жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
еҶ…еӯҳи®Ўз®—жҢҮж•°жҚ®дәӢе…ҲеӯҳеӮЁдәҺеҶ…еӯҳпјҢеҗ„жӯҘйӘӨдёӯй—ҙз»“жһңдёҚиҗҪзЎ¬зӣҳзҡ„и®Ўз®—ж–№ејҸпјҢйҖӮеҗҲжҖ§иғҪиҰҒжұӮиҫғй«ҳпјҢ并еҸ‘иҫғеӨ§зҡ„жғ…еҶөгҖӮ
HANAгҖҒTimesTenзӯүеҶ…еӯҳж•°жҚ®еә“еҸҜе®һзҺ°еҶ…еӯҳи®Ўз®—пјҢдҪҶиҝҷзұ»дә§е“Ғд»·ж јжҳӮиҙөз»“жһ„еӨҚжқӮе®һж–Ҫеӣ°йҡҫпјҢжҖ»дҪ“жӢҘжңүжҲҗжң¬иҫғй«ҳгҖӮжң¬ж–Үд»Ӣз»Қзҡ„йӣҶз®—еҷЁеҗҢж ·еҸҜе®һзҺ°еҶ…еӯҳи®Ўз®—пјҢиҖҢдё”з»“жһ„з®ҖеҚ•е®һж–Ҫж–№дҫҝпјҢжҳҜдёҖз§ҚиҪ»йҮҸзә§еҶ…еӯҳи®Ўз®—еј•ж“ҺгҖӮ
дёӢйқўе°ұжқҘд»Ӣз»ҚдёҖдёӢйӣҶз®—еҷЁе®һзҺ°еҶ…еӯҳи®Ўз®—зҡ„дёҖиҲ¬иҝҮзЁӢгҖӮ
йӣҶз®—еҷЁжңүдёӨз§ҚйғЁзҪІж–№ејҸпјҡзӢ¬з«ӢйғЁзҪІгҖҒеҶ…еөҢйғЁзҪІпјҢеҢәеҲ«йҰ–е…ҲеңЁдәҺеҗҜеҠЁж–№ејҸжңүжүҖдёҚеҗҢгҖӮ
l зӢ¬з«ӢйғЁзҪІ
дҪңдёәзӢ¬з«ӢжңҚеҠЎйғЁзҪІж—¶пјҢйӣҶз®—еҷЁдёҺеә”з”Ёзі»з»ҹеҲҶеҲ«дҪҝз”ЁдёҚеҗҢзҡ„JVMпјҢдёӨиҖ…еҸҜд»ҘйғЁзҪІеңЁеҗҢдёҖеҸ°жңәеҷЁдёҠпјҢд№ҹеҸҜеҲҶеҲ«йғЁзҪІгҖӮеә”з”Ёзі»з»ҹйҖҡеёёдҪҝз”ЁйӣҶз®—еҷЁй©ұеҠЁпјҲODBCжҲ–JDBCпјүи®ҝй—®йӣҶз®—жңҚеҠЎпјҢд№ҹеҸҜйҖҡиҝҮHTTPи®ҝй—®гҖӮ
n WindowsдёӢеҗҜеҠЁзӢ¬з«ӢжңҚеҠЎпјҢжү§иЎҢвҖңе®үиЈ…зӣ®еҪ•\esProc\bin\esprocs.exeвҖқпјҢ然еҗҺзӮ№еҮ»вҖңеҗҜеҠЁвҖқжҢүй’®гҖӮ
n LinuxдёӢеә”жү§иЎҢвҖңе®үиЈ…зӣ®еҪ•/esProc/bin/ServerConsole.shвҖқгҖӮ
еҗҜеҠЁжңҚеҠЎеҷЁеҸҠй…ҚзҪ®еҸӮж•°зҡ„з»ҶиҠӮпјҢиҜ·еҸӮиҖғпјҡhttp://doc.raqsoft.com.cn/esproc/tutorial/fuwuqi.htmlгҖӮ
l еҶ…еөҢйғЁзҪІ
дҪңдёәеҶ…еөҢжңҚеҠЎйғЁзҪІж—¶пјҢйӣҶз®—еҷЁеҸӘиғҪдёҺJAVAеә”з”Ёзі»з»ҹйӣҶжҲҗпјҢдёӨиҖ…е…ұдә«JVMгҖӮеә”з”Ёзі»з»ҹйҖҡиҝҮJDBCи®ҝй—®еҶ…еөҢзҡ„йӣҶз®—жңҚеҠЎпјҢж— йңҖзү№ж„ҸеҗҜеҠЁгҖӮ
иҜҰжғ…еҸӮиҖғhttp://doc.raqsoft.com.cn/esproc/tutorial/bjavady.htmlгҖӮ
еҠ иҪҪж•°жҚ®жҳҜжҢҮйҖҡиҝҮйӣҶз®—еҷЁи„ҡжң¬пјҢе°Ҷж•°жҚ®еә“гҖҒж—Ҙеҝ—гҖҒWebServiceзӯүеӨ–йғЁж•°жҚ®иҜ»е…ҘеҶ…еӯҳзҡ„иҝҮзЁӢгҖӮ
жҜ”еҰӮOracleдёӯи®ўеҚ•иЎЁеҰӮдёӢпјҡ
и®ўеҚ•ID(key) | е®ўжҲ·ID | и®ўеҚ•ж—Ҙжңҹ | иҝҗиҙ§иҙ№ |
10248 | VINET | 2012-07-04 | 32.38 |
10249 | TOMSP | 2012-07-05 | 11.61 |
10250 | HANAR | 2012-07-08 | 65.83 |
10251 | VICTE | 2012-07-08 | 41.34 |
10252 | SUPRD | 2012-07-09 | 51.3 |
вҖҰ | вҖҰ | вҖҰ | вҖҰ |
и®ўеҚ•жҳҺз»ҶеҰӮдёӢпјҡ
и®ўеҚ•ID(key)(fk) | дә§е“ҒID(key) | еҚ•д»· | ж•°йҮҸ |
10248 | 17 | 14 | 12 |
10248 | 42 | 9 | 10 |
10248 | 72 | 34 | 5 |
10249 | 14 | 18 | 9 |
10249 | 51 | 42 | 40 |
вҖҰ | вҖҰ | вҖҰ | вҖҰ |
е°ҶдёҠиҝ°дёӨеј иЎЁеҠ иҪҪеҲ°еҶ…еӯҳпјҢеҸҜд»ҘдҪҝз”ЁдёӢйқўзҡ„йӣҶз®—еҷЁи„ҡжң¬пјҲinitData.dfxпјүпјҡ
A | |
1 | =connect("orcl") |
2 | =A1.query("select и®ўеҚ•ID,е®ўжҲ·ID,и®ўеҚ•ж—Ҙжңҹ,иҝҗиҙ§иҙ№ from и®ўеҚ•").keys(и®ўеҚ•ID) |
3 | =A1.query@x("select и®ўеҚ•ID,дә§е“ҒID,еҚ•д»·,ж•°йҮҸ from и®ўеҚ•жҳҺз»Ҷ") .keys(и®ўеҚ•ID,дә§е“ҒID) |
4 | =env(и®ўеҚ•,A2) |
5 | =env(и®ўеҚ•жҳҺз»Ҷ,A3) |
A1пјҡиҝһжҺҘOracleж•°жҚ®еә“гҖӮ
A2-A3пјҡжү§иЎҢSQLжҹҘиҜўпјҢеҲҶеҲ«еҸ–еҮәи®ўеҚ•иЎЁе’Ңи®ўеҚ•жҳҺз»ҶиЎЁгҖӮquery@xиЎЁзӨәжү§иЎҢSQLеҗҺе…ій—ӯиҝһжҺҘгҖӮеҮҪж•°keysеҸҜе»әз«Ӣдё»й”®пјҢеҰӮжһңж•°жҚ®еә“е·Іе®ҡд№үдё»й”®пјҢеҲҷж— йңҖдҪҝз”ЁиҜҘеҮҪж•°гҖӮ
