您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
HDFS主要用于最初由Yahoo提出的分布式文件系统,以下它的主要用途:
1、保存大数据
2、提供快速读取大数据的能力
Heroop帧的主要特征是通过将数据和计算分布在集群中的各节点服务器来实现分布式计算的目的。在计算逻辑和所需数据接近这一点上,并行计算分区后进行汇总。
基本模块
HDFS分离保存Meta数据和用户数据。Meta的数据被保存在Namicos中,用户数据被保存在Datan路径中。服务器之间的通信基于TCP协议。
与GFS(Google File System)同样,从可靠性的考虑出发,具有将文件的内容复制到多个Datao,之后将数据的复制复制到多个Datannampa的目的和优点。
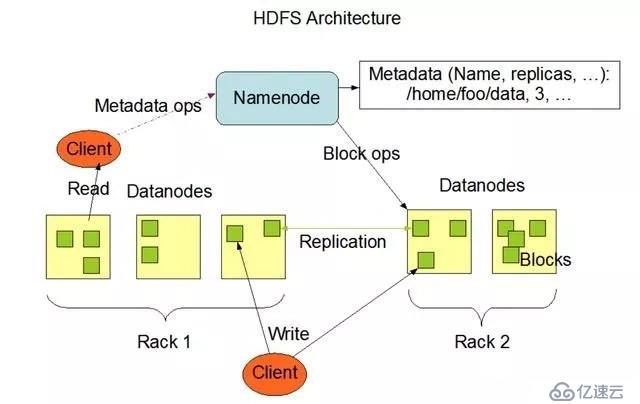
1、 Namamos
Namelos是HDFS的重要点,它保存了HDFS文件系统命名的空间树,文件和路径在Nameos中用inpoes显示。在HDFS系统中,文件的内容被分割为大的block(例如128 Mbytes,根据用户的需求被配置),各block独立复制到多个Data南径中。Namicos将各文件的各个block的复印件存储在Datanpase的物理位置。
HDFS cial读HDFS的过程。
读:当读HDFS保存的某些文件时,首先对Nameos,当Nameos返回该文件的block的Datan路径的位置时,可以从最近的Datao读取数据。
写:cial在写文件时,对Namelos的要求,Namicos将Datao写的位置返回(多个,例如3个Datao),对它要求直接的Datannampas,写入文件block。每个block,例如写三个Data号码路径,多确保文件block。
如何使用pporela方式写入数据,简单来说,将一个Datao的第一Datao数据复制到第二Datao,将第二Datao的数据复制到第三Datapass。
这里有几个概念:
很多小伙伴,对大数据的概念都是模糊不清的,大数据是什么,能做什么,学的时候,该按照什么线路去学习,学完往哪方面发展,想深入了解,想学习的同学欢迎加入大数据学习群:775908246,有大量干货(零基础以及进阶的经典实战)分享给大家,并且有清华大学毕业的资深大数据讲师给大家免费授课,给大家分享目前国内最完整的大数据高端实战实用学习流程体系。

2 、Datao
一个Datao上的block的拷贝由两个文件表示,第一文件是数据的内容本身,第二个文件包括block meta的数据(包括文件checksm),生成时间。
当Datao启动时,可以积极连接Namelos,验证names ple ID和Datao的软件版本。如果不符合Namelox,Datao会自动关闭。names psteID属于在初始化文件系统的示例时分配的不同names p纠纷ID的节点。
在HANshake握手后,Datao通过登录Namelos将Namicos的分配stor记ID(用于识别Datao)登录到Datanmupas中。
Datao能够通过Block rep报向Nameos发送登记时保存的block的复印信息。block rep报每1小时发送给Namicos,更新保存的复印信息。这样的Namicos,知道各自的拷贝保存着哪个Dataman路径。
如果Databs的周期性(譬如,每3秒),发送Namelox的消息的话,有Namicos10分以内没领取Data号码牌这样的消息,我想这个Datao已经不能提供服务。上面的block的复印件也不能利用。
Holtbated消息是Datao a .总存储器容量,b .使用的存储器空间和c .当前传输的数据的数目,这些信息可以使用Nameos的空间分配和负载平衡。
因为Nameos没有直接调整Data南径,所以使用hittbal的回答发送命令。这些命令是:
3、 Image和Journal
在任何HDFS client发起的事务上,变化被记录在journal上。checkpoint文件不会更改,它只会被新的checkpoint文件更新。如果checkpoint文件或journal文件丢失或损坏,命名空间信息就会部分或全部丢失,为了避免这种情况,HDFS可以通过配置将checkpoint和journal文件保存在不同的存储路径。
4、CheckpointNode和BackupNode
CheckpointNode周期性地将当前的checkpoint和journal组合产生新的checkpoint和一个空的journal。CheckpointNode往往运行在一个与NameNode不同的独立的服务器上。
BackupNode类似CheckpointNode,也可以周期性地生成checkpoint,但除此之外,它还能够在内存中保存一份与NameNode同步的image。active NameNode将journal的改动发送给BackupNode。
1、读写文件
HDFS实现的是多个读取模型。
HDFS cial在创建文件之前可以获取此文件的读取器。其他没有出租的cial无法写入此文件。写着操作的cial,如果对Namelos的更新关闭了文件,关闭契约。如果软件过期,cial将被关闭或未更新租赁,其他cial将获得租赁合同的权限。如果霍华德租赁期限到期(1小时)的话,HDFS租赁合同无法更新。
阅读可以不受租赁机制影响,并且多个客户端可以并行读取该文件。
2、block分布
相同block的不同复印的分布对于HDFS数据的可靠性,读写性能重要。默认策略如下:当一个新block创建时,HDFS将一个副本放在writer的所在地节点,第二个和第三个副本放在不同的机架不同的节点,其余更多副本放在另一个节点,原则:复印多个到同一个结点不能放置。两个以上的复印件不能放在同一个机上。复印数比RK少2倍时。
在一般的网络结构中,同一台机器的节点使用一个交换机连接。同一机器的节点之间的网络的带宽往往变高。
总的说来:

3 、复印管理
Namicos确保所有block中指定的复印数。当Namelos接到Datao发出的block reping时,block的数量检测高达-或over -指定的复印数。
如果超过了,Nameos删除某个副本。
在低于指定的复印数目的情况下,该block具有复制优先顺序,仅复印数有一个block具有最高的优先顺序。有线程确定新复制在哪里创建。
Nameos必须确保所有复印件不在同一个书架上,如果所有的复印件都在同一个书架上,Nameos必须减少指定的复印件数,从而启动复印。复印完成后,Nameos检测复印数大于指定数目,删除某个副本。通过复制-删除和复制。
4、平衡器
平衡器用来平衡HDFS集群中节点的磁盘使用率。当某个节点的磁盘使用率大于集群平均使用率超过一定阈值,平衡器会将数据从高磁盘使用率的DataNode节点移动到低使用率的DataNode节点。平衡器会尽量减少跨机架的数据拷贝。
5、block扫描仪
所有Databs都用于检测block的复印是否破损。另外,如果检测到损坏,Namicos将会在该复印标记损坏的同时创建新的复印件,并在新复印成功后删除损坏的复印件。
6、节点结束
集群管理员可以控制Datao的退出,Datao退出时,不会被选为复印的目的地。但仍然可以支持读者。Nameos将所有block的复印件移到其他Datanpass。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。