您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这一节我们对 SQL 和集算器 SPL 在序列值查找、分栏、动态行、动态列、指定序排序等方面进行了对比。
1、 列出中文人口和英文人口均达到 1% 的国家代码
MySQL8:
select countrycode from world.countrylanguage
where language in ('Chinese', 'English') and percentage>=1
group by countrycode
having count(*)>=2;
集算器SPL:
| A | |
| 1 | =connect("mysql") |
| 2 | =A1.query@x("select * from world.countrylanguage where percentage>=1") |
| 3 | =A2.group(CountryCode) |
| 4 | =A3.select(~.(Language).contain("Chinese","English")) |
| 5 | =A4.(CountryCode) |
A4: 选取语言包含 Chinese 和 English 的组
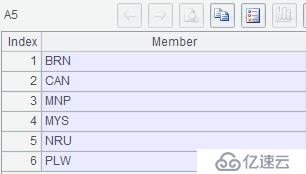
2、 从数据结构为 (id,v) 的表中,按 id 升序查找连续记录的 v 值分别为 23、7、11 时下一个记录的 v 值
MySQL8:
with t(id,v) as (select 1,3 union all select 2,15
union all select 3,23 union all select 4,7
union all select 5,11 union all select 6,19
union all select 7,23 union all select 8,7
union all select 9,6),
s(v) as (select '23,7,11'),
t1(v) as (select group_concat(v order by id) from t),
t2(p1,p2,p3,next) as (
select @p1:=locate(s.v,t1.v), @p2:=if(@p1>0,@p1+char_length(s.v)+1,null),
@p3:=locate(',',t1.v,@p2),@s:=substr(t1.v,@p2,@p3-@p2)
from s,t1)
select next from t2;
说明:利用串操作求下一个值,t中id为序号,v为值,s中v为待查的值串。
集算器SPL:
| A | |
| 1 | =connect("mysql") |
| 2 | =A1.query@x("with t(id,v) as (select 1,3 union all select 2,15 union all select 3,23 union all select 4,7 union all select 5,11 union all select 6,19 union all select 7,23 union all select 8,7 union all select 9,6) select * from t order by id") |
| 3 | [23,7,11] |
| 4 | =A2.(v) |
| 5 | =A4.pos@c(A3) |
| 6 | =if(A5>0,A4.m(A5+A3.len())) |
A3: 待查值的序列
A5: 在A4中查找与A3成员连续相同的起始位置
3、 在数据结构为 (id,used) 的表中,id 值连续,used 为 0 表示未用,为 1 时表示已用,请列出所有未用区间的起始和结束 id
MySQL:
with t(id,used) as (select 1,1 union all select 2,1
union all select 3,0 union all select 4,1
union all select 5,0 union all select 6,0
union all select 7,1 union all select 8,1
union all select 9,0 union all select 10,0
union all select 10,0 union all select 11,0),
first as (select a.id
from t a left join t b on a.id=b.id+1
where a.used=0 and (b.id is null or b.used=1)),
t2 as (select first.id firstUnused, min(c.id) minUsed, max(d.id) maxUnused
from first
left join t c on first.id<c.id and c.used=1
left join t d on first.id<d.id and d.used=0
group by firstUnused)
select firstUnused, if(minUsed is null, ifnull(maxUnused,firstUnused), minUsed-1) lastUnused
from t2;
说明:此SQL没有采用《SQL难点解决:直观分组》中用窗口函数将相邻的同值分到同组的思路,而是仅使用了普通的join和left join,first求所有未用区间的起始id列表,t2求每个起始id对应的比它大的最小已用id和比它大的最大未用id,请读者仔细体会。
集算器SPL:
| A | |
| 1 | =connect("mysql") |
| 2 | =A1.query@x("with t(id,used) as (select 1,1 union all select 2,1 union all select 3,0 union all select 4,1 union all select 5,0 union all select 6,0 union all select 7,1 union all select 8,1 union all select 9,0 union all select 10,0 union all select 10,0 union all select 11,0) select * from t order by id") |
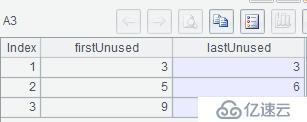
| 3 | =create(firstUnused,lastUnused) |
| 4 | >A2.run(if(used==0&&used!=used[-1],a=id), if(used==0&&used!=used[1],A3.insert(0,a,id))) |
A3:当 used 为 0 且和上一行 used 不等时当前行 id 即为起始 id,当 used 为 0 且和下一行 used 不等时则当前行 id 即为结束 id,并向 A3 中的插入
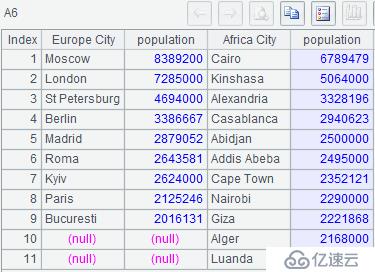
4、 分栏列出欧洲和非洲人口超 200 万的城市名称及人口(每栏按从多到少排序)
MySQL:
with t as (select t1.name,t1.population,t2.continent,
rank()over(partition by t2.continent order by t1.population desc) rk
