жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
ж–Ү | жҪҳеӣҪеәҶ жҗәзЁӢеӨ§ж•°жҚ®е№іеҸ°е®һж—¶и®Ўз®—е№іеҸ°иҙҹиҙЈдәә
 жң¬ж–Үдё»иҰҒд»ҺжҗәзЁӢеӨ§ж•°жҚ®е№іеҸ°жҰӮеҶөгҖҒжһ¶жһ„и®ҫи®ЎеҸҠе®һзҺ°гҖҒеңЁе®һзҺ°еҪ“дёӯиё©еқ‘еҸҠеЎ«еқ‘зҡ„иҝҮзЁӢгҖҒе®һж—¶и®Ўз®—йўҶеҹҹиҜҰз»Ҷзҡ„еә”з”ЁеңәжҷҜпјҢд»ҘеҸҠжңӘжқҘ规еҲ’дә”дёӘж–№йқўйҳҗиҝ°жҗәзЁӢе®һж—¶и®Ўз®—е№іеҸ°жһ¶жһ„дёҺе®һи·өпјҢеёҢжңӣеҜ№йңҖиҰҒжһ„е»әе®һж—¶ж•°жҚ®е№іеҸ°зҡ„е…¬еҸёе’ҢеҗҢеӯҰжңүжүҖеҖҹйүҙгҖӮ
жң¬ж–Үдё»иҰҒд»ҺжҗәзЁӢеӨ§ж•°жҚ®е№іеҸ°жҰӮеҶөгҖҒжһ¶жһ„и®ҫи®ЎеҸҠе®һзҺ°гҖҒеңЁе®һзҺ°еҪ“дёӯиё©еқ‘еҸҠеЎ«еқ‘зҡ„иҝҮзЁӢгҖҒе®һж—¶и®Ўз®—йўҶеҹҹиҜҰз»Ҷзҡ„еә”з”ЁеңәжҷҜпјҢд»ҘеҸҠжңӘжқҘ规еҲ’дә”дёӘж–№йқўйҳҗиҝ°жҗәзЁӢе®һж—¶и®Ўз®—е№іеҸ°жһ¶жһ„дёҺе®һи·өпјҢеёҢжңӣеҜ№йңҖиҰҒжһ„е»әе®һж—¶ж•°жҚ®е№іеҸ°зҡ„е…¬еҸёе’ҢеҗҢеӯҰжңүжүҖеҖҹйүҙгҖӮ
жҗәзЁӢеӨ§ж•°жҚ®е№іеҸ°з»“жһ„еҲҶдёәдёүеұӮпјҡ
еә”з”ЁеұӮпјҡејҖеҸ‘е№іеҸ°ZeusпјҲеҲҶдёәи°ғеәҰзі»з»ҹгҖҒDataxж•°жҚ®дј иҫ“зі»з»ҹгҖҒдё»ж•°жҚ®зі»з»ҹгҖҒж•°жҚ®иҙЁйҮҸзі»з»ҹпјүгҖҒжҹҘиҜўе№іеҸ°пјҲArtNovaжҠҘиЎЁзі»з»ҹгҖҒAdhocжҹҘиҜўпјүгҖҒжңәеҷЁеӯҰд№ пјҲеҹәдәҺtensorflowгҖҒsparkзӯүејҖжәҗжЎҶжһ¶иҝӣиЎҢејҖеҸ‘пјӣGPUдә‘е№іеҸ°еҹәдәҺK8Sе®һзҺ°пјүгҖҒе®һж—¶и®Ўз®—е№іеҸ°Muiseпјӣ
дёӯй—ҙеұӮпјҡеҹәдәҺејҖжәҗзҡ„еӨ§ж•°жҚ®еҹәзЎҖжһ¶жһ„пјҢеҲҶдёәеҲҶеёғејҸеӯҳеӮЁе’Ңи®Ўз®—жЎҶжһ¶гҖҒе®һж—¶и®Ўз®—жЎҶжһ¶пјӣ
зҰ»зәҝдё»иҰҒжҳҜеҹәдәҺHadoopгҖҒHDFSеҲҶеёғејҸеӯҳеӮЁгҖҒеҲҶеёғејҸзҰ»зәҝи®Ўз®—еҹәдәҺHiveеҸҠSparkгҖҒKVеӯҳеӮЁеҹәдәҺHBaseгҖҒPrestoе’ҢKylinз”ЁдәҺAdhocд»ҘеҸҠжҠҘиЎЁзі»з»ҹпјӣ
е®һж—¶и®Ўз®—жЎҶжһ¶еә•еұӮжҳҜеҹәдәҺKafkaе°ҒиЈ…зҡ„ж¶ҲжҒҜйҳҹеҲ—зі»з»ҹHermes, QmqжҳҜжҗәзЁӢиҮӘз ”зҡ„ж¶ҲжҒҜйҳҹеҲ—пјҢ Qmqдё»иҰҒз”ЁдәҺе®ҡеҚ•дәӨжҳ“зі»з»ҹпјҢзЎ®дҝқзҷҫеҲҶд№ӢзҷҫдёҚдёўеӨұж•°жҚ®иҖҢжү“йҖ зҡ„ж¶ҲжҒҜйҳҹеҲ—гҖӮ
еә•еұӮпјҡиө„жәҗзӣ‘жҺ§дёҺиҝҗз»ҙзӣ‘жҺ§пјҢеҲҶдёәиҮӘеҠЁеҢ–иҝҗз»ҙзі»з»ҹгҖҒеӨ§ж•°жҚ®жЎҶжһ¶и®ҫж–Ҫзӣ‘жҺ§гҖҒеӨ§ж•°жҚ®дёҡеҠЎзӣ‘жҺ§гҖӮ

