您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
Aggregation 可以和普通查询结果并存,一个查询结果中也允许包含多个不相关的Aggregation. 如果只关心聚合结果而不关心查询结果的话会把SearchSource的size设置为0,能有效提高性能.
Metrics:
简单聚合类型, 对于目标集和中的所有文档计算聚合指标, 一般没有嵌套的sub aggregations. 比如 平均值(avg) , 求和 (sum), 计数 (count), 基数 (cardinality). Cardinality对应distinct count
Bucketing:
桶聚合类型, 在一系列的桶而不是所有文档上计算聚合指标,每个桶表示原始结果集合中符合某种条件的子集. 一般有嵌套的sub aggregations. 典型的如TermsAggregation, HistogramAggregation
Matrix:
矩阵聚合, 多维度聚合, 即根据两个或者多个聚合维度计算二维甚至多维聚合指标表格. 目前貌似只有一种MatrixStatAggregation. 并且目前不支持脚本(scripting)
Aggregation request:
两层结构:
Aggregation -> SubAggregation
Sub aggregation是在原来的Aggregation的计算结果中进一步做聚合计算
Aggregation response:
三层结构: (针对Bucketing aggregation) MultiBucketsAggregation -> Buckets -> Aggregations
Aggregation 属性:
name: 和请求中的Aggregation的名字对应
buckets: 每个Bucket对应Agggregation结果中每一个可能的取值和相应的聚合结果.
Bucket 属性:
key: 对应的是聚合维度可能的取值, 具体的值和Aggregation的类型有关, 比如Term aggregation (按交易类型计算总金额), 那么Bucket key值就是所有可能的交易类型 (credit/debit etc). 又比如DateHistogram aggregation (按天计算交易笔数), 那么Bucket key值就是具体的日期.
docCount: 对应的是每个桶中的文本数量.
value: 对应的是聚合指标的计算结果. 注意如果是多层Aggregation计算, 中间层的Aggregation value一般没有值, 比如Term aggregation. 只有到底层具体计算指标的Aggregation才有值.
aggregations: 对应请求中当前Aggregation的subAggregation的计算结果 (如果存在)
SQL映射实现的前提: 只针对聚合计算,即sql select部分存在聚合函数类型的column
映射过程很难直接描述,上几个例子方便大家理解,反正SQL的结构也无非就是SELECT/FROM/WHERE/GROUP BY/HAVING/ORDER BY. ORDER BY先不讨论,一般聚合结果不太关心顺序. FROM也很容易理解,就是索引的名字.
SQL组成部分对应的ES Builder:
| Column 1 | Column 2 | Column 3 |
|---|---|---|
| select column (聚合函数) | MetricsAggregationBuilder 由 column对应聚合函数决定 (例如 MaxAggregationBuilder) | |
| select column (group by 字段) | Bucket key | |
| where | FiltersAggregationBuilder + FiltersAggregator.KeydFilter | keyedFilter = FiltersAggregator.KeyedFilter("combineCondition", sub QueryBuilder) <br/> AggregationBuilders.filters("whereAggr", keyedFilter) |
| group by | TermsAggregationBuilder | AggregationBuilders.terms("aggregation name").field(fieldName) |
| having | MetricsAggregationBuilder 由 having 条件聚合函数决定 (例如 MaxAggregationBuilder) + BucketSelectorPipelineAggregationBuilder | PipelineAggregatorBuilders.bucketSelector(aggregationName, bucketPathMap, script) |
常用的SQL运算符和聚合函数对应的ES Builder:
| Sql element | Aggregation Type | Code to build |
|---|---|---|
| count(field) | ValueCountAggregationBuilder | AggregationBuilders.count(metricsName).field(fieldName) |
| count(distinct field) | CardinalityAggregationBuilder | AggregationBuilders.cardinality(metricsName).field(fieldName) |
