жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
д»ҠеӨ©е°ұи·ҹеӨ§е®¶иҒҠиҒҠжңүе…іDataphinжҖҺж ·её®еҠ©дјҒдёҡиҗғеҸ–ж•°жҚ®дёӯеҝғпјҢеҸҜиғҪеҫҲеӨҡдәәйғҪдёҚеӨӘдәҶи§ЈпјҢдёәдәҶи®©еӨ§е®¶жӣҙеҠ дәҶи§ЈпјҢе°Ҹзј–з»ҷеӨ§е®¶жҖ»з»“дәҶд»ҘдёӢеҶ…е®№пјҢеёҢжңӣеӨ§е®¶ж №жҚ®иҝҷзҜҮж–Үз« еҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
DataphinдҪңдёәйҳҝйҮҢе·ҙе·ҙж•°жҚ®дёӯеҸ°OneData (OneModelгҖҒOneIDгҖҒOneService)ж–№жі•и®әзҡ„дә§е“ҒиҪҪдҪ“пјҢеё®еҠ©дјҒдёҡжһ„е»әдёүеӨ§ж•°жҚ®дёӯеҝғпјҡеҹәдәҺж•°жҚ®йӣҶжҲҗеҪўжҲҗзҡ„еһӮзӣҙж•°жҚ®дёӯеҝғгҖҒеҹәдәҺж•°жҚ®ејҖеҸ‘жІүж·Җзҡ„е…¬е…ұж•°жҚ®дёӯеҝғе’ҢеҹәдәҺж Үзӯҫе·ҘеҺӮжһ„е»әзҡ„иҗғеҸ–ж•°жҚ®дёӯеҝғгҖӮд»ҠеӨ©жҲ‘们е°ұдёҖиө·жқҘзңӢзңӢпјҢDataphinжҳҜеҰӮдҪ•еҹәдәҺOneIDжҖқжғіжһ„е»әж•°жҚ®иҗғеҸ–дёӯеҝғпјҢиҝһжҺҘдёҠдёӢжёёеә”з”ЁдёәдјҒдёҡеҲӣйҖ жӣҙеӨҡд»·еҖјзҡ„еҗ§пҪһ
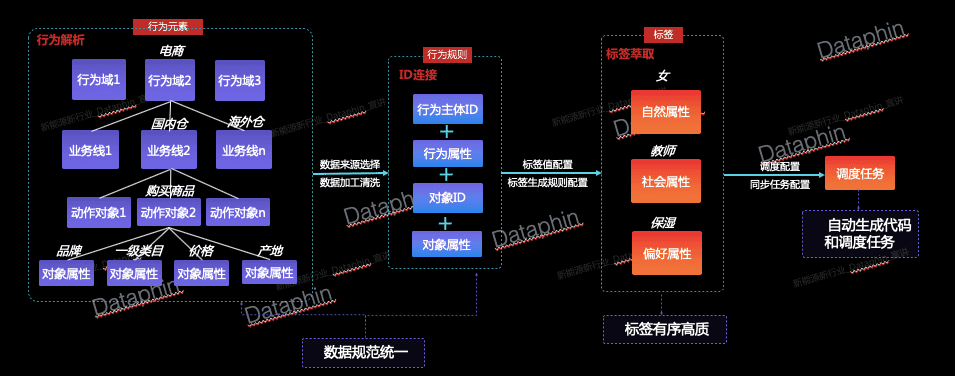
дёәд»Җд№ҲиҰҒе»әз«ӢиҗғеҸ–ж•°жҚ®дёӯеҝғпјҡжҸҗеҚҮж•°жҚ®д»·еҖјеҜҶеәҰ
йҰ–е…ҲпјҢжҲ‘们жқҘзңӢзңӢDataphinдёәд»Җд№ҲиҰҒеё®еҠ©дјҒдёҡжһ„е»әиҮӘе·ұзҡ„иҗғеҸ–ж•°жҚ®дёӯеҝғпјҹ