A4-A5:е°ҶдёӨеј иЎЁеёёй©»еҶ…еӯҳпјҢеҲҶеҲ«е‘ҪеҗҚдёәи®ўеҚ•е’Ңи®ўеҚ•жҳҺз»ҶпјҢд»Ҙдҫҝе°ҶжқҘеңЁдёҡеҠЎи®Ўз®—ж—¶еј•з”ЁгҖӮеҮҪж•°envзҡ„дҪңз”ЁжҳҜи®ҫзҪ®/йҮҠж”ҫе…ЁеұҖе…ұдә«еҸҳйҮҸпјҢд»ҘдҫҝеңЁеҗҢдёҖдёӘJVMдёӢиў«е…¶д»–з®—жі•еј•з”ЁпјҢиҝҷйҮҢе°ҶеҶ…еӯҳиЎЁи®ҫдёәе…ЁеұҖеҸҳйҮҸпјҢд№ҹе°ұжҳҜе°Ҷе…ЁиЎЁж•°жҚ®дҝқеӯҳеңЁеҶ…еӯҳдёӯпјҢдҫӣе…¶д»–з®—жі•дҪҝз”ЁпјҢд№ҹе°ұе®һзҺ°дәҶеҶ…еӯҳи®Ўз®—гҖӮдәӢе®һдёҠпјҢеҜ№дәҺеӨ–еӯҳиЎЁгҖҒж–Ү件еҸҘжҹ„зӯүиө„жәҗд№ҹеҸҜд»Ҙз”ЁиҝҷдёӘеҠһжі•и®ҫдёәе…ЁеұҖеҸҳйҮҸпјҢдҪҝеҸҳйҮҸй©»з•ҷеңЁеҶ…еӯҳдёӯгҖӮ
и„ҡжң¬йңҖиҰҒжү§иЎҢжүҚиғҪз”ҹж•ҲгҖӮ
еҜ№дәҺеҶ…еөҢйғЁзҪІзҡ„йӣҶз®—жңҚеҠЎпјҢйҖҡеёёеңЁеә”з”Ёзі»з»ҹеҗҜеҠЁж—¶жү§иЎҢи„ҡжң¬гҖӮеҰӮжһңеә”з”Ёзі»з»ҹжҳҜJAVAзЁӢеәҸпјҢеҸҜд»ҘеңЁзЁӢеәҸдёӯйҖҡиҝҮJDBCжү§иЎҢinitData.dfxпјҢе…ій”®д»Јз ҒеҰӮдёӢпјҡ
1. com.esproc.jdbc.InternalConnection con=null; 2. try { 3. Class.forName("com.esproc.jdbc.InternalDriver"); 4. con =(com.esproc.jdbc.InternalConnection)DriverManager.getConnection("jdbc:esproc:local://"); 5. ResultSet rs = con.executeQuery("call initData()"); 6. } catch (SQLException e){ 7. out.println(e); 8. }finally{ 9. if (con!=null) con.close(); 10. } |
иҝҷзҜҮж–Үз« иҜҰз»Ҷд»Ӣз»ҚдәҶJAVAи°ғз”ЁйӣҶз®—еҷЁзҡ„иҝҮзЁӢhttp://doc.raqsoft.com.cn/esproc/tutorial/bjavady.html
еҰӮжһңеә”з”Ёзі»з»ҹжҳҜJAVA WebServerпјҢйӮЈд№ҲйңҖиҰҒзј–еҶҷдёҖдёӘServletпјҢеңЁServletзҡ„initж–№жі•дёӯйҖҡиҝҮJDBCжү§иЎҢinitData.dfxпјҢеҗҢж—¶е°ҶиҜҘservletи®ҫзҪ®дёәеҗҜеҠЁзұ»пјҢ并еңЁweb.xmlйҮҢиҝӣиЎҢеҰӮдёӢй…ҚзҪ®пјҡ
<servlet> |
еҜ№дәҺзӢ¬з«ӢйғЁзҪІзҡ„йӣҶз®—жңҚеҠЎеҷЁпјҢJAVAеә”з”Ёзі»з»ҹеҗҢж ·иҰҒз”ЁJDBCжҺҘеҸЈжү§иЎҢйӣҶз®—еҷЁи„ҡжң¬пјҢз”Ёжі•дёҺеҶ…еөҢжңҚеҠЎзұ»дјјгҖӮеҢәеҲ«еңЁдәҺи„ҡжң¬еӯҳж”ҫдәҺиҝңз«ҜпјҢжүҖд»ҘйңҖиҰҒеғҸдёӢйқўиҝҷж ·жҢҮе®ҡжңҚеҠЎеҷЁең°еқҖе’Ңз«ҜеҸЈпјҡ
st = con.createStatement(); st.executeQuery("=callx(\вҖңinitData.dfx\вҖқ;[\вҖң127.0.0.1:8281\вҖқ])"); |
еҰӮжһңеә”з”Ёзі»з»ҹйқһJAVAжһ¶жһ„пјҢеҲҷеә”еҪ“дҪҝз”ЁODBCжү§иЎҢйӣҶз®—еҷЁи„ҡжң¬пјҢиҜҰи§Ғhttp://doc.raqsoft.com.cn/esproc/tutorial/odbcbushu.html
еҜ№дәҺзӢ¬з«ӢйғЁзҪІзҡ„жңҚеҠЎеҷЁпјҢд№ҹеҸҜд»Ҙи„ұзҰ»еә”з”ЁзЁӢеәҸпјҢеңЁе‘Ҫд»ӨиЎҢжүӢе·Ҙжү§иЎҢinitData.dfxгҖӮиҝҷз§Қжғ…еҶөдёӢйңҖиҰҒеҶҚеҶҷдёҖдёӘи„ҡжң¬пјҲеҰӮrunOnServer.dfxпјүпјҡ
A | |
1 | =callx(вҖңinitData.dfxвҖқ;[вҖң127.0.0.1:8281вҖқ]) |
然еҗҺеңЁе‘Ҫд»ӨиЎҢз”Ёesprocx.exeи°ғз”ЁrunOnServer.dfxпјҡ
D:\raqsoft64\esProc\bin>esprocx runOnServer.dfx |
LinuxдёӢз”Ёжі•зұ»дјјпјҢеҸӮиҖғhttp://doc.raqsoft.com.cn/esproc/tutorial/minglinghang.html
ж•°жҚ®еҠ иҪҪеҲ°еҶ…еӯҳд№ӢеҗҺпјҢе°ұеҸҜд»Ҙзј–еҶҷеҗ„з§Қз®—жі•иҝӣиЎҢи®ҝй—®пјҢжү§иЎҢ计算并иҺ·еҫ—з»“жһңпјҢдёӢйқўдёҫдҫӢиҜҙжҳҺпјҡд»Ҙе®ўжҲ·IDдёәеҸӮж•°пјҢз»ҹи®ЎиҜҘе®ўжҲ·жҜҸе№ҙжҜҸжңҲзҡ„и®ўеҚ•ж•°йҮҸгҖӮ
иҜҘз®—жі•еҜ№еә”зҡ„Oracleдёӯзҡ„SQLиҜӯеҸҘеҰӮдёӢпјҡ
select to_char(и®ўеҚ•ж—Ҙжңҹ,'yyyy') AS е№ҙд»Ҫ,to_char(и®ўеҚ•ж—Ҙжңҹ,'MM') AS жңҲд»Ҫ, count(1) AS и®ўеҚ•ж•°йҮҸ from и®ўеҚ• whereе®ўжҲ·ID=? group by to_char(и®ўеҚ•ж—Ҙжңҹ,'yyyy'),to_char(и®ўеҚ•ж—Ҙжңҹ,'MM') |
еңЁйӣҶз®—еҷЁдёӯпјҢеә”еҪ“зј–еҶҷеҰӮдёӢдёҡеҠЎз®—жі•пјҲalgorithm_1.dfxпјү
A | |
1 | =и®ўеҚ•.select@m(е®ўжҲ·ID==pCustID).groups(year(и®ўеҚ•ж—Ҙжңҹ):е№ҙд»Ҫ, month(и®ўеҚ•ж—Ҙжңҹ):жңҲд»Ҫ;count(1):и®ўеҚ•ж•°йҮҸ) |
дёәж–№дҫҝи°ғиҜ•е’Ңз»ҙжҠӨпјҢд№ҹеҸҜд»ҘеҲҶжӯҘйӘӨзј–еҶҷпјҡ
A | |
1 | =и®ўеҚ•.select@m(е®ўжҲ·ID==pCustID) |