1.Muiseе№іеҸ°д»Ӣз»Қ
1пјүMuiseжҳҜд»Җд№Ҳ
MuiseпјҢеҸ–иҮӘеёҢи…ҠзҘһиҜқзҡ„ж–ҮиүәеҘізҘһзјӘж–Ҝд№ӢеҗҚпјҢжҳҜжҗәзЁӢзҡ„е®һж—¶ж•°жҚ®еҲҶжһҗе’ҢеӨ„зҗҶзҡ„е№іеҸ°пјӣMuiseе№іеҸ°еә•еұӮеҹәдәҺж¶ҲжҒҜйҳҹеҲ—е’ҢејҖжәҗзҡ„е®һж—¶еӨ„зҗҶзі»з»ҹJStormгҖҒSpark Streamingе’ҢFlinkпјҢиғҪеӨҹж”ҜжҢҒз§’зә§пјҢз”ҡиҮіжҳҜжҜ«з§’зә§е»¶иҝҹзҡ„жөҒејҸж•°жҚ®еӨ„зҗҶгҖӮ
2пјүMuiseзҡ„еҠҹиғҪ
ж•°жҚ®жәҗпјҡHermes Kafka/MysqlгҖҒQmqпјӣ
ж•°жҚ®еӨ„зҗҶпјҡжҸҗдҫӣMuise JStorm/Spark/FlinkCore APIж¶Ҳиҙ№HermesжҲ–Qmqж•°жҚ®пјҢеә•еұӮдҪҝз”ЁJstormгҖҒSparkжҲ–е®һж—¶еӨ„зҗҶж•°жҚ®пјҢ并жҸҗдҫӣиҮӘе·ұе°ҒиЈ…зҡ„APIз»ҷз”ЁжҲ·дҪҝз”ЁгҖӮAPIеҜ№жҺҘдәҶжүҖжңүж•°жҚ®жәҗзі»з»ҹпјҢж–№дҫҝз”ЁжҲ·зӣҙжҺҘдҪҝз”Ёпјӣ
дҪңдёҡз®ЎзҗҶпјҡPortalжҸҗдҫӣеҜ№дәҺJStormгҖҒSpark Streamingе’ҢFlinkдҪңдёҡзҡ„з®ЎзҗҶпјҢеҢ…еҗ«ж–°е»әдҪңдёҡпјҢдёҠдј jarеҢ…д»ҘеҸҠеҸ‘еёғз”ҹдә§зӯүеҠҹиғҪпјӣ
зӣ‘жҺ§е’Ңе‘ҠиӯҰпјҡдҪҝз”ЁJstormгҖҒSparkе’ҢFlinkжҸҗдҫӣзҡ„MetricsжЎҶжһ¶пјҢж”ҜжҢҒиҮӘе®ҡд№үзҡ„metricsпјӣmetricsдҝЎжҒҜдёӯеҝғеҢ–з®ЎзҗҶпјҢжҺҘе…ҘOpsзҡ„зӣ‘жҺ§е’Ңе‘ҠиӯҰзі»з»ҹпјҢжҸҗдҫӣе…Ёйқўзҡ„зӣ‘жҺ§е’Ңе‘ҠиӯҰж”ҜжҢҒпјҢеё®еҠ©з”ЁжҲ·еңЁз¬¬дёҖж—¶й—ҙеҶ…зӣ‘жҺ§еҲ°дҪңдёҡжҳҜеҗҰеҸ‘з”ҹй—®йўҳгҖӮ
2.Muiseе№іеҸ°зҺ°зҠ¶
е№іеҸ°зҺ°зҠ¶пјҡ
Jstorm 2.1.1гҖҒSpark 2.0.1гҖҒFlink1.6.0гҖҒKafka 2.0пјӣ
йӣҶзҫӨ规模пјҡ
13дёӘйӣҶзҫӨгҖҒ200+еҸ°жңәеҷЁ150+JstormгҖҒ50+YarnгҖҒ100+ Kafkaпјӣ
дҪңдёҡ规模пјҡ
11дёӘдёҡеҠЎзәҝгҖҒ350+JstormдҪңдёҡгҖҒ120+SS/FlinkдҪңдёҡпјӣ
ж¶ҲжҒҜ规模пјҡ
Topic 1300+гҖҒеўһйҮҸ 100T+ PDгҖҒAvg 200K TPSгҖҒMax 900K TPSпјӣ
ж¶ҲжҒҜ延时пјҡ
Hermes 200msд»ҘеҶ…гҖҒStorm 20msд»ҘеҶ…пјӣ
ж¶ҲжҒҜеӨ„зҗҶжҲҗеҠҹзҺҮпјҡ
99.99%гҖӮ
3.Muiseе№іеҸ°жј”иҝӣд№Ӣи·Ҝ
2015 Q2~2015 Q3 пјҡеҹәдәҺStormејҖеҸ‘е®һж—¶и®Ўз®—е№іеҸ°пјӣ
2016 Q1~2016 Q2 пјҡStormиҝҒ移JStormгҖҒеј•е…ҘStreamCQLпјӣ