еӨ§ж•°жҚ®ж—¶д»ЈпјҢд»»дҪ•еҫ®е°Ҹзҡ„ж•°жҚ®йғҪеҸҜиғҪдә§з”ҹдёҚеҸҜжҖқи®®зҡ„д»·еҖјгҖӮдҪңдёәжҷәиғҪж•°жҚ®жһ„е»әдёҺз®ЎзҗҶе№іеҸ°пјҢDataphinзҡ„规иҢғе»әжЁЎгҖҒж•°жҚ®еӨ„зҗҶзӯүж ёеҝғеҠҹиғҪеё®еҠ©дјҒдёҡй«ҳж•Ҳж•ҙеҗҲжқҘиҮӘдёҚеҗҢдёҡеҠЎж•°жҚ®еә“зҡ„жө·йҮҸж•°жҚ®пјҢжІүж·Җж•°жҚ®иө„дә§пјҢжһ„е»әиҮӘе·ұзҡ„ж•°жҚ®дёӯеҸ°пјҢеә”еҜ№еӨ§ж•°жҚ®ж—¶д»ЈVolumeпјҲеӨ§йҮҸпјүгҖҒVarietyпјҲеӨҡж ·пјүгҖҒVelocityпјҲй«ҳйҖҹпјүж–№йқўзҡ„жҢ‘жҲҳгҖӮ然иҖҢпјҢзӣёжҜ”дәҺдј з»ҹзҡ„е°Ҹж•°жҚ®пјҢеӨ§ж•°жҚ®жӣҙеӨ§зҡ„д»·еҖјеңЁдәҺд»Һжө·йҮҸдёҚзӣёе…ізҡ„еҗ„зұ»ж•°жҚ®дёӯпјҢжҢ–жҺҳеҮәеҜ№йў„жөӢеҲҶжһҗжңүеҸӮиҖғж„Ҹд№үзҡ„ж•°жҚ®пјҢжҸҗеҚҮж•°жҚ®д»·еҖјеҜҶеәҰ并еә”з”ЁдәҺжҢҮеҜјз”ҹдә§пјҢд»ҺиҖҢеё®еҠ©дјҒдёҡе®һзҺ°жҸҗж•ҲйҷҚжң¬зҡ„зӣ®зҡ„гҖӮDataphinзҡ„ж•°жҚ®иҗғеҸ–еҠҹиғҪжӯЈжҸҗдҫӣдәҶиҝҷж ·зҡ„иғҪеҠӣгҖӮ
д»ҺдёҡеҠЎи§Ҷи§’жқҘзңӢпјҢж—Ҙеёёз”ҹдә§е’ҢиҗҘй”Җжҙ»еҠЁдёӯпјҢдёҚз®ЎжҳҜдәәзҫӨеңҲйҖүгҖҒйҖүеқҖиҝҳжҳҜдёӘжҖ§еҢ–жҠ•ж”ҫпјҢйғҪзҰ»дёҚејҖж Үзӯҫзҡ„жҢҮеҜјгҖӮж ҮзӯҫжҳҜеҜ№дёҖдёӘе®һдҪ“зҡ„з«ӢдҪ“еҲ»з”»пјҲдёҚеұҖйҷҗдәҺдәәпјҢд»»дҪ•еҸҜиў«жҸҸиҝ°е’ҢеҲҶжһҗзҡ„еӯҳеңЁйғҪеҸҜд»ҘжҳҜе®һдҪ“пјҢеҰӮе•Ҷе“ҒгҖҒе…¬еҸёзӯүпјүгҖӮдёҚеҗҢз»ҙеәҰзҡ„ж Үзӯҫд»ҺдёҚеҗҢи§’еәҰеҜ№е®һдҪ“иҝӣиЎҢжҸҸиҝ°пјҢдҫӢеҰӮд»Ҙйӣ¶е”®и§Ҷи§’дёәеҲҮе…ҘзӮ№пјҢжҲ‘们еҸҜд»Ҙд»ҺиҮӘ然еұһжҖ§пјҲеҰӮжҖ§еҲ«гҖҒе№ҙйҫ„пјүгҖҒзӨҫдјҡеұһжҖ§пјҲеҰӮз»ҸжөҺзҠ¶еҶөгҖҒе©ҡ姻зҠ¶жҖҒпјүгҖҒе…ҙи¶ЈеҒҸеҘҪпјҲеҰӮе–ңж¬ўж•ҙжҙҒзҡ„зҺҜеўғгҖҒеёҢжңӣжңүжјӮдә®зҡ„зүҷйҪҝпјүе’ҢиЎҢдёҡж¶Ҳиҙ№еҒҸеҘҪпјҲеҰӮзҫҺеҰҶеҒҸеҘҪгҖҒжҜҚе©ҙеҒҸеҘҪпјүжқҘеҜ№ж¶Ҳиҙ№иҖ…иҝӣиЎҢжҸҸиҝ°гҖӮй«ҳиҙЁйҮҸгҖҒе…Ёйқўзҡ„ж