жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
вҖңдёӘж•°вҖқжҳҜвҖңдёӘжҺЁвҖқж——дёӢйқўеҗ‘ APP ејҖеҸ‘иҖ…жҸҗдҫӣж•°жҚ®з»ҹи®ЎеҲҶжһҗзҡ„дә§е“ҒгҖӮвҖңдёӘж•°вҖқйҖҡиҝҮеҸҜи§ҶеҢ–еҹӢзӮ№жҠҖжңҜеҸҠеӨ§ж•°жҚ®еҲҶжһҗиғҪеҠӣд»Һз”ЁжҲ·еұһжҖ§гҖҒжё йҒ“иҙЁйҮҸгҖҒиЎҢдёҡеҜ№жҜ”зӯүз»ҙеәҰеҜ№ APP иҝӣиЎҢе…Ёйқўзҡ„з»ҹи®ЎеҲҶжһҗгҖӮ
вҖңдёӘж•°вҖқдёҚд»…еҸҜд»ҘеҸҠж—¶з»ҹи®Ўз”ЁжҲ·зҡ„жҙ»и·ғгҖҒж–°еўһзӯүпјҢиҝҳеҸҜд»ҘеҲҶжһҗеҚёиҪҪз”ЁжҲ·зҡ„жҲҗеҲҶгҖҒжөҒеҗ‘пјҢжӯӨеӨ–иҝҳиғҪе®һзҺ°жөҒеӨұгҖҒд»ҳиҙ№зӯүз”ЁжҲ·е…ій”®иЎҢдёәзҡ„йў„жөӢпјҢд»ҺиҖҢеё®еҠ© APP ејҖеҸ‘иҖ…е®һзҺ°з”ЁжҲ·зІҫз»ҶеҢ–иҝҗиҗҘе’Ңе…Ёз”ҹе‘Ҫе‘Ёжңҹз®ЎзҗҶгҖӮе…¶дёӯеҫҲеҖјеҫ—дёҖжҸҗзҡ„жҳҜпјҢвҖңдёӘж•°вҖқеңЁвҖңеҸҜи§ҶеҢ–еҹӢзӮ№вҖқеҸҠвҖңиЎҢдёәйў„жөӢвҖқж–№йқўзҡ„еҲӣж–°пјҢдёә APP ејҖеҸ‘иҖ…еңЁе®һйҷ…иҝҗиҗҘдёӯеёҰжқҘдәҶжһҒеӨ§дҫҝеҲ©пјҢжүҖд»ҘпјҢеңЁдёӢж–ҮдёӯпјҢжҲ‘们д№ҹе°Ҷеӣҙз»•иҝҷдёӨзӮ№еҒҡиҜҰз»Ҷзҡ„еҲҶжһҗгҖӮ
еҹӢзӮ№жҳҜжҢҮеңЁдә§е“ҒжөҒзЁӢзҡ„е…ій”®йғЁдҪҚжӨҚе…Ҙзӣёе…із»ҹи®Ўд»Јз ҒпјҢд»ҘиҝҪиёӘз”ЁжҲ·иЎҢдёәпјҢз»ҹи®Ўе…ій”®жөҒзЁӢзҡ„дҪҝз”ЁзЁӢеәҰпјҢ并е°Ҷж•°жҚ®д»Ҙж—Ҙеҝ—зҡ„ж–№ејҸдёҠжҠҘиҮіжңҚеҠЎеҷЁзҡ„иҝҮзЁӢгҖӮ