| sum(field) | SumAggregationBuilder | AggregationBuilders.sum(metricsName).field(fieldName) |
| min(field) | MinAggregationBuilder | AggregationBuilders.min(metricsName).field(fieldName) |
| max(field) | MaxAggregationBuilder | AggregationBuilders.max(metricsName).field(fieldName) |
| avg(field) | AvgAggregationBuilder | AggregationBuilders.avg(metricsName).field(fieldName) |
| AND | BoolQueryBuilder | QueryBuilders.boolQuery().must().add(sub QueryBuilder) |
| OR | BoolQueryBuilder | QueryBuilders.boolQuery().should().add(sub QueryBuilder) |
| NOT | BoolQueryBuilder | QueryBuilders.boolQuery().mustNot().add(sub QueryBuilder) |
| = | TermQueryBuilder | QueryBuilders.termQuery(fieldName, value) |
| IN | TermsQueryBuilder | QueryBuilders.termsQuery(fieldName, values) |
| LIKE | WildcardQueryBuilder | QueryBuilders.wildcardQuery(fieldName, value) |
| > | RangeQueryBuilder | QueryBuilders.rangeQuery(fieldName).gt(value) |
| >= | RangeQueryBuilder | QueryBuilders.rangeQuery(fieldName).gte(value) |
| < | RangeQueryBuilder | QueryBuilders.rangeQuery(fieldName).lt(value) |
| <= | RangeQueryBuilder | QueryBuilders.rangeQuery(fieldName).lte(value) |
