您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
MR编程模型主要分为五个步骤:输入、映射、分组、规约、输出。
输入(InputFormat):
主要包含两个步骤—数据分片、迭代输入
数据分片(getSplits):数据分为多少个splits,就有多少个map task;
单个split的大小,由设置的split.minsize和split.maxsize决定;
公式为 max{minsize, min{maxsize, blocksize}};
hadoop2.7.3之前blocksize默认64M,之后默认128M。
决定了单个split大小之后,就是hosts选择,一个split可能包含多个block(将minsize设置大于128M);
而多个block可能分布在多个hosts节点上(一个block默认3备份,如果4个block就可能在12个节点),getsplits会选择包含数据最多的一部分hosts。
由此可见,为了让数据本地话更合理,最好是一个block一个task,也就是说split大小跟block大小一致。
getSplits会产生两个文件
job.split:存储的主要是每个分片对应的HDFS文件路径,和其在HDFS文件中的起始位置、长度等信息(map task使用,获取分片的具体位置);
job.splitmetainfo:存储的则是每个分片在分片数据文件job.split中的起始位置、分片大小和hosts等信息(主要是作业初始化时使用,用于map task的本地化)。
迭代输入:迭代输入一条条的数据,对于文本数据来说,key就是行号、value当前行文本。
map task总共可以五个过程:read、map、collect、splill、conbine。
Read:从数据源读入一条条数据;
map:将数据传给map函数,变成另外一对KV
collect阶段:
主要是map处理完的数据,先放入内存的环形缓冲区中,待环形缓冲区的值超过一定比例的时候再执行下一步的spill到磁盘;
collect()内部会调用getPartition来进行分区,而环形缓冲区则存储的是K、V和partition号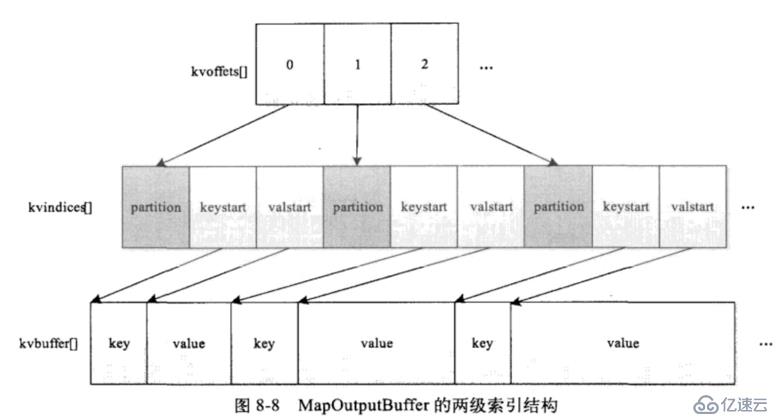
这里采用的两级索引结构,主要是排序时在同一个partition内排序,所以先排partition,再排partition内部数据。
kvindices中记录的分区号、key开始的位置、value开始的位置,也就是一对儿KV在kvindices中占用3个int,kvoffsets只记录一对KV在kvindices中的偏移地址,所以只需要一个int,所以二者按1:3的大小分配内存。
spill过程:
环形缓存区中内存数据在超过一定阈值后会spill到磁盘上,在splill到磁盘上之前会先在内存中进行排序(快速排序);
之后按分区编号分别写到临时文件,同一个分区编号后面会有个数字,表示第几次溢写,conbine:对多个文件合并,多伦递归,没轮合并最小的n个文件。
reduce总共可分为以下几个阶段:shuffle、merge、sort、reduce、write
shuffle:从JobTracker中获取已完成的map task列表以及输出位置,通过http接口获取数据;
merge:shuffle拉去的数据线放入内存,内存不够再放入磁盘,会有一个线程不断地合并内存和磁盘中的数据
sort:reduce从不同的map task中拉取到多个有序文件,然后再做一次归并排序,则每个reduce获取到文件就都是有序的了
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。