您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
esproc
| A | |
| 1 | =now() |
| 2 | =file("C:\\Users\\Sean\\Desktop\\esproc_vs_python\\EMPLOYEE.txt") |
| 3 | =A2.import@t() |
| 4 | >A3.insert(2,100:EID,"wang":NAME,"lao":SURNAME,"Femal":GENDER,"CA":STATE,date("1999-1-1"):BIRTHDAY,date("2009-3-4"):HIREDATE,"HR":DEPT,3000:SALARY) |
| 5 | =interval@ms(A1,now()) |
A4:添加一条记录(“:”前表示字段值,“:”后表示字段),其中2表示第二条记录的位置
A5:计算运算时间(interval():计算时间间隔。@ms表示以毫秒为单位)
python:
import time
import pandas as pd
import datetime
import numpy as np
import random
s=time.time()
data = pd.read_csv("C:/Users/Sean/Desktop/esproc_vs_python/EMPLOYEE.txt",sep="\t")
values=[100,"wang","lao","Femal","CA","1999-01-01","2009-03-04","HR",3000]
line_dic={}
for i in range(len(data.columns)):
line_dic[data.columns[i]]=values[i]
line = pd.DataFrame(line_dic,index=[1])
data = pd.concat([data.loc[:0],line,data.loc[1:]],ignore_index=True)
print(data)
e=time.time()
print(e-s)
用pd.concat([df1,df2,…,dfn))达到新增记录的目的,dataframe结构的记录是从0开始计数的,如df.loc[1:]表示切片取出第二条以后的所有记录
最后计算出运算耗时。
结果:
esproc

python

| 耗时 | |
| esproc | 0.004 |
| python | 0.039 |
esproc
| A | |
| 1 | =now() |
| 2 | =file("C:\\Users\\Sean\\Desktop\\esproc_vs_python\\EMPLOYEE.txt") |
| 3 | =A2.import@t() |
| 4 | >A3.delete(2) |
| 5 | =interval@ms(A1,now()) |
A4:删除第2条记录
python:
import time
import pandas as pd
import datetime
import numpy as np
import random
s=time.time()
data = pd.read_csv("C:/Users/Sean/Desktop/esproc_vs_python/EMPLOYEE.txt",sep="\t")
data = data.drop(1)
print(data)
e=time.time()
print(e-s)
利用df.drop()函数删除某条记录
结果:
esproc

python

| 耗时 | |
| esproc | 0.003 |
| python | 0.034 |
esproc
| A | |
| 1 | =now() |
| 2 | =file("C:\\Users\\Sean\\Desktop\\esproc_vs_python\\EMPLOYEE.txt") |
| 3 | =A2.import@t() |
| 4 | >A3.modify(5,"aaa":NAME,1000:SALARY) |
| 5 | =interval@ms(A1,now()) |
A4:修改第5条记录中的NAME字段的值为“aaa”,修改SALARY字段的值为1000
python:
import time
import pandas as pd
import datetime
import numpy as np
import random
s=time.time()
data = pd.read_csv("C:/Users/Sean/Desktop/esproc_vs_python/EMPLOYEE.txt",sep="\t")
data.loc[4,['NAME','SALARY']]=['aaa',1000]
print(data)
e=time.time()
print(e-s)
利用df.loc[]切片取出第5条记录的NAME,SALARY字段并赋值为‘aaa’和1000
结果:
esproc