1.select count(payerId) as payerCount from Payment group by country
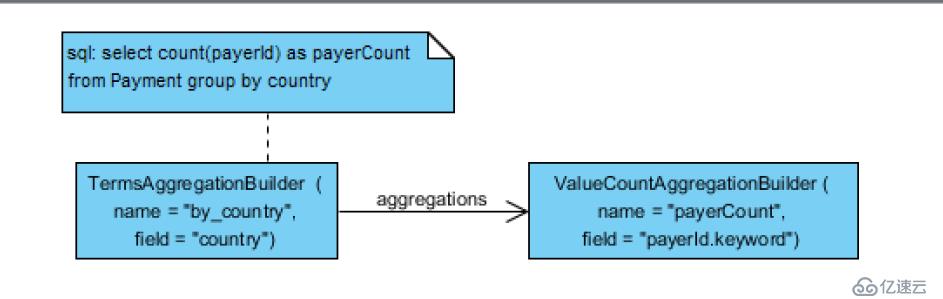
这里需要注意的是payerId这个doc的属性在实际构造的Aggregation query 中变成了 payerId.keyword,Elasticsearch 默认对于分词的字段(text类型)不支持聚合,会报出 "Fielddata is disabled on text fields by default. Set fielddata=true"的错误. fielddata聚合是一个非常costly的运算,一般不建议使用. 好在Elasticsearch索引时默认会对payerId这个属性生成两个字段, payerId 是分词的text类型, payerId.keyword是不分词的keyword类型.
2.select max(payerId) from Payment group by accountId, country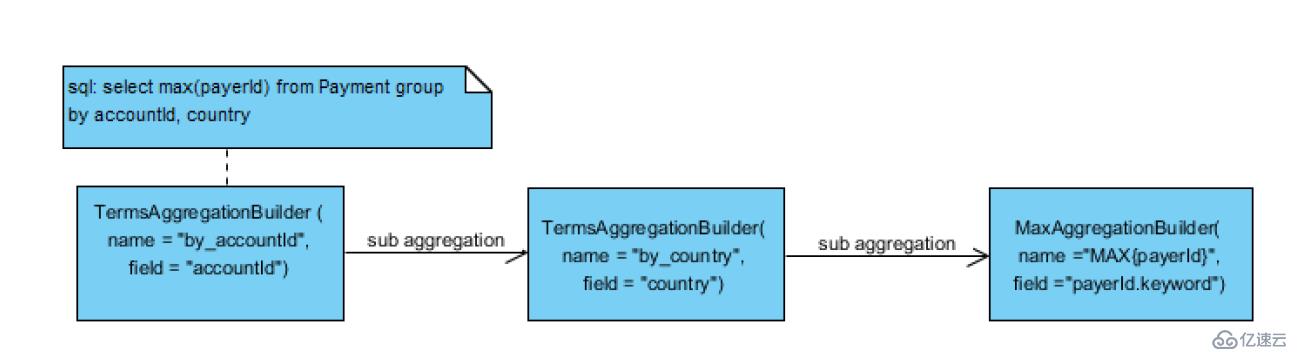
两个group by 条件对应两层term aggregation
3.select count(distinct payerId) as payerCount from Payment where country in ('CN', 'GE') group by accountId, country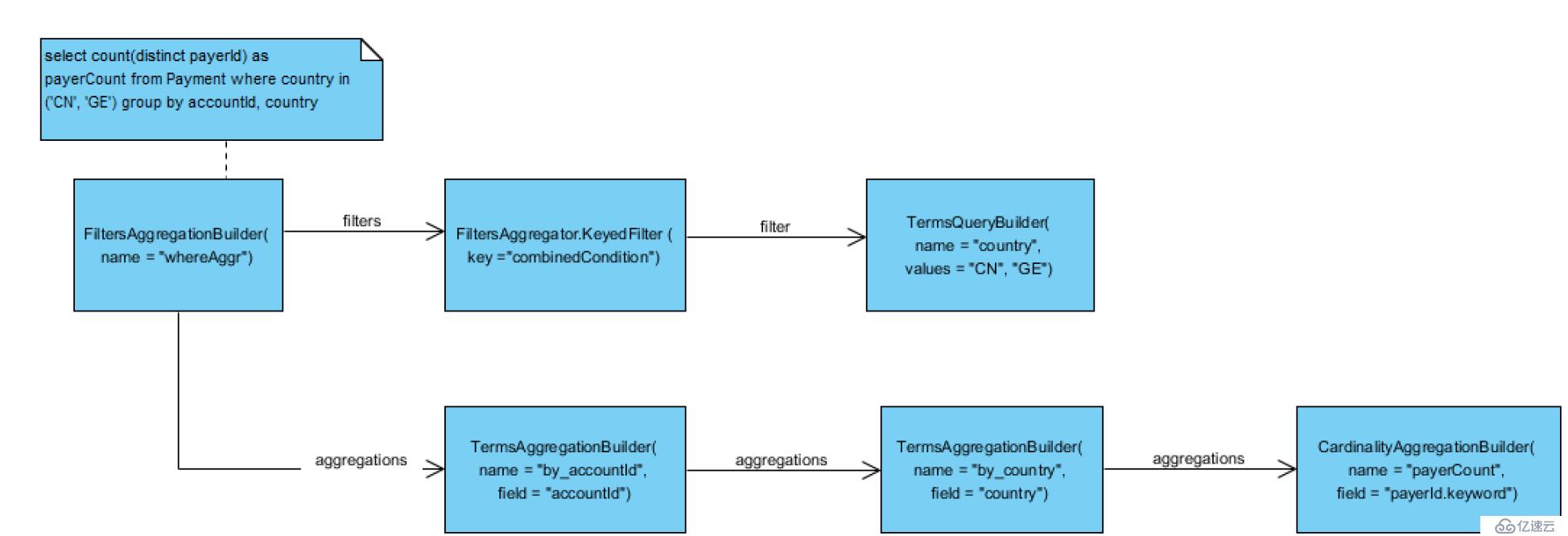
增加了where条件, 在顶层是一个FiltersAggregationBuilder. 其中分为两部分, 其中filters对应的是所有查询条件构建的一个KeyedFilter, 其中又包含了多个子查询条件. aggregations 对应的是groupBy条件和select部分的聚合函数
4.select count(distinct payerId) as payerCount from Payment where withinTime(createAt, 1, 'DAY') and name like '%SH%' group by accountId, country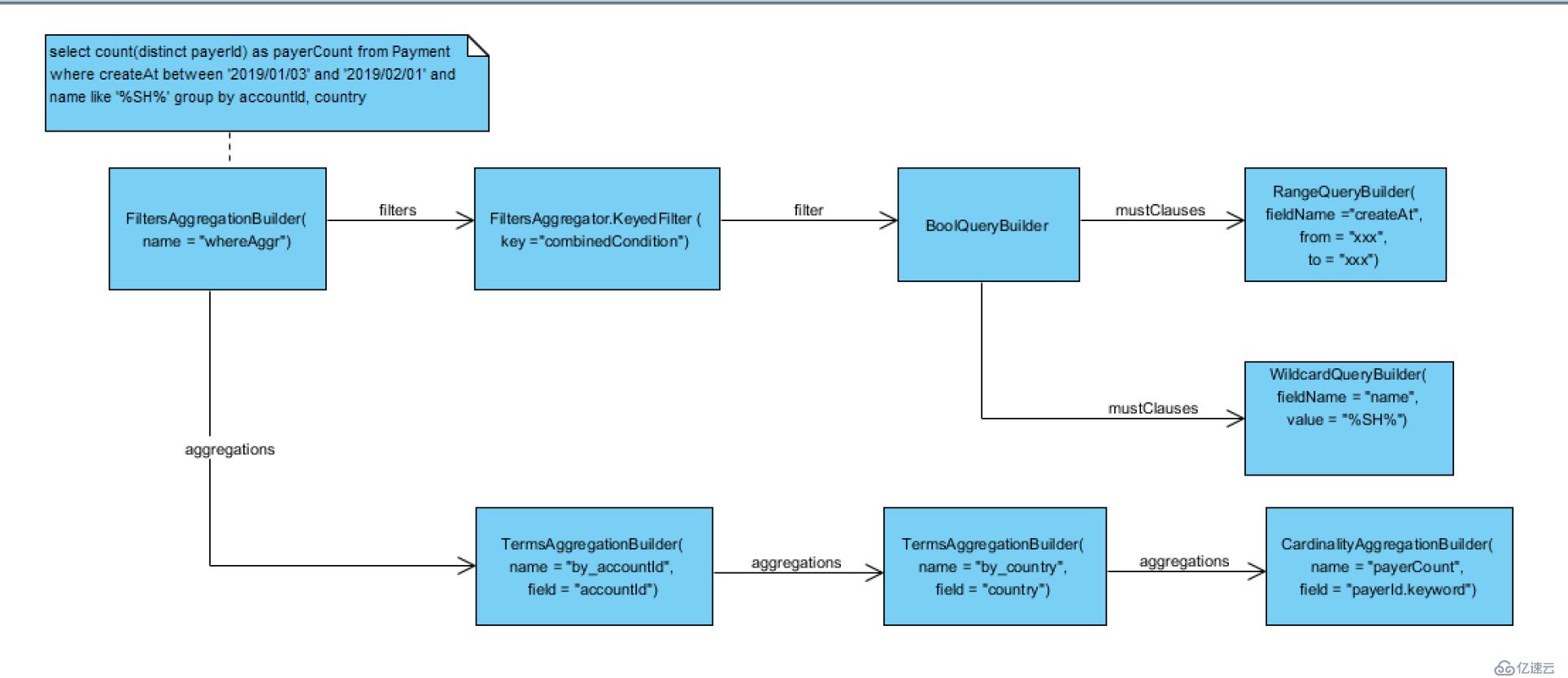
多个where条件, 用BoolQueryBuilder组合起来
5.select max(amount) as maxAmt, min(amount) as minAmt from Payment where amount > 1000.00 or amount <= 50.53 group by accountId, country having count(distinct beneficiaryId) > 3 and sum(amount) > 1530.20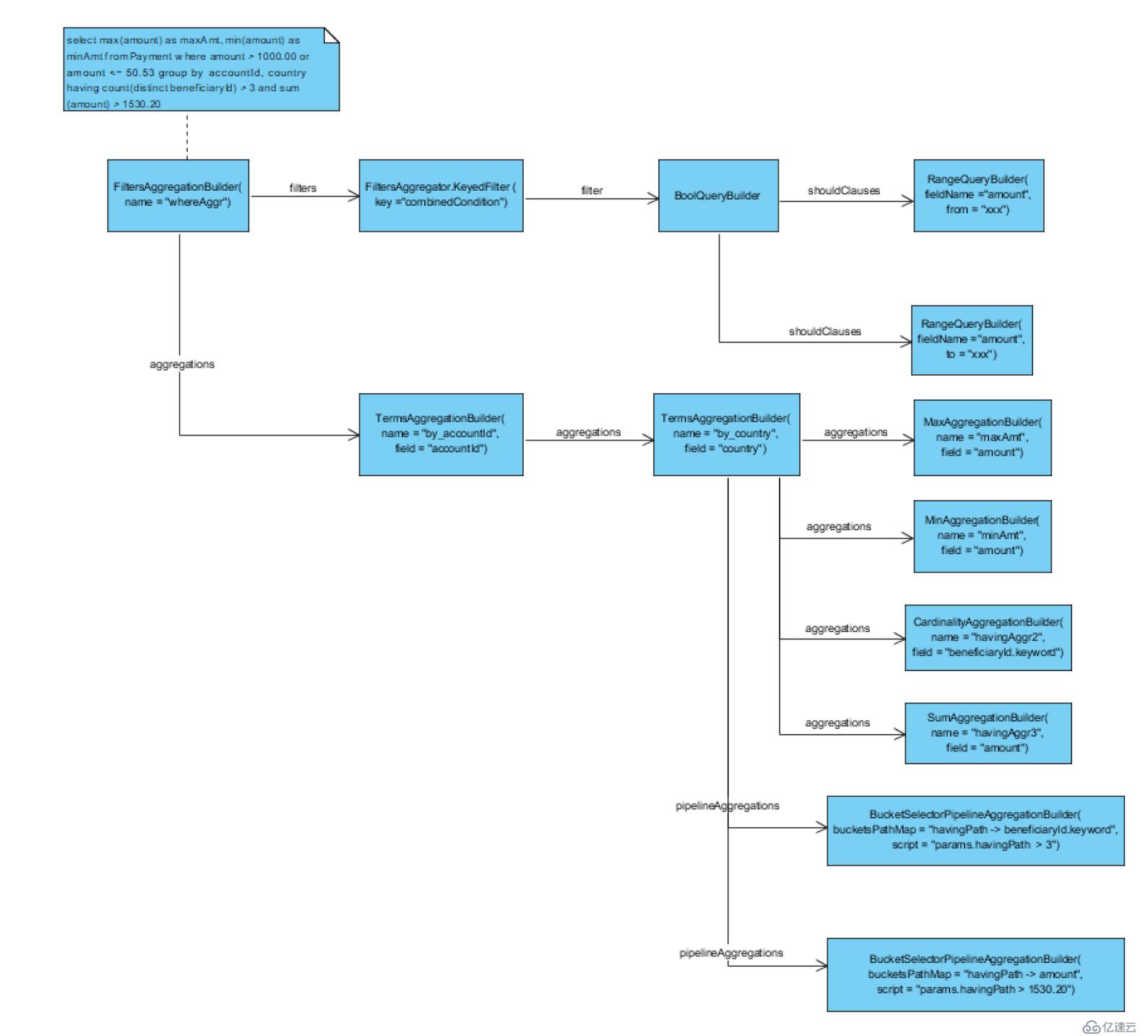
