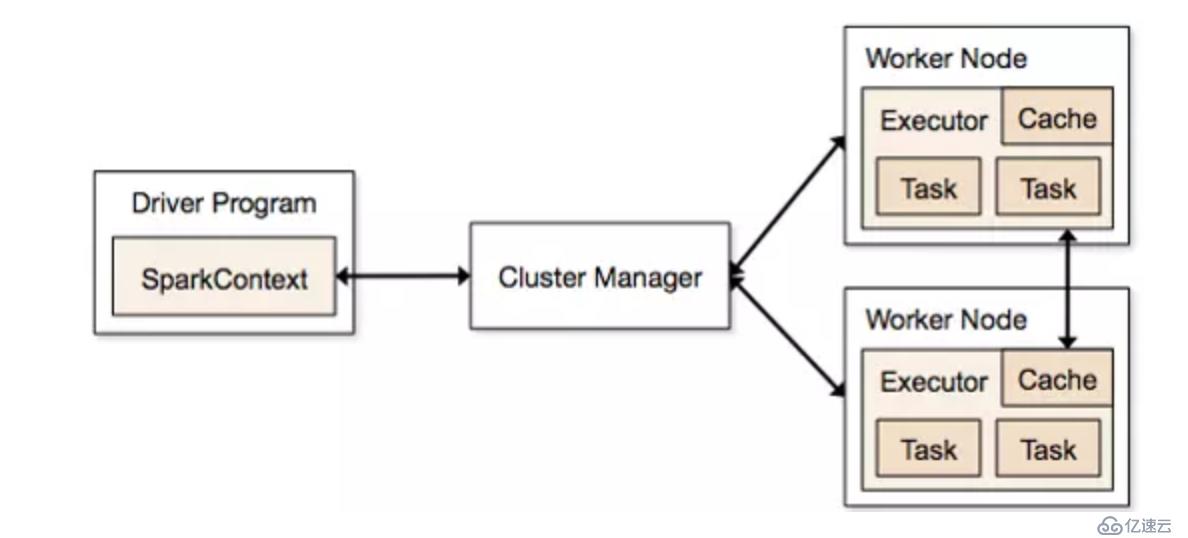
上图是spark框架概要图,spark一些重要概念先简要介绍一下:
- cluster manager:资源管理集群,比如standalone、yarn;
- application:用户编写的应用程序;
- Driver:application中的main函数,创建的SparkContext负责与cluster manager通信,进行资源的申请、任务的分配与监控。一般认为SparkContext就是Driver;
- worker:集群中可以运行任务的节点;
- executor:worker上运行任务的进程,负责执行task;
- task:被executor执行的最小单位,一个stage由多个task组成;
- stage:一个job中的多个阶段,一般只要发生shuffle就会切分一个stage;
- job:一个application至少有一个job,spark只要有一个action就会产生一个job。
spark逻辑执行图的四个概要步骤
- 从数据源创造初始RDD;
- 对RDD进行一系列transformation操作,生成新的RDD[T],其中类型T可以是scala中的基本数据类型,也可以是<k, v>,如果是<k, v>那么k不能是复杂数据结构;
- 对最后的final RDD进行action操作,每个partition产生result;
- 将result回送到Driver端,进行最后的计算。
逻辑执行图的生成
- 如何产生RDD,应该产生哪些RDD
一般每个transformation方法都会返回一个RDD,有些transformation还会有一些子transformation,因此可能产生多于一个的RDD;
- RDD的依赖关系
RDD依赖哪些父RDD比较简单,从代码中可以直观看到;
RDD中有多少个partition呢?这个一般是用户指定,如果未指定的话,会去父RDD中partition数最多的那个;
RDD和父RDD的partitions之间是怎么依赖的呢?