2017 Q1~2017 Q2 пјҡSpark Streamingи°ғз ”дёҺжҺҘе…Ҙпјӣ
2017 Q3~2018 Q1 пјҡFlinkи°ғз ”дёҺжҺҘе…ҘгҖӮ
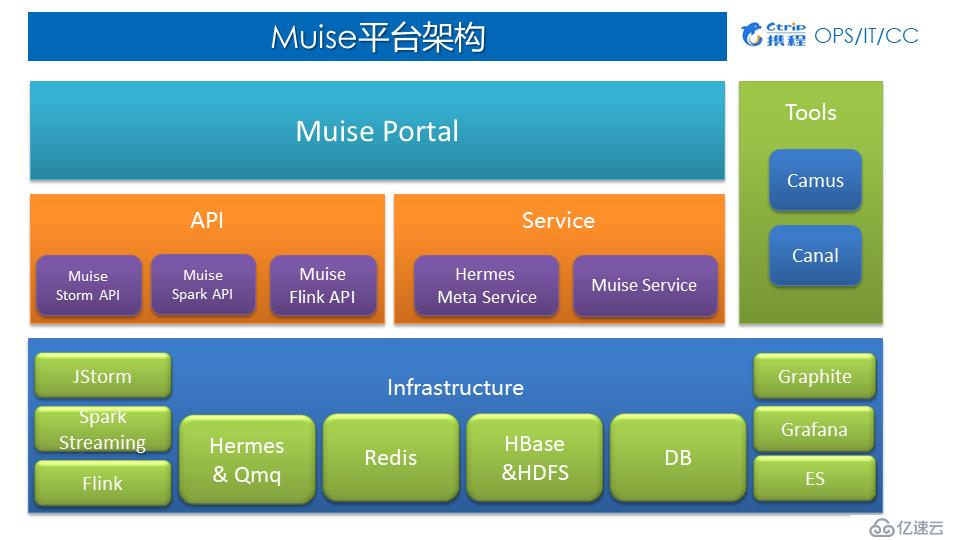
4.Muiseе№іеҸ°жһ¶жһ„
1пјүMuiseе№іеҸ°жһ¶жһ„
еә”з”ЁеұӮпјҡMuise Portal зӣ®еүҚдё»иҰҒж”ҜжҢҒдәҶ Storm дёҺ Spark StreamingдёӨзұ»дҪңдёҡпјҢж”ҜжҢҒж–°е»әдҪңдёҡгҖҒJarеҢ…еҸ‘еёғгҖҒдҪңдёҡиҝҗиЎҢдёҺеҒңжӯўзӯүдёҖзі»еҲ—еҠҹиғҪпјӣ
дёӯй—ҙеұӮпјҡеҜ№еә•еұӮInfrastructureеҒҡдәҶе°ҒиЈ…пјҢдёәз”ЁжҲ·жҸҗдҫӣеҹәдәҺStormгҖҒSparkгҖҒFlinkзӣёеҜ№еә”зҡ„APIд»ҘеҸҠеҗ„ж–№йқўServicesпјӣ
еә•еұӮпјҡHermes & QmqжҳҜж•°жҚ®жәҗгҖҒRedisгҖҒHBaseгҖҒHDFSгҖҒDBзӯүдҪңдёәеӨ–йғЁзҡ„ж•°жҚ®еӯҳеӮЁгҖҒGraphiteгҖҒGrafanaгҖҒESдё»иҰҒз”ЁдәҺзӣ‘жҺ§гҖӮ
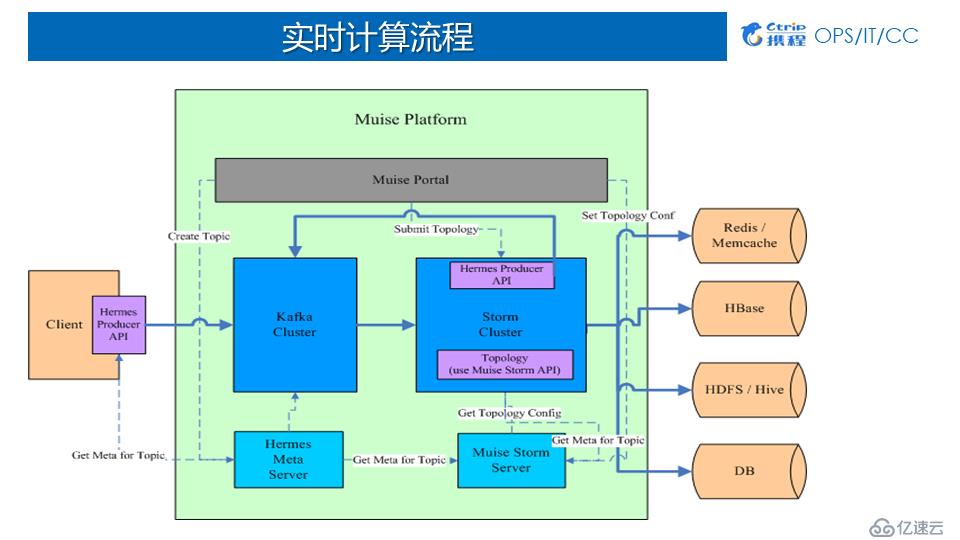
2пјүMuiseе®һж—¶и®Ўз®—жөҒзЁӢ
Producerз«Ҝпјҡз”ЁжҲ·е…Ҳз”іиҜ·Kafkaзҡ„topicпјҢ然еҗҺе°Ҷж•°жҚ®е®һж—¶еҶҷеҲ°Kafkaдёӯпјӣ
Muise Portalз«Ҝпјҡз”ЁжҲ·еҹәдәҺжҲ‘们жҸҗдҫӣзҡ„APIеҒҡејҖеҸ‘пјҢејҖеҸ‘е®Ңд»ҘеҗҺйҖҡиҝҮMuise Portalй…ҚзҪ®гҖҒдёҠдј е’ҢеҗҜеҠЁдҪңдёҡпјӣдҪңдёҡеҗҜеҠЁеҗҺпјҢjarеҢ…дјҡеҲҶеҸ‘еҲ°еҗ„дёӘеҜ№еә”зҡ„йӣҶзҫӨж¶Ҳиҙ№Kafkaж•°жҚ®пјӣ
еӯҳеӮЁз«Ҝпјҡж•°жҚ®еңЁиў«ж¶Ҳиҙ№д№ӢеҗҺеҸҜд»ҘеҶҷеӣһQMQжҲ–KafkaпјҢд№ҹеҸҜд»ҘеӯҳеӮЁеҲ°еӨ–йғЁзі»з»ҹRedisгҖҒHBaseгҖҒHDFS/HiveгҖҒDBгҖӮ
5.е№іеҸ°и®ҫи®Ў вҖ”вҖ”жҳ“з”ЁжҖ§
йҰ–е…ҲпјҡдҪңдёәдёҖдёӘе№іеҸ°и®ҫ计第дёҖиҰҒзӮ№е°ұжҳҜиҰҒз®ҖеҚ•жҳ“з”ЁпјҢжҲ‘们жҸҗдҫӣз»јеҗҲзҡ„PortalпјҢдҫҝдәҺз”ЁжҲ·иҮӘе·ұж–°е»әз®ЎзҗҶе®ғзҡ„дҪңдёҡпјҢж–№дҫҝејҖеҸ‘е®һж—¶дҪңдёҡ第дёҖж—¶й—ҙиғҪеӨҹдёҠзәҝпјӣ
е…¶ж¬ЎпјҡжҲ‘们е°ҒиЈ…дәҶеҫҲеӨҡCore APIпјҢж”ҜжҢҒеӨҡеҘ—е®һж—¶и®Ўз®—жЎҶжһ¶пјҡ
ж”ҜжҢҒHermesKafka/MySQL гҖҒQMQпјӣ
йӣҶжҲҗJstormгҖҒSpark StreamingгҖҒFlinkпјӣ
дҪңдёҡиө„жәҗз®ЎжҺ§пјӣ
жҸҗдҫӣDBгҖҒRedisгҖҒHBaseе’ҢHDFSиҫ“еҮә组件пјӣ
еҹәдәҺеҶ…зҪ®Metricзі»з»ҹе®ҡеҲ¶еӨҡйЎ№metricиҝӣиЎҢдҪңдёҡйў„иӯҰзӣ‘жҺ§пјӣ
з”ЁжҲ·еҸҜиҮӘе®ҡд№үMetricз”ЁдәҺзӣ‘жҺ§дёҺйў„иӯҰпјӣ
ж”ҜжҢҒAtLeast Once дёҺExactly OnceиҜӯд№үгҖӮ
дёҠж–Үи®ІеҲ°е№іеҸ°и®ҫи®ЎиҰҒжҳ“з”ЁпјҢдёӢйқўи®Іе№іеҸ°зҡ„е®№й”ҷпјҢзЎ®дҝқж•°жҚ®дёҖе®ҡдёҚиғҪеҮәй—®йўҳгҖӮ
6.е№іеҸ°и®ҫи®ЎвҖ”вҖ”е®№й”ҷ
JstormпјҡеҹәдәҺAckerжңәеҲ¶зЎ®дҝқAt Least Onceпјӣ
Spark StreamingпјҡеҹәдәҺCheckpointе®һзҺ°Exactly OnceгҖҒеҹәдәҺKafka OffsetеӣһжәҜе®һзҺ°At Least Onceпјӣ
FlinkпјҡеҹәдәҺFlinktwo-phase commit + Kafka 0.11дәӢеҠЎжҖ§ж”ҜжҢҒе®һзҺ°Exactly OnceгҖӮ
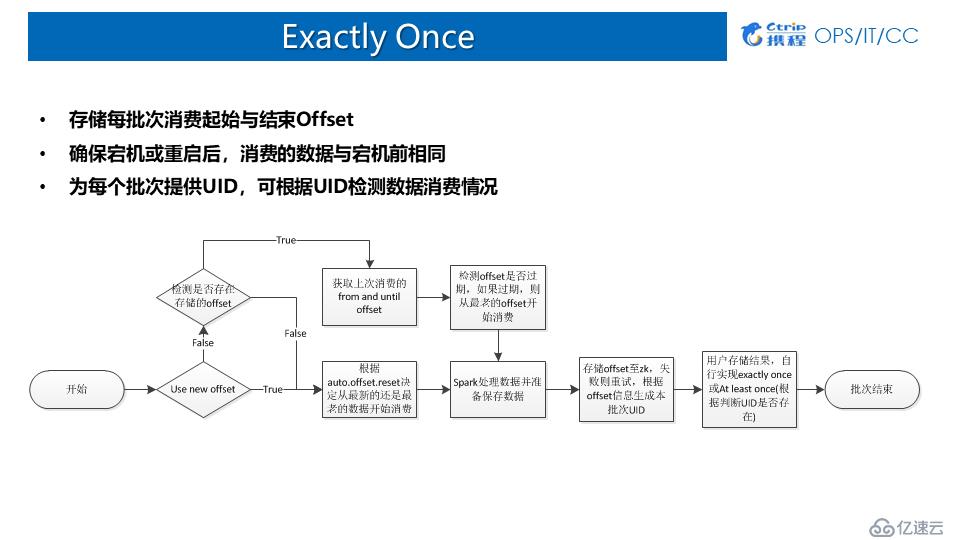
7.Exactly Once
1пјүDirect Approach
еҪ“еүҚеӨ§йғЁеҲҶжӢҝSpark Streamingж¶Ҳиҙ№Kafkaзҡ„иҜқпјҢйғҪжҳҜз”ЁDirect Approachзҡ„ж–№ејҸпјҡ
дјҳзӮ№пјҡи®°еҪ•жҜҸдёӘжү№ж¬Ўж¶Ҳиҙ№зҡ„OffsetпјҢдҪңдёҡеҸҜйҖҡиҝҮoffsetеӣһжәҜпјӣ
зјәзӮ№пјҡж•°жҚ®еӯҳеӮЁдёҺoffsetеӯҳеӮЁејӮжӯҘпјҡ
ж•°жҚ®дҝқеӯҳжҲҗеҠҹпјҢеә”з”Ёе®•жңәпјҢoffsetжңӘдҝқеӯҳ пјҲеҜјиҮҙж•°жҚ®йҮҚеӨҚпјүпјӣ
offsetдҝқеӯҳжҲҗеҠҹпјҢеә”з”Ёе®•жңәпјҢж•°жҚ®дҝқеӯҳеӨұиҙҘ пјҲеҜјиҮҙж•°жҚ®дёўеӨұпјүпјӣ
2пјүCheckPoint
дјҳзӮ№пјҡй»ҳи®Өи®°еҪ•жҜҸдёӘжү№ж¬Ўзҡ„иҝҗиЎҢзҠ¶жҖҒдёҺжәҗж•°жҚ®пјҢе®•жңәж—¶еҸҜд»Һcpзӣ®еҪ•жҒўеӨҚпјӣ
зјәзӮ№пјҡ
1. йқһ100%дҝқиҜҒExactlyOnceпјӣ
https://www.iteblog.com/archives/1795 жҸҸиҝ°дәҶж— жі•дҝқиҜҒExactly onceзҡ„еңәжҷҜпјӣ
https://issues.apache.org/jira/browse/SPARK-17606 д№ҹеӯҳеңЁdoCheckPointж—¶еҮәзҺ°еқ—дёўеӨұзҡ„жғ…еҶөпјӣ
2. еҗҜз”ЁcpеёҰжқҘйўқеӨ–жҖ§иғҪеҪұе“Қпјӣ
3. StreamingдҪңдёҡйҖ»иҫ‘ж”№еҸҳж— жі•д»ҺcpжҒўеӨҚгҖӮ
йҖӮз”ЁеңәжҷҜпјҡжҜ”иҫғйҖӮеҗҲжңүзҠ¶жҖҒи®Ўз®—зҡ„еңәжҷҜпјӣ
дҪҝз”Ёж–№ејҸпјҡе»әи®®зЁӢеәҸиҮӘе·ұеӯҳеӮЁoffsetпјҢеҪ“еҸ‘з”ҹе®•жңәж—¶пјҢеҰӮжһңsparkд»Јз ҒйҖ»иҫ‘жІЎжңүеҸ‘з”ҹж”№еҸҳпјҢеҲҷж №жҚ®checkpointзӣ®еҪ•еҲӣе»әStreamingContextгҖӮеҰӮжһңеҸ‘з”ҹж”№еҸҳпјҢеҲҷж №жҚ®е®һзҺ°иҮӘе·ұеӯҳеӮЁзҡ„offsetеҲӣе»әcontext并и®ҫз«Ӣж–°зҡ„checkpointзӮ№гҖӮ
