жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
еӨ§ж•°жҚ®дёҚжҳҜжҹҗдёӘдё“дёҡжҲ–дёҖй—Ёзј–зЁӢиҜӯиЁҖпјҢе®һйҷ…дёҠе®ғжҳҜдёҖзі»еҲ—жҠҖжңҜзҡ„з»„еҗҲиҝҗз”ЁгҖӮжңүдәәйҖҡиҝҮдёӢж–№зҡ„зӯүејҸз»ҷеҮәдәҶеӨ§ж•°жҚ®зҡ„е®ҡд№үгҖӮеӨ§ж•°жҚ® = зј–зЁӢжҠҖе·§ + ж•°жҚ®з»“жһ„е’Ңз®—жі• + еҲҶжһҗиғҪеҠӣ + ж•°жҚ®еә“жҠҖиғҪ + ж•°еӯҰ + жңәеҷЁеӯҰд№ + NLP + OS + еҜҶз ҒеӯҰ + 并иЎҢзј–зЁӢиҷҪ然иҝҷдёӘзӯүејҸзңӢиө·жқҘеҫҲй•ҝпјҢйңҖиҰҒеӯҰд№ зҡ„дёңиҘҝеҫҲеӨҡпјҢдҪҶд»ҳеҮәе’ҢжұҮжҠҘжҳҜжҲҗжӯЈжҜ”зҡ„пјҢиҮіе°‘е’Ңи–Әиө„жҳҜжҲҗжӯЈжҜ”зҡ„гҖӮ既然иҰҒеӯҰзҡ„зҹҘиҜҶеҫҲеӨҡпјҢйӮЈд№ҲдёҖдёӘжӯЈзЎ®зҡ„еӯҰд№ йЎәеәҸе°ұйқһеёёе…ій”®дәҶгҖӮ
.еңЁе…Ҙй—ЁеӯҰд№ еӨ§ж•°жҚ®зҡ„иҝҮзЁӢеҪ“дёӯжңүйҒҮи§ҒеӯҰд№ пјҢиЎҢдёҡпјҢзјәд№Ҹзі»з»ҹеӯҰд№ и·ҜзәҝпјҢзі»з»ҹеӯҰд№ и§„еҲ’пјҢж¬ўиҝҺдҪ еҠ е…ҘжҲ‘зҡ„еӨ§ж•°жҚ®еӯҰд№ дәӨжөҒиЈҷпјҡ529867072 пјҢиЈҷж–Ү件жңүжҲ‘иҝҷеҮ е№ҙж•ҙзҗҶзҡ„еӨ§ж•°жҚ®еӯҰд№ жүӢеҶҢпјҢејҖеҸ‘е·Ҙе…·пјҢPDFж–ҮжЎЈд№ҰзұҚпјҢдҪ еҸҜд»ҘиҮӘиЎҢдёӢиҪҪгҖӮ
гҖҢеӨ§ж•°жҚ®гҖҚеҲ¶е®ҡдәҶдёҖжқЎдё“дёҡзҡ„еӯҰд№ и·Ҝеҫ„пјҢеёҢжңӣеё®еҠ©еӨ§е®¶е°‘иө°ејҜи·ҜгҖӮдё»иҰҒеҲҶдёә 7 дёӘйҳ¶ж®өпјҡе…Ҙй—ЁзҹҘиҜҶ вҶ’ Java еҹәзЎҖ вҶ’ Scala еҹәзЎҖ вҶ’ Hadoop жҠҖжңҜжЁЎеқ— вҶ’ Hadoop йЎ№зӣ®е®һжҲҳ вҶ’ Spark