жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
1. йӣҶзҫӨзҡ„и§’иүІжҸҸиҝ°пјҡ
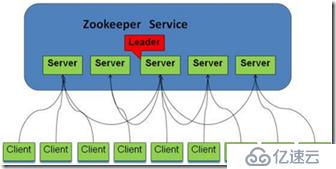
и§’иүІ | жҸҸиҝ° |
йўҶеҜјиҖ…пјҲleaderпјү | йўҶеҜјиҖ…иҙҹиҙЈиҝӣиЎҢе…¬еёғеҶіи®®пјҢдё»иҰҒеӨ„зҗҶеҶҷиҜ·жұӮ |
и·ҹйҡҸиҖ…пјҲfollowerпјү | Followerз”ЁдәҺжҺҘ收客жҲ·з«ҜиҜ·жұӮ并еҗ‘е®ўжҲ·з«Ҝиҝ”еӣһз»“жһңпјҲеҸӘиғҪеӨ„зҗҶиҜ»иҜ·жұӮпјҢеҰӮжһңжҺҘ收еҲ°еҶҷиҜ·жұӮпјҢ е°ҶеҶҷиҜ·жұӮиҪ¬еҸ‘з»ҷleaderпјүпјҢеҪ“leaderе®•жңәж—¶пјҢеҸ‘иө·йҖүдё»пјҢжңүжҠ•зҘЁе’Ңиў«жҠ•зҘЁжқғ |
и§ӮеҜҹиҖ…пјҲobserverпјү | ObserverеҸҜд»ҘжҺҘ收客жҲ·з«ҜиҝһжҺҘпјҢе°ҶеҶҷиҜ·жұӮиҪ¬еҸ‘з»ҷleaderиҠӮзӮ№пјҢеё®еҠ©followerеҮҸиҪ»иҜ»зҡ„еҺӢеҠӣгҖӮ дҪҶObserverдёҚеҸӮеҠ йҖүдёҫе’Ңиў«йҖүдёҫгҖӮObserverзҡ„зӣ®еҪ•жҳҜдёәдәҶжү©еұ•зі»з»ҹпјҢжҸҗй«ҳиҜ»еҸ–йҖҹеәҰ |
е®ўжҲ·з«Ҝ | иҜ·жұӮеҸ‘иө·ж–№ |
2. zookeeperзҡ„йҖүдё»иҝҮзЁӢ
пјҲ1пјүе…Ёж–°йӣҶзҫӨзҡ„йҖүдё»пјҡ
ж №жҚ®еҗҜеҠЁзҡ„йЎәеәҸе’ҢidиҝӣиЎҢйҖүдё»пјҲиҝҮеҚҠжңәеҲ¶пјҡйӣҶзҫӨдёӯи¶…иҝҮеҚҠж•°зҡ„йӣҶзҫӨеҸҜдҪҝз”Ёж—¶пјҢжүҚејҖе§ӢйҖүдё»пјү
д»Ҙhadoop01пјҲid=1пјүвҖ”hadoop02пјҲid=2пјү---hadoop03пјҲid=3пјү----hadoop04пјҲid=rпјү----hadoop05пјҲid=5пјүдёәдҫӢпјҡ
еҪ“hadoop01еҗҜеҠЁж—¶пјҢжӯӨж—¶еҸӘжңүе®ғдёҖеҸ°жңҚеҠЎеҷЁпјҢпјҢд»–еҸ‘еҮәеҸ–зҡ„жҠҘе‘ҠжІЎжңүд»»дҪ•зӣёеә”пјҢжүҖжңүе®ғзҡ„йҖүдёҫдёҖзӣҙжҳҜlookingзҠ¶жҖҒгҖӮ