зӣ®еүҚпјҢж•°жҚ®еҹӢзӮ№йҮҮйӣҶжЁЎејҸдё»иҰҒжңүд»Јз ҒеҹӢзӮ№гҖҒж— еҹӢзӮ№гҖҒеҸҜи§ҶеҢ–еҹӢзӮ№зӯүж–№ејҸгҖӮ
вҖңд»Јз ҒеҹӢзӮ№вҖқжҳҜжҢҮеңЁзӣ‘жҺ§йЎөйқўдёҠеҠ е…ҘеҹәзЎҖ jsпјҢж №жҚ®йңҖжұӮж·»еҠ зӣ‘жҺ§д»Јз ҒпјҢе®ғзҡ„дјҳзӮ№жҳҜзҒөжҙ»пјҢеҸҜд»ҘиҮӘе®ҡд№үи®ҫзҪ®пјҢеҸҜд»ҘйҖүжӢ©иҮӘе·ұйңҖиҰҒзҡ„ж•°жҚ®жқҘеҲҶжһҗпјҢдҪҶеҜ№еӨҚжқӮзҪ‘з«ҷжқҘиҜҙпјҢжҜҸж¬Ўдҝ®ж”№дёҖдёӘйЎөйқўе°ұеҫ—йҮҚж–°еҮәдёҖд»ҪеҹӢзӮ№ж–№жЎҲпјҢжҲҗжң¬иҫғеӨ§гҖӮзӣ®еүҚпјҢйҮҮз”Ёиҝҷз§ҚеҹӢзӮ№ж–№жЎҲзҡ„д»ЈиЎЁдә§е“ҒжңүзҷҫеәҰз»ҹи®ЎгҖҒеҸӢзӣҹгҖҒи…ҫи®Ҝдә‘еҲҶжһҗгҖҒGoogle Analytics зӯүгҖӮ
вҖңеҸҜи§ҶеҢ–еҹӢзӮ№вҖқйҖҡеёёжҳҜжҢҮејҖеҸ‘иҖ…йҖҡиҝҮи®ҫеӨҮиҝһжҺҘз”ЁжҲ·иЎҢдёәеҲҶжһҗе·Ҙе…·пјҢзӣҙжҺҘеңЁж•°жҚ®жҺҘе…Ҙз®ЎзҗҶз•ҢйқўдёҠеҜ№еҸҜдәӨдә’дё”дәӨдә’еҗҺжңүж•Ҳжһңзҡ„йЎөйқўе…ғзҙ пјҲеҰӮпјҡеӣҫзүҮгҖҒжҢүй’®гҖҒй“ҫжҺҘзӯүпјүиҝӣиЎҢж“ҚдҪңе®һзҺ°ж•°жҚ®еҹӢзӮ№пјҢдёӢеҸ‘йҮҮйӣҶд»Јз Ғз”ҹж•Ҳеӣһж•°зҡ„еҹӢзӮ№ж–№ејҸгҖӮзӣ®еүҚпјҢеҸҜи§ҶеҢ–еҹӢзӮ№зҡ„д»ЈиЎЁдә§е“ҒжңүдёӘж•°гҖҒMixpanelгҖҒзҘһзӯ–ж•°жҚ®зӯүгҖӮ