2 | =A1.groups(year(и®ўеҚ•ж—Ҙжңҹ):е№ҙд»Ҫ, month(и®ўеҚ•ж—Ҙжңҹ):жңҲд»Ҫ; count(1):и®ўеҚ•ж•°йҮҸ) |
A1пјҡжҢүе®ўжҲ·IDиҝҮж»Өж•°жҚ®гҖӮе…¶дёӯпјҢвҖңи®ўеҚ•вҖқе°ұжҳҜеҠ иҪҪж•°жҚ®ж—¶е®ҡд№үзҡ„е…ЁеұҖеҸҳйҮҸпјҢpCustIDжҳҜеӨ–йғЁеҸӮж•°пјҢз”ЁдәҺжҢҮе®ҡйңҖиҰҒз»ҹи®Ўзҡ„е®ўжҲ·IDпјҢеҮҪж•°selectжү§иЎҢжҹҘиҜўгҖӮ@mиЎЁзӨә并иЎҢи®Ўз®—пјҢеҸҜжҳҫи‘—жҸҗй«ҳжҖ§иғҪгҖӮ
A2пјҡжү§иЎҢеҲҶз»„жұҮжҖ»пјҢиҫ“еҮәи®Ўз®—з»“жһңгҖӮйӣҶз®—еҷЁй»ҳи®Өиҝ”еӣһжңүиЎЁиҫҫејҸзҡ„жңҖеҗҺдёҖдёӘеҚ•е…ғж јпјҢд№ҹе°ұжҳҜA2гҖӮеҰӮжһңиҰҒиҝ”еӣһжҢҮе®ҡеҚ•е…ғзҡ„еҖјпјҢеҸҜд»Ҙз”ЁreturnиҜӯеҸҘ
еҪ“pCustID=вҖқVINETвҖқж—¶пјҢи®Ўз®—з»“жһңеҰӮдёӢпјҡ
е№ҙд»Ҫ | жңҲд»Ҫ | и®ўеҚ•ж•°йҮҸ |
2012 | 7 | 3 |
2012 | 8 | 2 |
2012 | 9 | 1 |
2013 | 11 | 4 |
йңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢеҒҮеҰӮеӨҡдёӘдёҡеҠЎи®Ўз®—йғҪиҰҒеҜ№е®ўжҲ·IDиҝӣиЎҢжҹҘиҜўпјҢйӮЈдёҚеҰЁеңЁеҠ иҪҪж•°жҚ®ж—¶жҠҠи®ўеҚ•жҢүе®ўжҲ·IDжҺ’еәҸпјҢиҝҷж ·еҗҺз»ӯдёҡеҠЎз®—жі•дёӯе°ұеҸҜд»ҘдҪҝз”ЁдәҢеҲҶжі•иҝӣиЎҢеҝ«йҖҹжҹҘиҜўпјҢд№ҹе°ұжҳҜдҪҝз”Ёselect@bеҮҪж•°гҖӮе…·дҪ“е®һзҺ°дёҠпјҢinitData.dfxдёӯSQLеә”еҪ“ж”№жҲҗпјҡ
=A1.query("select и®ўеҚ•ID,е®ўжҲ·ID,и®ўеҚ•ж—Ҙжңҹ,иҝҗиҙ§иҙ№ from и®ўеҚ• order by е®ўжҲ·ID") |
зӣёеә”зҡ„пјҢalgorithm_1.dfxдёӯзҡ„жҹҘиҜўеә”еҪ“ж”№жҲҗпјҡ
=и®ўеҚ•.select@b(е®ўжҲ·ID==pCustID) |
жү§иЎҢи„ҡжң¬иҺ·еҫ—з»“жһңзҡ„ж–№жі•пјҢеүҚйқўе·Із»ҸжҸҗиҝҮпјҢдёӢйқўйҮҚзӮ№иҜҙиҜҙжҠҘиЎЁпјҢиҝҷзұ»жңҖеёёз”Ёзҡ„еә”з”ЁзЁӢеәҸгҖӮ
з”ұдәҺжҠҘиЎЁе·Ҙе…·йғҪжңүеҸҜи§ҶеҢ–и®ҫи®Ўз•ҢйқўпјҢжүҖд»Ҙж— йңҖз”ЁJAVAд»Јз Ғи°ғз”ЁйӣҶз®—еҷЁпјҢеҸӘйңҖе°Ҷж•°жҚ®жәҗй…ҚзҪ®дёәжҢҮеҗ‘йӣҶз®—жңҚеҠЎпјҢеңЁжҠҘиЎЁе·Ҙе…·дёӯд»ҘеӯҳеӮЁиҝҮзЁӢзҡ„еҪўејҸи°ғз”ЁйӣҶз®—еҷЁи„ҡжң¬гҖӮ
еҜ№дәҺеҶ…еөҢйғЁзҪІзҡ„йӣҶз®—жңҚеҠЎеҷЁпјҢи°ғз”ЁиҜӯеҸҘеҰӮдёӢпјҡ
call algorithm_1(вҖқVINETвҖқ) |
з”ұдәҺжң¬дҫӢдёӯз®—жі•йқһеёёз®ҖеҚ•пјҢжүҖд»ҘдәӢе®һдёҠеҸҜд»ҘдёҚз”Ёзј–еҶҷзӢ¬з«Ӣзҡ„dfxи„ҡжң¬пјҢиҖҢжҳҜеңЁжҠҘиЎЁдёӯзӣҙжҺҘд»ҘSQLж–№ејҸд№ҰеҶҷиЎЁиҫҫејҸпјҡ
=и®ўеҚ•.select@m(е®ўжҲ·ID==вҖқVINETвҖқ).groups(year(и®ўеҚ•ж—Ҙжңҹ):е№ҙд»Ҫ, month(и®ўеҚ•ж—Ҙжңҹ):жңҲд»Ҫ;count(1):и®ўеҚ•ж•°йҮҸ) |
еҜ№дәҺзӢ¬з«ӢйғЁзҪІзҡ„йӣҶз®—жңҚеҠЎеҷЁпјҢиҝңзЁӢи°ғз”ЁиҜӯеҸҘеҰӮдёӢпјҡ
=callx(вҖңalgorithm_1.dfxвҖқ,вҖқVINETвҖқ;[вҖң127.0.0.1:8281вҖқ]) |
жңүж—¶пјҢйңҖиҰҒеңЁеҶ…еӯҳиҝӣиЎҢзҡ„дёҡеҠЎз®—жі•иҫғе°‘пјҢиҖҢweb.xmlдёҚж–№дҫҝж·»еҠ еҗҜеҠЁзұ»пјҢиҝҷж—¶еҸҜд»ҘеңЁдёҡеҠЎз®—жі•дёӯи°ғз”ЁеҲқе§ӢеҢ–и„ҡжң¬пјҢиҫҫеҲ°иҮӘеҠЁеҲқе§ӢеҢ–зҡ„ж•ҲжһңпјҢеҗҢж—¶д№ҹзңҒеҺ»зј–еҶҷservletзҡ„иҝҮзЁӢгҖӮе…·дҪ“и„ҡжң¬еҰӮдёӢпјҡ
A | B | |
1 | if !ifv(и®ўеҚ•) | =call("initData.dfx") |
2 | =и®ўеҚ•.select@m(е®ўжҲ·ID==pCustID) | |
3 | =A2.groups(year(и®ўеҚ•ж—Ҙжңҹ):е№ҙд»Ҫ, month(и®ўеҚ•ж—Ҙжңҹ):жңҲд»Ҫ; count(1):и®ўеҚ•ж•°йҮҸ) |
A1-B1:еҲӨж–ӯжҳҜеҗҰеӯҳеңЁе…ЁеұҖеҸҳйҮҸвҖңи®ўеҚ•жҳҺз»ҶвҖқпјҢеҰӮжһңдёҚеӯҳеңЁпјҢеҲҷжү§иЎҢеҲқе§ӢеҢ–ж•°жҚ®и„ҡжң¬initData.dfxгҖӮ
A2-A3:继з»ӯжү§иЎҢеҺҹз®—жі•гҖӮ
еүҚйқўдҫӢеӯҗз”ЁеҲ°дәҶselectеҮҪж•°пјҢиҝҷдёӘеҮҪж•°зҡ„дҪңз”ЁдёҺSQLзҡ„whereиҜӯеҸҘзұ»дјјпјҢйғҪеҸҜиҝӣиЎҢжқЎд»¶жҹҘиҜўпјҢдҪҶдёӨиҖ…зҡ„еә•еұӮеҺҹзҗҶеӨ§дёҚзӣёеҗҢгҖӮwhereиҜӯеҸҘжҜҸж¬ЎйғҪдјҡеӨҚеҲ¶дёҖйҒҚж•°жҚ®пјҢз”ҹжҲҗж–°зҡ„з»“жһңйӣҶпјӣиҖҢselectеҮҪж•°еҸӘжҳҜеј•з”ЁеҺҹжқҘзҡ„и®°еҪ•жҢҮй’ҲпјҢ并дёҚдјҡеӨҚеҲ¶ж•°жҚ®гҖӮд»ҘжҢүе®ўжҲ·жҹҘиҜўи®ўеҚ•дёәдҫӢпјҢеј•з”Ёе’ҢеӨҚеҲ¶зҡ„еҢәеҲ«еҰӮдёӢеӣҫжүҖзӨәпјҡ
