,相信大家对mmseg4j-1.9 solr4的bug怎么处理 这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。