жҠҖжңҜжЁЎеқ— вҶ’ еӨ§ж•°жҚ®йЎ№зӣ®е®һжҲҳгҖӮе…¶дёӯпјҢйҳ¶ж®өдёҖеҲ°йҳ¶ж®өдә”еқҮдёәе…Қиҙ№иҜҫзЁӢпјҢе…·дҪ“иҜҙжқҘпјҡйҳ¶ж®өдёҖпјҡеӯҰд№ е…Ҙй—ЁзҹҘиҜҶиҝҷдёҖйғЁеҲҶдё»иҰҒй’ҲеҜ№зҡ„жҳҜж–°жүӢпјҢеңЁеӯҰд№ д№ӢеүҚйңҖиҰҒе…ҲжҺҢжҸЎеҹәжң¬зҡ„ж•°жҚ®еә“зҹҘиҜҶгҖӮMySQL жҳҜдёҖдёӘ DBMSпјҲж•°жҚ®еә“з®ЎзҗҶзі»з»ҹпјүпјҢжҳҜжңҖжөҒиЎҢзҡ„е…ізі»еһӢж•°жҚ®еә“з®ЎзҗҶзі»з»ҹпјҲе…ізі»ж•°жҚ®еә“пјҢжҳҜе»әз«ӢеңЁе…ізі»ж•°жҚ®еә“жЁЎеһӢеҹәзЎҖдёҠзҡ„ж•°жҚ®еә“пјҢеҖҹеҠ©дәҺйӣҶеҗҲд»Јж•°зӯүжҰӮеҝөе’Ңж–№жі•жқҘеӨ„зҗҶж•°жҚ®еә“дёӯзҡ„ж•°жҚ®пјүгҖӮMongoDB жҳҜ IT иЎҢдёҡйқһеёёжөҒиЎҢзҡ„дёҖз§Қйқһе…ізі»еһӢж•°жҚ®еә“пјҲNoSQLпјүпјҢе…¶зҒөжҙ»зҡ„ж•°жҚ®еӯҳеӮЁж–№ејҸеӨҮеҸ—еҪ“еүҚ IT д»Һдёҡдәәе‘ҳзҡ„йқ’зқҗгҖӮиҖҢ Redis жҳҜдёҖдёӘејҖжәҗгҖҒж”ҜжҢҒзҪ‘з»ңгҖҒеҹәдәҺеҶ…еӯҳгҖҒй”®еҖјеҜ№еӯҳеӮЁж•°жҚ®еә“гҖӮдёӨиҖ…йғҪйқһеёёжңүеҝ…иҰҒдәҶи§ЈгҖӮ
еӯҰд№ еӨ§ж•°жҚ®йҰ–е…ҲжҲ‘们иҰҒеӯҰд№ JavaиҜӯиЁҖе’ҢLinuxж“ҚдҪңзі»з»ҹпјҢиҝҷдёӨдёӘжҳҜеӯҰд№ еӨ§ж•°жҚ®зҡ„еҹәзЎҖпјҢеӯҰд№ зҡ„йЎәеәҸдёҚеҲҶеүҚеҗҺгҖӮ
JavaеӨ§е®¶йғҪзҹҘйҒ“Javaзҡ„ж–№еҗ‘жңүJavaSEгҖҒJavaEEгҖҒJavaMEпјҢеӯҰд№ еӨ§ж•°жҚ®иҰҒеӯҰд№ йӮЈдёӘж–№еҗ‘е‘ўпјҹеҸӘйңҖиҰҒеӯҰд№ Javaзҡ„ж