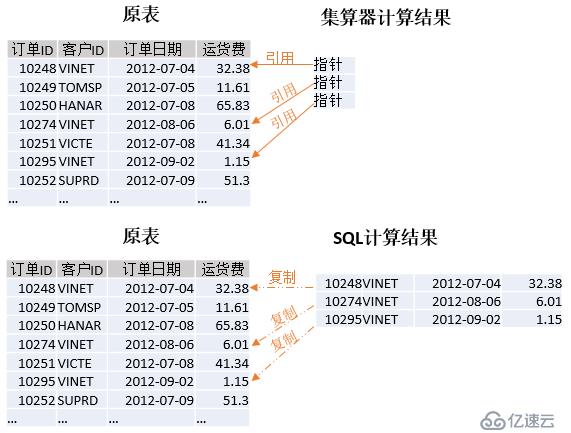
еҸҜд»ҘзңӢеҲ°пјҢйӣҶз®—еҷЁз”ұдәҺйҮҮз”ЁдәҶеј•з”ЁжңәеҲ¶пјҢжүҖд»Ҙи®Ўз®—з»“жһңеҚ з”Ёз©әй—ҙжӣҙе°ҸпјҢи®Ўз®—жҖ§иғҪжӣҙй«ҳпјҲеҲҶй…ҚеҶ…еӯҳжӣҙеҝ«пјүгҖӮжӯӨеӨ–пјҢеҜ№дәҺдёҠиҝ°и®Ўз®—з»“жһңиҝҳеҸҜеҶҚж¬ЎиҝӣиЎҢжҹҘиҜўпјҢйӣҶз®—еҷЁдёӯж–°з»“жһңйӣҶеҗҢж ·еј•з”ЁжңҖеҲқзҡ„и®°еҪ•пјҢиҖҢSQLе°ұиҰҒеӨҚеҲ¶еҮәеҫҲеӨҡж–°и®°еҪ•гҖӮ
йҷӨдәҶжҹҘиҜўд№ӢеӨ–пјҢиҝҳжңүеҫҲеӨҡйӣҶз®—еҷЁз®—жі•йғҪйҮҮз”ЁдәҶеј•з”ЁжҖқз»ҙпјҢжҜ”еҰӮжҺ’еәҸгҖҒйӣҶеҗҲдәӨ并иЎҘгҖҒе…іиҒ”гҖҒеҪ’并гҖӮ
еӣһйЎҫеүҚйқўжЎҲдҫӢпјҢеҸҜд»ҘзңӢеҲ°йӣҶз®—еҷЁиҜӯеҸҘе’ҢSQLиҜӯеҸҘеӯҳеңЁеҰӮдёӢзҡ„еҜ№еә”е…ізі»пјҡ
и®Ўз®— | SQL | йӣҶз®—еҷЁ |
жҹҘиҜў | select | select |
жқЎд»¶ | WhereвҖҰ.и®ўеҚ•.е®ўжҲ·ID=? | и®ўеҚ•ID.е®ўжҲ·ID==pCustID |
еҲҶз»„жұҮжҖ» | group by | groups
|
ж—ҘжңҹеҮҪж•° | to_char(и®ўеҚ•ж—Ҙжңҹ,'yyyy') | year(и®ўеҚ•ж—Ҙжңҹ) |
еҲ«еҗҚ | AS е№ҙд»Ҫ | :е№ҙд»Ҫ |
дәӢе®һдёҠпјҢйӣҶз®—еҷЁж”ҜжҢҒе®Ңе–„зҡ„з»“жһ„еҢ–ж•°жҚ®з®—жі•пјҢжҜ”еҰӮпјҡ
l GROUP BYвҖҰHAVING
A | ||
1 | =и®ўеҚ•.groups(year(и®ўеҚ•ж—Ҙжңҹ):е№ҙд»Ҫ;count(1):и®ўеҚ•ж•°йҮҸ).select(и®ўеҚ•ж•°йҮҸ>300) |
l ORDER BYвҖҰASC/DESC
A | ||
1 | =и®ўеҚ•.sort(е®ўжҲ·ID,-и®ўеҚ•ж—Ҙжңҹ) | /жҺ’еәҸеҸӘжҳҜеҸҳжҚўдәҶи®°еҪ•жҢҮй’Ҳзҡ„ж¬ЎеәҸпјҢ并没жңүеӨҚеҲ¶и®°еҪ• |
l DISTINCT
A | ||
1 | =и®ўеҚ•.id(year(и®ўеҚ•ж—Ҙжңҹ)) | /еҸ–е”ҜдёҖеҖј |
2 | =A1.(е®ўжҲ·ID) | /жүҖжңүеҮәзҺ°еҖј |
3 | =и®ўеҚ•.([ year(и®ўеҚ•ж—Ҙжңҹ),е®ўжҲ·ID]) | /з»„еҗҲзҡ„жүҖжңүеҮәзҺ°еҖј |
l UNION/UNION ALL/INTERSECT/MINUS
A | ||
1 | =и®ўеҚ•.select(иҝҗиҙ§иҙ№>100) | |
2 | =и®ўеҚ•.select([2011,2012].pos(year(и®ўеҚ•ж—Ҙжңҹ)) | |
3 | =A2|A3 | /UNION ALL |
4 | =A2&A3 | /UNION |
5 | =A2^A3 | /INTERSECTION |
6 | =A2\A3 | /DIFFERENCE |
дёҺSQLзҡ„дәӨ并иЎҘдёҚеҗҢпјҢйӣҶз®—еҷЁеҸӘжҳҜз»„еҗҲи®°еҪ•жҢҮй’ҲпјҢ并дёҚдјҡеӨҚеҲ¶и®°еҪ•гҖӮ
l SELECT вҖҰ FROM (SELECT вҖҰ)
A | ||
1 | =и®ўеҚ•.select(и®ўеҚ•ж—Ҙжңҹ>date("2010-01-01")) | /жү§иЎҢжҹҘиҜў |
2 | =A1.count() | /еҜ№з»“жһңйӣҶеҶҚз»ҹи®Ў |
l SELECT (SELECT вҖҰ FROM) FROM
A | ||
1 | =и®ўеҚ•.new(и®ўеҚ•ID,е®ўжҲ·.select(е®ўжҲ·ID==и®ўеҚ•.е®ўжҲ·ID).е®ўжҲ·еҗҚ) | /е®ўжҲ·иЎЁе’Ңи®ўеҚ•иЎЁйғҪжҳҜе…ЁеұҖеҸҳйҮҸ |
l CURSOR/FETCH
жёёж ҮжңүдёӨз§Қз”Ёжі•пјҢе…¶дёҖжҳҜеӨ–йғЁJAVAзЁӢеәҸи°ғз”ЁйӣҶз®—еҷЁпјҢйӣҶз®—еҷЁиҝ”еӣһжёёж ҮпјҢжҜ”еҰӮдёӢйқўи„ҡжң¬пјҡ
A | ||
1 | =и®ўеҚ•.select(и®ўеҚ•ж—Ҙжңҹ>=date("2010-01-01")).cursor() |
JAVAиҺ·еҫ—жёёж ҮеҗҺеҸҜ继з»ӯеӨ„зҗҶпјҢдёҺJDBCи®ҝй—®жёёж Үзҡ„ж–№жі•зӣёеҗҢгҖӮ
е…¶дәҢпјҢеңЁйӣҶз®—еҷЁеҶ…йғЁдҪҝз”Ёжёёж ҮпјҢйҒҚеҺҶ并е®ҢжҲҗи®Ўз®—гҖӮжҜ”еҰӮдёӢйқўи„ҡжң¬пјҡ
A | B | |||
1 | =и®ўеҚ•.cursor() | |||
2 | for A1,100 | =A2.select(и®ўеҚ•ж—Ҙжңҹ>=date("2010-01-01")) | /жҜҸж¬ЎеҸ–100жқЎиҝҗз®— | |
3 | вҖҰ |
йӣҶз®—еҷЁйҖӮеҗҲи§ЈеҶіеӨҚжқӮдёҡеҠЎйҖ»иҫ‘зҡ„и®Ўз®—пјҢдҪҶиҖғиҷ‘еҲ°з®ҖеҚ•з®—жі•еҚ еӨ§еӨҡж•°пјҢиҖҢеҫҲеӨҡзЁӢеәҸе‘ҳд№ жғҜдҪҝз”ЁSQLиҜӯеҸҘпјҢжүҖд»ҘйӣҶз®—еҷЁд№ҹж”ҜжҢҒжүҖи°“вҖңз®ҖеҚ•SQLвҖқзҡ„иҜӯжі•гҖӮжҜ”еҰӮalgorithm_1.dfxд№ҹеҸҜеҶҷдҪңпјҡ
A | |
1 | $() select year(и®ўеҚ•ж—Ҙжңҹ) AS е№ҙд»Ҫ,month(и®ўеҚ•ж—Ҙжңҹ) AS жңҲд»Ҫ,count(1) AS и®ўеҚ•ж•°йҮҸ From {и®ўеҚ•} whereи®ўеҚ•.е®ўжҲ·ID='VINET' group by year(и®ўеҚ•ж—Ҙжңҹ),month(и®ўеҚ•ж—Ҙжңҹ) |
