您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
hadoop version //查看版本
hadoop fs -appendToFile src(Linux中的文件) dest(hdfs目录下的文件) //追加
hadoop fs -cat file(hdfs目录下的文件) //查看文件内容
Hadoop fs -tail file(hdfs目录下的文件) //查看文件末尾1kb的数据
hadoop fs -checksum file(hdfs目录下的文件) //校验当前文件是否正确
hadoop fs -copyFromLocal src dest //从本地复制文件到HDFS
hadoop fs -copyToLocal dest src //从hdfs复制文件到本地
hadoop fs -count path //对目录内容做计数
hadoop fs -find path //查看某个hdfs目录中是否相应的文件
hadoop fs -getmerge src dest //合并下载
hadoop fs -ls path //列表
hadoop fs -put file(本地) dest(hdfs) //将本地文件上传到hdfs
hadoop fs -setrep num file //设置hdfs系统中的某个文件的副本数(只能是hdfs中已上传的文件)
hadoop fs -setrep -R num file //设置hdfs系统中的目录下的所有文件的副本数
hadoop fs -text 压缩文件 //查看hdfs中的压缩文件
hadoop fs -truncate dir //清空hdfs目录
hdfs getconf -confkey [key](配置文件的name) //查看相应的配置的value
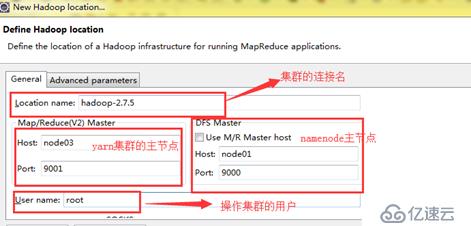

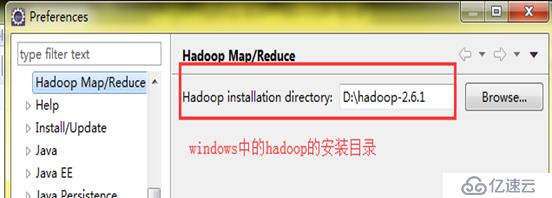
Configuration类的介绍:
Configuration类是加载hadoop中的相应的配置文件
Configuration conf=new Configuration(true);
如果在这里没有在source folder中放入相应的配置文件:
core-site.xml、hdfs-site.xml、yarn-site.xml、mapreduce-site.xml…
那么Configuration类会自动的加载jar包中的配置文件:
hadoop-hdfs-2.7.6.jar/hdfs-default.xml
只有在sourcefolder中放入相应的配置时,才能够加载相应的配置,但是配置文件的名称必须是site 或者default的文件,才能够正确加载使用相应的方法加载配置文件:
Configuration conf=new Configuration();
conf.addResource(""); //这例实参的内容为配置文件的权限定名称 FileSystem类的介绍:
获取FileSystem对象:
//以这种方式获取的fs对象是本地的文件系统的对象,如果在windows下就是windows的对象
Configuration conf=new Configuration();
FileSystem fs=FileSystem.get(conf);
//能加载自己集群的文件系统对象
conf.set("fs.defaultFS", "hdfs://hadoop01:9000");解决编程时的权限问题:
由于hdfs文件系统是基于用户的,在Windows下eclipse中操作hdfs默认的用户是Windows的用户,在操作hdfs文件系统时没有权限的,所以在做读写操作时,可能会报出:
解决方案:
(1)在运行时使用run configuration,配置相应的参数:-DHADOOP_USER_NAME=hadoop(指定运行用户)
(2)在代码中指定用户:FileSystem.get(newURI("hdfs://hadoop01:9000"),conf,"hadoop");
(3)在代码中指定jvm运行时使用的用户System.setProperty("HADOOP_USER_NAME", "hadoop"); 这里需要使用run configuration运行
(4)在Windows中添加一个hadoop用户,不建议使用
如果以上方式仍然出现问题,那么就需要在window的path中配置一个环境变量:
DHADOOP_USER_NAME = hadoop 即可。
public class HDFSApp {
//文件系统
FileSystem fileSystem = null;
//配置类
Configuration configuration = null;
@Before
public void setup() {
configuration = new Configuration();
configuration.set("fs.defautlFS", "hdfs://zzy:9000");
configuration.addResource("core-site.xml");
configuration.addResource("hdfs-site.xml");
try {
fileSystem = FileSystem.get(configuration);
} catch (IOException e) {
e.printStackTrace();
}
}
//创建目录
@Test
public void mkdir() {
try {
System.setProperty("HADOOP_USER_NAME", "hadoop");
boolean isMkdirs = fileSystem.mkdirs(new Path("/user/hadoop/test"));
if (isMkdirs) {
System.out.println("创建成功!!");
} else {
System.out.println("创建失败!!");
}
} catch (IOException e) {
e.printStackTrace();
}
}
//删除目录
@Test
public void deletedir() {
System.setProperty("HADOOP_USER_NAME", "hadoop");
try {
fileSystem.delete(new Path("/每日任务.txt"), true);
} catch (IOException e) {
e.printStackTrace();
}
}
//将本地文件copy到hdfs中
@Test
public void CopyFromeLocal() {
System.setProperty("HADOOP_USER_NAME", "hadoop");
Path src=new Path("C:\\Users\\aura-bd\\Desktop\\每日任务.txt");
Path dest=new Path("/");
try {
fileSystem.copyFromLocalFile(src,dest);
} catch (IOException e) {
e.printStackTrace();
}
}
//将hdfs文件copy到本地
@Test public void CopyToLocal(){