8.е№іеҸ°и®ҫи®ЎвҖ”вҖ”зӣ‘жҺ§дёҺе‘ҠиӯҰ
еҰӮдҪ•иғҪеӨҹ第дёҖж—¶й—ҙеё®з”ЁжҲ·еҸ‘зҺ°дҪңдёҡй—®йўҳпјҢжҳҜдёҖдёӘйҮҚдёӯд№ӢйҮҚгҖӮ
йӣҶзҫӨзӣ‘жҺ§
жңҚеҠЎеҷЁзӣ‘жҺ§пјҡиҖғйҮҸзҡ„жҢҮж ҮжңүMemoryгҖҒCPUгҖҒDisk IOгҖҒNet IOпјӣ
е№іеҸ°зӣ‘жҺ§пјҡGangliaпјӣ
дҪңдёҡзӣ‘жҺ§
еҹәдәҺе®һж—¶и®Ўз®—жЎҶжһ¶еҺҹз”ҹMetricзі»з»ҹпјӣ
е®ҡеҲ¶MetricsеҸҚеә”дҪңдёҡзҠ¶жҖҒпјӣ
йҮҮйӣҶеҺҹз”ҹдёҺе®ҡеҲ¶Metricsз”ЁдәҺзӣ‘жҺ§е’Ңе‘ҠиӯҰпјӣ
еӯҳеӮЁпјҡGraphiteеұ• зҺ°пјҡGrafana е‘ҠиӯҰпјҡAppmonпјӣ
жҲ‘们зҺ°еңЁе®ҡеҲ¶зҡ„еҫҲеӨҡMetricsеҪ“дёӯжҜ”иҫғйҖҡз”Ёзҡ„жҳҜпјҡ
Failпјҡе®ҡжңҹж—¶й—ҙеҶ…пјҢJstormж•°жҚ®еӨ„зҗҶеӨұиҙҘж•°йҮҸгҖҒSpark task Failж•°йҮҸпјӣ
Ackпјҡе®ҡжңҹж—¶й—ҙеҶ…пјҢеӨ„зҗҶзҡ„ж•°жҚ®йҮҸпјӣ
Lagпјҡе®ҡжңҹж—¶й—ҙеҶ…пјҢж•°жҚ®дә§з”ҹдёҺиў«ж¶Ҳиҙ№зҡ„дёӯй—ҙ延иҝҹпјҲkafka 2.0еҹәдәҺиҮӘеёҰbornTimeпјүгҖӮ
жҗәзЁӢејҖеҸ‘дәҶиҮӘе·ұе‘ҠиӯҰзі»з»ҹпјҢе°ҶMetricsд»Је…Ҙзі»з»ҹд№ӢеҗҺеҹәдәҺ规еҲҷеҒҡе‘ҠиӯҰгҖӮйҖҡиҝҮдҪңдёҡзӣ‘жҺ§зңӢжқҝе®ҢжҲҗзӣёе…іжҢҮж Үзҡ„зӣ‘жҺ§е’ҢжҹҘзңӢпјҢжҲ‘们дјҡжҠҠFlinkдҪңдёәжҜ”иҫғе…іеҝғзҡ„MetricsжҢҮж ҮпјҢе…ЁйғҪеҜје…ҘеҲ°Graphiteж•°жҚ®еә“йҮҢйқўпјҢ然еҗҺеҹәдәҺеүҚз«ҜGrafanaеҒҡеұ•зҺ°гҖӮйҖҡиҝҮдҪңдёҡзӣ‘жҺ§зңӢжқҝпјҢжҲ‘们иғҪеӨҹзӣҙжҺҘзңӢеҲ°Kafka to Flink DelayпјҲLagпјүпјҢзӣёеҪ“дәҺж•°жҚ®д»Һдә§з”ҹеҲ°иў«FlinkдҪңдёҡж¶Ҳиҙ№пјҢдёӯй—ҙ延иҝҹжҳҜ62жҜ«з§’пјҢйҖҹеәҰзӣёеҜ№жҜ”иҫғеҝ«зҡ„гҖӮе…¶ж¬ЎжҲ‘们зӣ‘жҺ§дәҶжҜҸж¬Ўд»ҺKafkaдёӯиҺ·еҸ–ж•°жҚ®зҡ„йҖҹеәҰгҖӮеӣ дёәд»ҺKafkaиҺ·еҸ–ж•°жҚ®жҳҜеҹәдәҺдёҖе°Ҹеқ—дёҖе°Ҹеқ—еҺ»иҺ·еҸ–пјҢжҲ‘们и®ҫзҪ®зҡ„жҳҜжҜҸж¬ЎжӢү2е…Ҷзҡ„ж•°жҚ®йҮҸгҖӮйҖҡиҝҮдҪңдёҡзӣ‘жҺ§зңӢжқҝеҸҜд»Ҙзӣ‘жҺ§еҲ°жҜҸж¬Ўд»ҺKafkaжӢүеҸ–ж•°жҚ®ж—¶еҖҷзҡ„е№іеқҮ延иҝҹжҳҜ25жҜ«з§’пјҢMaxжҳҜ 760жҜ«з§’гҖӮ

жҺҘдёӢжқҘи®Іи®ІжҲ‘们еңЁиҝҷеҮ е№ҙиё©еҲ°зҡ„дёҖдәӣеқ‘д»ҘеҸҠеҰӮдҪ•еЎ«еқ‘зҡ„гҖӮ
еқ‘1пјҡHermesUBTж•°жҚ®йҮҸеӨ§пјҢеҹӢзӮ№дҝЎжҒҜдј—еӨҡпјҢжңҚеҠЎз«ҜдёҺе®ўжҲ·з«ҜеқҮжүҝеҸ—е·ЁеӨ§еҺӢеҠӣпјӣ
