жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
hdfs namenode HAй«ҳеҸҜз”Ёж–№жЎҲ
1гҖҒhadoop-ha йӣҶзҫӨиҝҗдҪңжңәеҲ¶д»Ӣз»Қ
жүҖи°“HAпјҢеҚій«ҳеҸҜз”ЁпјҲ7*24 е°Ҹж—¶дёҚдёӯж–ӯжңҚеҠЎпјү //hadoop 2.x еҶ…зҪ®дәҶ HA ж–№жЎҲ
е®һзҺ°й«ҳеҸҜз”ЁжңҖе…ій”®зҡ„жҳҜж¶ҲйҷӨеҚ•зӮ№ж•…йҡң
hadoop-ha дёҘж јжқҘиҜҙеә”иҜҘеҲҶжҲҗеҗ„дёӘ组件зҡ„HA жңәеҲ¶
жҸҗзӨәпјҡ
еңЁд№ӢеүҚжІЎжңүHAжңәеҲ¶зҡ„ж—¶еҖҷпјҢsecondary namenode е’Ңstanday namenode жңүеҫҲеӨ§зҡ„еҢәеҲ«
secondary namenode дёҚеҸҜд»Ҙжӣҝд»ЈnamenodeпјӣиҖҢstanday namenode еҸҜд»Ҙе®Ңе…Ёзҡ„жӣҝд»Јnamenode
HAжҠҖжңҜиҰҒзӮ№ пјҡе…ғж•°жҚ®з®ЎзҗҶ 2дёӘnamenodeзҡ„зҠ¶жҖҒз®ЎзҗҶ еҰӮдҪ•йҳІжӯўи„‘иЈӮ
HDFS зҡ„HA жңәеҲ¶
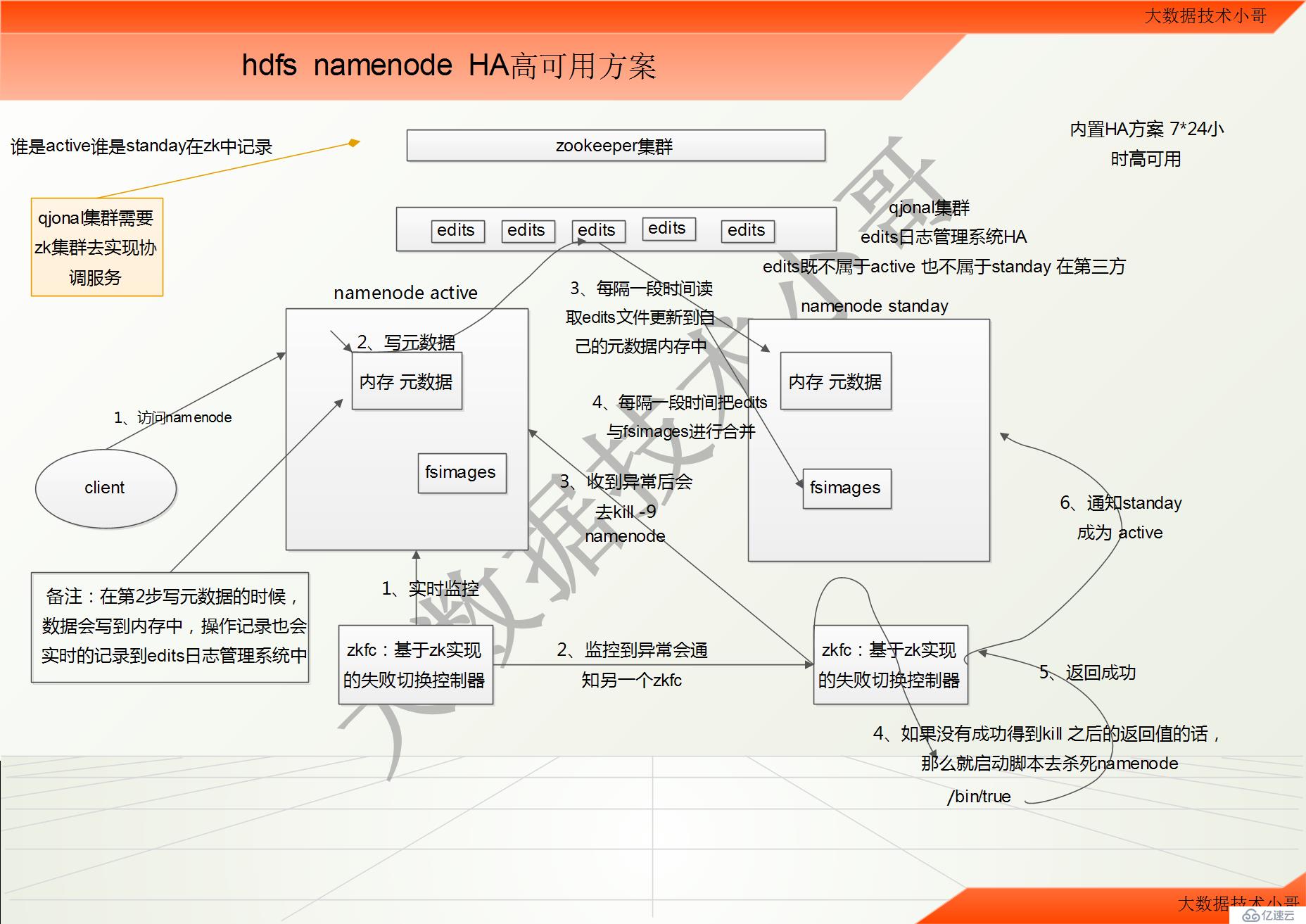
йҖҡиҝҮеҸҢnamenode ж¶ҲйҷӨеҚ•зӮ№ж•…йҡң
еҸҢnamenode еҚҸи°ғе·ҘдҪңзҡ„иҰҒзӮ№пјҡ
AгҖҒе…ғж•°жҚ®з®ЎзҗҶж–№ејҸйңҖиҰҒж”№еҸҳпјҡ
еҶ…еӯҳдёӯеҗ„иҮӘдҝқеӯҳдёҖд»Ҫе…ғж•°жҚ®
Edits ж—Ҙеҝ—еҸӘиғҪжңүдёҖд»ҪпјҢеҸӘжңүActive зҠ¶жҖҒзҡ„namenode иҠӮзӮ№еҸҜд»ҘеҒҡеҶҷж“ҚдҪң
дёӨдёӘnamenode йғҪеҸҜд»ҘиҜ»еҸ–edits
е…ұдә«зҡ„edits ж”ҫеңЁдёҖдёӘе…ұдә«еӯҳеӮЁдёӯз®ЎзҗҶпјҲqjournal е’ҢNFS дёӨдёӘдё»жөҒе®һзҺ°пјү
1гҖҒе®ўжҲ·з«Ҝи®ҝй—®active namenode //еҸҢnamenodeдёӯзҡ„fsimagesдёҖејҖе§ӢеҲқе§ӢеҢ–зҡ„ж—¶еҖҷпјҢйғҪжҳҜе®Ңе…ЁдёҖж ·пјҢйғҪжҳҜз©әзҡ„