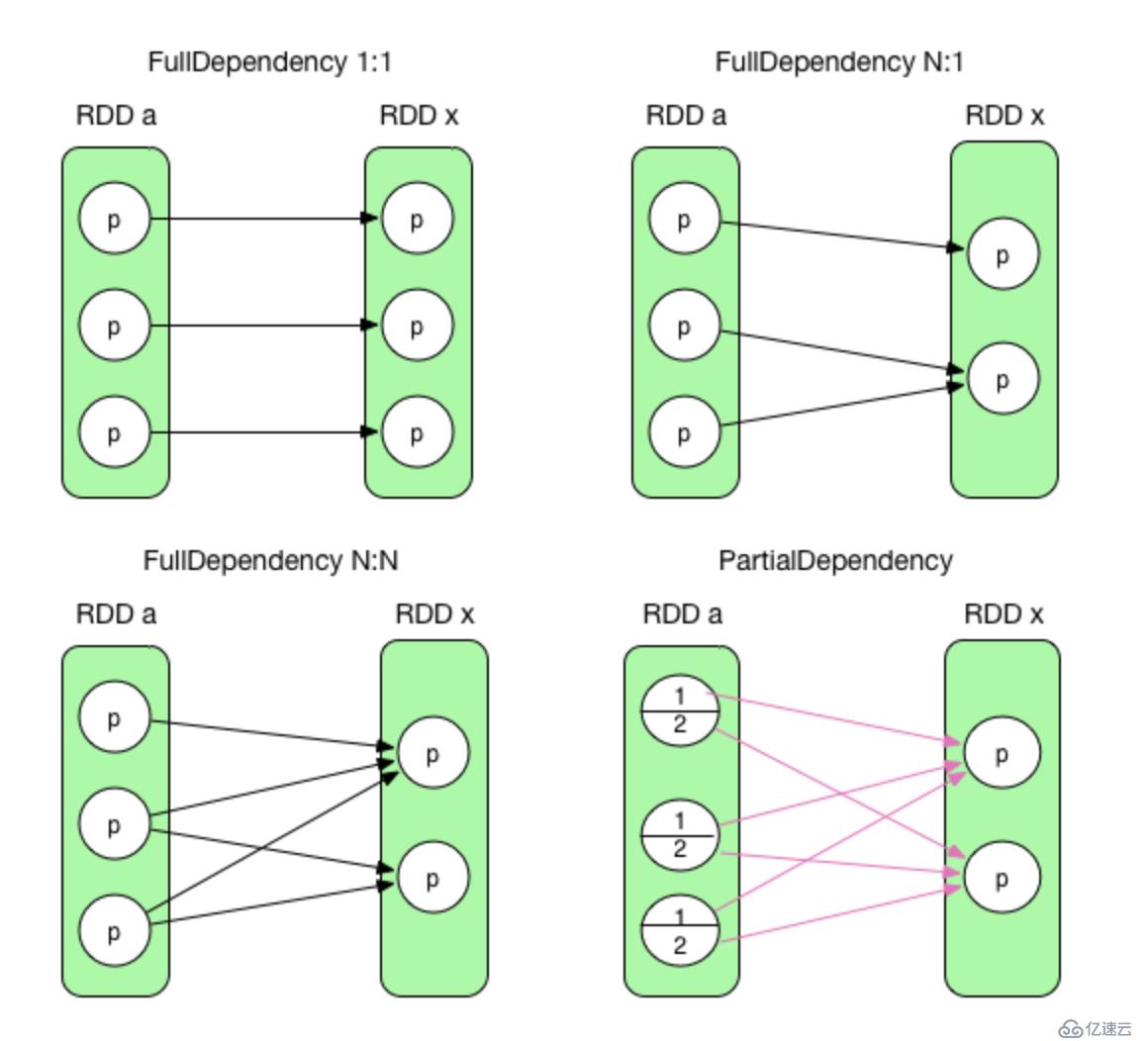
上图前三种是窄依赖,最后一个是宽依赖。窄依赖一般也叫完全依赖,就是说父RDD中partition的全部数据都被子RDD特定的partition依赖;宽依赖一般也叫部分依赖,就是说父RDD中某个partition的一部分数据被子RDD的partition1所依赖,而另一部分数据被子RDD的partition2所依赖,这种情况就要发生shuflle。
一般认为父RDD的所有partition只要不被子RDD的多个partition依赖就属于窄依赖,就不会发生shuffle,但是存在特殊情况就是第三种情况:父RDD的partition被子RDD的多个partition依赖,但依然不需要发生shuffle(一般笛卡尔积是这种情况)。
常用transformation简介
- union:将两个RDD合并,不改变partition里的数据
- groupByKey:将相同key的records聚合在一起,聚合后的每条对应的value为原来所有相同的key的value组成的数组。(默认不会再map端开启conbine)
- reduceByKey:相当于传统的MR,对相同key的value做出一定函数处理,得出最后一个value,比如reduceByKey(+)就会相同的key的value不断相加。