и§ЈеҶіж–№жЎҲпјҡжҸҗдҫӣз»ҹдёҖеҲҶжөҒдҪңдёҡпјҢеҹәдәҺзү№е®ҡ规еҲҷдёҺй…ҚзҪ®е°Ҷж•°жҚ®еҲҶжөҒиҮідёҚеҗҢtopicгҖӮ
еқ‘2пјҡKafkaж— жі•дҝқиҜҒе…ЁеұҖжңүеәҸпјӣ
и§ЈеҶіж–№жЎҲпјҡеҰӮжһңеңЁејәеҲ¶е…ЁеұҖжңүеәҸзҡ„еңәжҷҜдёӢпјҢдҪҝз”ЁеҚ•PartitionпјӣеҰӮжһңеңЁйғЁеҲҶжңүеәҸзҡ„жғ…еҶөдёӢпјҢеҸҜеҹәдәҺжҹҗдёӘеӯ—ж®өдҪңHashпјҢдҝқиҜҒPartitionеҶ…йғЁжңүеәҸгҖӮ
еқ‘3пјҡKafkaж— жі•ж №жҚ®ж—¶й—ҙзІҫзЎ®еӣһжәҜеҲ°жҹҗж—¶й—ҙж®өзҡ„ж•°жҚ®пјӣ
и§ЈеҶіж–№жЎҲпјҡе№іеҸ°жҸҗдҫӣиҝҮж»ӨеҠҹиғҪпјҢиҝҮж»Өж—¶й—ҙж—©дәҺи®ҫе®ҡж—¶й—ҙзҡ„ж•°жҚ®пјҲkafka 0.10д№ӢеҗҺжҜҸжқЎж•°жҚ®йғҪеёҰжңүиҮӘе·ұзҡ„ж—¶й—ҙжҲіпјҢжүҖд»ҘиҝҷдёӘй—®йўҳеңЁеҚҮзә§kafkaд№ӢеҗҺиҮӘ然иҖҢ然зҡ„е°ұи§ЈеҶідәҶпјүгҖӮ
еқ‘4пјҡжңҖеҲқпјҢжҗәзЁӢжүҖжңүзҡ„Spark StreamingгҖҒFlinkдҪңдёҡйғҪжҳҜи·‘еңЁдё»жңәзҫӨдёҠйқўзҡ„пјҢжҳҜдёҖдёӘеӨ§HadoopйӣҶзҫӨпјҢзӣ®еүҚжҳҜеҮ еҚғеҸ°и§„жЁЎпјҢзҰ»зәҝе’Ңе®һж—¶жҳҜж··еёғзҡ„пјҢдёҖж—ҰдёҖдёӘеӨ§зҡ„зҰ»зәҝдҪңдёҡдёҠжқҘж—¶пјҢдјҡеҜ№е®һж—¶дҪңдёҡжңүеҪұе“Қпјӣе…¶ж¬ЎжҳҜHadoopйӣҶзҫӨз»ҸеёёдјҡеҒҡдёҖдәӣеҚҮзә§ж”№йҖ пјҢжүҖд»ҘеҸҜиғҪдјҡйҮҚеҗҜName NodeжҲ–иҖ…Node ManagerпјҢиҝҷдјҡеҜјиҮҙдҪңдёҡжңүж—¶дјҡжҢӮжҺүпјӣ
и§ЈеҶіж–№жЎҲпјҡжҲ‘们йҮҮз”ЁеҲҶејҖйғЁзҪІпјҢеҚ•зӢ¬жҗӯе»әе®һж—¶йӣҶзҫӨпјҢзӢ¬з«ӢиҝҗиЎҢе®һж—¶дҪңдёҡгҖӮзҰ»зәҝеҪ’зҰ»зәҝпјҢе®һж—¶еҪ’е®һж—¶зҡ„пјҢе®һж—¶йӣҶзҫӨеҚ•зӢ¬и·‘Spark Streamingи·ҹYarnзҡ„дҪңдёҡпјҢзҰ»зәҝдё“й—Ёи·‘зҰ»зәҝзҡ„дҪңдёҡгҖӮ
еҪ“еҲҶејҖйғЁзҪІеҗҺпјҢдјҡйҒҮеҲ°ж–°зҡ„й—®йўҳпјҢйғЁеҲҶе®һж—¶дҪңдёҡйңҖиҰҒеҺ»дёҖдәӣзҰ»зәҝдҪңдёҡеҒҡдёҖдәӣJoinжҲ– Featureзҡ„ж“ҚдҪңпјҢжүҖд»Ҙд№ҹжҳҜйңҖиҰҒи®ҝй—®дё»жңәзҫӨж•°жҚ®гҖӮиҝҷзӣёеҪ“дәҺжңүдёҖдёӘи·ЁйӣҶзҫӨи®ҝй—®зҡ„й—®йўҳгҖӮ
еқ‘5пјҡHadoopе®һж—¶йӣҶзҫӨи·ЁйӣҶзҫӨи®ҝй—®дё»жңәзҫӨпјӣ
и§ЈеҶіж–№жЎҲпјҡHdfs-site.xmlй…ҚзҪ®ns-prodгҖҒnsеҸҢйҮҚnamespaceпјҢеҲҶеҲ«жҢҮеҗ‘жң¬ең°дёҺдё»жңәзҫӨпјӣ
Sparkй…ҚзҪ®spark.yarn.access.namenodes or hadoopFlieSystems