дёҠиҝ°и„ҡжң¬йҖҡз”ЁдәҺд»»ж„ҸSQLпјҢ$()иЎЁзӨәжү§иЎҢй»ҳи®Өж•°жҚ®жәҗпјҲйӣҶз®—еҷЁпјүзҡ„SQLиҜӯеҸҘпјҢеҰӮжһңжҢҮе®ҡж•°жҚ®жәҗеҗҚз§°жҜ”еҰӮ$(orcl)пјҢеҲҷеҸҜд»Ҙжү§иЎҢзӣёеә”ж•°жҚ®еә“пјҲж•°жҚ®жәҗеҗҚз§°жҳҜorclзҡ„Oracleж•°жҚ®еә“пјүзҡ„SQLиҜӯеҸҘгҖӮ
from {}иҜӯеҸҘеҸҜд»Һд»»ж„ҸйӣҶз®—еҷЁиЎЁиҫҫејҸеҸ–ж•°пјҢжҜ”еҰӮпјҡfrom {и®ўеҚ•.groups(year(и®ўеҚ•ж—Ҙжңҹ):е№ҙд»Ҫ;count(1):и®ўеҚ•ж•°йҮҸ)}
from д№ҹеҸҜд»Һж–Ү件жҲ–excelеҸ–ж•°пјҢжҜ”еҰӮпјҡfrom d:/emp.xlsx
з®ҖеҚ•SQLеҗҢж ·ж”ҜжҢҒjoinвҖҰonвҖҰиҜӯеҸҘпјҢдҪҶз”ұдәҺSQLиҜӯеҸҘпјҲжҢҮд»»ж„ҸRDBпјүеңЁе…іиҒ”з®—жі•дёҠжҖ§иғҪиҫғе·®пјҢеӣ жӯӨдёҚе»әи®®иҪ»жҳ“дҪҝз”ЁгҖӮеҜ№дәҺе…іиҒ”иҝҗз®—пјҢйӣҶз®—еҷЁжңүдё“й—Ёзҡ„й«ҳжҖ§иғҪе®һзҺ°ж–№жі•пјҢеҗҺз»ӯз« иҠӮдјҡжңүд»Ӣз»ҚгҖӮ
з®ҖеҚ•SQLзҡ„иҜҰжғ…еҸҜд»ҘеҸӮиҖғпјҡhttp://doc.raqsoft.com.cn/esproc/func/dbquerysql.html#db_sql_
SQLеҹәдәҺж— еәҸйӣҶеҗҲеҒҡиҝҗз®—пјҢдёҚиғҪзӣҙжҺҘз”ЁеәҸеҸ·еҸ–ж•°пјҢеҸӘиғҪдёҙж—¶з”ҹжҲҗеәҸеҸ·пјҢж•ҲзҺҮдҪҺдё”з”Ёжі•з№ҒзҗҗгҖӮйӣҶз®—еҷЁдёҺSQLдҪ“зі»дёҚеҗҢпјҢиғҪеӨҹеҹәдәҺжңүеәҸйӣҶеҗҲиҝҗз®—пјҢеҸҜд»ҘзӣҙжҺҘз”ЁеәҸеҸ·еҸ–ж•°гҖӮдҫӢеҰӮпјҡ
A | ||
1 | =и®ўеҚ•.sort(и®ўеҚ•ж—Ҙжңҹ) | /еҰӮжһңеҠ иҪҪж—¶е·ІжҺ’еәҸпјҢиҝҷжӯҘеҸҜзңҒз•Ҙ |
2 | =A1.m(1).и®ўеҚ•ID | /第дёҖжқЎ |
3 | =A1.m(-1).и®ўеҚ•ID | /жңҖеҗҺдёҖжқЎ |
4 | =A1.m(to(3,5)) | /第3-5жқЎ |
еҮҪж•°m()еҸҜжҢүжҢҮе®ҡеәҸеҸ·иҺ·еҸ–жҲҗе‘ҳпјҢеҸӮж•°дёәиҙҹиЎЁзӨәеҖ’еәҸгҖӮеҸӮж•°д№ҹеҸҜд»ҘжҳҜйӣҶеҗҲпјҢжҜ”еҰӮm([3,4,5])гҖӮиҖҢеҲ©з”ЁеҮҪж•°to()еҸҜжҢүиө·жӯўеәҸеҸ·з”ҹжҲҗйӣҶеҗҲпјҢto(3,5)=[3,4,5]гҖӮ
еүҚйқўдҫӢеӯҗжҸҗеҲ°иҝҮдәҢеҲҶжі•жҹҘиҜўselect@bпјҢе…¶е®һе·Із»ҸеҲ©з”ЁдәҶйӣҶз®—еҷЁжңүеәҸи®ҝй—®зҡ„зү№зӮ№гҖӮ
жңүж—¶еҖҷжҲ‘们жғіеҸ–еүҚ NеҗҚпјҢ常规зҡ„жҖқи·Ҝе°ұжҳҜе…ҲжҺ’еәҸпјҢеҶҚжҢүдҪҚзҪ®еҸ–еүҚNдёӘжҲҗе‘ҳпјҢйӣҶз®—еҷЁи„ҡжң¬еҰӮдёӢпјҡ
=и®ўеҚ•.sort(и®ўеҚ•ж—Ҙжңҹ).m(to(100)) |
еҜ№еә”SQLеҶҷжі•еҰӮдёӢпјҡ
select top(100) * from и®ўеҚ• order by и®ўеҚ•ж—Ҙжңҹ --MSSQL select * from (select * from и®ўеҚ• order by и®ўеҚ•ж—Ҙжңҹ) where rownum<=100 --Oracle |
дҪҶдёҠиҝ°еёёи§„жҖқи·ҜиҰҒеҜ№ж•°жҚ®йӣҶеӨ§жҺ’еәҸпјҢиҝҗз®—ж•ҲзҺҮеҫҲдҪҺгҖӮйҷӨдәҶ常规жҖқи·ҜпјҢйӣҶз®—еҷЁиҝҳжңүжӣҙй«ҳж•Ҳзҡ„е®һзҺ°ж–№жі•пјҡдҪҝз”ЁеҮҪж•°topгҖӮ
=и®ўеҚ•.top(100;и®ўеҚ•ж—Ҙжңҹ) |
еҮҪж•°topеҸӘжҺ’еәҸеҮәи®ўеҚ•ж—ҘжңҹжңҖж—©зҡ„NжқЎи®°еҪ•пјҢ然еҗҺдёӯж–ӯжҺ’еәҸз«ӢеҲ»иҝ”еӣһпјҢиҖҢдёҚжҳҜ常规жҖқи·ҜйӮЈж ·иҝӣиЎҢе…ЁйҮҸжҺ’еәҸгҖӮз”ұдәҺеә•еұӮжЁЎеһӢзҡ„йҷҗеҲ¶пјҢSQLдёҚж”ҜжҢҒиҝҷз§Қй«ҳжҖ§иғҪз®—жі•гҖӮ
еҮҪж•°topиҝҳеҸҜеә”з”ЁдәҺи®Ўз®—еҲ—пјҢжҜ”еҰӮжӢҹеҜ№и®ўеҚ•йҮҮеҸ–ж–°зҡ„иҝҗиҙ§иҙ№и§„еҲҷпјҢжұӮ新规еҲҷдёӢиҝҗиҙ§иҙ№жңҖеӨ§зҡ„еүҚ100жқЎи®ўеҚ•пјҢиҖҢ新规еҲҷжҳҜпјҡеҰӮжһңеҺҹиҝҗиҙ§иҙ№еӨ§дәҺзӯүдәҺ1000пјҢеҲҷиҝҗиҙ§иҙ№жү“е…«жҠҳгҖӮ
йӣҶз®—еҷЁи„ҡжң¬дёәпјҡ
=и®ўеҚ•.top(-100;if(иҝҗиҙ§иҙ№>=1000,иҝҗиҙ§иҙ№*0.8,иҝҗиҙ§иҙ№)) |
е…іиҒ”и®Ўз®—жҳҜе…ізі»еһӢж•°жҚ®еә“зҡ„ж ёеҝғз®—жі•пјҢеңЁеҶ…еӯҳи®Ўз®—дёӯеә”з”Ёе№ҝжіӣпјҢжҜ”еҰӮпјҡз»ҹи®ЎжҜҸе№ҙжҜҸжңҲзҡ„и®ўеҚ•ж•°йҮҸе’Ңи®ўеҚ•йҮ‘йўқгҖӮ
иҜҘз®—жі•еҜ№еә”Oracleзҡ„SQLиҜӯеҸҘдёәпјҡ