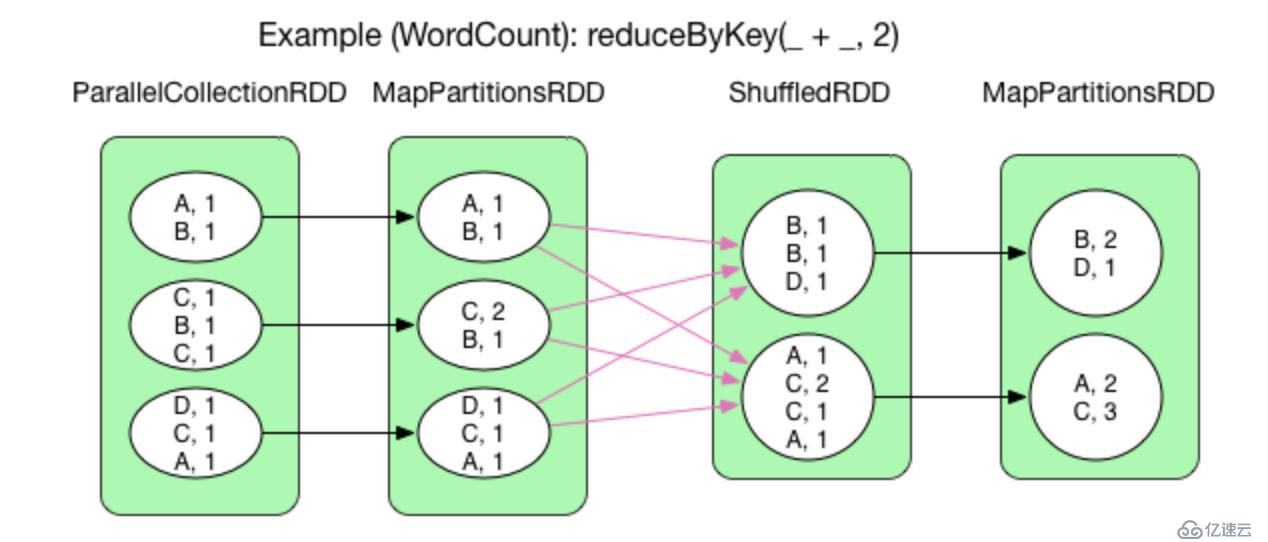
reduceByKey() 默认在 map 端开启 combine(),因此在 shuffle 之前先通过 mapPartitions 操作进行 combine,得到 MapPartitionsRDD,然后 shuffle 得到 ShuffledRDD,然后再进行 reduce(通过 aggregate + mapPartitions() 操作来实现)得到 MapPartitionsRDD。
- distinct:去重,这个transformation内部会先把value转出<k, ->形式的rdd,然后进行依次reduceByKey,最后再还原。
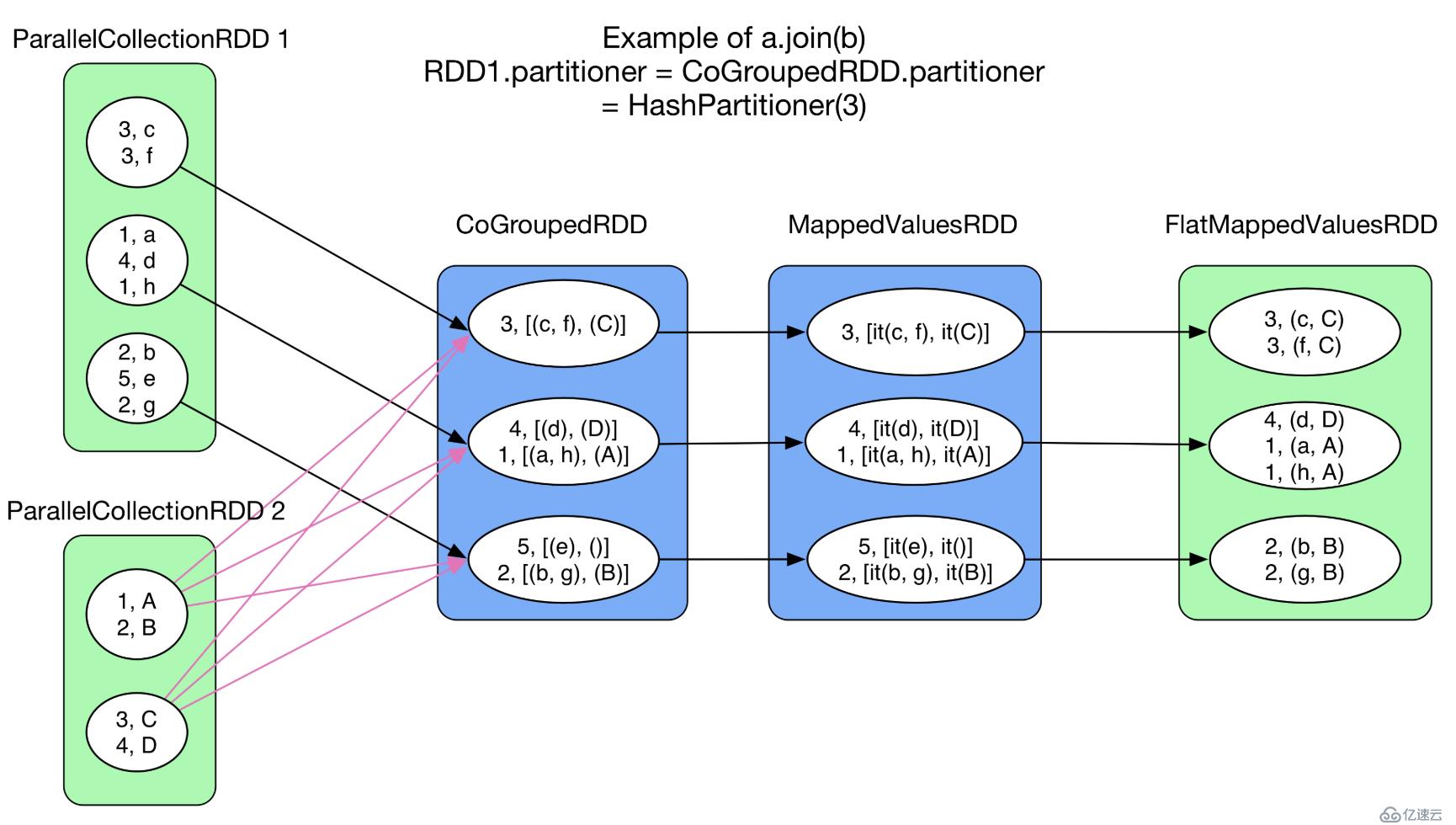
- cogroup(otherRdd, numPartitions):类似groupByKey,不过这个聚合两个或两个以上的RDD,产生的结果也不太一样,是每个RDD自己内部相同的key对应的value先聚合成一个数组,然后两个rdd相同key对应的数组再聚合成一个二维数组,类似于[(a, c), (f)]这样。