еқ‘6пјҡж— и®әжҳҜJstormиҝҳжҳҜжҺҘStormйғҪдјҡйҒҮеҲ°дёҖдёӘCPUжҠўеҚ зҡ„й—®йўҳпјҢеҪ“дҪ дёҠдәҶдёҖдёӘеӨ§зҡ„дҪңдёҡпјҢе°Өе…¶жҳҜйӮЈз§Қж¶ҲиҖ—CPUзү№еҲ«еҺүе®ізҡ„пјҢеҸҜиғҪжҲ‘з»ҷе®ғеҲҶејҖдәҶдёҖдёӘWorkerпјҢдёҖдёӘCPU CoreпјҢдҪҶжҳҜе®ғжңҖеҗҺжңүеҸҜиғҪдјҡз»ҷжҲ‘з”ЁеҲ°3дёӘз”ҡиҮі4дёӘпјӣ
и§ЈеҶіж–№жЎҲпјҡеҗҜз”ЁcgroupйҷҗеҲ¶cpuдҪҝз”ЁзҺҮгҖӮ
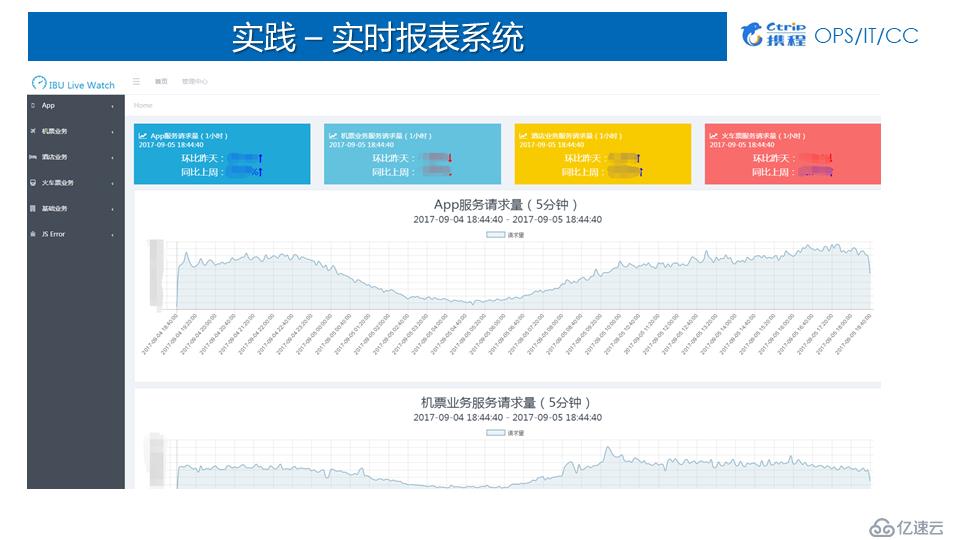
1.е®һж—¶жҠҘиЎЁз»ҹи®Ў
е®һж—¶жҠҘиЎЁз»ҹи®ЎдёҺеұ•зҺ°д№ҹжҳҜSpark StreamingдҪҝз”ЁиҫғеӨҡзҡ„дёҖдёӘеңәжҷҜпјҢж•°жҚ®еҸҜд»ҘеҹәдәҺProcess Timeз»ҹи®ЎпјҢд№ҹеҸҜд»ҘеҹәдәҺEvent Timeз»ҹи®ЎгҖӮз”ұдәҺжң¬иә«Spark StreamingдёҚеҗҢжү№ж¬Ўзҡ„jobеҸҜд»Ҙи§ҶдёәдёҖдёӘдёӘзҡ„ж»ҡеҠЁзӘ—еҸЈпјҢжҹҗдёӘзӢ¬з«Ӣзҡ„зӘ—еҸЈдёӯеҢ…еҗ«дәҶеӨҡдёӘж—¶й—ҙж®өзҡ„ж•°жҚ®пјҢиҝҷдҪҝеҫ—дҪҝз”ЁSparkStreamingеҹәдәҺEvent Timeз»ҹи®Ўж—¶еӯҳеңЁдёҖе®ҡзҡ„йҷҗеҲ¶гҖӮдёҖиҲ¬иҫғдёәеёёз”Ёзҡ„ж–№ејҸжҳҜз»ҹи®ЎжҜҸдёӘжү№ж¬ЎдёӯдёҚеҗҢж—¶й—ҙз»ҙеәҰзҡ„зҙҜз§ҜеҖје№¶еҜје…ҘеҲ°еӨ–йғЁзі»з»ҹпјҢеҰӮESпјӣ然еҗҺеңЁжҠҘиЎЁеұ•зҺ°зҡ„ж—¶еҹәдәҺж—¶й—ҙеҒҡдәҢж¬ЎиҒҡеҗҲиҺ·еҫ—е®Ңж•ҙзҡ„зҙҜеҠ еҖјжңҖз»ҲжұӮеҫ—иҒҡеҗҲеҖјгҖӮдёӢеӣҫеұ•зӨәдәҶжҗәзЁӢIBUеҹәдәҺSpark Streamingе®һзҺ°зҡ„е®һж—¶зңӢжқҝгҖӮ
2.е®һж—¶ж•°д»“
1пјүSpark Streamingиҝ‘е®һж—¶еӯҳеӮЁж•°жҚ®
еҰӮд»ҠеёӮйқўдёҠжңүеҪўеҪўГ—Г—Г—зҡ„е·Ҙе…·еҸҜд»Ҙд»ҺKafkaе®һж—¶ж¶Ҳиҙ№ж•°жҚ®е№¶иҝӣиЎҢиҝҮж»Өжё…жҙ—жңҖз»ҲиҗҪең°еҲ°еҜ№еә”зҡ„еӯҳеӮЁзі»з»ҹпјҢеҰӮпјҡCamusгҖҒFlumeзӯүгҖӮзӣёжҜ”иҫғдәҺжӯӨзұ»дә§е“ҒпјҢSpark Streamingзҡ„дјҳеҠҝйҰ–е…ҲеңЁдәҺеҸҜд»Ҙж”ҜжҢҒжӣҙдёәеӨҚжқӮзҡ„еӨ„зҗҶйҖ»иҫ‘пјҢе…¶ж¬ЎеҹәдәҺYarnзі»з»ҹзҡ„иө„жәҗи°ғеәҰдҪҝеҫ—Spark Streamingзҡ„иө„жәҗй…ҚзҪ®жӣҙеҠ зҒөжҙ»пјҢз”ЁжҲ·йҮҮз”ЁSpark Streamingе®һж—¶жҠҠж•°жҚ®еҶҷеҲ°HDFSжҲ–иҖ…еҶҷеҲ°HiveйҮҢйқўеҺ»гҖӮ
2пјүеҹәдәҺеҗ„з§Қ规еҲҷдҪңж•°жҚ®иҙЁйҮҸжЈҖжөӢ
еҹәдәҺSpark StreamingпјҢиҮӘе®ҡд№үmetricеҠҹиғҪеҜ№ж•°жҚ®зҡ„ж•°жҚ®йҮҸгҖҒеӯ—ж®өж•°гҖҒж•°жҚ®ж јејҸдёҺйҮҚеӨҚж•°жҚ®иҝӣиЎҢдәҶж•°жҚ®иҙЁйҮҸж ЎйӘҢдёҺзӣ‘жҺ§гҖӮ
3пјүеҹәдәҺиҮӘе®ҡд№үmetricе®һж—¶йў„иӯҰ
еҹәдәҺжҲ‘们е°ҒиЈ…жҸҗдҫӣзҡ„MetricжіЁеҶҢзі»з»ҹзЎ®е®ҡдёҖдәӣ规еҲҷпјҢ然еҗҺжҜҸдёӘжү№ж¬ЎеҹәдәҺиҝҷдәӣ规еҲҷеҒҡдёҖдёӘж ЎйӘҢпјҢиҝ”еӣһдёҖдёӘз»“жһңгҖӮиҝҷдёӘз»“жһңдјҡеҹәдәҺMetric sinkеҗҗеҮәжқҘпјҢеҗҗеҮәжқҘеҹәдәҺmetricsзҡ„з»“жһңеҒҡдёҖдёӘзӣ‘жҺ§гҖӮеҪ“еүҚжҲ‘们йҮҮз”ЁFlinkеҠ иҪҪTensorFlowжЁЎеһӢе®һж—¶еҒҡйў„жөӢгҖӮеҹәжң¬ж—¶ж•ҲжҖ§жҳҜж•°жҚ®дёҖж—ҰеҲ°иҫҫдёӨз§’й’ҹд№ӢеҶ…е°ұиғҪеӨҹжҠҠе‘ҠиӯҰдҝЎжҒҜе‘ҠеҮәжқҘпјҢз»ҷз”ЁжҲ·йқһеёёеҘҪзҡ„дҪ“йӘҢгҖӮ

1.Flink on K8S
еңЁжҗәзЁӢеҶ…йғЁжңүдёҖдәӣдёҚеҗҢзҡ„и®Ўз®—жЎҶжһ¶пјҢжңүе®һж—¶и®Ўз®—зҡ„пјҢжңүжңәеҷЁеӯҰд№ зҡ„пјҢиҝҳжңүзҰ»зәҝи®Ўз®—зҡ„пјҢжүҖд»ҘйңҖиҰҒдёҖдёӘз»ҹдёҖзҡ„еә•еұӮжЎҶжһ¶жқҘиҝӣиЎҢз®ЎзҗҶпјҢеӣ жӯӨеңЁжңӘжқҘе°ҶFlinkиҝҒ移еҲ°дәҶK8SдёҠпјҢиҝӣиЎҢз»ҹдёҖзҡ„иө„жәҗз®ЎжҺ§гҖӮ
2.Muiseе№іеҸ°жҺҘе…ҘFlink SQL
Muiseе№іеҸ°иҷҪ然жҺҘе…ҘдәҶFlinkпјҢдҪҶжҳҜз”ЁжҲ·иҝҳжҳҜеҫ—жүӢеҶҷд»Јз ҒпјҢжҲ‘们ејҖеҸ‘дәҶдёҖдёӘе®һж—¶зү№еҫҒе№іеҸ°пјҢз”ЁжҲ·еҸӘйңҖиҰҒеҶҷSQLпјҢеҚіеҹәдәҺFlinkзҡ„SQLе°ұеҸҜд»Ҙе®һж—¶йҮҮйӣҶз”ЁжҲ·жүҖйңҖиҰҒзҡ„жЁЎеһӢйҮҢйқўжҲ–иҖ…з”ЁеҲ°зҡ„зү№еҫҒгҖӮд№ӢеҗҺдјҡжҠҠе®һж—¶зү№еҫҒе№іеҸ°и·ҹе®һж—¶и®Ўз®—е№іеҸ°еҒҡиҝӣиЎҢеҗҲ并пјҢз”ЁжҲ·жңҖеҗҺеҸӘйңҖиҰҒеҶҷSQLе°ұеҸҜд»Ҙе®һзҺ°жүҖжңүзҡ„е®һж—¶дҪңдёҡе®һзҺ°гҖӮ
3.Jstormе…ЁйқўеҗҜз”ЁCgroup
еҪ“еүҚз”ұдәҺйғЁеҲҶеҺҶеҸІеҺҹеӣ еҜјиҮҙзҺ°еңЁеҫҲеӨҡдҪңдёҡи·‘еңЁJstormдёҠйқўпјҢеӣ жӯӨеҮәзҺ°дәҶиө„жәҗеҲҶй…ҚдёҚеқҮиЎЎзҡ„жғ…еҶөпјҢд№ӢеҗҺдјҡе…ЁйқўеҗҜз”ЁCgroupгҖӮ
4.еңЁзәҝжЁЎеһӢи®ӯз»ғ
жҗәзЁӢйғЁеҲҶйғЁй—ЁйңҖиҰҒе®һж—¶еңЁзәҝжЁЎеһӢи®ӯз»ғпјҢйҖҡиҝҮз”ЁSparkи®ӯз»ғдәҶжЁЎеһӢд№ӢеҗҺпјҢ然еҗҺдҪҝз”ЁSpark Streamingзҡ„жЁЎеһӢпјҢе®һж—¶еҒҡдёҖдёӘжӢҰжҲӘжҲ–иҖ…жҺ§еҲ¶пјҢеә”з”ЁеңЁйЈҺжҺ§зӯүеңәжҷҜгҖӮ
вҖ”endвҖ”
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