您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
废话不多说,直接上干货!!!
相关依赖:
<properties>
<project.build.sourceEncoding>UTF8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<encoding>UTF-8</encoding>
<scala.version>2.11.8</scala.version>
<spark.version>2.3.2</spark.version>
<hadoop.version>2.7.6</hadoop.version>
<scala.compat.version>2.11</scala.compat.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- sparkStreaming -->
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-streaming -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-8_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.scalikejdbc/scalikejdbc -->
<dependency>
<groupId>org.scalikejdbc</groupId>
<artifactId>scalikejdbc_2.11</artifactId>
<version>3.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>2.8.0</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>compile</scope>
</dependency>
</dependencies>编程架构: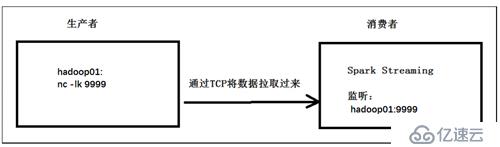
在某个节点上中启动nc -lk 9999,然后用作数据源。编写程序实现网络的wordcount。
代码实现:
object NetWordCount {
/**
* 编程套路:
* 1.获取编程入口,StreamingContext
* 2.通过StreamingContext构建第一个DStream
* 3.对DStream进行各种的transformation操作
* 4.对于数据结果进行output操作
* 5.提交sparkStreaming应用程序
*/
def main(args: Array[String]): Unit = {
//屏蔽日志
Logger.getLogger("org.apache.hadoop").setLevel(Level.ERROR)
Logger.getLogger("org.apache.zookeeper").setLevel(Level.WARN)
Logger.getLogger("org.apache.hive").setLevel(Level.WARN)
//1.获取编程入口,StreamingContext
val conf= new SparkConf().setMaster("local[2]")
.setAppName("NetWordCount")
//第二个参数,表示批处理时长
val ssc=new StreamingContext(conf,Seconds(2))
/**
* 2.通过StreamingContext构建第一个DStream(通过网络去读数据)
* 第一个参数:主机名
* 第二个参数:端口号
*/
val ReceiverInputDStream: ReceiverInputDStream[String] = ssc.socketTextStream("test",9999)
//3.对DStream进行各种的transformation操作
val wordDS: DStream[String] = ReceiverInputDStream.flatMap(msg => {
msg.split("\\s+")
})
val wordCountDS: DStream[(String, Int)] = wordDS.map(word=>(word,1)).reduceByKey(_+_)
//4.对于数据结果进行output操作,这里是打印输出
wordCountDS.print()
//5.提交sparkStreaming应用程序
ssc.start()
ssc.awaitTermination()
}
}使用nc -lk 9999在相应的节点上发出消息(每隔一个批处理时间发送一次),查看控制台打印:
batch2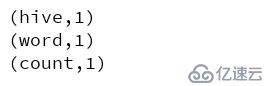
batch3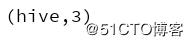
结果发现:由于现在的操作时无状态的,所以每隔2s处理一次,但是每次的单词数不会统计,也就是说,只会统计当前批处理的单词,之前输入的则不会统计。
同样是wordCounte,这次要实现的效果是:到现在为止,统计过去时间段内的所有单词的个数。
代码:
object UpdateStateBykeyWordCount {
/**
* 编程套路:
* 1.获取编程入口,StreamingContext
* 2.通过StreamingContext构建第一个DStream
* 3.对DStream进行各种的transformation操作
* 4.对于数据结果进行output操作
* 5.提交sparkStreaming应用程序
*/
def main(args: Array[String]): Unit = {
//屏蔽日志
Logger.getLogger("org.apache.hadoop").setLevel(Level.ERROR)
Logger.getLogger("org.apache.zookeeper").setLevel(Level.WARN)
Logger.getLogger("org.apache.hive").setLevel(Level.WARN)
//1.获取编程入口,StreamingContext
val conf = new SparkConf().setMaster("local[2]")
.setAppName("NetWordCount")
//第二个参数,表示批处理时长
val ssc = new StreamingContext(conf, Seconds(2))
ssc.checkpoint("C:\\z_data\\checkPoint\\checkPoint_1")
/**
* 2.通过StreamingContext构建第一个DStream(通过网络去读数据)
* 第一个参数:主机名
* 第二个参数:端口号
*/
val ReceiverInputDStream: ReceiverInputDStream[String] = ssc.socketTextStream("test", 9999)
//3.对DStream进行各种的transformation操作
val wordDS: DStream[(String,Int)] = ReceiverInputDStream.flatMap(msg => {
msg.split("\\s+")
}).map(word=>(word,1))
/**
* updateStateByKey是状态更新函数,
* updateFunc: (Seq[V], Option[S]) => Option[S]
* (U,C)=>C
* values:Seq[Int],state:Option[Int]==>Option[Int]
*
* @param values :新值
* @param state :状态值
* @return
*/
val updateDS: DStream[(String, Int)] = wordDS.updateStateByKey((values: Seq[Int], state: Option[Int]) => {
Option(values.sum + state.getOrElse(0))
})
//4.对于数据结果进行output操作,这里是打印输出
updateDS.print()
//5.提交sparkStreaming应用程序
ssc.start()
ssc.awaitTermination()
}
}使用 nc -kl 9999: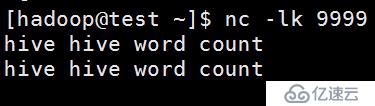
观察控制台:
batch2
batch3
发现:两次批处理的结果,进行了聚合,也就是所谓的有状态的计算。
注意:ssc.checkpoint("C:\\z_data\\checkPoint\\checkPoint_1")
上面这句代码一定要加,他会将上一次的批处理计算的结果保存起来,如果不加:
错误:requirement failed: The checkpoint directory has not been set. Please set it by StreamingContext.checkpoint().