select to_char(и®ўеҚ•.и®ўеҚ•ж—Ҙжңҹ,'yyyy') AS е№ҙд»Ҫ,to_char(и®ўеҚ•.и®ўеҚ•ж—Ҙжңҹ,'MM') AS жңҲд»ҪпјҢsum(и®ўеҚ•жҳҺз»Ҷ.еҚ•д»·*и®ўеҚ•жҳҺз»Ҷ.ж•°йҮҸ) AS й”Җе”®йҮ‘йўқпјҢcount(1) AS и®ўеҚ•ж•°йҮҸ from и®ўеҚ•жҳҺз»Ҷ left join и®ўеҚ• on и®ўеҚ•жҳҺз»Ҷ.и®ўеҚ•ID=и®ўеҚ•.и®ўеҚ•ID group by to_char(и®ўеҚ•.и®ўеҚ•ж—Ҙжңҹ,'yyyy'),to_char(и®ўеҚ•.и®ўеҚ•ж—Ҙжңҹ,'MM') |
з”ЁйӣҶз®—еҷЁе®һзҺ°дёҠиҝ°з®—жі•ж—¶пјҢеҠ иҪҪж•°жҚ®зҡ„и„ҡжң¬дёҚеҸҳпјҢдёҡеҠЎз®—жі•еҰӮдёӢпјҲalgorithm_2.dfxпјү
A | |
1 | =join(и®ўеҚ•жҳҺз»Ҷ:еӯҗиЎЁ,и®ўеҚ•ID;и®ўеҚ•:дё»иЎЁ,и®ўеҚ•ID) |
2 | =A1.groups(year(дё»иЎЁ.и®ўеҚ•ж—Ҙжңҹ):е№ҙд»Ҫ, month(дё»иЎЁ.и®ўеҚ•ж—Ҙжңҹ):жңҲд»Ҫ; sum(еӯҗиЎЁ.еҚ•д»·*еӯҗиЎЁ.ж•°йҮҸ):й”Җе”®йҮ‘йўқ, count(1):и®ўеҚ•ж•°йҮҸ) |
A1:е°Ҷи®ўеҚ•жҳҺз»ҶдёҺи®ўеҚ•е…іиҒ”иө·жқҘпјҢеӯҗиЎЁдё»иЎЁдёәеҲ«еҗҚпјҢзӮ№еҮ»еҚ•е…ғж јеҸҜи§Ғз»“жһңеҰӮдёӢ

еҸҜд»ҘзңӢеҲ°пјҢйӣҶз®—еҷЁjoinеҮҪж•°дёҺSQL joinиҜӯеҸҘиҷҪ然дҪңз”ЁдёҖж ·пјҢдҪҶз»“жһ„еҺҹзҗҶеӨ§дёҚзӣёеҗҢгҖӮеҮҪж•°joinе…іиҒ”еҪўжҲҗзҡ„з»“жһңпјҢе…¶еӯ—ж®өеҖјдёҚжҳҜеҺҹеӯҗж•°жҚ®зұ»еһӢпјҢиҖҢжҳҜи®°еҪ•пјҢеҗҺз»ӯеҸҜз”ЁвҖң.вҖқеҸ·иЎЁиҫҫе…ізі»еј•з”ЁпјҢеӨҡеұӮе…іиҒ”йқһеёёж–№дҫҝгҖӮ
A2:еҲҶз»„жұҮжҖ»гҖӮ
и®Ўз®—з»“жһңеҰӮдёӢпјҡ
е№ҙд»Ҫ | жңҲд»Ҫ | й”Җе”®йҮ‘йўқ | и®ўеҚ•ж•°йҮҸ |
2012 | 7 | 28988 | 57 |
2012 | 8 | 26799 | 71 |
2012 | 9 | 27201 | 57 |
2012 | 10 | 37793.7 | 69 |
2012 | 11 | 49704 | 66 |
вҖҰ | вҖҰ | вҖҰ | вҖҰ |
е…іиҒ”е…ізі»еҲҶеҫҲеӨҡзұ»пјҢдёҠиҝ°и®ўеҚ•е’Ңи®ўеҚ•жҳҺз»ҶеұһдәҺе…¶дёӯдёҖзұ»пјҡдё»еӯҗе…іиҒ”гҖӮй’ҲеҜ№дё»еӯҗе…іиҒ”пјҢеҸӘйңҖеңЁеҠ иҪҪж•°жҚ®ж—¶еҗ„иҮӘжҢүе…іиҒ”еӯ—ж®өжҺ’еәҸпјҢдёҡеҠЎз®—жі•дёӯе°ұеҸҜз”ЁеҪ’并算法жқҘжҸҗй«ҳжҖ§иғҪгҖӮдҫӢеҰӮпјҡ
=join@m(и®ўеҚ•жҳҺз»Ҷ:еӯҗиЎЁ,и®ўеҚ•ID;и®ўеҚ•:дё»иЎЁ,и®ўеҚ•ID) |
еҮҪж•°join@mиЎЁзӨәеҪ’并关иҒ”пјҢеҸӘеҜ№еҗҢеәҸзҡ„дёӨдёӘжҲ–еӨҡдёӘиЎЁжңүж•ҲгҖӮ
йӣҶз®—еҷЁзҡ„е…іиҒ”и®Ўз®—дёҺRDBдёҚеҗҢпјҢRDRеҜ№жүҖжңүзұ»еһӢзҡ„е…іиҒ”е…ізі»йғҪйҮҮз”ЁзӣёеҗҢзҡ„з®—жі•пјҢж— жі•иҝӣиЎҢжңүй’ҲеҜ№жҖ§зҡ„дјҳеҢ–пјҢиҖҢйӣҶз®—еҷЁйҮҮеҸ–еҲҶиҖҢжІ»д№Ӣзҡ„зҗҶеҝөпјҢеҜ№дёҚеҗҢзұ»еһӢзҡ„е…іиҒ”е…ізі»жҸҗдҫӣдәҶдёҚеҗҢзҡ„з®—жі•пјҢеҸҜиҝӣиЎҢжңүй’ҲеҜ№жҖ§зҡ„йҖҸжҳҺдјҳеҢ–гҖӮ
йҷӨдәҶдё»еӯҗе…іиҒ”пјҢжңҖеёёз”Ёзҡ„е°ұжҳҜеӨ–й”®е…іиҒ”пјҢеёёз”Ёзҡ„еӨ–й”®иЎЁпјҲжҲ–еӯ—е…ёиЎЁпјүжңүеҲҶзұ»гҖҒең°еҢәгҖҒеҹҺеёӮгҖҒе‘ҳе·ҘгҖҒе®ўжҲ·зӯүгҖӮеҜ№дәҺеӨ–й”®е…іиҒ”пјҢйӣҶз®—еҷЁд№ҹжңүзӣёеә”зҡ„дјҳеҢ–ж–№жі•пјҢеҚіеңЁж•°жҚ®еҠ иҪҪйҳ¶ж®өдәӢе…Ҳе»әз«Ӣе…іиҒ”пјҢеҰӮжӯӨдёҖжқҘдёҡеҠЎз®—жі•е°ұдёҚеҝ…дёҙж—¶е…іиҒ”пјҢжҖ§иғҪеӣ жӯӨжҸҗй«ҳпјҢ并еҸ‘ж—¶ж•Ҳжһңе°ӨдёәжҳҺжҳҫгҖӮеҸҰеӨ–пјҢйӣҶз®—еҷЁз”ЁжҢҮй’Ҳе»әз«ӢеӨ–й”®е…іиҒ”пјҢи®ҝй—®йҖҹеәҰжӣҙеҝ«гҖӮ
жҜ”еҰӮиҝҷдёӘжЎҲдҫӢпјҡи®ўеҚ•иЎЁзҡ„е®ўжҲ·IDеӯ—ж®өжҳҜеӨ–й”®пјҢеҜ№еә”е®ўжҲ·иЎЁпјҲе®ўжҲ·IDгҖҒе®ўжҲ·еҗҚз§°гҖҒең°еҢәгҖҒеҹҺеёӮпјүпјҢйңҖиҰҒз»ҹи®ЎеҮәжҜҸдёӘең°еҢәжҜҸдёӘеҹҺеёӮзҡ„и®ўеҚ•ж•°йҮҸгҖӮ
ж•°жҚ®еҠ иҪҪи„ҡжң¬пјҲinitData_3.dfxпјүеҰӮдёӢпјҡ
A | |
1 | =connect("orcl") |
2 | =A1.query("select и®ўеҚ•ID,е®ўжҲ·ID,и®ўеҚ•ж—Ҙжңҹ,иҝҗиҙ§иҙ№ from и®ўеҚ•").keys(и®ўеҚ•ID) |
3 | =A1.query@x(вҖңselect е®ўжҲ·ID,ең°еҢә,еҹҺеёӮ from е®ўжҲ·вҖқ).keys(е®ўжҲ·ID) |
4 | =A2.switch(е®ўжҲ·ID,A3:е®ўжҲ·ID) |
5 | =env(и®ўеҚ•,A2) |
6 | =env(е®ўжҲ·,A3) |
A4пјҡз”ЁеҮҪж•°switchе»әз«ӢеӨ–й”®е…іиҒ”пјҢе°Ҷи®ўеҚ•иЎЁзҡ„е®ўжҲ·IDеӯ—ж®өпјҢжӣҝжҚўдёәе®ўжҲ·иЎЁзӣёеә”и®°еҪ•зҡ„жҢҮй’ҲгҖӮ
дёҡеҠЎз®—жі•и„ҡжң¬еҰӮдёӢпјҲalgorithm_3.dfxпјүеҰӮдёӢ
A | |