System.setProperty("HADOOP_USER_NAME", "hadoop");
Path src=new Path("C:\\Users\\aura-bd\\Desktop\\");
Path dest=new Path("/user/hive/warehouse/test.db/pokes/data.txt");
try {
fileSystem.copyToLocalFile(dest,src);
} catch (IOException e) {
e.printStackTrace();
}
}
//显示目录下的文件夹信息
@Test
public void FSListFile(){
try {
RemoteIterator<LocatedFileStatus> filelist = fileSystem.listFiles(new Path("/user/hive/warehouse/test.db"), true);
while(filelist.hasNext()){
LocatedFileStatus fileStatus = filelist.next();
System.out.println(fileStatus.getPath());
System.out.println(fileStatus.getGroup());
System.out.println(fileStatus.getPath().getName());
System.out.println(fileStatus.getReplication());
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
for(BlockLocation block :blockLocations){
System.out.println(block.getHosts().toString());
System.out.println(block.getNames());
System.out.println(block.getOffset());
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
//显示文件夹以及文件信息
@Test
public void ListFiles(){
try {
FileStatus[] fileStatuses = fileSystem.listStatus(new Path("/"));
for(FileStatus file:fileStatuses){
if(file.isDirectory()){
System.out.println("directory:"+file.getPath().getName());
}else{
System.out.println("file:"+file.getPath().getName());
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
//下载文件
@Test
public void DownLoadFileToLocal(){
System.setProperty("HADOOP_USER_NAME", "hadoop");
try {
FSDataInputStream open = fileSystem.open(new
Path("/user/hive/warehouse/test.db/pokes/data.txt"));
OutputStream out=new FileOutputStream(new File("D:\\data.txt"));
IOUtils.copyBytes(open,out,1024);
} catch (IOException e) {
e.printStackTrace();
}
}
//上传文件
@Test
public void upLoadFileToLocal(){
System.setProperty("HADOOP_USER_NAME", "hadoop");
try {
FSDataOutputStream fsDataOutputStream = fileSystem.create(new Path("/a.txt"));
InputStream in=new FileInputStream("D:\\data.txt");
IOUtils.copyBytes(in,fsDataOutputStream,4096);
} catch (IOException e) {
e.printStackTrace();
}
}
} 在hadoop中MR编程计算框架中,都是计算向数据移动,那么如何获取一个文件的所有block信息,指定block块进行数据读取的呢?
代码实现:
public class RamdomRead {
private static Configuration conf;
private static FileSystem fs;
static {
conf=new Configuration(true);
conf.set("fs.defalutFS","hdfs://zzy:9000");
conf.addResource("core-site.xml");
conf.addResource("hdfs-site.xml");
try {
fs=FileSystem.get(conf);
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws IOException {
System.setProperty("HADOOP_USER_NAME","hadoop");
Path file=new Path("/data/2018-8-8/access.log");
FSDataInputStream open = fs.open(file);
//拿到文件信息
try {
FileStatus[] fileStatuses = fs.listStatus(file);
// 获取这个文件的所有 block 的信息
BlockLocation[] fileBlockLocations = fs.getFileBlockLocations(fileStatuses[0], 0L, fileStatuses[0].getLen());
// 第一个 block 的长度
BlockLocation fileBlockLocation = fileBlockLocations[0];
//第一个块的长度
long length = fileBlockLocation.getLength();
//第一个 block 的起始偏移量
long offset = fileBlockLocation.getOffset();
//读取数据
byte flush[]=new byte[4096];
FileOutputStream os = new FileOutputStream(new File("d:/block0"));
while(open.read(offset,flush,0,4096)!=-1){
os.write(flush);
offset+=4096;
if(offset>length){
return ;
}
}
os.flush();
os.close();
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。