- intersection(otherRdd):抽取两个rdd的公共数据,内部会想distinct那样先把value转为<k, ->形式,之后调用cogroup,最后把有相同key的留下并还原。
- join(otherRdd):将两个 RDD[(K, V)] 按照 SQL 中的 join 方式聚合在一起。与 intersection() 类似,首先进行 cogroup(),得到<K, (Iterable[V1], Iterable[V2])>类型的 MappedValuesRDD,然后对 Iterable[V1] 和 Iterable[V2] 做笛卡尔集,并将集合 flat() 化。
- sortByKey:将 RDD[(K, V)] 中的 records 按 key 排序,ascending = true 表示升序,false 表示降序。
- cartesion:
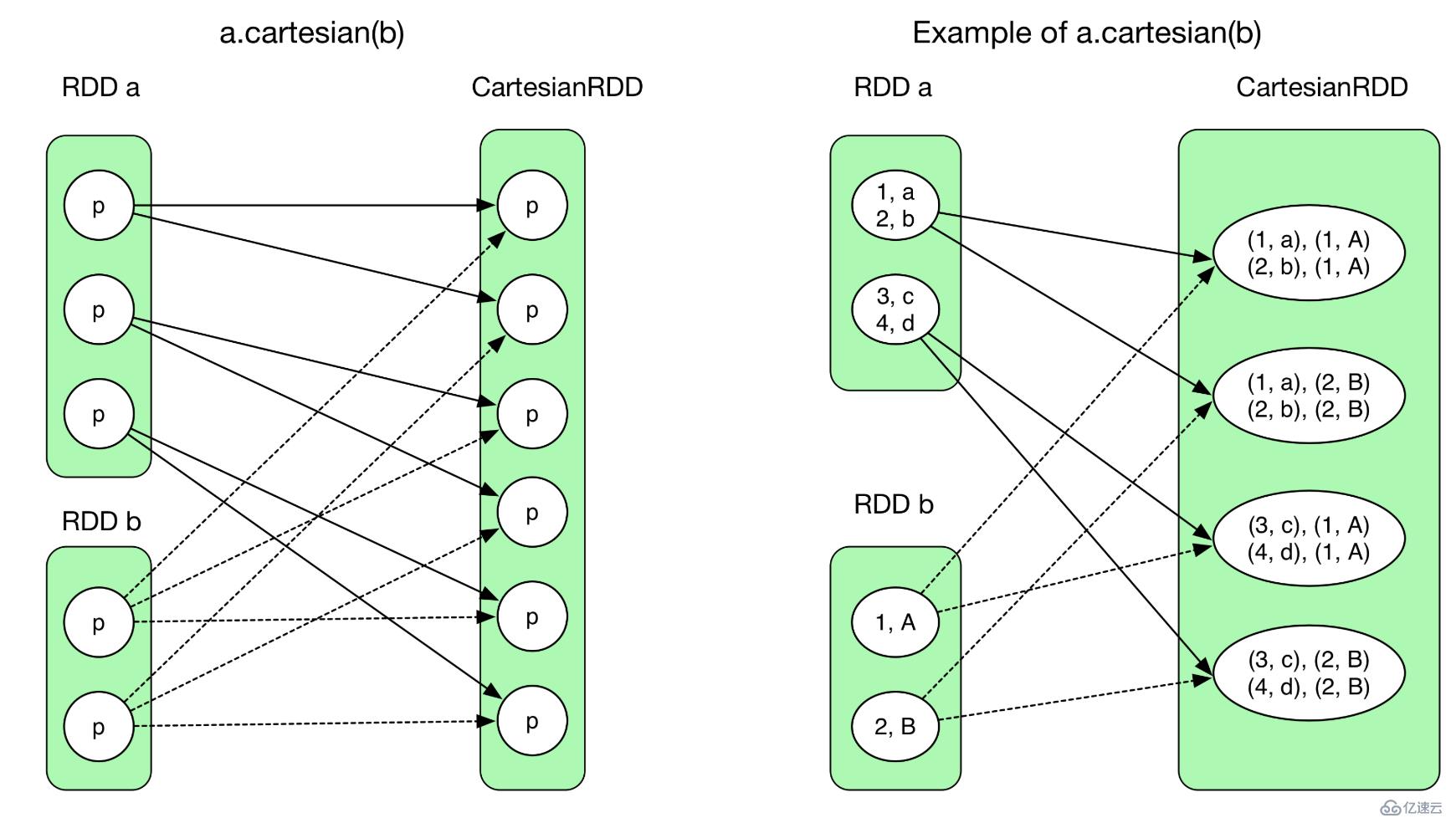
笛卡尔积就是上面提到的父RDD的partition被子RDD的多个partition依赖,但依然不需要发生shuffle的情况。
- coalesce:当 shuffle = false 的时候,是不能增加 partition 个数的
- filterByRange(lower: K, upper: K):以RDD中元素key的范围做过滤,包含lower和upper上下边界
spark常见action操作
- reduce(func):使用传入的函数参数 func 对数据集中的元素进行汇聚操作 (两两合并).
- collect():在 driver program 上将数据集中的元素作为一个数组返回. 这在执行一个 filter 或是其他返回一个足够小的子数据集操作后十分有用.
- count():返回数据集中的元素个数
- first():返回数据集中的第一个元素 (与 take(1) 类似)
- take(n):返回数据集中的前 n 个元素
- takeOrdered(n, [ordering]):以其自然序或使用自定义的比较器返回 RDD 的前 n 元素
- saveAsTextFile(path):数据集中的元素写入到指定目录下的一个或多个文本文件中, 该目录可以存在于本地文件系统, HDFS 或其他 Hadoop 支持的文件系统.
- countByKey():仅适用于 (K, V) 类型的 RDD. 返回每个 key 的 value 数的一个 hashmap (K, int) pair.
- foreach(func):对数据集中的每个元素执行函数 func.