жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жңәеҷЁеҲҶеёғ
hadoop1 192.168.56121
hadoop2 192.168.56122
hadoop3 192.168.56123
еҮҶеӨҮе®үиЈ…еҢ…
jdk-7u71-linux-x64.tar.gz
zookeeper-3.4.9.tar.gz
hadoop-2.9.2.tar.gz
жҠҠе®үиЈ…еҢ…дёҠдј еҲ°дёүеҸ°жңәеҷЁзҡ„/usr/localзӣ®еҪ•дёӢ并解еҺӢ
й…ҚзҪ®hosts
echoВ "192.168.56.121В hadoop1"В >>В /etc/hosts echoВ "192.168.56.122В hadoop2"В >>В /etc/hosts echoВ "192.168.56.123В hadoop3"В >>В /etc/hosts
й…ҚзҪ®зҺҜеўғеҸҳйҮҸ
/etc/profile
exportВ HADOOP_PREFIX=/usr/local/hadoop-2.9.2 exportВ JAVA_HOME=/usr/local/jdk1.7.0_71
йғЁзҪІzookeeper
еҲӣе»әzooз”ЁжҲ·
useraddВ zoo passwdВ zoo
дҝ®ж”№zookeeperзӣ®еҪ•зҡ„еұһдё»дёәzoo
chownВ zoo:zooВ -RВ /usr/local/zookeeper-3.4.9
дҝ®ж”№zookeeperй…ҚзҪ®ж–Ү件
еҲ°/usr/local/zookeeper-3.4.9/confзӣ®еҪ•
cpВ zoo_sample.cfgВ zoo.cfg viВ zoo.cfg tickTime=2000 initLimit=10 syncLimit=5 dataDir=/usr/local/zookeeper-3.4.9 clientPort=2181 server.1=hadoop1:2888:3888 server.2=hadoop2:2888:3888 server.3=hadoop3:2888:3888
еҲӣе»әmyidж–Ү件ж”ҫеңЁ/usr/local/zookeeper-3.4.9зӣ®еҪ•дёӢпјҢmyidж–Ү件дёӯеҸӘдҝқеӯҳ1-255зҡ„ж•°еӯ—пјҢдёҺzoo.cfgдёӯserver.idиЎҢдёӯзҡ„idзӣёеҗҢгҖӮ
hadoop1дёӯmyidдёә1
hadoop2дёӯmyidдёә2
hadoop3дёӯmyidдёә3
еңЁдёүеҸ°жңәеҷЁеҗҜеҠЁzookeeperжңҚеҠЎ
[zoo@hadoop1В zookeeper-3.4.9]$В bin/zkServer.shВ start
йӘҢиҜҒzookeeper
[zoo@hadoop1В zookeeper-3.4.9]$В bin/zkServer.shВ status ZooKeeperВ JMXВ enabledВ byВ default UsingВ config:В /usr/local/zookeeper-3.4.9/bin/../conf/zoo.cfg Mode:В follower
й…ҚзҪ®Hadoop
еҲӣе»әз”ЁжҲ·
useraddВ hadoop passwdВ hadoop
дҝ®ж”№hadoopзӣ®еҪ•еұһдё»дёәhadoop
chmodВ hadoop:hadoopВ -RВ /usr/local/hadoop-2.9.2
еҲӣе»әзӣ®еҪ•
mkdirВ /hadoop1В /hadoop2В /hadoop3 chownВ hadoop:hadoopВ /hadoop1 chownВ hadoop:hadoopВ /hadoop2 chownВ hadoop:hadoopВ /hadoop3
й…ҚзҪ®дә’дҝЎ