ҮзӯҫиғҪеӨҹжңүж•Ҳең°жҠҪиұЎеҮәдёҖдёӘе®һдҪ“зҡ„дҝЎжҒҜе…ЁиІҢпјҢдёәзІҫеҮҶиҗҘй”ҖеҘ е®ҡдәҶеҹәзЎҖгҖӮ
ж•°жҚ®еҸӘжңүиһҚйҖҡжүҚиғҪдә§з”ҹжӣҙеӨ§зҡ„д»·еҖјпјҢжҲ‘们дёҚд»…еёҢжңӣеҸҜд»ҘеҲҶжһҗе’Ңеә”з”ЁеӨ§ж•°жҚ®пјҢжӣҙеёҢжңӣеҫ—еҲ°йҖҡиҝҮи·ЁдёҡеҠЎеҚ•е…ғиҝһжҺҘиө·жқҘзҡ„ж•°жҚ®е’ҢзІҫз»ҶеҢ–иҗғеҸ–зҡ„ж•°жҚ®гҖӮиҝҷз§Қжғ…еҶөдёӢпјҢDataphinж•°жҚ®иҗғеҸ–жЁЎеқ—еҹәдәҺдёҡеҠЎж•°жҚ®еә“зҡ„еҺҹе§Ӣж•°жҚ®е’Ңе»әжЁЎз ”еҸ‘зӯүжІүж·Җзҡ„ж•°жҚ®иө„дә§пјҢе°Ҷе…Ёзі»з»ҹдёӯдё»ж•°жҚ®вҖ”вҖ”еҚіиҙҜз©ҝеҗ„дёӘйҡ”зҰ»дёҡеҠЎзҡ„ж ёеҝғеҜ№иұЎпјҢиҝӣиЎҢиҜҶеҲ«дёҺе…іиҒ”иҝһжҺҘпјҢжү“йҖҡдёҡеҠЎж•°жҚ®еӯӨеІӣпјҢиҝӣдёҖжӯҘжҸҗзӮјеҸҜзӣҙжҺҘеә”з”Ёзҡ„й«ҳд»·еҖјж Үзӯҫж•°жҚ®пјҢд»ҺиҖҢеё®еҠ©дјҒдёҡжһ„е»әиҮӘе·ұзҡ„иҗғеҸ–ж•°жҚ®дёӯеҝғпјҢ并еҜ№жҺҘдёҠжёёеә”з”ЁпјҲQuickAudienceзӯүпјүиҝӣдёҖжӯҘжҢҮеҜјз”ҹдә§иҗҘй”Җжҙ»еҠЁгҖӮ
еҰӮдҪ•й«ҳж•Ҳе»әз«ӢиҗғеҸ–ж•°жҚ®дёӯеҝғпјҡеҸҜи§ҶеҢ–й…ҚзҪ®пјҢиҮӘеҠЁеҢ–з”ҹдә§
Dataphinз ”еҸ‘жЁЎеқ—дёӢзҡ„ж•°жҚ®иҗғеҸ–дёәжҲ‘们жҸҗдҫӣдәҶиҝһжҺҘиЎҢдёәж•°жҚ®е№¶е®һзҺ°ж ҮзӯҫиҗғеҸ–зҡ„еҠҹиғҪпјҢзҺ°йҳ¶ж®өдјҳе…Ҳж”ҜжҢҒд»Ҙж¶Ҳиҙ№иҖ…дёәеҜ№иұЎзҡ„ж•°жҚ®дҪ“зі»пјҢеҠҹиғҪжЁЎеқ—дё»иҰҒеҢ…жӢ¬3 