1 | =и®ўеҚ•.groups(е®ўжҲ·ID.ең°еҢә:ең°еҢә ,е®ўжҲ·ID.еҹҺеёӮ:еҹҺеёӮ;count(1):и®ўеҚ•ж•°йҮҸ) |
еҠ иҪҪж•°жҚ®ж—¶е·Із»Ҹе»әз«ӢдәҶеӨ–й”®жҢҮй’Ҳе…іиҒ”пјҢжүҖд»ҘA1дёӯзҡ„вҖңе®ўжҲ·IDвҖқиЎЁзӨәпјҡи®ўеҚ•иЎЁзҡ„е®ўжҲ·IDеӯ—ж®өжүҖжҢҮеҗ‘зҡ„е®ўжҲ·иЎЁи®°еҪ•пјҢвҖңе®ўжҲ·ID.ең°еҢәвҖқеҚіе®ўжҲ·иЎЁзҡ„ең°еҢәеӯ—ж®өгҖӮ
и„ҡжң¬дёӯеӨҡеӨ„дҪҝз”ЁвҖң.вҖқеҸ·иЎЁиҫҫе…іиҒ”еј•з”ЁпјҢиҜӯжі•жҜ”SQLзӣҙи§Ӯжҳ“жҮӮпјҢйҒҮеҲ°еӨҡиЎЁеӨҡеұӮе…іиҒ”ж—¶е°ӨдёәдҫҝжҚ·гҖӮиҖҢеңЁSQLдёӯпјҢе…іиҒ”дёҖеӨҡеҰӮеҗҢеӨ©д№ҰгҖӮ
дёҠиҝ°и®Ўз®—з»“жһңеҰӮдёӢпјҡ
ең°еҢә | еҹҺеёӮ | и®ўеҚ•ж•°йҮҸ |
дёңеҢ— | еӨ§иҝһ | 40 |
еҚҺдёң | еҚ—дә¬ | 89 |
еҚҺдёң | еҚ—жҳҢ | 15 |
еҚҺдёң | еёёе·һ | 35 |
еҚҺдёң | жё©е·һ | 18 |
вҖҰ | вҖҰ | вҖҰ |
еҶ…еӯҳи®Ўз®—иҷҪ然еҝ«пјҢдҪҶжҳҜеҶ…еӯҳжңүйҷҗпјҢеӣ жӯӨйҖҡеёёеҸӘй©»з•ҷжңҖеёёз”ЁгҖҒ并еҸ‘и®ҝй—®жңҖеӨҡзҡ„ж•°жҚ®пјҢиҖҢеҶ…еӯҳж”ҫдёҚдёӢжҲ–и®ҝй—®йў‘зҺҮдҪҺзҡ„ж•°жҚ®пјҢиҝҳжҳҜиҰҒз•ҷеңЁзЎ¬зӣҳпјҢз”ЁеҲ°зҡ„ж—¶еҖҷеҶҚдёҙж—¶еҠ иҪҪпјҢ并дёҺеҶ…еӯҳж•°жҚ®е…ұеҗҢеҸӮдёҺи®Ўз®—гҖӮиҝҷе°ұжҳҜжүҖи°“зҡ„еҶ…еӨ–ж··еҗҲи®Ўз®—гҖӮ
дёӢйқўдёҫдҫӢиҜҙжҳҺйӣҶз®—еҷЁдёӯзҡ„еҶ…еӨ–ж··еҗҲи®Ўз®—гҖӮ
жЎҲдҫӢжҸҸиҝ°пјҡжҹҗйӣ¶е”®иЎҢдёҡзі»з»ҹдёӯпјҢи®ўеҚ•жҳҺз»Ҷи®ҝй—®йў‘зҺҮиҫғдҪҺпјҢж•°жҚ®йҮҸиҫғеӨ§пјҢжІЎеҝ…иҰҒд№ҹжІЎеҠһжі•еёёй©»еҶ…еӯҳгҖӮзҺ°еңЁиҰҒе°Ҷи®ўеҚ•жҳҺз»ҶдёҺеҶ…еӯҳйҮҢзҡ„и®ўеҚ•е…іиҒ”иө·жқҘпјҢз»ҹи®ЎеҮәжҜҸе№ҙжҜҸз§Қдә§е“Ғзҡ„й”Җе”®ж•°йҮҸгҖӮ
ж•°жҚ®еҠ иҪҪи„ҡжң¬пјҲinitData_4.dfxпјүеҰӮдёӢпјҡ
A | |
1 | =connect("orcl") |
2 | =A1.query@x("select и®ўеҚ•ID,е®ўжҲ·ID,и®ўеҚ•ж—Ҙжңҹ,иҝҗиҙ§иҙ№ from и®ўеҚ• order by и®ўеҚ•ID").keys(и®ўеҚ•ID) |
4 | =env(и®ўеҚ•,A2) |
дёҡеҠЎз®—жі•и„ҡжң¬пјҲalgorithm_4.dfxпјүеҰӮдёӢпјҡ
A | |
1 | =connect("orcl") |
2 | =A1.cursor@x("select и®ўеҚ•ID,дә§е“ҒID,ж•°йҮҸ from и®ўеҚ•жҳҺз»Ҷorder by и®ўеҚ•ID") |
3 | =и®ўеҚ•.cursor() |
4 | =joinx(A2:еӯҗиЎЁ,и®ўеҚ•ID; A3:дё»иЎЁ,и®ўеҚ•ID) |
5 | =A4.groups(year(дё»иЎЁ.и®ўеҚ•ж—Ҙжңҹ):е№ҙд»Ҫ,еӯҗиЎЁ.дә§е“ҒID:дә§е“Ғ ;sum(еӯҗиЎЁ.ж•°йҮҸ):й”Җе”®ж•°йҮҸ) |
A2пјҡжү§иЎҢSQLпјҢд»Ҙжёёж Үж–№ејҸеҸ–и®ўеҚ•жҳҺз»ҶпјҢд»Ҙдҫҝи®Ўз®—иҝңи¶…еҶ…еӯҳзҡ„еӨ§йҮҸж•°жҚ®гҖӮ
A3пјҡе°Ҷи®ўеҚ•иЎЁиҪ¬дёәжёёж ҮжЁЎејҸпјҢдёӢдёҖжӯҘдјҡз”ЁеҲ°гҖӮ
A4пјҡе…іиҒ”и®ўеҚ•жҳҺз»ҶиЎЁе’Ңи®ўеҚ•иЎЁгҖӮеҮҪж•°joinxдёҺjoin@mдҪңз”Ёзұ»дјјпјҢйғҪеҸҜеҜ№жңүеәҸж•°жҚ®иҝӣиЎҢеҪ’并关иҒ”пјҢеҢәеҲ«еңЁдәҺеүҚиҖ…еҜ№жёёж Үжңүж•ҲпјҢеҗҺиҖ…еҜ№еәҸиЎЁжңүж•ҲгҖӮ
A5пјҡжү§иЎҢеҲҶз»„жұҮжҖ»гҖӮ
ж•°жҚ®еә“дёӯзҡ„зү©зҗҶиЎЁжҖ»дјҡеҸҳеҢ–пјҢиҝҷз§ҚеҸҳеҢ–еә”еҪ“еҸҠж—¶еҸҚжҳ еҲ°е…ұдә«зҡ„еҶ…еӯҳиЎЁдёӯпјҢжүҚиғҪдҝқиҜҒеҶ…еӯҳи®Ўз®—з»“жһңзҡ„жӯЈзЎ®пјҢиҝҷз§Қжғ…еҶөдёӢе°ұйңҖиҰҒжӣҙж–°еҶ…еӯҳгҖӮеҰӮжһңзү©зҗҶиЎЁиҫғе°ҸпјҢйӮЈд№Ҳи§ЈеҶіиө·жқҘеҫҲе®№жҳ“пјҢеҸӘиҰҒе®ҡж—¶жү§иЎҢеҲқе§ӢеҢ–ж•°жҚ®и„ҡжң¬пјҲinitData.dfxпјүе°ұеҸҜд»ҘдәҶгҖӮдҪҶеҰӮжһңзү©зҗҶиЎЁеӨӘеӨ§пјҢе°ұдёҚиғҪиҝҷж ·еҒҡдәҶпјҢеӣ дёәеҲқе§ӢеҢ–и„ҡжң¬дјҡиҝӣиЎҢе…ЁйҮҸеҠ иҪҪпјҢжң¬иә«е°ұдјҡж¶ҲиҖ—еӨ§йҮҸж—¶й—ҙпјҢиҖҢдё”еҠ иҪҪж—¶ж— жі•иҝӣиЎҢеҶ…еӯҳи®Ўз®—гҖӮдҫӢеҰӮпјҡжҹҗйӣ¶е”®е·ЁеӨҙи®ўеҚ•ж•°жҚ®йҮҸиҫғеӨ§пјҢд»Һж•°жҚ®еә“е…ЁйҮҸеҠ иҪҪеҲ°еҶ…еӯҳйҖҡеёёи¶…иҝҮ5еҲҶй’ҹпјҢдҪҶдёәдҝқиҜҒдёҖе®ҡзҡ„е®һж—¶жҖ§пјҢеҶ…еӯҳж•°жҚ®еҸҲйңҖиҰҒ5еҲҶй’ҹжӣҙж–°дёҖж¬ЎпјҢжҳҫ然пјҢдёӨиҖ…еӯҳеңЁжҳҺжҳҫзҡ„зҹӣзӣҫгҖӮ