在上述的updateStateByKey代码中如果当前程序运行异常时,会丢失数据(重启之后,找不回原来计算的数据),因为编程入口StreamingContext在代码重新运行的时候,是重新生成的,为了使程序在异常退出的时候,在下次启动的时候,依然可以获得上一次的StreamingContext对象,保证计算数据不丢失,此时就需要将StreamingContext对象存储在持久化的系统中。也就是说需要制作StreamingContext对象的HA。
代码:
object WC_DriverHA {
def main(args: Array[String]): Unit = {
//屏蔽日志
Logger.getLogger("org.apache.hadoop").setLevel(Level.ERROR)
Logger.getLogger("org.apache.zookeeper").setLevel(Level.WARN)
Logger.getLogger("org.apache.hive").setLevel(Level.WARN)
/**
* StreamingContext.getOrCreate()
* 第一个参数:checkpointPath,和下面方法中的checkpointPath目录一致
* 第二个参数:creatingFunc: () => StreamingContext:用于创建StreamingContext对象
* 最终使用StreamingContext.getOrCreate()可以实现StreamingContext对象的HA,保证在程序重新运行的时候,之前状态仍然可以恢复
*/
val ssc= StreamingContext.getActiveOrCreate("C:\\z_data\\checkPoint\\checkPoint_HA",functionToCreateContext)
ssc.start()
ssc.awaitTermination()
}
def functionToCreateContext():StreamingContext={
//1.获取编程入口,StreamingContext
val conf = new SparkConf().setMaster("local[2]")
.setAppName("NetWordCount")
//第二个参数,表示批处理时长
val ssc = new StreamingContext(conf, Seconds(2))
ssc.checkpoint("C:\\z_data\\checkPoint\\checkPoint_HA")
/**
* 2.通过StreamingContext构建第一个DStream(通过网络去读数据)
* 第一个参数:主机名
* 第二个参数:端口号
*/
val ReceiverInputDStream: ReceiverInputDStream[String] = ssc.socketTextStream("test", 9999)
//3.对DStream进行各种的transformation操作
val wordDS: DStream[(String,Int)] = ReceiverInputDStream.flatMap(msg => {
msg.split("\\s+")
}).map(word=>(word,1))
val updateDS: DStream[(String, Int)] = wordDS.updateStateByKey((values: Seq[Int], state: Option[Int]) => {
Option(values.sum + state.getOrElse(0))
})
//4.对于数据结果进行output操作,这里是打印输出
updateDS.print()
//5.提交sparkStreaming应用程序
ssc.start()
ssc.awaitTermination()
ssc
}
}测试:
- 先正常运行一段时间,计算出结果
- 停止程序
- 再次启动
- 验证再次启动的程序,是否能够拿回停止前计算得到的结果
原理:
如果是第一次执行,那么在在这个checkpointDriectory目录中是不存在streamingContext对象的,所以要创建,第二次运行的时候,就不会在创建,则是从checkpointDriectory目录中读取进行恢复。
注意:
正常情况下,使用这种方式的HA,只能持久状态数据到持久化的文件中,默认情况是不会持久化StreamingContext对象到CheckPointDriectory中的。
从故障中恢复checkpoint中有两种类型
- Metadata checkpointing:driver节点中的元数据信息
- Configuration:用于创建流式应用程序的配置
- DStream:定义streaming程序的DStream操作
- Incomplete batches:批量的job排队但尚未完成。(程序上次运行到的位置)
- Data checkpointing:将生成的RDD保存到可靠的存储
- 计算之后生成的RDD
- 在receiver接收到数据,转化的RDD
- 从运行应用程序的driver的故障中恢复-元数据,(driver的HA)
- 使用有状态计算的时候启动checkPoint:updateStateByKey或者reduceByKeyAndWindow…
- 有状态计算的时候:
ssc.checkpoint("C:\\z_data\\checkpoint")
- driver的HA的时候:
ssc.checkpoint("C:\\z_data\\checkpoint")
ssc =StreamingContext.getOrCreate("C:\\z_data\\checkpoint"