史上最复杂SQL产生! 这里主要关注having部分的处理, 用到了Pipeline类型的BucketSelectorPipelineAggregationBuilder. 在最后一个GroupBy 条件对应的term aggregation下增加了两类子节点: sub aggregations 除了包括select 部分的聚合函数还包括having条件对应的聚合函数. pipeline aggregations 包括having条件对应的 BucketSelectorPipelineAggregationBuilder. BucketSelectorPipelineAggregationBuilder 主要的属性有: bucketsPathMap: 保存了path的名字和对应的聚合属性的映射,script: 用脚本描述聚合条件,但是条件左侧不直接使用属性名而是path的名字替换
注意虽然从逻辑上来说having 条件是应用在之前计算出聚合的结果之上, 但是从ES Aggregation的结构来看, BucketSelectorPipelineAggregationBuilder和having 条件中对应聚合指标的Aggregation是兄弟关系而不是父子关系!
另外要注意script path 是对于兄弟节点(sibling node)一个相对路径而不是从根节点Aggregation的绝对路径,用的是聚合属性的名称而不是Aggregation本身的名称. 并且要求根据路径访问到的Bucket必须是唯一的,因为BucketSelector只是根据条件判断当前Bucket是否被选择, 如果路径返回多个Bucket则无法应用这种Bool判断.
6.select count(paymentId) from Payment group by timeRange(createdAt, '1D', 'yyyy/MM/dd')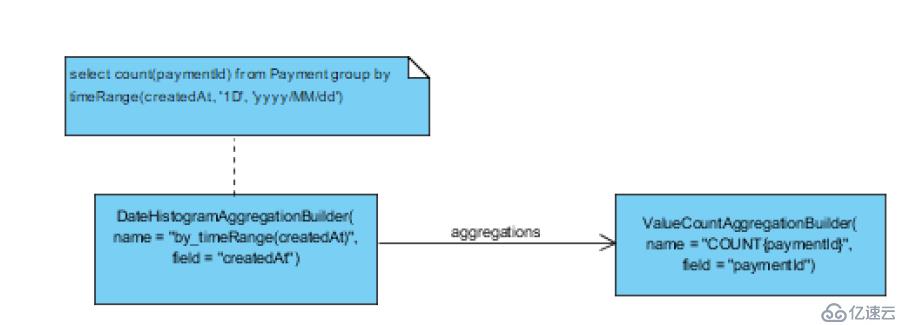
这里用到一个自定义函数timeRage, 表示对于createAt这个属性按天聚合,对应的ES aggregation类型为DateHistogramAggregation
Bucket count
Distinct count: Elasticsearch 采用的是基于hyperLogLog的近似算法.
https://www.elastic.co/guide/en/elasticsearch/reference/current/fielddata.html
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。