вҖңж— еҹӢзӮ№вҖқдёҺвҖңе…ЁеҹӢзӮ№вҖқзӣёдјјпјҢе®ғзҡ„еҺҹзҗҶжҳҜвҖңе…ЁйғЁйҮҮйӣҶпјҢжҢүйңҖйҖүеҸ–вҖқпјҢд№ҹе°ұжҳҜиҜҙе®ғеҸҜд»ҘеҜ№йЎөйқўдёӯжүҖжңүдәӨдә’е…ғзҙ зҡ„з”ЁжҲ·иЎҢдёәиҝӣиЎҢйҮҮйӣҶпјҢе®ғжҳҜе…Ҳе°ҪеҸҜиғҪеӨҡ收йӣҶжЈҖжөӢйЎөйқўзҡ„еҶ…е®№пјҢ然еҗҺеҶҚйҖҡиҝҮз•Ңйқўй…ҚзҪ®еҶіе®ҡеҲҶжһҗе“Әдәӣж•°жҚ®пјҢдҪҶе®ғжҳҜж ҮеҮҶеҢ–йҮҮйӣҶпјҢеҰӮжһңйңҖиҰҒи®ҫзҪ®иҮӘе®ҡд№үзҡ„йҮҮйӣҶж–№ејҸд»ҚйңҖиҰҒд»Јз ҒеҹӢзӮ№еҠ©еҠӣгҖӮиҝҷз§Қж–№жЎҲзҡ„д»ЈиЎЁдә§е“Ғжңү GrowingIOгҖҒж•°жһҒе®ўгҖҒзҷҫеәҰз»ҹи®ЎзӯүгҖӮ
еҪ“дёӢ移еҠЁдә’иҒ”зҪ‘жӯЈеӨ„дәҺй«ҳйҖҹеҸ‘еұ•дё”еҸ‘еұ•еҪўеҠҝзһ¬жҒҜдёҮеҸҳзҡ„йҳ¶ж®өдёӯпјҢејҖеҸ‘иҖ…йңҖиҰҒеҸҠж—¶ж №жҚ®еӨ§ж•°жҚ®зҡ„еҲҶжһҗгҖҒеҸҚйҰҲпјҢеҜ№дёҡеҠЎеҠҹиғҪзӯүеҒҡеҮәи°ғж•ҙпјҢеңЁдј з»ҹзҡ„ж“ҚдҪңжЁЎејҸдёӯпјҢеҰӮжһңжғіиҰҒдәҶи§ЈдёҚеҗҢиҠӮзӮ№зҡ„ж•°жҚ®пјҢе°ұиҰҒдҝ®ж”№зӣёеә”д»Јз ҒйҮҢйқўзҡ„еҹӢзӮ№пјҢ然еҗҺжөӢиҜ•еҸ‘еёғпјҢд№ӢеҗҺеҶҚеңЁеә”з”Ёе•Ҷеә—е®Ўж ёгҖҒдёҠзәҝпјҢж•ҙдёӘе‘ЁжңҹеҸҜиғҪй•ҝиҫҫеҮ дёӘжҳҹжңҹпјҢиҝҷжҳҫз„¶ж— жі•ж»Ўи¶ідёҡеҠЎзҡ„йңҖжұӮгҖӮжүҖд»ҘпјҢвҖңдёӘж•°вҖқйҮҮз”Ёзҡ„вҖңеҸҜи§ҶеҢ–еҹӢзӮ№вҖқжҠҖжңҜе°ұжҳҜдёәдәҶеё®еҠ©ејҖеҸ‘иҖ…и§ЈеҶіиҝҷдёӘй—®йўҳзҡ„гҖӮ