2гҖҒеҶҷж•°жҚ®зҡ„ж—¶еҖҷпјҢеҶҷе…Ҙж•°жҚ®еҶҷеҲ°active namenodeдёӯеҶ…еӯҳе…ғж•°жҚ®зҡ„ж—¶еҖҷпјҢд№ҹдјҡе®һж—¶зҡ„жӣҙж–°еҲ°qjonalйӣҶзҫӨeditsж—Ҙеҝ—ж–Ү件系з»ҹдёӯ
3гҖҒstanday дјҡжІЎйҡ”дёҖж®өж—¶й—ҙеҺ»иҜ»еҸ–editsж–Ү件пјҢ并жӣҙж–°еҲ°иҮӘе·ұзҡ„е…ғж•°жҚ®еҶ…еӯҳдёӯпјҢдҝқжҢҒе’ҢactiveжңҖе°Ҹе·®ејӮ
4гҖҒжҜҸйҡ”дёҖж®өж—¶й—ҙпјҢstandayдёӯзҡ„fsimageдјҡе’Ңeditsжӣҙж–°дёҖж¬ЎпјҢдҝқжҢҒеңЁжң¬ең°
еӨҮжіЁпјҡeditsж—ўдёҚеұһдәҺactiveд№ҹдёҚеұһдәҺstanday дҫқйқ 第дёүж–№qjonalйӣҶзҫӨ е®Ңе…ЁзӢ¬з«Ӣ
еҒҮи®ҫ active namenode е®•жңәдәҶпјҢжӯӨж—¶ standay е’ҢactiveжңүзӮ№е·®ејӮпјҢдҪҶжҳҜе·®ејӮеҫҲе°ҸпјҢstandayиҝ…йҖҹд»Һeditsж—Ҙеҝ—зі»з»ҹдёӯжӣҙж–°жңҖж–°дёҖж¬ЎиҖҒзҡ„activeзҡ„ж“ҚдҪңпјҢе®Ңе…Ёе’ҢиҖҒactiveдёҖж ·зҡ„е…ғж•°жҚ®пјҢйӮЈд№Ҳе°ұиҰҒеҸҜд»Ҙиҝ…йҖҹзҡ„еҜ№еӨ–жқҘжҸҗдҫӣжңҚеҠЎгҖӮ
BгҖҒйңҖиҰҒдёҖдёӘзҠ¶жҖҒз®ЎзҗҶеҠҹиғҪжЁЎеқ—
е®һзҺ°дәҶдёҖдёӘzkfailoverпјҢеёёй©»еңЁжҜҸдёҖдёӘnamenode жүҖеңЁзҡ„иҠӮзӮ№
жҜҸдёҖдёӘzkfailover иҙҹиҙЈзӣ‘жҺ§иҮӘе·ұжүҖеңЁзҡ„namenode иҠӮзӮ№пјҢеҲ©з”Ёzk иҝӣиЎҢзҠ¶жҖҒж ҮиҜҶ
еҪ“йңҖиҰҒиҝӣиЎҢзҠ¶жҖҒеҲҮжҚўж—¶пјҢз”ұzkfailover жқҘиҙҹиҙЈеҲҮжҚў
еҲҮжҚўж—¶йңҖиҰҒйҳІжӯўbrain split зҺ°иұЎзҡ„еҸ‘з”ҹ
1гҖҒactiveдёҠзҡ„zkfcе®һж—¶зӣ‘жҺ§иҮӘе·ұnamenodeзҡ„зҠ¶жҖҒеҒҘеә·дҝЎжҒҜ
2гҖҒеҰӮжһңеҸ‘з”ҹдәҶејӮеёёд№ӢеҗҺдјҡжҺ§еҲ¶standayзҡ„zkfc
3гҖҒstandayзҡ„zkfc收еҲ°ејӮеёёд№ӢеҗҺдјҡеҺ»kill -9 active namenode