ssh-keygen ssh-copy-idВ -iВ ~/.ssh/id_rsa.pubВ hadoop@hadoop1 ssh-copy-idВ -iВ ~/.ssh/id_rsa.pubВ hadoop@hadoop2 ssh-copy-idВ -iВ ~/.ssh/id_rsa.pubВ hadoop@hadoop3 #дҪҝз”ЁеҰӮдёӢе‘Ҫд»ӨжөӢиҜ•дә’дҝЎ sshВ hadoop1В date sshВ hadoop2В date sshВ hadoop3В date
й…ҚзҪ®зҺҜеўғеҸҳйҮҸ
/home/hadoop/.bash_profile
exportВ PATH=$JAVA_HOME/bin:$HADOOP_PREFIX/bin:$HADOOP_PREFIX/sbin:$PATH
й…ҚзҪ®еҸӮж•°
etc/hadoop/hadoop-env.shВ
exportВ JAVA_HOME=/usr/local/jdk1.7.0_71
etc/hadoop/core-site.xml
<!--В жҢҮе®ҡhdfsзҡ„nameserviceдёәnsВ --> В <property> В В В В В В <name>fs.defaultFS</name> В В В В В В <value>hdfs://ns</value> В </property> В <!--жҢҮе®ҡhadoopж•°жҚ®дёҙж—¶еӯҳж”ҫзӣ®еҪ•--> В <property> В В В В В В <name>hadoop.tmp.dir</name> В В В В В В <value>/usr/loca/hadoop-2.9.2/temp</value> В </property> В <property> В В В В В В <name>io.file.buffer.size</name> В В В В В В <value>4096</value> В </property> В <!--жҢҮе®ҡzookeeperең°еқҖ--> В <property> В В В В В В <name>ha.zookeeper.quorum</name> В В В В В В <value>hadoop1:2181,hadoop2:2181,hadoop3:2181</value> В </property>
В
etc/hadoop/hdfs-site.xml
<!--жҢҮе®ҡhdfsзҡ„nameserviceдёәnsпјҢйңҖиҰҒе’Ңcore-site.xmlдёӯзҡ„дҝқжҢҒдёҖиҮҙВ --> В В <property> В В В В В В <name>dfs.nameservices</name> В В В В В В <value>ns</value> В В </property> В В <!--В nsдёӢйқўжңүдёӨдёӘNameNodeпјҢеҲҶеҲ«жҳҜnn1пјҢnn2В --> В В <property> В В В В В <name>dfs.ha.namenodes.ns</name> В В В В В <value>nn1,nn2</value> В В </property> В В <!--В nn1зҡ„RPCйҖҡдҝЎең°еқҖВ --> В В <property> В В В В В <name>dfs.namenode.rpc-address.ns.nn1</name> В В В В В <value>hadoop1:9000</value> В В </property> В В <!--В nn1зҡ„httpйҖҡдҝЎең°еқҖВ --> В В <property> В В В В В В <name>dfs.namenode.http-address.ns.nn1</name> В В В В В В <value>hadoop1:50070</value> В В </property> В В <!