您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
背景
一般大公司的机器学习团队,才会尝试构建大规模机器学习模型,如果去看百度、头条、阿里等分享,都有提到过这类模型。当然,大家现在都在说深度学习,但在推荐、搜索的场景,据我所知,ROI并没有很高,大家还是参考wide&deep的套路做,其中的deep并不是很deep。而大规模模型,是非常通用的一套框架,这套模型的优点是一种非常容易加特征,所以本质是拼特征的质和量,比如百度、头条号称特征到千亿规模。可能有些朋友不太了解大规模特征是怎么来的,举个简单的例子,假设你有百万的商品,然后你有几百个用户侧的profile,二者做个交叉特征,很容易规模就过10亿。特征规模大了之后,需要PS才能训练,这块非常感谢腾讯开源了Angel,拯救了我们这种没有足够资源的小公司,我们的实践效果非常好。
网上有非常多介绍大规模机器学习的资料,大部分的内容都集中在为何要做大规模机器学习模型以及Parameter Server相关的资料,但我们在实际实践中,发现大规模的特征预处理也有很多问题需要解决。有一次和明风(以前在阿里,后来去了腾讯做了开源的PS:angel)交流过这部分的工作为何没有人开源,结论大致是这部分的工作和业务相关性大,且讲明白了技术亮点不多,属于苦力活,所以没有开源的动力。
本文总结了蘑菇街搜索推荐在实践大规模机器学习模型中的特征处理系统的困难点。我们的技术选型是spark,虽然spark的机器学习部分不能支持大规模(我们的经验是LR模型的特征大概能到3000w的规模),但是它非常适合做特征处理。非常感谢组里的小伙伴@玄德 贡献此文。
整体流程图
这套方法论的特点是,虽然特征规模很大,但是非常稀疏。我们对特征集合进行onehot编码,每条样本的存储需求很小。由于规模太大,编码就变成一个比较严峻的问题。
连续统计类特征:电商领域里面,统计的ctr、gmv是非常重要的特征。
特征构建遇到的问题
1. 特征值替换成对应的数值索引过慢
组合后的训练样例中的特征值需要替换成对应的数值索引,生成onehot的特征格式。
特征索引映射表1的格式如下:
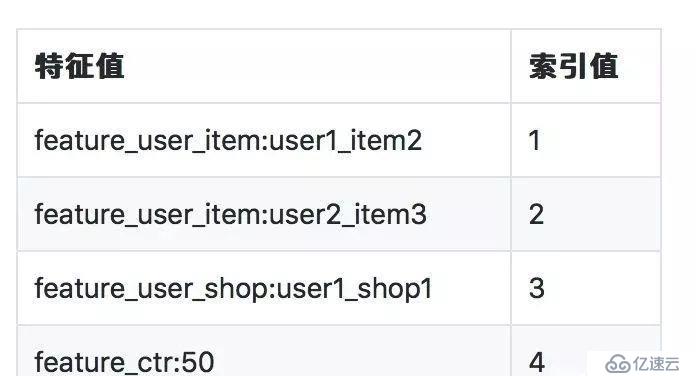
为了实现这种计算,我们需要对所有的特征做unique编码,然后将这个索引表join回原始的日志表,替换原始特征,后续流程使用编码的值做onehot,但这部分容易OOM,且性能有问题。于是我们着手优化这个过程.
首先我们想到的点是将索引表广播出去, 这样就不用走merge join, 不用对样例表进行shuffle操作,索引表在比较小的时候,大概是4KW的规模, 广播出去是没有问题的,实际内部实现走的是map-side join, 所以速度也是非常快的, 时间减少到一个小时内.
当索引表规模达到5KW的时候,直接整表广播, driver端gc就非常严重了, executor也非常不稳定, 当时比较费解, 单独把这部分数据加载到内存里面, 占用量只有大约executor内存的20%左右,为啥gc会这么严重呢?后面去看了下saprk的原理,解决了心中的疑惑. 因为spark2.x已经移除HTTPBroadcast, 仅有的一种实现是TorrentBroadcast.实现原理类似于大家常用的 BT下载技术。基本思想就是将数据分块成 data blocks,如果executor 取到了一些 data blocks,那么这个 executor 就可以被当作 data server 了,随着取到数据的 executor 越来越多,有更多的 data server 加入,数据就很快能传播到全部的 executor 那里去了.