ҮеҮҶзүҲJavaSEе°ұеҸҜд»ҘдәҶпјҢеғҸServletгҖҒJSPгҖҒTomcatгҖҒStrutsгҖҒSpringгҖҒHibernateпјҢMybatisйғҪжҳҜJavaEEж–№еҗ‘зҡ„жҠҖжңҜеңЁеӨ§ж•°жҚ®жҠҖжңҜйҮҢз”ЁеҲ°зҡ„并дёҚеӨҡпјҢеҸӘйңҖиҰҒдәҶи§Је°ұеҸҜд»ҘдәҶпјҢеҪ“然JavaжҖҺд№ҲиҝһжҺҘж•°жҚ®еә“иҝҳжҳҜиҰҒзҹҘйҒ“зҡ„пјҢеғҸJDBCдёҖе®ҡиҰҒжҺҢжҸЎдёҖдёӢгҖӮжңүеҗҢеӯҰиҜҙHibernateжҲ–Mybitesд№ҹиғҪиҝһжҺҘж•°жҚ®еә“е•ҠпјҢдёәд»Җд№ҲдёҚеӯҰд№ дёҖдёӢпјҢжҲ‘иҝҷйҮҢдёҚжҳҜиҜҙеӯҰиҝҷдәӣдёҚеҘҪпјҢиҖҢжҳҜиҜҙеӯҰиҝҷдәӣеҸҜиғҪдјҡз”ЁдҪ еҫҲеӨҡж—¶й—ҙпјҢеҲ°жңҖеҗҺе·ҘдҪңдёӯд№ҹдёҚеёёз”ЁпјҢжҲ‘иҝҳжІЎзңӢеҲ°и°ҒеҒҡеӨ§ж•°жҚ®еӨ„зҗҶз”ЁеҲ°иҝҷдёӨдёӘдёңиҘҝзҡ„пјҢеҪ“然дҪ зҡ„зІҫеҠӣеҫҲе……и¶ізҡ„иҜқпјҢеҸҜд»ҘеӯҰеӯҰHibernateжҲ–Mybitesзҡ„еҺҹзҗҶпјҢдёҚиҰҒеҸӘеӯҰAPIпјҢиҝҷж ·еҸҜд»ҘеўһеҠ дҪ еҜ№Javaж“ҚдҪңж•°жҚ®еә“зҡ„зҗҶи§ЈпјҢеӣ дёәиҝҷдёӨдёӘжҠҖжңҜзҡ„ж ёеҝғе°ұжҳҜJavaзҡ„еҸҚе°„еҠ дёҠJDBCзҡ„еҗ„з§ҚдҪҝз”ЁгҖӮ
Linuxеӣ дёәеӨ§ж•°жҚ®зӣёе…іиҪҜ件йғҪжҳҜеңЁLinuxдёҠиҝҗиЎҢзҡ„пјҢжүҖд»ҘLinuxиҰҒеӯҰд№ зҡ„жүҺе®һдёҖдәӣпјҢеӯҰеҘҪLinuxеҜ№дҪ еҝ«йҖҹжҺҢжҸЎеӨ§ж•°жҚ®зӣёе…іжҠҖжңҜдјҡжңүеҫҲеӨ§зҡ„её®еҠ©пјҢиғҪи®©дҪ жӣҙеҘҪзҡ„зҗҶи§ЈhadoopгҖҒhiveгҖҒhbaseгҖҒsparkзӯүеӨ§ж•°жҚ®иҪҜ件зҡ„иҝҗиЎҢзҺҜеўғе’ҢзҪ‘з»ңзҺҜеўғй…ҚзҪ®пјҢиғҪе°‘иё©еҫҲеӨҡеқ‘пјҢеӯҰдјҡshellе°ұиғҪзңӢжҮӮи„ҡжң¬иҝҷж ·иғҪжӣҙе®№жҳ“зҗҶи§Је’Ңй…ҚзҪ®еӨ§ж•°жҚ®йӣҶзҫӨгҖӮиҝҳиғҪи®©дҪ еҜ№д»ҘеҗҺж–°еҮәзҡ„еӨ§ж•°жҚ®жҠҖжңҜеӯҰд№ иө·жқҘжӣҙеҝ«гҖӮеҘҪиҜҙе®ҢеҹәзЎҖдәҶпјҢеҶҚиҜҙиҜҙиҝҳйңҖиҰҒеӯҰд№ е“ӘдәӣеӨ§ж•°жҚ®жҠҖжңҜпјҢеҸҜд»ҘжҢүжҲ‘еҶҷзҡ„йЎәеәҸеӯҰдёӢеҺ»гҖӮ
HadoopиҝҷжҳҜзҺ°еңЁжөҒиЎҢзҡ„еӨ§ж•°жҚ®еӨ„зҗҶе№іеҸ°еҮ д№Һе·Із»ҸжҲҗдёәеӨ§ж•°жҚ®зҡ„д»ЈеҗҚиҜҚпјҢжүҖд»ҘиҝҷдёӘжҳҜеҝ…еӯҰзҡ„гҖӮHadoopйҮҢйқўеҢ…жӢ¬еҮ дёӘ组件HDFSгҖҒMapReduceе’ҢYARNпјҢHDFSжҳҜеӯҳеӮЁж•°жҚ®зҡ„ең°ж–№е°ұеғҸжҲ‘们з”өи„‘зҡ„зЎ¬зӣҳдёҖж ·ж–Ү件йғҪеӯҳеӮЁеңЁиҝҷдёӘдёҠйқўпјҢMapReduceжҳҜеҜ№ж•°жҚ®иҝӣиЎҢеӨ„зҗҶи®Ўз®—зҡ„пјҢе®ғжңүдёӘзү№зӮ№е°ұжҳҜдёҚз®ЎеӨҡеӨ§зҡ„ж•°жҚ®еҸӘиҰҒз»ҷе®ғж—¶й—ҙе®ғе°ұиғҪжҠҠж•°жҚ®и·‘е®ҢпјҢдҪҶжҳҜж—¶й—ҙеҸҜиғҪдёҚжҳҜеҫҲеҝ«жүҖд»Ҙе®ғеҸ«ж•°жҚ®зҡ„жү№еӨ„зҗҶгҖӮ
YARNжҳҜдҪ“зҺ°Hadoopе№іеҸ°жҰӮеҝөзҡ„йҮҚиҰҒ组件жңүдәҶе®ғеӨ§ж•°жҚ®з”ҹжҖҒдҪ“зі»зҡ„е…¶е®ғиҪҜ件е°ұиғҪеңЁhadoopдёҠиҝҗиЎҢдәҶпјҢиҝҷж ·е°ұиғҪжӣҙеҘҪзҡ„еҲ©з”ЁHDFSеӨ§еӯҳеӮЁзҡ„дјҳеҠҝе’ҢиҠӮзңҒжӣҙеӨҡзҡ„иө„жәҗжҜ”еҰӮжҲ‘们е°ұдёҚз”ЁеҶҚеҚ•зӢ¬е»әдёҖдёӘsparkзҡ„йӣҶзҫӨдәҶпјҢи®©е®ғзӣҙжҺҘи·‘еңЁзҺ°жңүзҡ„hadoop yarnдёҠйқўе°ұеҸҜд»ҘдәҶгҖӮ