Hadoop02еҗҜеҠЁпјҡе®ғдёҺжңҖејҖе§ӢеҗҜеҠЁзҡ„hadoop01иҝӣиЎҢйҖҡдҝЎпјҢзӣёдә’дәӨжҚўиҮӘе·ұзҡ„йҖүдёҫз»“жһңпјҢз”ұдәҺдёӨиҖ…йғҪжІЎжңүеҺҶеҸІж•°жҚ®пјҢжүҖд»ҘidеҖјиҫғеӨ§зҡ„жңҚеҠЎеҷЁиғңеҮәпјҢдҪҶжҳҜз”ұдәҺжІЎжңүиҫҫеҲ°и¶…иҝҮеҚҠж•°д»ҘдёҠзҡ„жңҚеҠЎеҷЁеҗҢж„ҸйҖүдёҫе®ғпјҲиҝҷдёӘдҫӢеӯҗдёӯзҡ„еҚҠж•°д»ҘдёҠжҳҜ 3пјүпјҢжүҖжңүhadoop01гҖҒhadoop02иҝҳжҳҜ继з»ӯдҝқжҢҒlookingзҠ¶жҖҒгҖӮ
Hadoop03еҗҜеҠЁпјҢж №жҚ®еүҚйқўзҡ„еҲҶжһҗпјҢжңҚеҠЎеҷЁ 3 жҲҗдёәжңҚеҠЎеҷЁ 1,2,3 дёӯзҡ„иҖҒеӨ§пјҢиҖҢдёҺдёҠйқўдёҚ еҗҢзҡ„жҳҜпјҢжӯӨж—¶жңүдёүеҸ°жңҚеҠЎеҷЁ(и¶…иҝҮеҚҠж•°)йҖүдёҫдәҶе®ғпјҢжүҖHadoop03е®ғжҲҗдёәдәҶиҝҷж¬ЎйҖүдёҫзҡ„ leader
жңҚhadoop04еҗҜеҠЁпјҢж №жҚ®дёҠйқўзҡ„еҲҶжһҗпјҢзҗҶи®әдёҠпјҢhadoop04еә”иҜҘжҳҜжңҚеҠЎеҷЁдёӯidжңҖеӨ§зҡ„пјҢдҪҶжҳҜз”ұеүҚйқўе·Іиҝ‘жңүи¶…иҝҮеҚҠж•°зҡ„жңҚеҠЎеҷЁйҖүдёҫдәҶhadoop03пјҢжүҖд»Ҙhadoop04еҸӘиғҪжҳҜfollower
Hadoop05еҗҜеҠЁпјҢдёҺhadoop04дёҖж ·пјҢд№ҹжҳҜfollower
zookeeper serverзҡ„дёүз§Қе·ҘдҪңзҠ¶жҖҒпјҡ
LOOKINGпјҡеҪ“еүҚ Server дёҚзҹҘйҒ“ leader жҳҜи°ҒпјҢжӯЈеңЁжҗңеҜ»пјҢжӯЈеңЁйҖүдёҫ
LEADINGпјҡеҪ“еүҚ Server еҚідёәйҖүдёҫеҮәжқҘзҡ„ leaderпјҢиҙҹиҙЈеҚҸи°ғдәӢеҠЎ
FOLLOWINGпјҡleader е·Із»ҸйҖүдёҫеҮәжқҘпјҢеҪ“еүҚ Server дёҺд№ӢеҗҢжӯҘпјҢжңҚд»Һ leader зҡ„е‘Ҫд»Ө
пјҲ2пјүйқһе…Ёж–°йӣҶзҫӨзҡ„йҖүдё»
leader е·Із»ҸйҖүдёҫеҮәжқҘпјҢеҪ“еүҚ Server дёҺд№ӢеҗҢжӯҘпјҢжңҚд»Һ leader зҡ„е‘Ҫд»ӨпјҢдҪҶжҳҜз”ұдәҺжҹҗз§ҚеҺҹеӣ дё»иҠӮзӮ№е®•жңәпјҡ