在广播的过程中会将数据冗余一份到blockManager,供其他executor进行读取. 其原理如图所示:
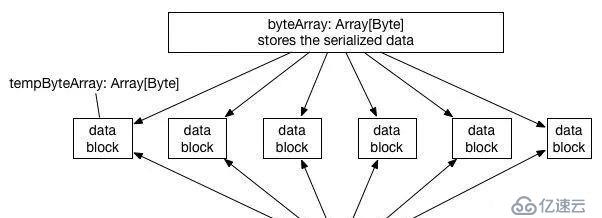
在广播的过程中, driver端和executor端都会有短暂的时间达到2倍的内存占用。
dirver端
driver端先把数据序列成byteArray, 切割成小块的data block再广播出去, 切割的过程,内存会不断接近2倍byteArray的大小, 直到切割完之后,将byteArray释放掉.
executor端
executor装载广播的数据是driver的反过程, 每次拿到一个data block之后, 就将其存放到blockManager, 同时通知driver的blockManagerMaster说这个block多了一个存储的地方,供其他executor下载.等executor把所有的block都从其他地方拿全之后,先申请一个Array[Byte],将block的数据进行反序列化之后得到原始数据.这个过程中和driver端应用,内存会不断接近2倍数据的大小, 直到反序列化完成.
通过了解了spark广播的实现, 可以解释广播5kw维特征的gc严重的问题.
随着实验特征的迭代,表2的列数会不断的增多,处理时间会随着列数的增多而线性增加, 特征索引的规模增多,会导致广播的过程中gc问题越来越严重, 直到OOM频繁出现.
这个阶段需要解决2个问题
1.需要高效得将表1的数据广播到各个executor
2.不能使用join列的方式来实现替换索引值
综合这两个问题, 我们想出了一个解决方案, 将表1先按照特征值排好序, 然后再重新编码, 用一个长度为max(索引值)长度的数组去存储, 索引值作为下标,对应的元素为特征值,将其广播到executor之后, 遍历日志的每一行的每一列, 实际上就是对应的特征值, 去上面的数组中二分查找出对应的索引值并替换掉.
使用下标数据存储表1, 特征值按照平均长度64个字符计算, 每个字符占用1个字节, 5千万维特征需要3.2G内存,广播的实际表现ok,1亿维特征的话需要占用6.4G内存, 按照广播的时候会有双倍内存占用的情况,gc会比较严重. 我们又想了一个办法, 将字符串hash成long,long仅占用8字节,比起存储字符串来说大大节省了空间, hash的有个问题是可能会冲突, 由于8字节的hash映射空间有 -2^63 到 2^63-1, 我们使用的是BKDRHash, 实际测下来冲突率很少,在业务可接受的范围, 这个方法可以大大节省占用的内存,1亿特征仅占用800M的内存, 广播起来毫无压力,对应的在遍历表2的时候, 需要先将特征值用同样的算法hash之后再进行查找. 经过这一轮优化之后, 相同资源的情况下,处理10亿行, 5KW维特征的时候, 耗时已经降低到半个小时了, 且内存情况相对稳定.
这种情况跑了一段时间之后, 特征规模上到亿了, 发现这一步的耗时已经上升到45分钟了,分析了下特征的分布,发现连续特征离散化的特征在日志出现的频率很高,由于是连续统计值,本身非常稠密,基本每一条数据都有其出现,但是这类特征在表1的分布不多, 这完全可以利用缓存把这类特征对应的索引值保存下来, 而没必要走hash之后再二分搜索,完全可以用少量的空间节省大量的时间. 实际实现的时候,判断需要查找的特征值是否符合以上的这种情况, 如果符合的话, 直接用guava缓存表2的特征值->表1的索引值,实际统计的缓存命中率是99.98888%, 实际耗时下降得也很明显, 从之前的45分钟降到17分钟.当然缓存并不是银弹,在算hash的时候误用了缓存, 导致这一步的计算反而变得慢了, 因为hash的组合实在是太多了, 缓存命中率只有10%左右, 而且hash计算复杂度并不高.在实际使用缓存的时候, 有必要去统计一下缓存的命中率.
2. Spark的一些经验
1.利用好spark UI的SQL预览, 做类似特征处理的ETL任务多关注下SQL, 做这类特征处理的工作的时候, 这个功能绝对是一把利器, 前期实现时间比较赶, 测试用例比较少, 在查实际运行逻辑错误的问题时, 可以利用前期对数据的分析结论结合SQL选项的流程图来定位数据出错的位置.
2.利用spark UI找出倾斜的任务,找到耗时比较长的Stages, 点进去看Aggregated Metrics by Executor
3.对单个task可以不用太关注, 如果某些Executor的耗时比起其他明显多了,一般都是数据清洗导致的(不排除某些慢节点)
4.利用UI确认是否需要缓存, 如果一个任务重复步骤非常频繁的,且任务的数据本地性都是RACK_LOCAL的 则要考虑将其上游结果缓存下来. 比如我们这里会统计单列特征的频次的时候
5.会将上游数据缓存下来, 但是数据量相对比较大, 我们选择将其缓存到磁盘,spark实现的自动分配内存和磁盘的方法有点问题,不知道是我们的姿势问题还是他的实现有bug。
生产版本小结
亿级别特征维度,几十亿样本(对全样本做了采样,效果损失不明显),二十分钟左右跑完。不过这个时间数据参考意义不大,和跑的资源和机器性能有关,而大厂在这块优势太大了。而本文核心解决的点是特征处理过程中,特征编码的索引达到亿级别时,数据处理性能差或者spark OOM的问题。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。