вҖңдёӘж•°вҖқзҡ„еҸҜи§ҶеҢ–еҹӢзӮ№зҒөжҙ»гҖҒж–№дҫҝпјҢдёҚйңҖеҜ№ж•°жҚ®иҝҪиёӘзӮ№ж·»еҠ д»»дҪ•д»Јз ҒпјҢдҪҝз”ЁиҖ…еҸӘйңҖиҰҒйҖҡиҝҮи®ҫеӨҮиҝһжҺҘз®ЎзҗҶеҸ°пјҢеҜ№йЎөйқўеҸҜеҹӢзӮ№зҡ„е…ғзҙ еңҲеңҲзӮ№зӮ№пјҢеҚіеҸҜж·»еҠ йҡҸж—¶з”ҹж•Ҳзҡ„з•ҢйқўиҝҪиёӘзӮ№пјҢеҗҢж—¶еңЁж•°жҚ®йҮҮйӣҶжЁЎејҸеҸҠж•°жҚ®еҲҶжһҗиғҪеҠӣдёҠпјҢвҖңдёӘж•°вҖқиғҪеӨҹжҸҗдҫӣз»ҷејҖеҸ‘иҖ…们еҮҶзЎ®зҡ„гҖҒжңүж•Ҳзҡ„ж•°жҚ®гҖӮ
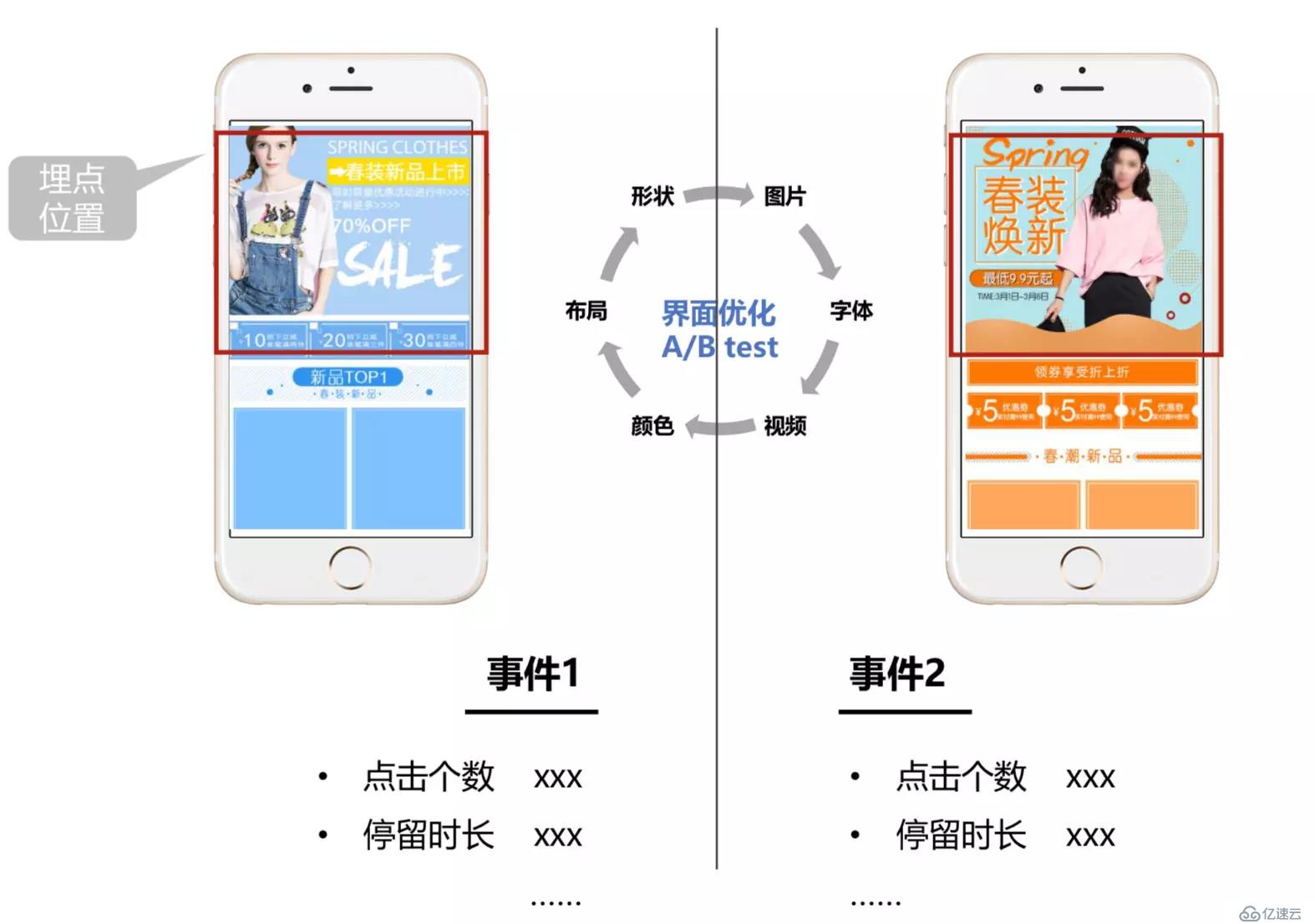
еҸҜи§ҶеҢ–еҹӢзӮ№дё»иҰҒе…·жңүд»ҘдёӢзү№жҖ§пјҡ
1гҖҒйӣ¶д»Јз ҒпјҢж— йңҖд»Јз ҒпјҢиҠӮзңҒжҲҗжң¬
2гҖҒе…Қжӣҙж–°пјҢж–°еўһдҫҝжҚ·пјҢж— йңҖеҚҮзә§
3гҖҒжҳ“жөӢиҜ•пјҢеңҲйҖүжөӢиҜ•пјҢе®һж—¶е‘ҲзҺ°
жҚўиҖҢиЁҖд№ӢпјҢеҸҜи§ҶеҢ–еҹӢзӮ№дёҚд»…еҸҜд»ҘиҠӮзәҰдјҒдёҡжҲҗжң¬пјҢиҝҳеҸҜд»ҘжҸҗй«ҳејҖеҸ‘дәәе‘ҳе’ҢиҝҗиҗҘдәәе‘ҳзҡ„е·ҘдҪңж•ҲзҺҮгҖӮ
вҖңдёӘж•°вҖқзҡ„иЎҢдёәйў„жөӢдё»иҰҒеҢ…жӢ¬жөҒеӨұйў„жөӢгҖҒеҚёиҪҪйў„жөӢгҖҒд»ҳиҙ№йў„жөӢзӯүпјҢе®ғзҡ„еҺҹзҗҶжҳҜеҹәдәҺ App еҺҶеҸІиЎҢдёәж•°жҚ®жһ„е»әз®—жі•жЁЎеһӢйў„жөӢз”ЁжҲ·е…ій”®иЎҢдёәпјҢд»ҺиҖҢеё®еҠ©ејҖеҸ‘иҖ…иҫҫеҲ°з”ЁжҲ·зІҫз»ҶеҢ–иҝҗиҗҘе’Ңе…Ёз”ҹе‘Ҫе‘Ёжңҹз®ЎзҗҶзҡ„зӣ®зҡ„гҖӮ
еңЁиҝҷйҮҢйңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢвҖңдёӘж•°вҖқзҡ„иЎҢдёәйў„жөӢдёҺз”өе•Ҷе№іеҸ°еёёз”Ёзҡ„дёӘжҖ§еҢ–жҺЁиҚҗдёҚеҗҢпјҢеҗҺиҖ…дё»иҰҒжҳҜеҹәдәҺз”ЁжҲ·иҝ‘жңҹзҡ„иЎҢдёәпјҢеҰӮжөҸи§Ҳи®°еҪ•гҖҒиҙӯд№°и®°еҪ•иҖҢеҲҶжһҗеҮәз”ЁжҲ·еҸҜиғҪйңҖиҰҒзҡ„дёңиҘҝпјҢиҖҢвҖңдёӘж•°вҖқжҳҜеҹәдәҺ App еҗ„жё йҒ“еҚёиҪҪж•°гҖҒеҚёиҪҪи¶ӢеҠҝзӯүжҢҮж Үзҡ„з»јеҗҲеҲҶжһҗпјҢжӣҙеӨҡзҡ„жҳҜеҜ№дәәзҫӨзҡ„иҒҡзұ»еҲҶжһҗпјҢиҖҢйқһд»…д»…еҹәдәҺдёӘдәәзҡ„иЎҢдёәгҖӮ
жҚ®вҖңдёӘжҺЁвҖқеӨ§ж•°жҚ®з§‘еӯҰ家жңұйҮ‘жҳҹд»Ӣз»ҚпјҢвҖңдёӘж•°вҖқзҡ„иЎҢдёәйў„жөӢдё»иҰҒеҲҶдёәд»ҘдёӢеҮ дёӘжӯҘйӘӨпјҡ
1гҖҒжүҫж ·жң¬пјҢдё»иҰҒд»ҺеҺҶеҸІж•°жҚ®еә“дёӯжҠҪеҸ–пјӣ
2гҖҒзү№еҫҒжҠҪеҸ–пјҢе°Ҷз”ЁжҲ·дёҺж•°жҚ®еә“жү“йҖҡпјҢеҒҡеҢ№й…Қпјӣ
3гҖҒзү№еҫҒзӯӣйҖүпјҢдҝқз•ҷзӣёе…іжҖ§й«ҳзҡ„жҲ–жңүд»·еҖјзҡ„зү№еҫҒпјӣ
4гҖҒжЁЎеһӢи®ӯз»ғпјҢе°Ҷдҝқз•ҷдёӢжқҘзҡ„зү№еҫҒж”ҫеҲ°жЁЎеһӢдёӯи®ӯз»ғпјҢеңЁжЁЎеһӢзҡ„йҖүз”ЁдёҠпјҢвҖңдёӘж•°вҖқдё»иҰҒз”ЁдәҶйҖ»иҫ‘еӣһеҪ’пјҢйҖ»иҫ‘еӣһеҪ’зҡ„жЁЎеһӢзӣёеҜ№ж·ұеәҰеӯҰд№ зӯүе…¶д»–жЁЎеһӢжқҘиҜҙпјҢз®ҖеҚ•дёҖдәӣпјҢиҖҢдё”еңЁзү№еҫҒзӯӣйҖүдёҠзӣёеҜ№еҘҪеӨ„зҗҶпјҢеҫ—еҲ°зҡ„з»“жһңеҘҪи§ЈйҮҠпјҢд№ҹзӣёеҜ№зЁіе®ҡгҖӮ
5гҖҒеҸӮж•°дјҳеҢ–пјҢж №жҚ®ж•ҲжһңиҝӣиЎҢи°ғж•ҙпјҢеҰӮжһңз»“жһңдёҚзҗҶжғіпјҢеҚіеҸҜиҝ”еӣһи°ғж•ҙеҸӮж•°йҮҚж–°иө°дёҖж¬Ўд»ҘдёҠжөҒзЁӢгҖӮ