--В nn2зҡ„RPCйҖҡдҝЎең°еқҖВ --> В В <property> В В В В В В <name>dfs.namenode.rpc-address.ns.nn2</name> В В В В В В <value>hadoop2:9000</value> В В </property> В В <!--В nn2зҡ„httpйҖҡдҝЎең°еқҖВ --> В В <property> В В В В В В <name>dfs.namenode.http-address.ns.nn2</name> В В В В В В <value>hadoop2:50070</value> В В </property> В В <!--В жҢҮе®ҡNameNodeзҡ„е…ғж•°жҚ®еңЁJournalNodeдёҠзҡ„еӯҳж”ҫдҪҚзҪ®В --> В В <property> В В В В В В В <name>dfs.namenode.shared.edits.dir</name> В В В В В В В <value>qjournal://hadoop1:8485;hadoop2:8485;hadoop3:8485/ns</value> В В </property> В В <!--В жҢҮе®ҡJournalNodeеңЁжң¬ең°зЈҒзӣҳеӯҳж”ҫж•°жҚ®зҡ„дҪҚзҪ®В --> В В <property> В В В В В В В В <name>dfs.journalnode.edits.dir</name> В В В В В В В В <value>/hadoop1/hdfs/journal</value> В В </property> В В <!--В ејҖеҗҜNameNodeж•…йҡңж—¶иҮӘеҠЁеҲҮжҚўВ --> В В <property> В В В В В В В В <name>dfs.ha.automatic-failover.enabled</name> В В В В В В В В <value>true</value> В В </property> В В <!--В й…ҚзҪ®еӨұиҙҘиҮӘеҠЁеҲҮжҚўе®һзҺ°ж–№ејҸВ --> В В <property> В В В В В В В В В В <name>dfs.client.failover.proxy.provider.ns</name> В В В В В В В В В В <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> В В </property> В В <!--В й…ҚзҪ®йҡ”зҰ»жңәеҲ¶пјҢеҰӮжһңsshжҳҜй»ҳи®Ө22з«ҜеҸЈпјҢvalueзӣҙжҺҘеҶҷsshfenceеҚіеҸҜВ --> В В <property> В В В В В В В В В В В <name>dfs.ha.fencing.methods</name> В В В В В В В В В В В <value>sshfence</value> В В </property> В В <!--В дҪҝз”Ёйҡ”зҰ»жңәеҲ¶ж—¶йңҖиҰҒsshе…Қзҷ»йҷҶВ --> В В <property> В В В В В В В В В В <name>dfs.ha.fencing.ssh.private-key-files</name> В В В В В В В В В В <value>/home/hadoop/.ssh/id_rsa</value> В В </property> В В <property> В В В В В В <name>dfs.namenode.name.dir</name> В В В В В В <value>file:/hadoop1/hdfs/name,file:/hadoop2/hdfs/name</value> В В </property> В В <property> В В В В В В <name>dfs.datanode.data.dir</name> В В В В В В <value>file:/hadoop1/hdfs/data,file:/hadoop2/hdfs/data,file:/hadoop3/hdfs/data</value> В В </property> В В <property> В В В В В <name>dfs.replication</name> В В В В В <value>2</value> В В </property> В В <!