您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
监听是一个目录,这个目录不能有子目录,监控的是这个目录下的文件。采集完成,这个目录下的文件会加上后缀(.COMPLETED)
配置文件:
#Name the components on this agent
#这里的a1指的是agent的名字,可以自定义,但注意:同一个节点下的agent的名字不能相同
#定义的是sources、sinks、channels的别名
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#指定source的类型和相关的参数
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /home/hadoop/flumedata
#设定channel
a1.channels.c1.type = memory
#设定sink
a1.sinks.k1.type = logger
#Bind the source and sink to the channel
#设置sources的通道
a1.sources.r1.channels = c1
#设置sink的通道
a1.sinks.k1.channel = c1 一个NetCat Source用来监听一个指定端口,并将接收到的数据的每一行转换为一个事件。
数据源: netcat(监控tcp协议)
Channel:内存
数据目的地:控制台
配置文件
#指定代理
a1.sources = r1
a1.channels = c1
a1.sinks = k1
#指定sources
a1.sources.r1.channels = c1
#指定source的类型
a1.sources.r1.type = netcat
#指定需要监控的主机
a1.sources.r1.bind = 192.168.191.130
#指定需要监控的端口
a1.sources.r1.port = 3212
#指定channel
a1.channels.c1.type = memory
#sinks 写出数据 logger
a1.sinks.k1.channel=c1
a1.sinks.k1.type=logger 监听AVRO端口来接受来自外部AVRO客户端的事件流。利用Avro Source可以实现多级流动、扇出流、扇入流等效果。另外也可以接受通过flume提供的Avro客户端发送的日志信息。
数据源: avro
Channel:内存
数据目的地:控制台
配置文件
#指定代理
a1.sources = r1
a1.channels = c1
a1.sinks = k1
#指定sources
a1.sources.r1 channels. = c1
#指定source的类型
a1.sources.r1.type = avro
#指定需要监控的主机名
a1.sources.r1.bind = hadoop03
#指定需要监控的端口
a1.sources.r1.port = 3212
#指定channel
a1.channels.c1.type = memory
#指定sink
a1.sinks.k1.channel = c1
a1.sinks.k1.type = loggersource ====exec (一个Linux命令: tail -f)
channel====memory
sink====hdfs
注意:如果集群是高可用的集群,需要将core-site.xml 和hdfs-site.xml 放入flume的conf中。
配置文件:
a1.sources = r1
a1.channels = c1
a1.sinks = k1
#指定sources
a1.sources.r1.channels = c1
#指定source的类型
a1.sources.r1.type = exec
#指定exec的command
a1.sources.r1.command = tail -F /home/hadoop/flumedata/zy.log
#指定channel
a1.channels.c1.type = memory
#指定sink 写入hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.type = hdfs
#指定hdfs上生成的文件的路径年-月-日,时_分
a1.sinks.k1.hdfs.path = /flume/%y-%m-%d/%H_%M
#开启滚动
a1.sinks.k1.hdfs.round = true
#设定滚动的时间(设定目录的滚动)
a1.sinks.k1.hdfs.roundValue = 24
#时间的单位
a1.sinks.k1.hdfs.roundUnit = hour
#设定文件的滚动
#当前文件滚动的时间间隔(单位是:秒)
a1.sinks.k1.hdfs.rollInterval = 10
#设定文件滚动的大小(文件多大,滚动一次)
a1.sinks.k1.hdfs.rollSize = 1024
#设定文件滚动的条数(多少条滚动一次)
a1.sinks.k1.hdfs.rollCount = 10
#指定时间来源(true表示指定使用本地时间)
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#设定存储在hdfs上的文件类型,(DataStream,文本)
a1.sinks.k1.hdfs.fileType = DataStream
#加文件前缀
a1.sinks.k1.hdfs.filePrefix = zzy
#加文件后缀
a1.sinks.k1.hdfs.fileSuffix = .log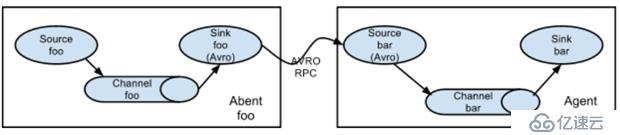