е…¶е®һжҠҠHadoopзҡ„иҝҷдәӣ组件еӯҰжҳҺзҷҪдҪ е°ұиғҪеҒҡеӨ§ж•°жҚ®зҡ„еӨ„зҗҶдәҶпјҢеҸӘдёҚиҝҮдҪ зҺ°еңЁиҝҳеҸҜиғҪеҜ№"еӨ§ж•°жҚ®"еҲ°еә•жңүеӨҡеӨ§иҝҳжІЎжңүдёӘеӨӘжё…жҘҡзҡ„жҰӮеҝөпјҢеҗ¬жҲ‘зҡ„еҲ«зә з»“иҝҷдёӘгҖӮзӯүд»ҘеҗҺдҪ е·ҘдҪңдәҶе°ұдјҡжңүеҫҲеӨҡеңәжҷҜйҒҮеҲ°еҮ еҚҒT/еҮ зҷҫTеӨ§и§„жЁЎзҡ„ж•°жҚ®пјҢеҲ°ж—¶еҖҷдҪ е°ұдёҚдјҡи§үеҫ—ж•°жҚ®еӨ§зңҹеҘҪпјҢи¶ҠеӨ§и¶ҠжңүдҪ еӨҙз–јзҡ„гҖӮеҪ“然еҲ«жҖ•еӨ„зҗҶиҝҷд№ҲеӨ§и§„жЁЎзҡ„ж•°жҚ®пјҢеӣ дёәиҝҷжҳҜдҪ зҡ„д»·еҖјжүҖеңЁпјҢи®©йӮЈдәӣдёӘжҗһJavaeeзҡ„phpзҡ„html5зҡ„е’ҢDBAзҡ„зҫЎж…•еҺ»еҗ§гҖӮ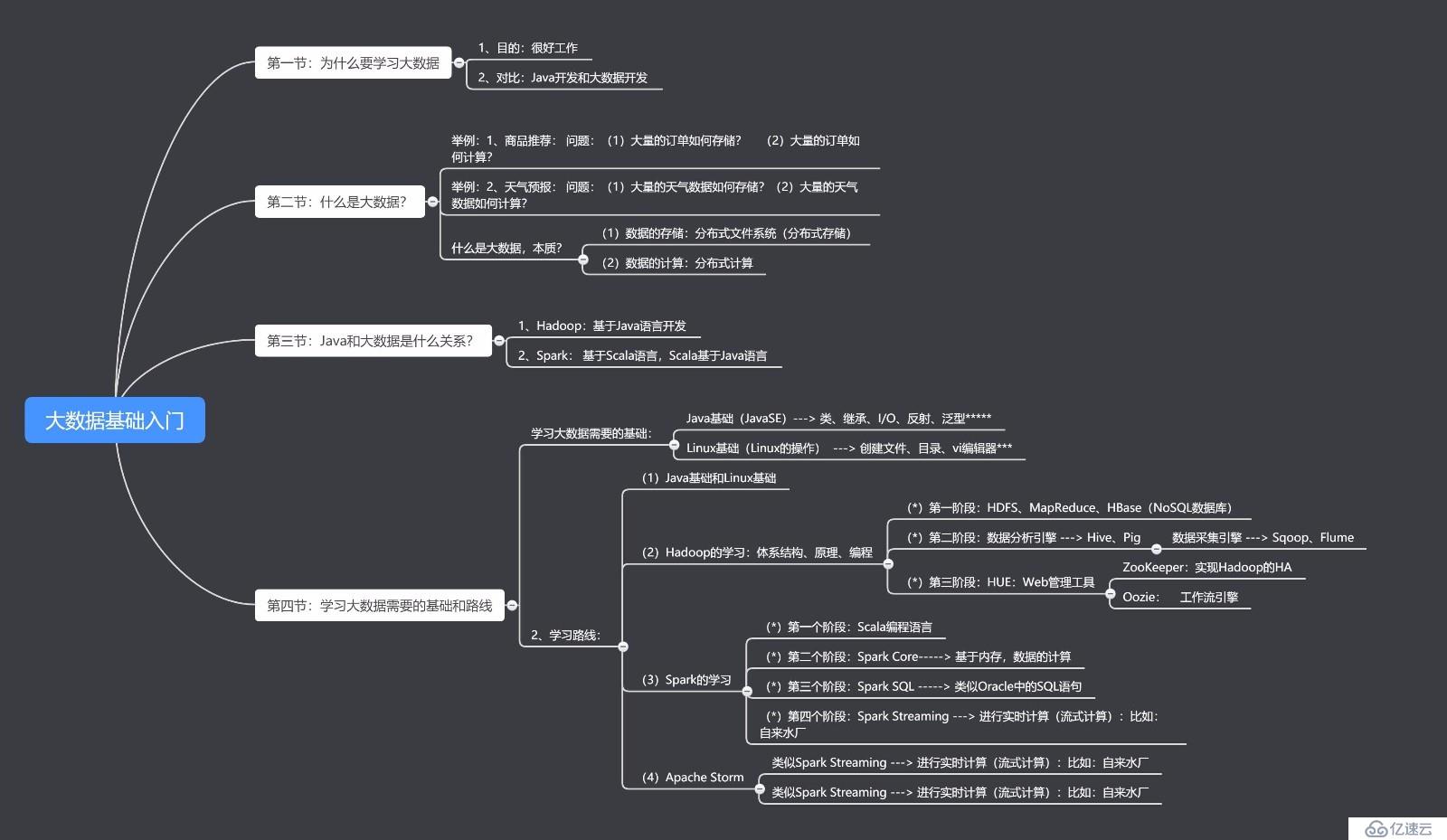
и®°дҪҸеӯҰеҲ°иҝҷйҮҢеҸҜд»ҘдҪңдёәдҪ еӯҰеӨ§ж•°жҚ®зҡ„дёҖдёӘиҠӮзӮ№гҖӮ
ZookeeperиҝҷжҳҜдёӘдёҮйҮ‘жІ№пјҢе®үиЈ…Hadoopзҡ„HAзҡ„ж—¶еҖҷе°ұдјҡз”ЁеҲ°е®ғпјҢд»ҘеҗҺзҡ„Hbaseд№ҹдјҡз”ЁеҲ°е®ғгҖӮе®ғдёҖиҲ¬з”ЁжқҘеӯҳж”ҫдёҖдәӣзӣёдә’еҚҸдҪңзҡ„дҝЎжҒҜпјҢиҝҷдәӣдҝЎжҒҜжҜ”иҫғе°ҸдёҖиҲ¬дёҚдјҡи¶…иҝҮ1MпјҢйғҪжҳҜдҪҝз”Ёе®ғзҡ„иҪҜ件еҜ№е®ғжңүдҫқиө–пјҢеҜ№дәҺжҲ‘们дёӘдәәжқҘи®ІеҸӘйңҖиҰҒжҠҠе®ғе®үиЈ…жӯЈзЎ®пјҢи®©е®ғжӯЈеёёзҡ„runиө·жқҘе°ұеҸҜд»ҘдәҶгҖӮ
MysqlжҲ‘们еӯҰд№ е®ҢеӨ§ж•°жҚ®зҡ„еӨ„зҗҶдәҶпјҢжҺҘдёӢжқҘеӯҰд№ еӯҰд№ е°Ҹж•°жҚ®зҡ„еӨ„зҗҶе·Ҙе…·mysqlж•°жҚ®еә“пјҢеӣ дёәдёҖдјҡиЈ…hiveзҡ„ж—¶еҖҷиҰҒз”ЁеҲ°пјҢmysqlйңҖиҰҒжҺҢжҸЎеҲ°д»Җд№ҲеұӮеәҰйӮЈпјҹдҪ иғҪеңЁLinuxдёҠжҠҠе®ғе®үиЈ…еҘҪпјҢиҝҗиЎҢиө·жқҘпјҢдјҡй…ҚзҪ®з®ҖеҚ•зҡ„жқғйҷҗпјҢдҝ®ж”№rootзҡ„еҜҶз ҒпјҢеҲӣе»әж•°жҚ®еә“гҖӮиҝҷйҮҢдё»иҰҒзҡ„жҳҜеӯҰд№ SQLзҡ„иҜӯжі•пјҢеӣ дёәhiveзҡ„иҜӯжі•е’ҢиҝҷдёӘйқһеёёзӣёдјјгҖӮ