--В еңЁNNе’ҢDNдёҠејҖеҗҜWebHDFSВ (RESTВ API)еҠҹиғҪ,дёҚжҳҜеҝ…йЎ»В --> В В <property> В В В В В <name>dfs.webhdfs.enabled</name> В В В В В <value>true</value> В В </property> В В <property> В В <!--В ListВ ofВ permitted/excludedВ DataNodes.В В --> <name>dfs.hosts.exclude</name> <value>/usr/local/hadoop-2.9.2/etc/hadoop/excludes</value> </property>
etc/hadoop/mapred-site.xml
<property> В В В В В В <name>mapreduce.framework.name</name> В В В В В В <value>yarn</value> В В </property> yarn-site.xml В В <!--В жҢҮе®ҡnodemanagerеҗҜеҠЁж—¶еҠ иҪҪserverзҡ„ж–№ејҸдёәshuffleВ serverВ --> В В <property> В В В В В В В В В В <name>yarn.nodemanager.aux-services</name> В В В В В В В В В В <value>mapreduce_shuffle</value> В В В </property> В В В <property> В В В В В В В В В В <name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name> В В В В В В В В В В <value>org.apache.hadoop.mapred.ShuffleHandler</value> В В В </property> В В В <!--В жҢҮе®ҡresourcemanagerең°еқҖВ --> В В В <property> В В В В В В В В В В <name>yarn.resourcemanager.hostname</name> В В В В В В В В В В <value>hadoop1</value> В В В В </property>
etc/hadoop/slaves
hadoop1 hadoop2 hadoop3
йҰ–ж¬ЎеҗҜеҠЁе‘Ҫд»Ө
1гҖҒйҰ–е…ҲеҗҜеҠЁеҗ„дёӘиҠӮзӮ№зҡ„ZookeeperпјҢеңЁеҗ„дёӘиҠӮзӮ№дёҠжү§иЎҢд»ҘдёӢе‘Ҫд»Өпјҡ bin/zkServer.shВ start 2гҖҒеңЁжҹҗдёҖдёӘnamenodeиҠӮзӮ№жү§иЎҢеҰӮдёӢе‘Ҫд»ӨпјҢеҲӣе»әе‘ҪеҗҚз©әй—ҙ hdfsВ zkfcВ -formatZK 3гҖҒеңЁжҜҸдёӘjournalnodeиҠӮзӮ№з”ЁеҰӮдёӢе‘Ҫд»ӨеҗҜеҠЁjournalnode sbin/hadoop-daemon.shВ startВ journalnode 4гҖҒеңЁдё»namenodeиҠӮзӮ№ж јејҸеҢ–namenodeе’Ңjournalnodeзӣ®еҪ• hdfsВ namenodeВ -formatВ ns 5гҖҒеңЁдё»namenodeиҠӮзӮ№еҗҜеҠЁnamenodeиҝӣзЁӢ sbin/hadoop-daemon.shВ startВ namenode 6гҖҒеңЁеӨҮnamenodeиҠӮзӮ№жү§иЎҢ第дёҖиЎҢе‘Ҫд»ӨпјҢиҝҷдёӘжҳҜжҠҠеӨҮnamenodeиҠӮзӮ№зҡ„зӣ®еҪ•ж јејҸеҢ–并жҠҠе…ғж•°жҚ®д»Һдё»namenodeиҠӮзӮ№copyиҝҮжқҘпјҢ并且иҝҷдёӘе‘Ҫд»ӨдёҚдјҡжҠҠjournalnodeзӣ®еҪ•еҶҚж јејҸеҢ–дәҶпјҒ然еҗҺ用第дәҢдёӘе‘Ҫд»ӨеҗҜеҠЁеӨҮnamenodeиҝӣзЁӢпјҒ hdfsВ namenodeВ -bootstrapStandby sbin/hadoop-daemon.shВ startВ namenode 7гҖҒеңЁдёӨдёӘnamenodeиҠӮзӮ№йғҪжү§иЎҢд»ҘдёӢе‘Ҫд»Ө sbin/hadoop-daemon.shВ startВ zkfc 8гҖҒеңЁжүҖжңүdatanodeиҠӮзӮ№йғҪжү§иЎҢд»ҘдёӢе‘Ҫд»ӨеҗҜеҠЁdatanode sbin/hadoop-daemon.shВ startВ datanode
ж—ҘеёёеҗҜеҒңе‘Ҫд»Ө
#еҗҜеҠЁи„ҡжң¬пјҢеҗҜеҠЁжүҖжңүиҠӮзӮ№жңҚеҠЎ sbin/start-dfs.sh #еҒңжӯўи„ҡжң¬пјҢеҒңжӯўжүҖжңүиҠӮзӮ№жңҚеҠЎ sbin/stop-dfs.shйӘҢиҜҒ
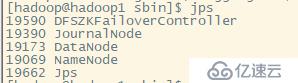
jpsжЈҖжҹҘиҝӣзЁӢ
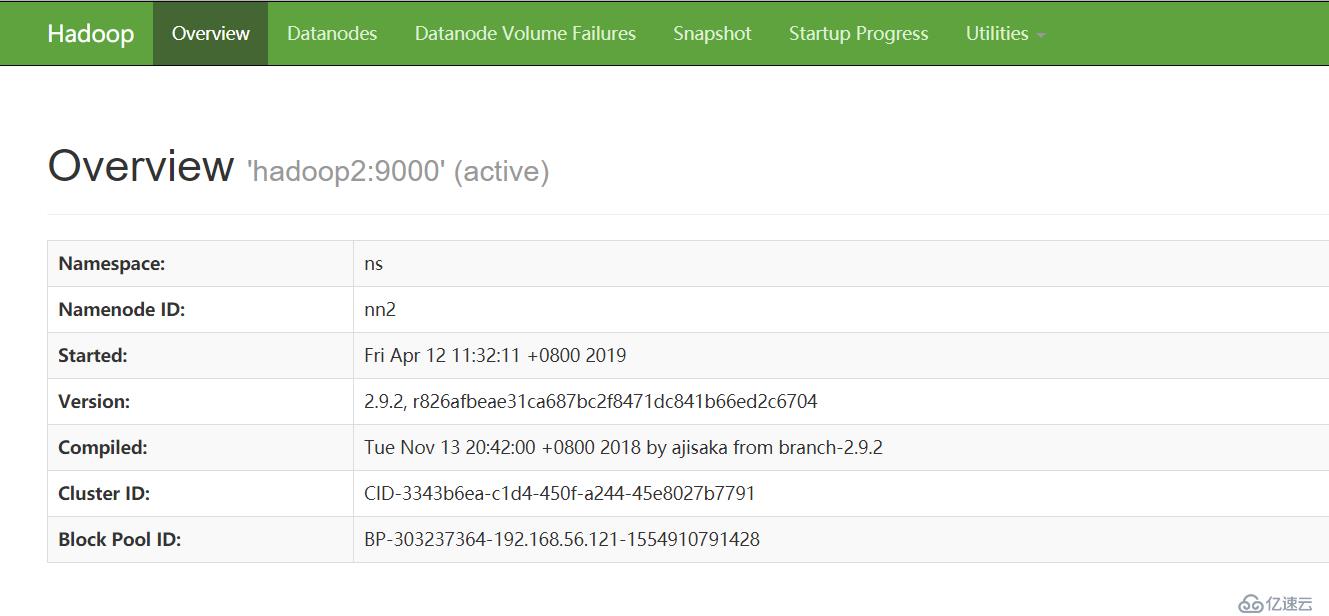
http://192.168.56.122:50070
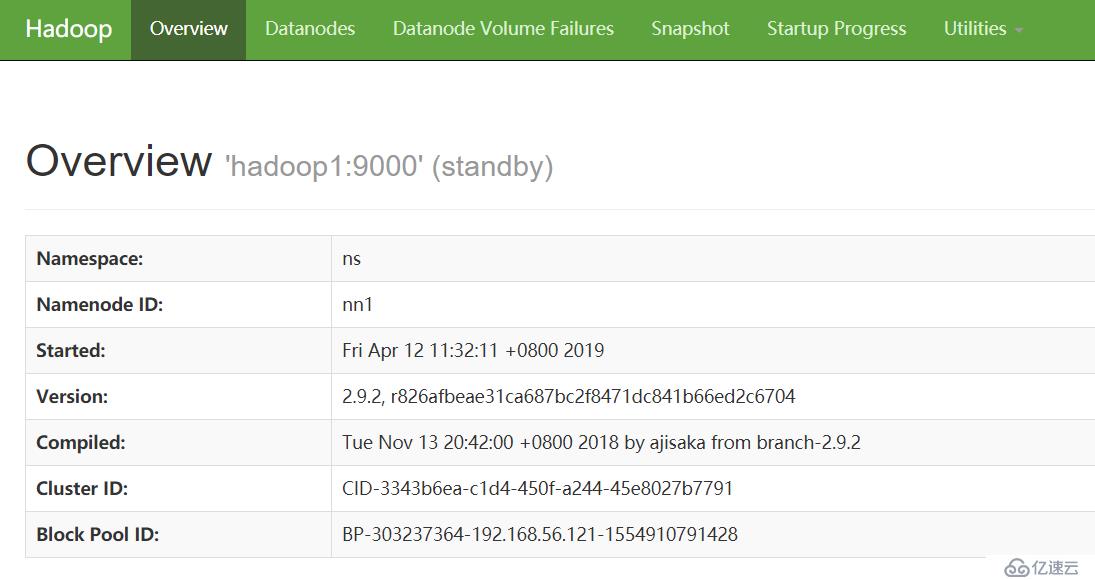
http://192.168.56.121:50070
жөӢиҜ•ж–Ү件дёҠдј дёӢиҪҪ
#еҲӣе»әзӣ®еҪ• [hadoop@hadoop1В ~]$В hadoopВ fsВ -mkdirВ /test #йӘҢиҜҒ [hadoop@hadoop1В ~]$В hadoopВ fsВ -lsВ / FoundВ 1В items drwxr-xr-xВ В В -В hadoopВ supergroupВ В В В В В В В В В 0В 2019-04-12В 12:16В /testВ В В В #дёҠдј ж–Ү件 [hadoop@hadoop1В ~]$В hadoopВ fsВ -putВ /usr/local/hadoop-2.9.2/LICENSE.txtВ /test #йӘҢиҜҒ [hadoop@hadoop1В ~]$В hadoopВ fsВ -lsВ /testВ В В В В В В В В В В В В В В В В В В В В В В В В В В В В В В В В В В В В FoundВ 1В items -rw-r--r--В В В 2В hadoopВ supergroupВ В В В В 106210В 2019-04-12В 12:17В /test/LICENSE.txt #дёӢиҪҪж–Ү件еҲ°/tmp [hadoop@hadoop1В ~]$В hadoopВ fsВ -getВ /test/LICENSE.txtВ /tmp #йӘҢиҜҒ [hadoop@hadoop1В ~]$В lsВ -lВ /tmp/LICENSE.txtВ -rw-r--r--.В 1В hadoopВ hadoopВ 106210В AprВ 12В 12:19В /tmp/LICENSE.txt
еҸӮиҖғпјҡhttps://blog.csdn.net/Trigl/article/details/55101826
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