,functionToCreateContext) 在使用transform操作的时候介绍两个重要的概念:
黑名单:如果允许的操作比不允许的操作多,那么将不允许的操作加入黑名单
白名单:如果允许的操作比不允许的操作少,那么将允许的操作加入白名单
代码:
object _1Streaming_tranform {
def main(args: Array[String]): Unit = {
//定义黑名单
val black_list=List("@","#","$","%")
Logger.getLogger("org.apache.hadoop").setLevel(Level.ERROR)
Logger.getLogger("org.apache.zookeeper").setLevel(Level.WARN)
Logger.getLogger("org.apache.hive").setLevel(Level.WARN)
//1.获取编程入口,StreamingContext
val conf = new SparkConf().setMaster("local[2]").setAppName("_1Streaming_tranform")
val ssc=new StreamingContext(conf,Seconds(2))
//2.从对应的网络端口读取数据
val inputDStream: ReceiverInputDStream[String] = ssc.socketTextStream("test",9999)
//2.1将黑名单广播出去
val bc = ssc.sparkContext.broadcast(black_list)
//2.2设置checkpoint
ssc.checkpoint("C:\\z_data\\checkPoint\\checkPoint_1")
//3业务处理
val wordDStream: DStream[String] = inputDStream.flatMap(_.split(" "))
//transform方法表示:从DStream拿出来一个RDD,经过transformsFunc计算之后,返回一个新的RDD
val fileterdDStream: DStream[String] = wordDStream.transform(rdd=>{
//过滤掉黑名单中的数据
val blackList: List[String] = bc.value
rdd.filter(word=>{
!blackList.contains(word)
})
})
//3.2统计相应的单词数
val resultDStream = fileterdDStream.map(msg => (msg, 1))
.updateStateByKey((values: Seq[Int], stats: Option[Int]) => {
Option(values.sum + stats.getOrElse(0))
})
//4打印output
resultDStream.print()
//5.开启streaming流
ssc.start()
ssc.awaitTermination()
}
}黑名单中的数据会被过滤: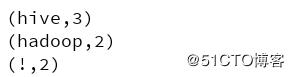
注意:
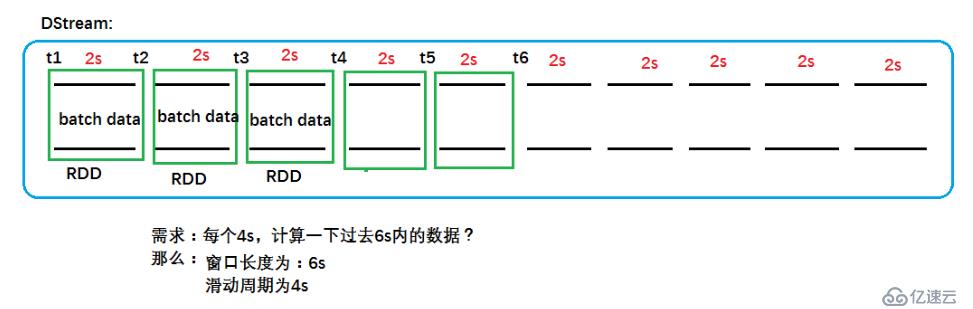
在做window操作时:
- 窗口覆盖的数据流的时间长度,必须是批处理时间间隔的倍数
- 前一个窗口到后一个窗口所经过的时间长度,必须是批处理时间间隔的倍数。
伪代码:
//1.获取编程入口,StreamingContext
val conf = new SparkConf().setMaster("local[2]").setAppName("WordCount_Window")
val ssc=new StreamingContext(conf,Seconds(batchInvail.toLong))
//2.从对应的网络端口读取数据
val inputDStream: ReceiverInputDStream[String] = ssc.socketTextStream(hostname,port.toInt)
val lineDStream: DStream[String] = inputDStream.flatMap(_.split(" "))
val wordDStream: DStream[(String, Int)] = lineDStream.map((_,1))
/**
* 每隔4秒,算过去6秒的数据
* reduceFunc:数据合并的函数
* windowDuration:窗口的大小(过去6秒的数据)
* slideDuration:窗口滑动的时间(每隔4秒)
*/
val resultDStream: DStream[(String, Int)] = wordDStream.reduceByKeyAndWindow((kv1:Int, kv2:Int)=>kv1+kv2,
Seconds(batchInvail.toLong * 3),
Seconds(batchInvail.toLong * 2))
resultDStream.print()
ssc.start()
ssc.awaitTermination()概念:
//这个方法表示遍历DStream中的每一个rdd
windowDS.foreachRDD(rdd=>{
if(!rdd.isEmpty()){
rdd.mapPartitions(ptn=>{
if(!ptn.isEmpty){
ptn.foreach(msg=>{
//在这里做相应的操作
})
}
})
}
})免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。