дёӢйқўжҲ‘们д»Ҙд»ҳиҙ№йў„жөӢдёәдҫӢпјҢдёәеӨ§е®¶жўізҗҶдёҖдёӢе…·дҪ“зҡ„е®һзҺ°иҝҮзЁӢгҖӮ
дёӘж•°д»ҳиҙ№йў„жөӢзҡ„жөҒзЁӢдё»иҰҒеҢ…жӢ¬д»ҘдёӢеҮ зӮ№пјҡ
1гҖҒзӣ®ж Үй—®йўҳеҲҶи§Ј
жҳҺзЎ®йңҖиҰҒиҝӣиЎҢйў„жөӢзҡ„й—®йўҳеҚід»ҳиҙ№йў„жөӢпјҢд»ҘеҸҠжңӘжқҘдёҖж®өж—¶й—ҙзҡ„и·ЁеәҰгҖӮ
2гҖҒеҲҶжһҗж ·жң¬ж•°жҚ®
пјҲ1пјүжҸҗеҸ–еҮәжүҖжңүз”ЁжҲ·зҡ„еҺҶеҸІд»ҳиҙ№и®°еҪ•пјӣ
пјҲ2пјүеҲҶжһҗд»ҳиҙ№и®°еҪ•пјҢдәҶи§Јд»ҳиҙ№з”ЁжҲ·зҡ„жһ„жҲҗпјҢжҜ”еҰӮе№ҙйҫ„еұӮж¬ЎгҖҒжҖ§еҲ«гҖҒиҙӯд№°еҠӣе’Ңж¶Ҳиҙ№зҡ„дә§е“Ғзұ»еҲ«зӯүпјӣ
пјҲ3пјүжҸҗеҸ–йқһд»ҳиҙ№з”ЁжҲ·зҡ„еҺҶеҸІж•°жҚ®пјҢиҝҷйҮҢеҸҜд»Ҙж №жҚ®дә§е“Ғзҡ„йңҖжұӮпјҢж·»еҠ жқЎд»¶гҖҒжҲ–ж— жқЎд»¶ең°иҝӣиЎҢжҸҗеҸ–пјҢжҜ”еҰӮжҸҗеҸ–жҙ»и·ғ并且йқһд»ҳиҙ№з”ЁжҲ·пјҢжҲ–иҖ…дёҚеҠ жқЎд»¶ең°зӣҙжҺҘиҝӣиЎҢжҸҗеҸ–пјӣ
пјҲ4пјүеҲҶжһҗйқһд»ҳиҙ№з”ЁжҲ·зҡ„жһ„жҲҗгҖӮ
3гҖҒжһ„е»әжЁЎеһӢзҡ„зү№еҫҒ
пјҲ1пјүеҺҹе§Ӣзҡ„ж•°жҚ®еҸҜиғҪиғҪеӨҹзӣҙжҺҘдҪңдёәзү№еҫҒдҪҝз”Ёпјӣ
пјҲ2пјүжңүдәӣж•°жҚ®еңЁеҸҳжҚўеҗҺпјҢжүҚдјҡжңүжӣҙеҘҪзҡ„дҪҝз”Ёж•ҲжһңпјҢжҜ”еҰӮе№ҙйҫ„пјҢеҸҜд»ҘеҸҳжҚўжҲҗе°‘е№ҙгҖҒдёӯе№ҙгҖҒиҖҒе№ҙзӯүзү№еҫҒпјӣ