еӨ§йғЁеҲҶпјҡIDдёӯеҝғгҖҒиЎҢдёәдёӯеҝғе’Ңж ҮзӯҫдёӯеҝғпјҲзӣ®еүҚIDдёӯеҝғжҡӮжңӘдёҠзәҝпјүгҖӮжӯӨеӨ–пјҢиҝҗз»ҙжЁЎеқ—дёӢиҝҳжҸҗдҫӣеҚ•зӢ¬зҡ„иҗғеҸ–иҝҗз»ҙеӯҗжЁЎеқ—пјҢж”ҜжҢҒд»ҺдёҡеҠЎи§Ҷи§’жҹҘзңӢиҗғеҸ–зӣёе…ізҡ„и°ғеәҰд»»еҠЎгҖӮдёӢйқўпјҢжҲ‘们е°Ҷд»ҺеҮ дёӘеҠҹиғҪжЁЎеқ—зҡ„и§Ҷи§’з»ҷеӨ§е®¶д»Ӣз»ҚDataphinеҰӮдҪ•её®еҠ©дјҒдёҡжһ„е»әиҮӘе·ұзҡ„иҗғеҸ–ж•°жҚ®дёӯеҝғгҖӮ
cdn.com/95221d8f99c5611687fcfb363c72554d0071f209.png">
1пјүIDдёӯеҝғпјҡзӣёе…іIDиҮӘеҠЁеҢ–иҜҶеҲ«дёҺиҝһжҺҘ
DataphinеҹәдәҺOneIDзҡ„жҖқжғіпјҢд»Ҙе”ҜдёҖж ҮиҜҶжү“йҖҡжқҘиҮӘдёҚеҗҢе№іеҸ°гҖҒзі»з»ҹгҖҒжё йҒ“зҡ„ж•°жҚ®пјҢж”ҜжҢҒйҖҡиҝҮеҸҜи§ҶеҢ–з•ҢйқўеҸӮж•°й…ҚзҪ®зҡ„ж–№ејҸпјҢд»ҺжүҖжңүж•°жҚ®дёӯжҸҗзӮје№¶еҹәдәҺз®—жі•иҮӘеҠЁиҜҶеҲ«еҗ„зұ»еһӢID д№Ӣй—ҙзҡ„жҳ е°„е…ізі»пјҲиҙӯзү©дјҡе‘ҳIDгҖҒи§Ҷйў‘и§ӮзңӢиҖ…IDгҖҒиҙӯзү©и®ҫеӨҮmacгҖҒи§ӮзңӢи®ҫеӨҮIP зӯүпјүпјҢ并е°ҶеұһдәҺеҗҢдёҖе®һдҪ“зҡ„дёҚеҗҢзұ»еһӢIDйҖҡиҝҮе”ҜдёҖзҡ„One IDиҝӣиЎҢиҝһжҺҘпјҢдҪҝеҫ—еҹәдәҺIDз”ҹдә§зҡ„ж ҮзӯҫеҸҜд»ҘиҒҡеҗҲеҲ°еҗҢдёҖе®һдҪ“пјҢд»ҺиҖҢеҜ№е®һдҪ“иҝӣиЎҢжӣҙзІҫеҮҶгҖҒе…Ёйқўзҡ„еҲ»з”»гҖӮ
2пјүиЎҢдёәдёӯеҝғпјҡжІүж·ҖиЎҢдёәе…ғзҙ пјҢжһ„е»әиЎҢдёә规еҲҷ