SqoopиҝҷдёӘжҳҜз”ЁдәҺжҠҠMysqlйҮҢзҡ„ж•°жҚ®еҜје…ҘеҲ°HadoopйҮҢзҡ„гҖӮеҪ“然дҪ д№ҹеҸҜд»ҘдёҚз”ЁиҝҷдёӘпјҢзӣҙжҺҘжҠҠMysqlж•°жҚ®иЎЁеҜјеҮәжҲҗж–Ү件еҶҚж”ҫеҲ°HDFSдёҠд№ҹжҳҜдёҖж ·зҡ„пјҢеҪ“然з”ҹдә§зҺҜеўғдёӯдҪҝз”ЁиҰҒжіЁж„ҸMysqlзҡ„еҺӢеҠӣгҖӮHiveиҝҷдёӘдёңиҘҝеҜ№дәҺдјҡSQLиҜӯжі•зҡ„жқҘиҜҙе°ұжҳҜзҘһеҷЁпјҢе®ғиғҪи®©дҪ еӨ„зҗҶеӨ§ж•°жҚ®еҸҳзҡ„еҫҲз®ҖеҚ•пјҢдёҚдјҡеҶҚиҙ№еҠІзҡ„зј–еҶҷMapReduceзЁӢеәҸгҖӮжңүзҡ„дәәиҜҙPigйӮЈпјҹе®ғе’ҢPigе·®дёҚеӨҡжҺҢжҸЎдёҖдёӘе°ұеҸҜд»ҘдәҶгҖӮ
Oozie既然еӯҰдјҡHiveдәҶпјҢжҲ‘зӣёдҝЎдҪ дёҖе®ҡйңҖиҰҒиҝҷдёӘдёңиҘҝпјҢе®ғеҸҜд»Ҙеё®дҪ з®ЎзҗҶдҪ зҡ„HiveжҲ–иҖ…MapReduceгҖҒSparkи„ҡжң¬пјҢиҝҳиғҪжЈҖжҹҘдҪ зҡ„зЁӢеәҸжҳҜеҗҰжү§иЎҢжӯЈзЎ®пјҢеҮәй”ҷдәҶз»ҷдҪ еҸ‘жҠҘиӯҰ并иғҪеё®дҪ йҮҚиҜ•зЁӢеәҸпјҢжңҖйҮҚиҰҒзҡ„жҳҜиҝҳиғҪеё®дҪ й…ҚзҪ®д»»еҠЎзҡ„дҫқиө–е…ізі»гҖӮжҲ‘зӣёдҝЎдҪ дёҖе®ҡдјҡе–ңж¬ўдёҠе®ғзҡ„пјҢдёҚ然дҪ зңӢзқҖйӮЈдёҖеӨ§е Ҷи„ҡжң¬пјҢе’ҢеҜҶеҜҶйә»йә»зҡ„crondжҳҜдёҚжҳҜжңүз§ҚжғіеұҺзҡ„ж„ҹи§үгҖӮHbaseиҝҷжҳҜHadoopз”ҹжҖҒдҪ“зі»дёӯзҡ„NOSQLж•°жҚ®еә“пјҢд»–зҡ„ж•°жҚ®жҳҜжҢүз…§keyе’Ңvalueзҡ„еҪўејҸеӯҳеӮЁзҡ„并且keyжҳҜе”ҜдёҖзҡ„пјҢжүҖд»Ҙе®ғиғҪз”ЁжқҘеҒҡж•°жҚ®зҡ„жҺ’йҮҚпјҢе®ғдёҺMYSQLзӣёжҜ”иғҪеӯҳеӮЁзҡ„ж•°жҚ®йҮҸеӨ§еҫҲеӨҡгҖӮжүҖд»Ҙд»–еёёиў«з”ЁдәҺеӨ§ж•°жҚ®еӨ„зҗҶе®ҢжҲҗд№ӢеҗҺзҡ„еӯҳеӮЁзӣ®зҡ„ең°гҖӮ