пјҲ3пјүдәӨеҸүзү№еҫҒзҡ„з”ҹжҲҗпјҢжҜ”еҰӮвҖңдёӯе№ҙвҖқе’ҢвҖңеҘіжҖ§вҖқдёӨз§Қзү№еҫҒпјҢе°ұеҸҜд»ҘеҗҲ并дёәдёҖдёӘзү№еҫҒиҝӣиЎҢдҪҝз”ЁгҖӮ
4гҖҒи®Ўз®—зү№еҫҒзҡ„зӣёе…іжҖ§
пјҲ1пјүи®Ўз®—зү№еҫҒйҘұе’ҢеәҰпјҢиҝӣиЎҢйҘұе’ҢеәҰиҝҮж»Өпјӣ
пјҲ2пјүи®Ўз®—зү№еҫҒ IVгҖҒеҚЎж–№зӯүжҢҮж ҮпјҢз”Ёд»ҘиҝӣиЎҢзү№еҫҒзӣёе…іжҖ§зҡ„иҝҮж»ӨгҖӮ
5гҖҒйҖүз”ЁйҖ»иҫ‘еӣһеҪ’иҝӣиЎҢе»әжЁЎ
пјҲ1пјүйҖүжӢ©йҖӮеҪ“зҡ„еҸӮж•°иҝӣиЎҢе»әжЁЎпјӣ
пјҲ2пјүжЁЎеһӢи®ӯз»ғеҘҪеҗҺпјҢз»ҹи®ЎжЁЎеһӢзҡ„зІҫзЎ®еәҰгҖҒеҸ¬еӣһзҺҮгҖҒAUC зӯүжҢҮж ҮпјҢжқҘиҜ„д»·жЁЎеһӢпјӣ
пјҲ3пјүеҰӮжһңи§үеҫ—жЁЎеһӢзҡ„иЎЁзҺ°еҸҜд»ҘжҺҘеҸ—пјҢе°ұеҸҜд»ҘеңЁйӘҢиҜҒйӣҶдёҠеҒҡйӘҢиҜҒпјҢйӘҢиҜҒйҖҡиҝҮеҗҺпјҢиҝӣиЎҢжЁЎеһӢдҝқеӯҳе’Ңйў„жөӢгҖӮ
6гҖҒйў„жөӢ
еҠ иҪҪдёҠиҝ°дҝқеӯҳзҡ„жЁЎеһӢпјҢ并еҠ иҪҪйў„жөӢж•°жҚ®пјҢиҝӣиЎҢйў„жөӢгҖӮ
7гҖҒзӣ‘жҺ§
жңҖеҗҺпјҢиҝҗиҗҘдәәе‘ҳиҝҳйңҖиҰҒеҜ№жҜҸж¬Ўйў„жөӢзҡ„з»“жһңиҝӣиЎҢе…ій”®жҢҮж Үзӣ‘жҺ§пјҢеҸҠж—¶еҸ‘зҺ°е№¶и§ЈеҶіеҮәзҺ°зҡ„й—®йўҳпјҢйҳІжӯўеҮәзҺ°ж„ҸеӨ–жғ…еҶөпјҢеҜјиҮҙйў„жөӢж— ж•ҲжҲ–йў„жөӢз»“жһңеҮәзҺ°еҒҸе·®гҖӮ
е…¶д»–еңәжҷҜеҰӮжөҒеӨұйў„жөӢгҖҒеҚёиҪҪйў„жөӢзӯүпјҢеңЁжөҒзЁӢдёҠдёҺд»ҳиҙ№йў„жөӢзұ»дјјпјҢжүҖд»ҘеңЁиҝҷйҮҢе°ұдёҚеҶҚдёҖдёҖд»Ӣз»ҚдәҶгҖӮ