Dataphinзӣ®еүҚж”ҜжҢҒд»Ҙдәәзҡ„зӣёе…іID дёәдёӯеҝғпјҢйҖҡиҝҮеҸҜи§ҶеҢ–з•ҢйқўиЎЁеҚ•й…ҚзҪ®зҡ„ж–№ејҸпјҢд»ҺжқҘжәҗиЎҢдёәж•°жҚ®дёӯжҸҗзӮјиҝӣиҖҢиҒҡжӢўдёҚеҗҢдёҡеҠЎеҹҹдёӢзҡ„иЎҢдёәж•°жҚ®пјҲеҰӮз”өе•Ҷиҙӯзү©гҖҒи§Ҷйў‘и§ӮзңӢпјүгҖӮ
йҰ–е…ҲпјҢжҲ‘们йңҖиҰҒд»ҺдёҡеҠЎи§Ҷи§’еҜ№иЎҢдёәж•°жҚ®иҝӣиЎҢжўізҗҶпјҢд»ҺдёӯжҸҗзӮјеҮәеҸҜеӨҚз”Ёзҡ„иЎҢдёәе…ғзҙ пјҲиЎҢдёәеҹҹгҖҒдёҡеҠЎзәҝгҖҒеҠЁдҪңгҖҒеҜ№иұЎгҖҒеҜ№иұЎеұһжҖ§пјүпјҢ并йҖҡиҝҮеҜ№иЎҢдёәе…ғзҙ иҝӣиЎҢз»„еҗҲе®ҡд№үдёҚеҗҢзҡ„иЎҢдёәпјҲиЎҢдёәеҹҹ-дёҡеҠЎзәҝ-еҠЁдҪң-еҜ№иұЎпјүгҖӮиЎҢдёәеҹҹиҒҡеҗҲдёҡеҠЎеҗ«д№үдёҖиҮҙзҡ„иЎҢдёәж•°жҚ®пјҢеҰӮз”өе•ҶеҹҹгҖҒж–ҮеЁұеҹҹпјӣдёҡеҠЎзәҝеҹәдәҺиЎҢдёәеҹҹе°ҶиЎҢдёәж•°жҚ®иҝӣдёҖжӯҘз»ҶеҲҶпјҢеҗ„дёҡеҠЎзәҝд№Ӣй—ҙзӣёеҜ№зӢ¬з«ӢпјҢеҰӮж·ҳе®қдёҡеҠЎзәҝгҖҒеӨ©зҢ«дёҡеҠЎзәҝпјӣеҠЁдҪңжҢҮиЎҢдёәдё»дҪ“еҸ‘еҮәзҡ„ж“ҚдҪңпјҢеҰӮиҙӯд№°гҖҒжөҸи§ҲпјӣеҜ№иұЎжҢҮиЎҢдёәдё»дҪ“ж“ҚдҪңзҡ„е…·дҪ“дәӢзү©пјҢеҰӮе•Ҷе“ҒгҖҒз”өеҪұпјӣеҜ№иұЎеұһжҖ§жҳҜеҜ№иұЎзҡ„жҸҸиҝ°жҖ§дҝЎжҒҜпјҢеҰӮеҗҚз§°гҖҒе“ҒзүҢгҖҒе№ҙд»ҪгҖӮйҖҡиҝҮжҠҪеҸ–жІүж·ҖиЎҢдёәе…ғзҙ пјҢжҲ‘们еҸҜд»Ҙе°ҶжқҘжәҗж•°жҚ®жӣҙеҘҪең°иҝӣиЎҢеҲ’еҲҶз»„еҗҲд»Ҙеҫ—еҲ°е…·жңүжҳҺзЎ®дёҡеҠЎеҗ«д№үзҡ„иЎҢдёәпјҢеҰӮз”өе•Ҷеҹҹ-ж·ҳе®қ-иҙӯд№°-е•Ҷе“ҒгҖҒж–ҮеЁұеҹҹ-дјҳй…·-жөҸи§Ҳ-з”өеҪұгҖӮйҖҡиҝҮжІүж·ҖиЎҢдёәе…ғзҙ пјҢжҲ‘们еҸҜд»ҘжӣҙеҘҪең°и§„иҢғжқҘжәҗж•°жҚ®пјҢ并еҮҸе°‘йҮҚеӨҚе»әи®ҫе’ҢдәәеҠӣжҠ•е…ҘгҖӮ