жӯӨж—¶жҲ‘д»¬ж №жҚ®дёүдёӘз»ҙеәҰжқҘйҖүдё»пјҡж•°жҚ®versionгҖҒserveridгҖҒйҖ»иҫ‘ж—¶й’ҹгҖӮ
ж•°жҚ®versionпјҡж•°жҚ®ж–°зҡ„versionе°ұеӨ§пјҢж•°жҚ®жҜҸж¬Ўжӣҙж–°пјҢеҗҢж—¶дјҡжӣҙж–°е®ғзҡ„version
Serveridпјҡе°ұжҳҜжҲ‘们й…ҚзҪ®зҡ„ myid дёӯзҡ„еҖјпјҢжҜҸдёӘжңәеҷЁдёҖдёӘ
йҖ»иҫ‘ж—¶й’ҹпјҡиҝҷдёӘеҖјд»Һ0ејҖе§ӢпјҢжҜҸдёҖж¬ЎйҖүдёҫеҜ№еә”дёҖдёӘеҖјпјҢд№ҹе°ұжҳҜиҜҙпјҢеҰӮжһңеңЁеҗҢдёҖж¬ЎйҖүдёҫдёӯпјҢиҝҷдёӘеҖјеә”иҜҘдёҖиҮҙпјҢйҖ»иҫ‘ж—¶й’ҹи¶ҠеӨ§пјҢиҜҙжҳҺиҝҷдёҖж¬ЎйҖүдёҫleaderдәәзҡ„иҝӣзЁӢжӣҙж–°пјҢд№ҹе°ұжҳҜжҜҸж¬ЎйҖүдёҫжӢҘжңүдёҖдёӘ zxidпјҢжҠ•зҘЁз»“жһңеҸӘеҸ– zxid жңҖж–°зҡ„
йҖүдёҫзҡ„ж ҮеҮҶпјҡ
йҖ»иҫ‘ж—¶й’ҹе°Ҹзҡ„йҖүдёҫз»“жһңиў«еҝҪз•ҘпјҢйҮҚж–°жҠ•зҘЁ
з»ҹдёҖйҖ»иҫ‘ж—¶й’ҹеҗҺж•°жҚ®versionеӨ§зҡ„иғңеҮә
йҖ»иҫ‘ж—¶й’ҹз»ҹдёҖпјҢversionд№ҹзӣёеҗҢпјҢпјҢserver id еӨ§зҡ„иғңеҮәгҖӮ
ж №жҚ®д»ҘдёҠзҡ„规еҲҷпјҢеҝ«йҖҹйҖүеҮәйӣҶзҫӨзҡ„дё»иҠӮзӮ№гҖӮ
3. zookeeperеҶҷж•°жҚ®зҡ„жөҒзЁӢпјҡ
е®ўжҲ·з«ҜеҸ‘йҖҒеҶҷе…Ҙж•°жҚ®зҡ„иҜ·жұӮпјҢиҝҷдёӘиҜ·жұӮжңҖз»Ҳдјҡиў«leaderеӨ„зҗҶ
leaderдјҡе…ҲеҶҷе…Ҙж•°жҚ®пјҢеҶҷе…Ҙе®ҢжҲҗд№ӢеҗҺйҖҡзҹҘfollowerиҝӣиЎҢж•°жҚ®зҡ„еҗҢжӯҘ
followerе°ұдјҡејҖе§ӢиҝӣиЎҢж•°жҚ®зҡ„еҗҢжӯҘпјҲ并иЎҢпјҢеӨҡеҸ°follower并иЎҢеҗҢжӯҘпјү
жҜҸдёҖдёӘfollowerеҸӘиҰҒж•°жҚ®еҗҢжӯҘе®ҢжҲҗе°ұдјҡеҗ‘leaderеҸ‘йҖҒж•°жҚ®еҗҢжӯҘжҲҗеҠҹдҝЎжҒҜ
leaderжҺҘ收еҲ°и¶…иҝҮеҚҠж•°д»ҘдёҠзҡ„жҲҗеҠҹдҝЎжҒҜеҗҺпјҢеҲҷи®Өдёәиҝҷж¬ЎеҶҷж•°жҚ®жҲҗеҠҹ
е…¶д»–иҠӮзӮ№ж…ўж…ўиҝӣиЎҢеҗҢжӯҘпјҢеңЁж•°жҚ®еҗҢжӯҘзҡ„иҝҮзЁӢдёӯпјҢдёҚеҜ№еӨ–жҸҗдҫӣиҜ»еҶҷжңҚеҠЎ