python

| 耗时 | |
| esproc | 0.003 |
| python | 0.037 |
esproc
| A | |
| 1 | =now() |
| 2 | =file("C:\\Users\\Sean\\Desktop\\esproc_vs_python\\EMPLOYEE.txt") |
| 3 | =A2.import@t() |
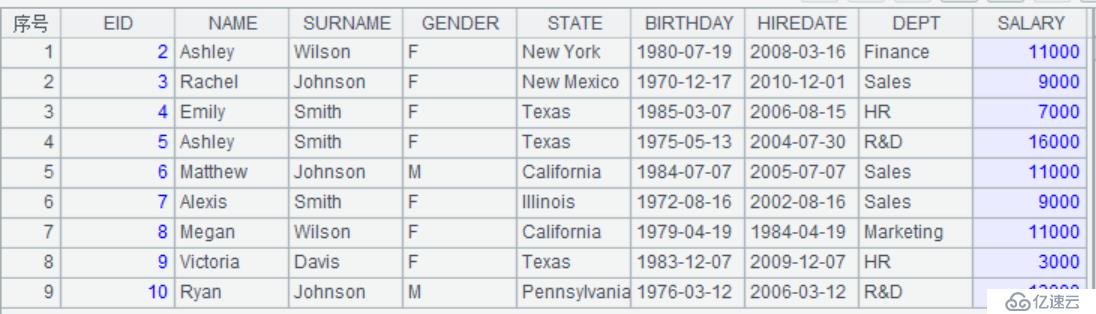
| 4 | =A3(to(2,10)) |
| 5 | =interval@ms(A1,now()) |
A4:to(m,n):产生m~n的序列,我们用T表示序表,A表示序列。T(A)表示取出序列中包含值的记录,这里表示取出第2~10条记录
python:
import time
import pandas as pd
import datetime
import numpy as np
import random
s=time.time()
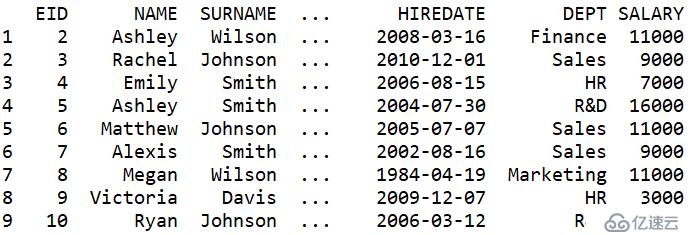
data = pd.read_csv("C:/Users/Sean/Desktop/esproc_vs_python/EMPLOYEE.txt",sep="\t")
data = data.loc[1:9]
print(data)
e=time.time()
print(e-s)
利用df.loc[]切片取出第2~10条记录
结果:
esproc
python
| 耗时 | |
| esproc | 0.003 |
| python | 0.023 |
esproc
| A | |
| 1 | =now() |
| 2 | =file("C:\\Users\\Sean\\Desktop\\esproc_vs_python\\EMPLOYEE.txt") |
| 3 | =A2.import@t() |
| 4 | =A3.derive(NAME+""+SURNAME:Fullname) |
| 5 | =interval@ms(A1,now()) |
A4:derive()增加字段,这里表示用原来的NAME和SURNAME连接生成Fullname字段。
python:
import time
import pandas as pd
import datetime
import numpy as np
import random
s=time.time()
data = pd.read_csv("C:/Users/Sean/Desktop/esproc_vs_python/EMPLOYEE.txt",sep="\t")
data['Fullname'] = data['NAME']+data['SURNAME']
print(data)
e=time.time()
print(e-s)
取出NAME和SURNAME合并成Fullname
结果:
esproc

python

| 耗时 | |
| esproc | 0.004 |
| python | 0.037 |
esproc
| A | |
| 1 | =now() |
| 2 | =file("C:\\Users\\Sean\\Desktop\\esproc_vs_python\\EMPLOYEE.txt") |
| 3 | =A2.import@t() |
| 4 | =A3.new(NAME,SURNAME,STATE,GENDER) |
| 5 | =interval@ms(A1,now()) |
A4:T.new()生成新的序表。这里表示生成包含A3序表中NAME,SURNAME,STATE,GENDER这几个字段的新序表。
python:
import time
import pandas as pd
import datetime
import numpy as np
import random
s=time.time()
data = pd.read_csv("C:/Users/Sean/Desktop/esproc_vs_python/EMPLOYEE.txt",sep="\t")
data = data[['NAME','SURNAME','STATE','GENDER']]
print(data)
e=time.time()
print(e-s)
取出NAME,SURNAME,STATE,GENDER这几个字段复制给新的dataframe。
结果:
esproc

python

| 耗时 | |
| esproc | 0.002 |
| python | 0.022 |
esproc
| A | |
| 1 | =now() |
| 2 | =file("C:\\Users\\Sean\\Desktop\\esproc_vs_python\\EMPLOYEE.txt") |
| 3 | =A2.import@t() |
| 4 | =A3.rename(EID:ID) |
| 5 | =interval@ms(A1,now()) |
A4:rename()修改字段名。这里表示将EID修改为ID
python:
import time
import pandas as pd
import datetime
import numpy as np
import random
s=time.time()
data = pd.read_csv("C:/Users/Sean/Desktop/esproc_vs_python/EMPLOYEE.txt",sep="\t")
data.rename(columns={'EID':'ID'},inplace=True)
print(data)
e=time.time()
print(e-s)
利用df.rename()函数修改字段名,将EID修改为ID。参数inplace控制是否修改原来的dataframe结构。
结果:
esproc

python

| 耗时 | |
| esproc | 0.002 |
| python | 0.030 |
小结:我们通过对记录和字段的增、删、改、查这些基本的运算,用esproc和python按照相同的思路,对相同的数据进行同样的处理,在描述效率方面,两者相差并不大,都很方便而且容易上手。
EMPLOYEE.txt
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。