з»ҷеҗҢдёҖиЎҢдёәйҖүжӢ©дёҚеҗҢзҡ„жқҘжәҗ表并添еҠ й…ҚзҪ®пјҢеҚіз”ҹжҲҗдёҚеҗҢзҡ„иЎҢдёә规еҲҷпјҲз”ұиЎҢдёә+жқҘжәҗиЎЁе”ҜдёҖзЎ®е®ҡпјүпјҢеҗҺз»ӯж Үзӯҫз”ҹдә§е°Ҷдҫқиө–е·Із»Ҹжһ„е»әзҡ„иЎҢдёәе’ҢиЎҢдёә规еҲҷгҖӮ规еҲҷй…ҚзҪ®дё»иҰҒеҢ…жӢ¬иЎҢдёәдё»дҪ“IDгҖҒеҜ№иұЎгҖҒеҜ№иұЎеұһжҖ§е’ҢиЎҢдёәеҸ‘з”ҹж¬Ўж•°пјҢд»ҺжқҘжәҗиЎЁйҖүжӢ©зӣёеә”зҡ„еӯ—ж®өпјҢеҶҚйҖҡиҝҮиЎҢдёә规еҲҷзҡ„е‘Ёжңҹи°ғеәҰд»»еҠЎпјҢжҲ‘们е°ұиғҪеҫ—еҲ°жҢҒз»ӯжӣҙж–°зҡ„иЎҢдёәж•°жҚ®дҪңдёәж Үзӯҫз”ҹдә§зҡ„жқҘжәҗгҖӮ
3пјүж Үзӯҫдёӯеҝғпјҡй«ҳж•Ҳж Үзӯҫз”ҹдә§
жһ„е»әе®ҢжҲҗиЎҢдёәе’ҢиЎҢдёә规еҲҷеҗҺпјҢиҝӣдёҖжӯҘең°пјҢжҲ‘们е°ҶеҹәдәҺз®—жі•жЁЎеһӢпјҢйҖҡиҝҮз®ҖеҚ•зҡ„з•Ңйқўй…ҚзҪ®е®ҡд№үж Үзӯҫзҡ„з”ҹжҲҗ规еҲҷгҖӮ
ж Үзӯҫзҡ„й…ҚзҪ®еҲҶдёәдёӨеӨ§жӯҘйӘӨпјҡ第дёҖжӯҘйҰ–е…ҲеҹәдәҺе®ҡд№үзҡ„иЎҢдёәеңҲйҖүеҮәжҹҗж ҮзӯҫйңҖиҰҒдҫқиө–зҡ„иЎҢдёәж•°жҚ®пјҢжҺҘзқҖеҜ№йў„жңҹеҫ—еҲ°зҡ„ж ҮзӯҫеҖје’Ңжү“ж Үж–№ејҸиҝӣиЎҢй…ҚзҪ®пјӣ第дәҢжӯҘйңҖиҰҒеҜ№е·ІйҖүзҡ„иЎҢдёәж•°жҚ®и®ҫзҪ®ж—¶й—ҙиЎ°еҮҸжЁЎејҸпјҢ并еҹәдәҺдёҡеҠЎеҗ«д№үз»ҷдёҚеҗҢзҡ„иЎҢдёәеҲҶй…ҚдёҚеҗҢзҡ„жқғйҮҚгҖӮдҫӢеҰӮпјҢжҲ‘们и®ӨдёәвҖңиҙӯд№°жҜҚе©ҙз”Ёе“ҒвҖқе’ҢвҖңи§ӮзңӢдәІеӯҗи§Ҷйў‘вҖқзҡ„з”ЁжҲ·йғҪеҸҜд»Ҙиў«жү“дёҠвҖңжҜҚе©ҙдәәзҫӨвҖқзҡ„ж ҮзӯҫпјҢйӮЈд№Ҳ第дёҖжӯҘпјҢжҲ‘们е°ҶиҝҷдёӨз§ҚиЎҢдёәзӣёе…ізҡ„ж•°жҚ®йғҪеӢҫйҖүеҮәжқҘпјҢи®ҫзҪ®йў„жңҹж