from world.city t1 join world.country t2 on t1.countrycode=t2.code
where t2.continent in ('Europe','Africa') and t1.population>=2000000
),
m(rk) as (select distinct rk from t)
select t1.name `Europe City`, t1.Population, t2.name `Africa City`, t2.Population
from m
left join (select * from t where continent='Europe') t1 using(rk)
left join (select * from t where continent='Africa') t2 using (rk);
集算器SPL:
| A | |
| 1 | =connect("mysql") |
| 2 | =A1.query@x("select t1.name,t1.population,t2.continent from world.city t1 join world.country t2 on t1.countrycode=t2.code where t2.continent in ('Europe','Africa') and t1.population>=2000000 order by t1.population desc") |
| 3 | =A2.select(continent:"Europe") |
| 4 | =A2.select(continent:"Africa") |
| 5 | =create('Europe City',population,'Africa City', population) |
| 6 | =A5.paste(A3.(name),A3.(population),A4.(name),A4.(population)) |
A6:将值序列直接粘贴到对应列
5、 现有数据结构为 (Student,Math,Chinese,English,Physics, Chemistry,Information) 的成绩表,请列出 Maliang 低于 90 分的学科对应的所有学生的成绩
MySQL:
create temporary table
scores(Student varchar(20),Math int,Chinese int,English int,
Physics int,Chemistry int,Information int);
insert into scores
select 'Lili', 93,99,100,88,92,95
union all select 'Sunqiang', 100,99,97,100,85,96
union all select 'Zhangjun', 95,92,94,90,93,91
union all select 'Maliang', 97,89,92,99,98,88;
select @m:=concat(if(Math<90, 'Math,', ''),
if(Chinese<90, 'Chinese,', ''),
if(English<90, 'English,', ''),
if(Physics<90, 'Physics,', ''),
if(Chemistry<90, 'Chemistry,', ''),
if(Information<90, 'Information,', ''))
from scores
where student='Maliang';
set @s:=left(@m, length(@m)-1);
set @sql:=concat('select Student,', @s, 'from scores');
prepare stmt from @sql;
execute stmt;
deallocate prepare stmt;
drop table scores;
集算器SPL:
| A | |
| 1 | =connect("mysql") |
| 2 | =A1.query@x("with t(Student,Math,Chinese,English,Physics, Chemistry,Information) as (select 'Lili', 93,99,100,88,92,95 union all select'Sunqiang', 100,99,97,100,85,96 union all select'Zhangjun', 95,92,94,90,93,91 union all select'Maliang', 97,89,92,99,98,88) select * from t") |
| 3 | =A2.select@1(Student:"Maliang") |
| 4 | =A3.array().pselect@a(#>1&&~<90) |
| 5 | =A2.fname()(A4).concat@c() |
| 6 | =A2.new(Student,${A5}) |
A4:将记录转成数组,并查找低于90分的学科所在列号
A5:从A2中取出相应位置的列名,并且逗号分隔连在一起
A6:根据A2构造学生和选出的列的新序表


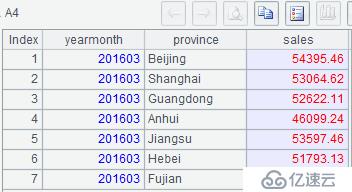
6、 列出 2016 年 3 月各省市销售额,要求 Beijing、Shanghai、Guangdong 依次列在最前
MySQL:
select *
from detail
where yearmonth=201603
order by case when province='Beijing' then 1
when province='Shanghai' then 2
when province='Guangdong' then 3 else 4 end;
集算器SPL:
| A | |
| 1 | =connect("mysql") |
| 2 | =A1.query@x("select * from detail where yearmonth=201603") |
| 3 | =["Beijing","Shanghai","Guangdong"] |
| 4 | =A2.align@s(A3,province) |
A4: 将A2中记录的province按A3对齐,多余的按原序排在后面
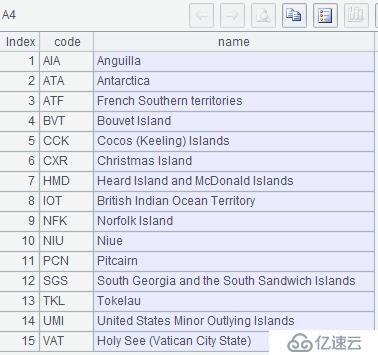
7、 列出不存在人口超过 1000 的城市的国家
MySQL:
select t1.code,t1.name
from world.country t1
left join (select * from world.city where population>=1000) t2
on t1.code=t2.countrycode
where t2.countrycode is null;
集算器SPL:
| A | |
| 1 | =connect("mysql") |
| 2 | =A1.query("select code,name from world.country") |
| 3 | =A1.query@xi("select distinct countrycode from world.city where population>=1000") |
| 4 | =A2.switch@d(code,A3:countrycode) |
A4:选取A2中code不在A3里的记录
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。