从第一台机器的flume agent传送到第二台机器的flume agent。
例:
规划:
hadoop02:tail-avro.properties
使用 exec “tail -F /home/hadoop/testlog/welog.log”获取采集数据
使用 avro sink 数据都下一个 agent
hadoop03:avro-hdfs.properties
使用 avro 接收采集数据
使用 hdfs sink 数据到目的地
配置文件
#tail-avro.properties
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/testlog/date.log
a1.sources.r1.channels = c1
#Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.channel = c1
a1.sinks.k1.hostname = hadoop02
a1.sinks.k1.port = 4141
a1.sinks.k1.batch-size = 2
#Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1#avro-hdfs.properties
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#Describe/configure the source
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 4141
#Describe k1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path =hdfs://myha01/testlog/flume-event/%y-%m-%d/%H-%M
a1.sinks.k1.hdfs.filePrefix = date_
a1.sinks.k1.hdfs.maxOpenFiles = 5000
a1.sinks.k1.hdfs.batchSize= 100
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat =Text
a1.sinks.k1.hdfs.rollSize = 102400
a1.sinks.k1.hdfs.rollCount = 1000000
a1.sinks.k1.hdfs.rollInterval = 60
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1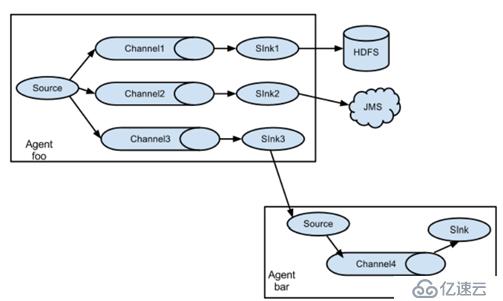
在一份agent中有多个channel和多个sink,然后多个sink输出到不同的文件或者文件系统中。
规划:
Hadoop02:(tail-hdfsandlogger.properties)
使用 exec “tail -F /home/hadoop/testlog/datalog.log”获取采集数据
使用 sink1 将数据 存储hdfs
使用 sink2 将数据都存储 控制台
配置文件
#tail-hdfsandlogger.properties
#2个channel和2个sink的配置文件
#Name the components on this agent
a1.sources = s1
a1.sinks = k1 k2
a1.channels = c1 c2
#Describe/configure tail -F source1
a1.sources.s1.type = exec
a1.sources.s1.command = tail -F /home/hadoop/logs/catalina.out
#指定source进行扇出到多个channnel的规则
a1.sources.s1.selector.type = replicating
a1.sources.s1.channels = c1 c2
#Use a channel which buffers events in memory
#指定channel c1
a1.channels.c1.type = memory
#指定channel c2
a1.channels.c2.type = memory
#Describe the sink
#指定k1的设置
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path=hdfs://myha01/flume_log/%y-%m-%d/%H-%M
a1.sinks.k1.hdfs.filePrefix = events
a1.sinks.k1.hdfs.maxOpenFiles = 5000
a1.sinks.k1.hdfs.batchSize= 100
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat =Text
a1.sinks.k1.hdfs.rollSize = 102400
a1.sinks.k1.hdfs.rollCount = 1000000
a1.sinks.k1.hdfs.rollInterval = 60
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.channel = c1
#指定k2的
a1.sinks.k2.type = logger
a1.sinks.k2.channel = c2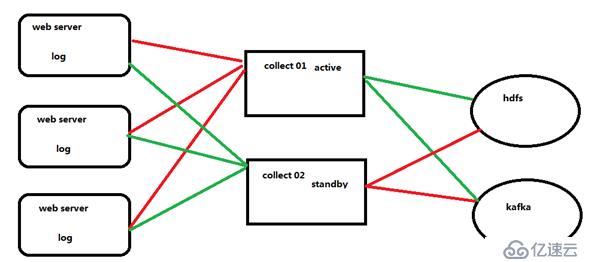