ҮзӯҫеҖјдёәвҖңжҜҚе©ҙдәәзҫӨвҖқпјӣ第дәҢжӯҘпјҢжҲ‘们и®Өдёәиҝ‘жңҹзҡ„иЎҢдёәжҜ”д№ӢеүҚеҸ‘з”ҹзҡ„иЎҢдёәжӣҙжңүеҸӮиҖғжҖ§пјҢеӣ жӯӨйҖүжӢ©зәҝжҖ§иЎ°еҮҸжЁЎејҸпјҢз»ҷиҝ‘жңҹиЎҢдёәиөӢдәҲжӣҙеӨ§зҡ„ж—¶й—ҙжқғйҮҚпјӣеҗҢж—¶пјҢеҹәдәҺдёҡеҠЎз»ҸйӘҢпјҢжҲ‘们и®ӨдёәвҖңиҙӯд№°жҜҚе©ҙз”Ёе“ҒвҖқжҜ”вҖңи§ӮзңӢдәІеӯҗи§Ҷйў‘вҖқжӣҙиғҪзІҫзЎ®е®ҡдҪҚеҲ°зӣ®ж Үз”ЁжҲ·пјҢжүҖд»Ҙз»ҷвҖңиҙӯд№°жҜҚе©ҙз”Ёе“ҒвҖқиЎҢдёәеҲҶй…ҚжӣҙеӨ§зҡ„жқғйҮҚгҖӮиҝҷж ·пјҢжҲ‘们е°ұе®ҢжҲҗдәҶвҖңжҜҚе©ҙдәәзҫӨвҖқиҝҷж ·дёҖдёӘиҙӯзү©еҒҸеҘҪж Үзӯҫзҡ„з”ҹдә§гҖӮ
дёҚеҗҢдәҺдј з»ҹж Үзӯҫз”ҹдә§пјҢDataphinж•°жҚ®иҗғеҸ–зҡ„з”ЁжҲ·еҸӘйңҖиҰҒе…іеҝғж Үзӯҫзҡ„е…·дҪ“дёҡеҠЎеҗ«д№үе’Ң规еҲҷпјҢиҖҢдёҚз”Ёе…іеҝғеә•еұӮз®—жі•зҡ„е®һзҺ°пјҢйҖҡиҝҮз®ҖеҚ•зҡ„з•Ңйқўж“ҚдҪңеҚіеҸҜе®ҢжҲҗж Үзӯҫзҡ„й…ҚзҪ®пјҢ并иҮӘеҠЁз”ҹжҲҗд»Јз Ғе’Ңе‘Ёжңҹи°ғеәҰд»»еҠЎпјҢжһҒеӨ§зЁӢеәҰдёҠйҷҚдҪҺдәҶж Үзӯҫз”ҹдә§зҡ„йҡҫеәҰе’Ңй—Ёж§ӣгҖӮ
4пјүиҗғеҸ–иҝҗз»ҙ
жңҖеҗҺпјҢжҲ‘们еңЁиҗғеҸ–жЁЎеқ—й…ҚзҪ®зҡ„иЎҢдёә规еҲҷе’Ңж ҮзӯҫйғҪдјҡз”ҹжҲҗиҮӘеҠЁеҢ–и°ғеәҰзҡ„е‘Ёжңҹд»»еҠЎгҖӮеңЁвҖңиҝҗз»ҙвҖқз•Ңйқўзҡ„вҖңиҗғеҸ–иҝҗз»ҙвҖқеӯҗжЁЎеқ—дёӢпјҢжҲ‘们еҸҜд»Ҙд»ҺдёҡеҠЎи§Ҷи§’жӣҙжё…жҷ°жҳҺдәҶең°жҹҘзңӢзӣёеә”д»»еҠЎе’ҢеҜ№еә”з”ҹжҲҗзҡ„е®һдҫӢпјҢ并й’ҲеҜ№ејӮеёёи°ғеәҰйҖҡиҝҮиЎҘж•°жҚ®зӯүж“ҚдҪңеӣһеӨҚз”ҹдә§гҖӮеҰӮжӯӨдёҖжқҘпјҢдёҡеҠЎдәәе‘ҳд№ҹеҸҜд»Ҙй…ҚзҪ®е№¶жҹҘзңӢиҗғеҸ–д»»еҠЎпјҢеӨ§еӨ§йҷҚдҪҺдәҶеҜ№жҠҖжңҜдәәе‘ҳзҡ„дҫқиө–гҖӮ
