您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
介绍: hdfs是主从架构,所有为了实时的得知dataNode是否存活,必须建立心跳机制,在整个hdfs运行过程中,dataNode会定时的向nameNode发送心跳报告已告知nameNode自己的状态。
心跳内容:
- 报告自己的存活状态,每次汇报之后都会更新维护的计数信息
- 向nameNode汇报自己的存储的block列表信息
心跳报告周期:
<property>
<name>dfs.heartbeat.interval</name>
<value>3</value> //单位秒
</property> nameNode判断一个dataNode宕机的基准:连续10次接收不到dataNode的心跳信息,和2次的检查时间。
检查时间:表示在nameNode在接收不到dataNode的心跳时,此时会向dataNode主动发送检查
<property>
<name>dfs.namenode.heartbeat.recheck-interval</name>
<value>300000</value> //单位毫秒
</property>计算公式:2dfs.namenode.heartbeat.recheck-interval+10dfs.heartbeat.interval=310+3002=630s=10.5min
介绍:hdfs在启动的时候,首先会进入的安全模式中,当达到规定的要求时,会退出安全模式。在安全模式中,不能执行任何修改元数据信息的操作。
hdfs的元数据的介绍(三个部分):
- 抽象目录树
- 数据与块的对应关系(文件被切分成多少个块)
- block块存放的位置信息
hdfs元数据的存储位置:
- 内存:内存中存储了一份完整的元数据信息(抽象目录树、数据与块的对应关系、block块存放的位置信息)
- 硬盘:抽象目录树、数据与块的对应关系
注意:其中内存中的元数据的block块存放的位置信息,是通过dataNode向nameNode汇报心跳时获取的,硬盘中的元数据,是因为内存中的元数据在机器宕机时就自动消失,所以需要将内存中的元数据持久化到硬盘
而硬盘中的元数据只有抽象目录树、数据与块的对应关系,没有block块存放的位置信息
nameNode在启动的所作的操作:
集群的启动顺序:nameNode---》dataNode---》secondaryNameNode
将硬盘中的元数据信息加载内存,如果是第一次启动集群,此时会在本地生成一个fsimage镜像文件,接收dataNode汇报的心跳,将汇报中的block的位置信息,加载到内存。当然就在此时hdfs会进入安全模式。
退出安全模式的条件:
- 如果在集群启动时dfs.namenode.safemode.min.datanodes(启动的dataNode个数)为0时,并且,数据块的最小副本数dfs.namenode.replication.min为1时,此时会退出安全模式,也就是说,集群达到了最小副本数,并且能运行的datanode节点也达到了要求,此时退出安全模式
- 启动的dataNode个数为0时,并且所有的数据块的存货率达到0.999f时,集群退出安全模式(副本数达到要求)
<property>
<name>dfs.namenode.safemode.threshold-pct</name>
<value>0.999f</value>
</property>手动退出或者进入安全模式
hdfs dfsadmin -safemode enter 进入
hdfs dfsadmin -safemode leave 退出
hdfs dfsadmin -safemode get 查看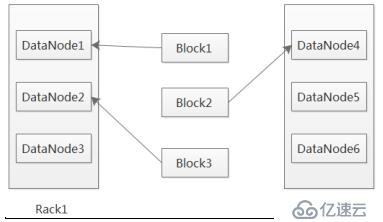
第一个副本,放置在离客户端最近的那个机架的任意节点,如果客户端是本机,那就存放在本机(保证有一个副本数),第二个副本,放置在跟第一个副本不同机架的任意节点上,第三个副本,放置在跟第二个副本相同机架的不同节点上。
修改副本的方法:
1. 修改配置文件:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>2. 命令设置: hadoop fs -setrep 2 -R dir
hdfs的负载均衡:表示每一个dataNode存储的数据与其硬件相匹配,即占用率相当
,如何手动调整负载均衡:
- 集群自动调整负载均衡的带宽:(默认为1M)
<property>
<name>dfs.datanode.balance.bandwidthPerSec</name>
<value>1048576</value> //1M
</property>- 告诉集群进行负载均衡:start-balancer.sh -t 10% 表示节点最大占用率与节点的最小的占用率之间的差值当超过10%时,此时集群不会立刻进行负载均衡,会在集群不忙的时候进行。
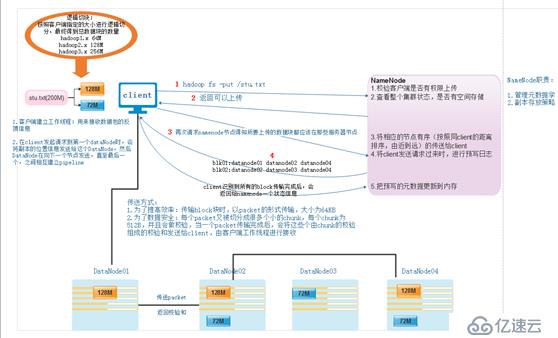
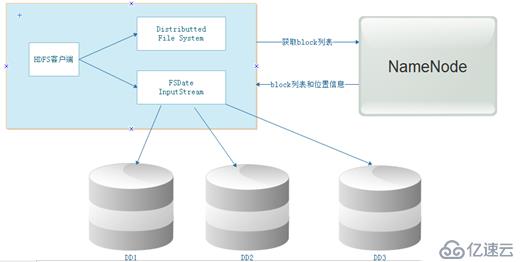
这是在分布式的基础上,secondaryNamenode对元数据的合并: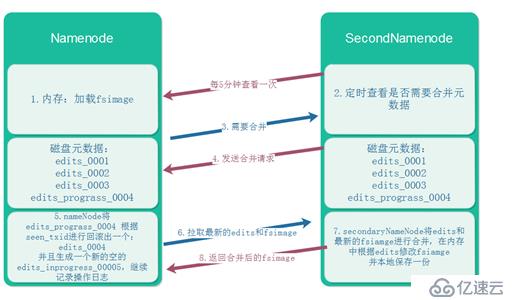
合并时机:
A:间隔多长时间合并一次
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value> //单位秒
</property>B:操作日志记录超过多少条合并一次
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
</property>免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。