KafkaиҝҷжҳҜдёӘжҜ”иҫғеҘҪз”Ёзҡ„йҳҹеҲ—е·Ҙе…·пјҢйҳҹеҲ—жҳҜе№Іеҗ—зҡ„пјҹжҺ’йҳҹд№°зҘЁдҪ зҹҘйҒ“дёҚпјҹж•°жҚ®еӨҡдәҶеҗҢж ·д№ҹйңҖиҰҒжҺ’йҳҹеӨ„зҗҶпјҢиҝҷж ·дёҺдҪ еҚҸдҪңзҡ„е…¶е®ғеҗҢеӯҰдёҚдјҡеҸ«иө·жқҘпјҢдҪ е№Іеҗ—з»ҷжҲ‘иҝҷд№ҲеӨҡзҡ„ж•°жҚ®пјҲжҜ”еҰӮеҘҪеҮ зҷҫGзҡ„ж–Ү件пјүжҲ‘жҖҺд№ҲеӨ„зҗҶеҫ—иҝҮжқҘпјҢдҪ еҲ«жҖӘд»–еӣ дёәд»–дёҚжҳҜжҗһеӨ§ж•°жҚ®зҡ„пјҢдҪ еҸҜд»Ҙи·ҹд»–и®ІжҲ‘жҠҠж•°жҚ®ж”ҫеңЁйҳҹеҲ—йҮҢдҪ дҪҝз”Ёзҡ„ж—¶еҖҷдёҖдёӘдёӘжӢҝпјҢиҝҷж ·д»–е°ұдёҚеңЁжҠұжҖЁдәҶ马дёҠзҒ°жөҒжөҒзҡ„еҺ»дјҳеҢ–д»–зҡ„зЁӢеәҸеҺ»дәҶгҖӮеӣ дёәеӨ„зҗҶдёҚиҝҮжқҘе°ұжҳҜд»–зҡ„дәӢжғ…гҖӮиҖҢдёҚжҳҜдҪ з»ҷзҡ„й—®йўҳгҖӮеҪ“然жҲ‘们д№ҹеҸҜд»ҘеҲ©з”ЁиҝҷдёӘе·Ҙе…·жқҘеҒҡзәҝдёҠе®һж—¶ж•°жҚ®зҡ„е…Ҙеә“жҲ–е…ҘHDFSпјҢиҝҷж—¶дҪ еҸҜд»ҘдёҺдёҖдёӘеҸ«Flumeзҡ„е·Ҙе…·й…ҚеҗҲдҪҝз”ЁпјҢе®ғжҳҜдё“й—Ёз”ЁжқҘжҸҗдҫӣеҜ№ж•°жҚ®иҝӣиЎҢз®ҖеҚ•еӨ„зҗҶпјҢ并еҶҷеҲ°еҗ„з§Қж•°жҚ®жҺҘеҸ—ж–№пјҲжҜ”еҰӮKafkaпјүзҡ„гҖӮ
Sparkе®ғжҳҜз”ЁжқҘејҘиЎҘеҹәдәҺMapReduceеӨ„зҗҶж•°жҚ®йҖҹеәҰдёҠзҡ„зјәзӮ№пјҢе®ғзҡ„зү№зӮ№жҳҜжҠҠж•°жҚ®иЈ…иҪҪеҲ°еҶ…еӯҳдёӯи®Ўз®—иҖҢдёҚжҳҜеҺ»иҜ»ж…ўзҡ„иҰҒжӯ»иҝӣеҢ–иҝҳзү№еҲ«ж…ўзҡ„зЎ¬зӣҳгҖӮзү№еҲ«йҖӮеҗҲеҒҡиҝӯд»Јиҝҗз®—пјҢжүҖд»Ҙз®—жі•жөҒ们зү№еҲ«зЁҖйҘӯе®ғгҖӮе®ғжҳҜз”Ёscalaзј–еҶҷзҡ„гҖӮJavaиҜӯиЁҖжҲ–иҖ…ScalaйғҪеҸҜд»Ҙж“ҚдҪңе®ғпјҢеӣ дёәе®ғ们йғҪжҳҜз”ЁJVMзҡ„гҖӮ
.еңЁе…Ҙй—ЁеӯҰд№ еӨ§ж•°жҚ®зҡ„иҝҮзЁӢеҪ“дёӯжңүйҒҮи§ҒеӯҰд№ пјҢиЎҢдёҡпјҢзјәд№Ҹзі»з»ҹеӯҰд№ и·ҜзәҝпјҢзі»з»ҹеӯҰд№ и§„еҲ’пјҢж¬ўиҝҺдҪ еҠ е…ҘжҲ‘зҡ„еӨ§ж•°жҚ®еӯҰд№ дәӨжөҒиЈҷпјҡ529867072 пјҢиЈҷж–Ү件жңүжҲ‘иҝҷеҮ е№ҙж•ҙзҗҶзҡ„еӨ§ж•°жҚ®еӯҰд№ жүӢеҶҢпјҢејҖеҸ‘е·Ҙе…·пјҢPDFж–ҮжЎЈд№ҰзұҚпјҢдҪ еҸҜд»ҘиҮӘиЎҢдёӢиҪҪгҖӮ
дјҡиҝҷдәӣдёңиҘҝдҪ е°ұжҲҗдёәдёҖдёӘдё“дёҡзҡ„еӨ§ж•°жҚ®ејҖеҸ‘е·ҘзЁӢеёҲдәҶпјҢжңҲи–Ә2WйғҪжҳҜе°ҸжҜӣжҜӣйӣЁеҗҺз»ӯжҸҗй«ҳ пјҡеҪ“然иҝҳжҳҜжңүеҫҲжңүеҸҜд»ҘжҸҗй«ҳзҡ„ең°ж–№пјҢжҜ”еҰӮеӯҰд№ дёӢpythonпјҢеҸҜд»Ҙз”Ёе®ғжқҘзј–еҶҷзҪ‘з»ңзҲ¬иҷ«гҖӮиҝҷж ·жҲ‘们е°ұеҸҜд»ҘиҮӘе·ұйҖ ж•°жҚ®дәҶпјҢзҪ‘з»ңдёҠзҡ„еҗ„з§Қж•°жҚ®дҪ й«ҳе…ҙйғҪеҸҜд»ҘдёӢиҪҪеҲ°дҪ зҡ„йӣҶзҫӨдёҠеҺ»еӨ„зҗҶгҖӮ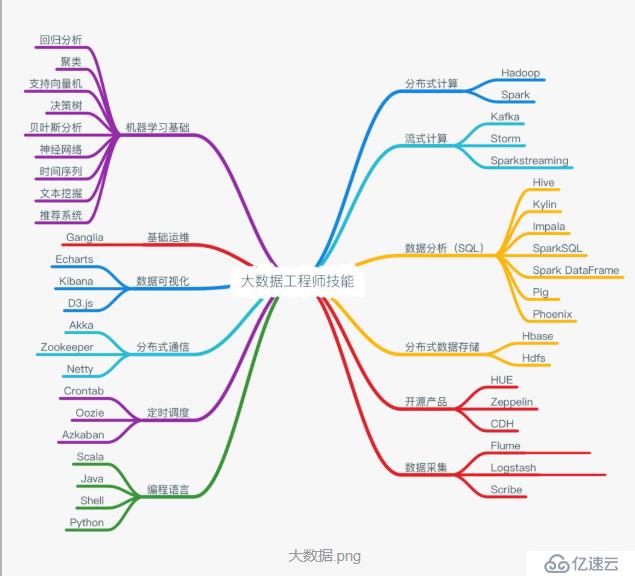
жңҖеҗҺеҶҚеӯҰд№ дёӢжҺЁиҚҗгҖҒеҲҶзұ»зӯүз®—жі•зҡ„еҺҹзҗҶиҝҷж ·дҪ иғҪжӣҙеҘҪзҡ„дёҺз®—жі•е·ҘзЁӢеёҲжү“дәӨйҖҡгҖӮ
иҝҷж ·дҪ зҡ„е…¬еҸёе°ұжӣҙзҰ»дёҚејҖдҪ дәҶпјҢеӨ§е®¶йғҪдјҡеҜ№дҪ е–ңж¬ўзҡ„дёҚиҰҒдёҚиҰҒзҡ„
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