Dataphinж•°жҚ®иҗғеҸ–еҠҹиғҪдёҠзәҝеҗҺпјҢжү№йҮҸз”ҹдә§еҚҒеҮ дёӘеҗҢзұ»еһӢзҡ„ж Үзӯҫзҡ„ж—¶й—ҙд»ҺдёӨе‘Ёзј©зҹӯеҲ°дёӨеӨ©е·ҰеҸіпјҢиҖҢдё”еҸҜд»Ҙзӣ‘жҺ§ж Үзӯҫз”ҹдә§д»»еҠЎпјҢдёҚз®ЎжҳҜйҖҹеәҰиҝҳжҳҜжӯЈзЎ®жҖ§дёҠйғҪеҫ—еҲ°дәҶеҫҲеӨ§зҡ„жҸҗеҚҮпјӣеҸӮдёҺзҡ„дәәе‘ҳд№ҹд»ҺеҺҹжң¬зҡ„ж•°жҚ®дә§е“Ғз»ҸзҗҶгҖҒж•°жҚ®з ”еҸ‘е·ҘзЁӢеёҲгҖҒж•°жҚ®з§‘еӯҰ家дёәдё»еҜјиҪ¬еҸҳдёәжӣҙеӨҡзҡ„дёҡеҠЎи§’иүІеҸҜд»ҘеҸӮдёҺз”ҡиҮідё»еҜјгҖӮ
DataphinиҗғеҸ–ж•°жҚ®дёӯеҝғзҡ„е»әз«ӢпјҢеё®еҠ©дјҒдёҡжӣҙеҘҪзҡ„е®һзҺ°дәҶзӣ®ж ҮеҜ№иұЎзӣёе…іID зҡ„иҜҶеҲ«дёҺиҝһжҺҘгҖҒзӣ®ж ҮеҜ№иұЎжүҖжңүиЎҢдёәзҡ„规иҢғеҢ–з»“жһ„еҢ–иҒҡйӣҶе’Ңзӣ®ж ҮеҜ№иұЎзӣёе…іж ҮзӯҫеұһжҖ§зҡ„еҝ«йҖҹеҲӣе»әпјҢд»ҺиҖҢеҝ«йҖҹжһ„е»әдјҒдёҡиҮӘе·ұз”ЁжҲ·ж•°жҚ®иө„дә§пјҢд»ҘдҫҝеҜ№жҺҘж•°жҚ®еә”з”Ёзұ»дә§е“ҒпјҢе®һзҺ°иҗҘй”ҖжҠ•ж”ҫзӯүгҖӮ
зңӢе®ҢдёҠиҝ°еҶ…е®№пјҢдҪ 们еҜ№DataphinжҖҺж ·её®еҠ©дјҒдёҡиҗғеҸ–ж•°жҚ®дёӯеҝғжңүиҝӣдёҖжӯҘзҡ„дәҶи§Јеҗ—пјҹеҰӮжһңиҝҳжғідәҶи§ЈжӣҙеӨҡзҹҘиҜҶжҲ–иҖ…зӣёе…іеҶ…е®№пјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢж„ҹи°ўеӨ§е®¶зҡ„ж”ҜжҢҒгҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