首先在三个web服务器中收集数据,然后交给collect,此处的collect是高可用的,首先collect01是主,所有收集到的数据发送给他,collect02只是出于热备状态不接受数据,当collect01宕机的时候,collect02顶替,然后接受数据,最终将数据发送给hdfs或者kafka。
agent和collecotr的部署
Agent1、Agent2数据分别流入到Collector1和Collector2中,Flume NG 本 身提供了 Failover 机制,可以自动切换和恢复。再由Collector1和Collector2将数据输出到hdfs中。
示意图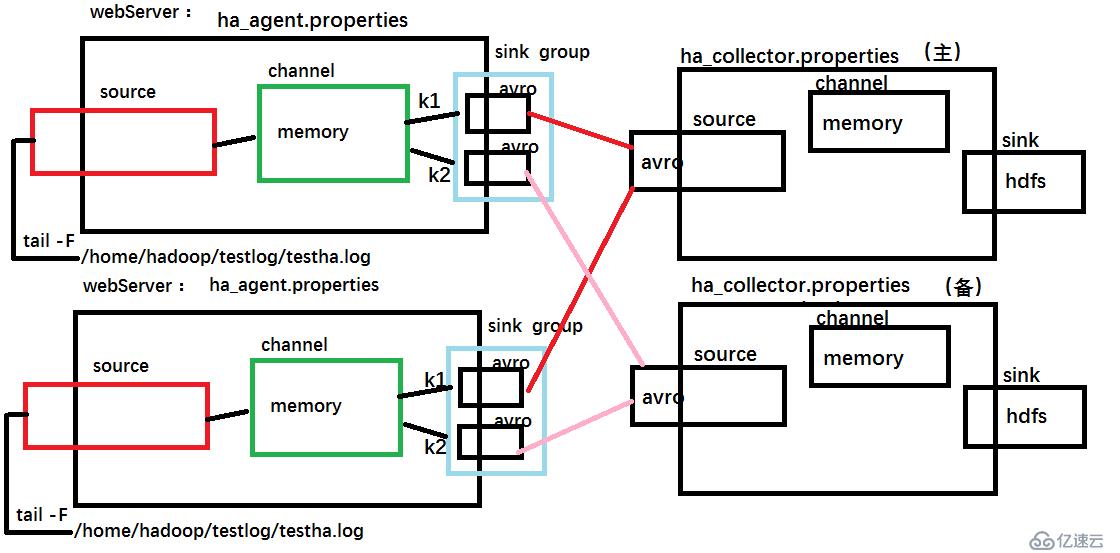
配置文件:
#ha_agent.properties
#agent name: agent1
agent1.channels = c1
agent1.sources = r1
agent1.sinks = k1 k2
#set gruop
agent1.sinkgroups = g1
#set channel
agent1.channels.c1.type = memory
agent1.channels.c1.capacity = 1000
agent1.channels.c1.transactionCapacity = 100
agent1.sources.r1.channels = c1
agent1.sources.r1.type = exec
agent1.sources.r1.command = tail -F /home/hadoop/testlog/testha.log
agent1.sources.r1.interceptors = i1 i2
agent1.sources.r1.interceptors.i1.type = static
agent1.sources.r1.interceptors.i1.key = Type
agent1.sources.r1.interceptors.i1.value = LOGIN
agent1.sources.r1.interceptors.i2.type = timestamp
#set sink1
agent1.sinks.k1.channel = c1
agent1.sinks.k1.type = avro
agent1.sinks.k1.hostname = hadoop02
agent1.sinks.k1.port = 52020
#set sink2
agent1.sinks.k2.channel = c1
agent1.sinks.k2.type = avro
agent1.sinks.k2.hostname = hadoop03
agent1.sinks.k2.port = 52020
#set sink group
agent1.sinkgroups.g1.sinks = k1 k2
#set failover
agent1.sinkgroups.g1.processor.type = failover
agent1.sinkgroups.g1.processor.priority.k1 = 10
agent1.sinkgroups.g1.processor.priority.k2 = 1
agent1.sinkgroups.g1.processor.maxpenalty = 10000#ha_collector.properties
#set agent name
a1.sources = r1
a1.channels = c1
a1.sinks = k1
#set channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#other node,nna to nns
a1.sources.r1.type = avro
##当前主机为什么,就修改成什么主机名
a1.sources.r1.bind = hadoop03
a1.sources.r1.port = 52020
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
a1.sources.r1.interceptors.i1.key = Collector
##当前主机为什么,就修改成什么主机名
a1.sources.r1.interceptors.i1.value = hadoop03
a1.sources.r1.channels = c1
#set sink to hdfs
a1.sinks.k1.type=hdfs
a1.sinks.k1.hdfs.path= hdfs://myha01/flume_ha/loghdfs
a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.writeFormat=TEXT
a1.sinks.k1.hdfs.rollInterval=10
a1.sinks.k1.channel=c1
a1.sinks.k1.hdfs.filePrefix=%Y-%m-%d最后启动:
#先启动 hadoop02 和 hadoop03 上的 collector 角色:
bin/flume-ng agent -c conf -f agentconf/ha_collector.properties -n a1 - Dflume.root.logger=INFO,console
#然后启动 hadoop01,hadoop02 上的 agent 角色:
bin/flume-ng agent -c conf -f agentconf/ha_agent.properties -n agent1 - Dflume.root.logger=INFO,console免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。