4гҖҒеҰӮжһңstandayзҡ„zkfcжІЎжңүжҲҗеҠҹеҫ—еҲ°kill -9 д№ӢеҗҺзҡ„иҝ”еӣһеҖјзҡ„иҜқпјҢйӮЈд№Ҳе°ұеҗҜеҠЁи„ҡжң¬еҺ»жқҖжӯ»active namenode и„ҡжң¬дҪҚзҪ®дёә/bin/true
5гҖҒжқҖжӯ»active namenodeд№ӢеҗҺпјҢе°ұжҲҗеҠҹеҫ—еҲ°и®ҝй—®еҖј
6гҖҒstandayзҡ„zkfcйҖҡзҹҘstanday namenodeз§°дёәactive еҜ№еӨ–жңҚеҠЎгҖӮ
д»Җд№ҲжҳҜzkfcпјҡе°ұжҳҜеҹәдәҺzookeeperе®һзҺ°зҡ„еӨұиҙҘеҲҮжҚўжҺ§еҲ¶еҷЁ
еҰӮдҪ•еңЁзҠ¶жҖҒеҲҮжҚўж—¶йҒҝе…Қbrain split(и„‘иЈӮ)пјҹ
и„‘иЈӮпјҡactive namenodeе·ҘдҪңдёҚжӯЈеёёеҗҺпјҢzkfcеңЁzookeeperдёӯеҶҷе…ҘдёҖдәӣж•°жҚ®пјҢиЎЁжҳҺејӮеёёпјҢиҝҷж—¶standby namenodeдёӯзҡ„zkfcиҜ»еҲ°ејӮеёёдҝЎжҒҜпјҢ并е°ҶstandbyиҠӮзӮ№зҪ®дёәactiveгҖӮдҪҶжҳҜпјҢеҰӮжһңд№ӢеүҚзҡ„active namenode并没жңүзңҹзҡ„жӯ»жҺүпјҢеҮәзҺ°дәҶеҒҮжӯ»пјҲжӯ»дәҶдёҖдјҡе„ҝеҗҺеҸҲжӯЈеёёдәҶпјүпјҢиҝҷж ·пјҢе°ұжңүдёӨеҸ°namenodeеҗҢж—¶е·ҘдҪңдәҶгҖӮиҝҷз§ҚзҺ°иұЎз§°дёәи„‘иЈӮгҖӮ
и§ЈеҶіж–№жЎҲпјҡstandby namenodeж„ҹзҹҘеҲ°дё»з”ЁиҠӮзӮ№еҮәзҺ°ејӮеёёеҗҺ并дёҚдјҡз«ӢеҚіеҲҮжҚўзҠ¶жҖҒпјҢzkfcдјҡйҰ–е…ҲйҖҡиҝҮsshиҝңзЁӢжқҖжӯ»activeиҠӮзӮ№зҡ„ namenodeиҝӣзЁӢпјҲkill -9 иҝӣзЁӢеҸ·пјүгҖӮеҰӮжһңеңЁдёҖж®өж—¶й—ҙеҶ…standbyзҡ„namenodeиҠӮзӮ№жІЎжңү收еҲ°killжү§иЎҢжҲҗеҠҹзҡ„еӣһжү§пјҢstandbyиҠӮзӮ№дјҡжү§иЎҢдёҖдёӘиҮӘе®ҡд№үи„ҡжң¬пјҢе°ҪйҮҸдҝқиҜҒдёҚдјҡеҮәзҺ°и„‘иЈӮй—®йўҳпјҒиҝҷдёӘжңәеҲ¶еңЁhadoopдёӯз§°дёәfencingпјҲеҢ…жӢ¬sshеҸ‘йҖҒkillжҢҮд»ӨпјҢжү§иЎҢиҮӘе®ҡд№үи„ҡжң¬дёӨйҒ“дҝқйҡңпјүгҖӮд»Һи§ЈеҶіж–№жЎҲдёӯеҸҜзҹҘпјӣеҪ“еҸ‘з”ҹactiveиҠӮзӮ№еҙ©еқҸж—¶пјӣhadoopдјҡиҝӣиЎҢд»ҘдёӢдёӨдёӘж“ҚдҪңпјҡ