4. zookeeperзҡ„ж•°жҚ®зҡ„еҗҢжӯҘиҝҮзЁӢ
followerиҝһжҺҘleader并еҸ‘йҖҒиҮӘе·ұжңҖеӨ§зҡ„zixd
leaderиҝӣиЎҢеҜ№жҜ”пјҢе°ҶиҮӘе·ұжңҖеӨ§зҡ„zxidе’ҢfollowerеҸ‘йҖҒиҝҮжқҘзҡ„zxidиҝӣиЎҢеҜ№жҜ”пјҢеҰӮжһңleaderзҡ„zxidеӨ§дәҺfollowerзҡ„пјҢеҲҷйҖҡзҹҘfollowerиҝӣиЎҢж•°жҚ®еҗҢжӯҘ
followerеҸ‘йҖҒж•°жҚ®еҗҢжӯҘиҜ·жұӮ
leaderзЎ®е®ҡеҪ“еүҚзҡ„followerзҡ„ж•°жҚ®еҗҢжӯҘзӮ№пјҲд»ҺfollowerжңҖеӨ§зҡ„zxidеҲ°leaderжңҖеӨ§зҡ„zxidд№Ӣй—ҙж•°жҚ®йңҖиҰҒеҗҢжӯҘпјү
followerејҖе§ӢеҗҢжӯҘж•°жҚ®пјҢиҝҷдёӘиҝҮзЁӢдёҚеҜ№еӨ–жҸҗдҫӣиҜ»еҶҷжңҚеҠЎгҖӮ
followerеҗҢжӯҘе®ҢжҲҗпјҢеҸ‘йҖҒж¶ҲжҒҜз»ҷleader
leaderе°ұдјҡдҝ®ж”№еҪ“еүҚзҡ„followerзҡ„зҠ¶жҖҒдёәupdateпјҢиҝҷдёӘж—¶еҖҷfollowerе°ұеҸҜд»ҘжҺҘеҸ—е®ўжҲ·з«Ҝзҡ„иҜ»еҶҷиҜ·жұӮпјҢдҪҶжҳҜеҸӘиғҪиҜ»пјҢеҰӮжһңжҳҜеҶҷе…ҘиҜ·жұӮпјҢйңҖиҰҒиҪ¬еҸ‘з»ҷleader
5. ZooKeeper дёӯеҗ„дёӘи§’иүІзҡ„е·ҘдҪңиҒҢиҙЈ
пјҲ1пјүLeader
жҒўеӨҚж•°жҚ®
з»ҙжҢҒдёҺfollowerзҡ„еҝғи·іпјҢжҺҘ收followerиҜ·жұӮ并еҲӨж–ӯfollowerзҡ„иҜ·жұӮж¶ҲжҒҜзұ»еһӢ
ж №жҚ®дёҚеҗҢзҡ„ж¶ҲжҒҜзұ»еһӢпјҢиҝӣиЎҢдёҚеҗҢзҡ„еӨ„зҗҶ
пјҲ2пјүfollower
еҗ‘leaderеҸ‘йҖҒиҜ·жұӮпјҲеҗҢжӯҘж•°жҚ®пјҢеҶҷе…ҘиҜ·жұӮпјү
жҺҘ收leaderзҡ„ж¶ҲжҒҜ并иҝӣиЎҢзӣёеә”зҡ„еӨ„зҗҶ
жҺҘ收clientзҡ„иҜ»еҶҷиҜ·жұӮпјҢеҰӮжһңжҳҜеҶҷе…Ҙзҡ„иҜ·жұӮиҪ¬еҸ‘з»ҷleaderеӨ„зҗҶ
иҝ”еӣһclientзҡ„иҜ»иҜ·жұӮпјҢжҹҘиҜўзҡ„з»“жһң
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