жңүдәҶзІҫеҮҶзҡ„иЎҢдёәйў„жөӢпјҢиҝҗиҗҘиҖ…еҲҷеҸҜд»Ҙе°ҶиҝҗиҗҘзӣ®ж ҮиҝӣиЎҢжӢҶеҲҶгҖҒз»ҶеҢ–пјҢе…·дҪ“еҲ°жҜҸдёӘеңәжҷҜгҖҒжҜҸдёӘжөҒзЁӢпјҢй’ҲеҜ№дёҚеҗҢз”ЁжҲ·йҮҮеҸ–дёҚеҗҢзҡ„жҺЁе№ҝжё йҒ“гҖҒиҝҗиҗҘзӯ–з•ҘгҖӮдҫӢеҰӮеҹәдәҺжөҒеӨұйў„жөӢпјҢиҝҗиҗҘиҖ…иғҪеӨҹжҸҗеүҚжҙһеҜҹеҲ°з”ЁжҲ·жөҒеӨұиЎҢдёәпјҢжҸҗж—©иҝӣиЎҢе№Ійў„пјҢйҖҡиҝҮдёӘжҖ§еҢ–еҶ…е®№жҺЁиҚҗгҖҒж¶ҲжҒҜжҺЁйҖҒзӯүиҝҗиҗҘжүӢж®өеҜ№еҚіе°ҶжөҒеӨұзҡ„з”ЁжҲ·иҝӣиЎҢжҢҪз•ҷпјҢд»ҺиҖҢйҷҚдҪҺжөҒеӨұзҺҮгҖӮжҖ»зҡ„жқҘиҜҙпјҢеңЁеӨ§ж•°жҚ®иЎҢдёәйў„жөӢзҡ„её®еҠ©дёӢпјҢиҝҗиҗҘиҖ…иғҪеӨҹжӣҙеҸҠж—¶гҖҒжӣҙе…Ёйқўең°дәҶи§Јз”ЁжҲ·пјҢд»ҺиҖҢиҫҫеҲ°зІҫз»ҶеҢ–иҝҗиҗҘзҡ„зӣ®зҡ„гҖӮ
жҺҘдёӢжқҘвҖңдёӘж•°вҖқиҝҳе°ҶеңЁе•Ҷе“ҒжҺЁиҚҗзӯүйўҶеҹҹеҒҡжӣҙеӨҡзҡ„жҺўзҙўпјҢдҫӢеҰӮејҖеҸ‘зІҫеҮҶзҡ„жҺЁиҚҗжҠҖжңҜзӯүпјҢд№ҹдјҡдёҚж–ӯжҢ–жҺҳеӨ§ж•°жҚ®зҡ„жҪңеҠӣпјҢз»“еҗҲеҸҚйҰҲзҡ„ж•°жҚ®еҒҡиҝӣдёҖжӯҘзҡ„дјҳеҢ–пјҢеӣҙз»•е®ўжҲ·жҸҗдҫӣзҡ„ж ·жң¬ж•°жҚ®еҒҡжӣҙж·ұе…Ҙзҡ„и®ӯз»ғеӯҰд№ зӯүпјҢдёәејҖеҸ‘иҖ…жҸҗдҫӣжӣҙе…Ёйқўзҡ„еӨ§ж•°жҚ®жңҚеҠЎпјҢеӨ§е®¶ж•¬иҜ·жңҹеҫ…гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