1пјүйҖҡиҝҮssh killжҺүactiveиҠӮзӮ№зҡ„namenodeиҝӣзЁӢ
2пјүжү§иЎҢиҮӘе®ҡд№үи„ҡжң¬
еҺҹж–Үпјҡhttps://blog.csdn.net/qq_22310551/article/details/85700978
еҰӮдҪ•жІЎжңүеҸҠж—¶еҫ—еҲ°killзҡ„жҲҗеҠҹиҝ”еӣһдҝЎжҒҜпјҢеңЁи°ғз”ЁдёҖдёӘз”ЁжҲ·жҢҮе®ҡзҡ„shellи„ҡжң¬зЁӢеәҸгҖӮ
[root@hadoop-node01 bin]# ls -l /bin/true //и„ҡжң¬дҪҚзҪ®еңЁbinдёӢйқў
-rwxr-xr-x. 1 root root 21112 10жңҲ 15 2014 /bin/true
еңЁcdhдёӯиҝҷдёӘзЁӢеәҸеңЁ
HDFS High Availability йҳІеҫЎж–№жі•
dfs.ha.fencing.methods
з”ЁдәҺжңҚеҠЎйҳІеҫЎзҡ„йҳІеҫЎж–№жі•еҲ—иЎЁгҖӮshell(./cloudera_manager_agent_fencer.py) жҳҜдёҖз§Қи®ҫи®ЎдёәдҪҝз”Ё Cloudera Manager Agent зҡ„йҳІеҫЎжңәеҲ¶гҖӮsshfence ж–№жі•дҪҝз”Ё SSHгҖӮеҰӮжһңдҪҝз”ЁиҮӘе®ҡд№үйҳІеҫЎзЁӢеәҸ(еҸҜиғҪдёҺе…ұдә«еӯҳеӮЁгҖҒз”өжәҗиЈ…зҪ®жҲ–зҪ‘з»ңдәӨжҚўжңәйҖҡдҝЎ)пјҢеҲҷдҪҝз”Ё shell и°ғз”Ёе®ғ们гҖӮ
Cloudera Manager йҳІеҫЎзӯ–з•Ҙзҡ„и¶…ж—¶ж—¶йҷҗ
dfs.ha.fencing.cloudera_manager.timeout_millis 10000
еҹәдәҺ Cloudera Manager д»ЈзҗҶзҡ„йҳІеҫЎзЁӢеәҸдҪҝз”Ёзҡ„и¶…ж—¶ж—¶йҷҗпјҲжҜ«з§’пјү
zookeeperеңЁHAжңәеҲ¶дёӯзҡ„дҪңз”Ё
1гҖҒQJNйӣҶзҫӨйңҖиҰҒzkе®һзҺ°еҚҸи°ғжңҚеҠЎ
2гҖҒnamenodeдёӯи°ҒжҳҜactiveи°ҒжҳҜstandayи®°еҪ•еңЁzkдёӯ
3гҖҒzkfcеҹәдәҺzookeeperе®һзҺ°еӨұиҙҘеҲҮжҚўжҺ§еҲ¶еҷЁ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