и§ЈеҶіжҖқи·Ҝе…¶е®һеҫҲиҮӘ然пјҢзү©зҗҶиЎЁеӨӘеӨ§зҡ„ж—¶еҖҷпјҢеә”иҜҘиҝӣиЎҢеўһйҮҸжӣҙж–°пјҢ5еҲҶй’ҹзҡ„еўһйҮҸдёҡеҠЎж•°жҚ®йҖҡеёёеҫҲе°ҸпјҢеўһйҮҸдёҚдјҡеҪұе“Қжӣҙж–°еҶ…еӯҳзҡ„ж•ҲзҺҮгҖӮ
иҰҒе®һзҺ°еўһйҮҸжӣҙж–°пјҢе°ұйңҖиҰҒзҹҘйҒ“е“ӘдәӣжҳҜеўһйҮҸж•°жҚ®пјҢдёҚеӨ–д№Һд»ҘдёӢдёүз§Қж–№жі•пјҡ
ж–№жі•AпјҡеңЁеҺҹиЎЁеҠ ж Үи®°еӯ—ж®өд»ҘиҜҶеҲ«гҖӮзјәзӮ№жҳҜдјҡж”№еҠЁеҺҹиЎЁгҖӮ
ж–№жі•BпјҡеңЁеҺҹеә“еҲӣе»әдёҖеј вҖңеҸҳжӣҙиЎЁвҖқпјҢе°ҶеҸҳжӣҙзҡ„ж•°жҚ®и®°еҪ•еңЁеҶ…гҖӮеҘҪеӨ„жҳҜдёҚеҠЁеҺҹиЎЁпјҢзјәзӮ№жҳҜд»Қ然иҰҒеҠЁж•°жҚ®еә“гҖӮ
ж–№жі•Cпјҡе°ҶеҸҳжӣҙиЎЁи®°еҪ•еңЁеҸҰдёҖдёӘж•°жҚ®еә“пјҢжҲ–ж–Үжң¬ж–Ү件ExcelдёӯгҖӮеҘҪеӨ„жҳҜеҜ№еҺҹж•°жҚ®еә“дёҚеҒҡд»»дҪ•ж”№еҠЁпјҢзјәзӮ№жҳҜеўһеҠ дәҶз»ҙжҠӨе·ҘдҪңйҮҸгҖӮ
йӣҶз®—еҷЁж”ҜжҢҒеӨҡж•°жҚ®жәҗи®Ўз®—пјҢжүҖд»Ҙж–№жі•BгҖҒCжІЎжң¬иҙЁеҢәеҲ«пјҢдёӢйқўе°ұд»ҘBдёәдҫӢжӣҙж–°и®ўеҚ•иЎЁгҖӮ
第дёҖжӯҘпјҢеңЁж•°жҚ®еә“дёӯе»әз«ӢвҖңи®ўеҚ•еҸҳжӣҙиЎЁвҖқпјҢ继жүҝеҺҹиЎЁеӯ—ж®өпјҢж–°еҠ дёҖдёӘвҖңеҸҳжӣҙж Үи®°вҖқеӯ—ж®өпјҢеҪ“з”ЁжҲ·дҝ®ж”№еҺҹе§ӢиЎЁж—¶пјҢйңҖиҰҒеңЁеҸҳжӣҙиЎЁеҗҢжӯҘи®°еҪ•гҖӮеҰӮдёӢжүҖзӨәзҡ„и®ўеҚ•еҸҳжӣҙиЎЁпјҢиЎЁзӨәж–°еўһ1жқЎдҝ®ж”№2жқЎеҲ йҷӨ1жқЎгҖӮ
и®ўеҚ•ID(key) | е®ўжҲ·ID | и®ўеҚ•ж—Ҙжңҹ | иҝҗиҙ§иҙ№ | еҸҳжӣҙж Үи®° |
10247 | VICTE | 2012-07-08 | 101 | ж–°еўһ |
10248 | VINET | 2012-07-04 | 102 | дҝ®ж”№ |
10249 | TOMSP | 2012-07-05 | 103 | дҝ®ж”№ |
10250 | HANAR | 2012-07-08 | 104 | еҲ йҷӨ |
第дәҢжӯҘпјҢзј–еҶҷйӣҶз®—еҷЁи„ҡжң¬updatemem_4.dfxпјҢиҝӣиЎҢж•°жҚ®жӣҙж–°гҖӮ
A | B | |
1 | =connect("orcl") | |
2 | =и®ўеҚ•cp=и®ўеҚ•.derive() | |
3 | =A1.query("select и®ўеҚ•ID,е®ўжҲ·ID,и®ўиҙӯж—Ҙжңҹ и®ўеҚ•ж—Ҙжңҹ,иҝҗиҙ§иҙ№,еҸҳжӣҙж Үи®° from и®ўеҚ•еҸҳжӣҙ") | |
4 | =и®ўеҚ•еҲ йҷӨ=A3.select(еҸҳжӣҙж Үи®°=="еҲ йҷӨ") | =и®ўеҚ•cp.select(и®ўеҚ•еҲ йҷӨ.(и®ўеҚ•ID).contain(и®ўеҚ•ID)) |
5 | =и®ўеҚ•cp.delete(B4) | |
6 | =и®ўеҚ•ж–°еўһ=A3.select(еҸҳжӣҙж Үи®°=="ж–°еўһ") | =и®ўеҚ•cp.insert@f(0:и®ўеҚ•ж–°еўһ) |
7 | =и®ўеҚ•дҝ®ж”№=A3.select(еҸҳжӣҙж Үи®°=="дҝ®ж”№") | =и®ўеҚ•cp.select(и®ўеҚ•дҝ®ж”№.(и®ўеҚ•ID).pos(и®ўеҚ•ID)) |
8 | =и®ўеҚ•cp.delete(B7) | |
9 | =и®ўеҚ•cp.insert@f(0:и®ўеҚ•дҝ®ж”№) | |
10 | =env(и®ўеҚ•,и®ўеҚ•cp) | |
11 | =A1.execute("delete from и®ўеҚ•еҸҳжӣҙ") | |
12 | =A1.close() |
A1пјҡе»әз«Ӣж•°жҚ®еә“иҝһжҺҘгҖӮ
A2пјҡе°ҶеҶ…еӯҳдёӯзҡ„и®ўеҚ•еӨҚеҲ¶дёҖд»ҪпјҢе‘ҪеҗҚдёәи®ўеҚ•cpгҖӮдёӢйқўиҝҮзЁӢеҸӘй’ҲеҜ№и®ўеҚ•cpиҝӣиЎҢдҝ®ж”№пјҢдҝ®ж”№е®ҢжҜ•еҶҚжӣҝд»ЈеҶ…еӯҳдёӯзҡ„и®ўеҚ•пјҢжңҹй—ҙи®ўеҚ•д»ҚеҸҜжӯЈеёёиҝӣиЎҢдёҡеҠЎи®Ўз®—гҖӮ
A3пјҡеҸ–ж•°жҚ®еә“и®ўеҚ•еҸҳжӣҙиЎЁгҖӮ
A4-B5пјҡеҸ–еҮәи®ўеҚ•еҸҳжӣҙиЎЁдёӯйңҖеҲ йҷӨзҡ„и®°еҪ•пјҢеңЁи®ўеҚ•cpдёӯжүҫеҲ°иҝҷдәӣи®°еҪ•пјҢ并еҲ йҷӨгҖӮ
A6-B6пјҡеҸ–еҮәи®ўеҚ•еҸҳжӣҙиЎЁдёӯйңҖж–°еўһзҡ„и®°еҪ•пјҢеңЁи®ўеҚ•cpдёӯиҝҪеҠ гҖӮ
A7-B9пјҡиҝҷдёҖжӯҘжҳҜдҝ®ж”№и®ўеҚ•cpпјҢзӣёеҪ“дәҺе…ҲеҲ йҷӨеҶҚиҝҪеҠ гҖӮд№ҹеҸҜз”ЁmodifyеҮҪж•°е®һзҺ°дҝ®ж”№гҖӮ
A10пјҡе°Ҷдҝ®ж”№еҗҺзҡ„и®ўеҚ•cpеёёй©»еҶ…еӯҳпјҢе‘ҪеҗҚдёәи®ўеҚ•гҖӮ
A11-A12пјҡжё…з©әвҖңеҸҳжӣҙиЎЁвҖқпјҢд»ҘдҫҝдёӢж¬ЎеҸ–ж–°зҡ„еҸҳжӣҙи®°еҪ•гҖӮ
дёҠиҝ°и„ҡжң¬е®һзҺ°дәҶе®Ңж•ҙзҡ„ж•°жҚ®жӣҙж–°пјҢиҖҢе®һйҷ…дёҠеҫҲеӨҡжғ…еҶөдёӢеҸӘйңҖиҰҒиҝҪеҠ ж•°жҚ®пјҢиҝҷж ·и„ҡжң¬иҝҳдјҡз®ҖеҚ•еҫҲеӨҡгҖӮ
и„ҡжң¬зј–еҶҷе®ҢжҲҗеҗҺпјҢиҝҳйңҖ第дёүжӯҘпјҡе®ҡж—¶5еҲҶй’ҹжү§иЎҢиҜҘи„ҡжң¬гҖӮ
е®ҡж—¶жү§иЎҢзҡ„ж–№жі•жңүеҫҲеӨҡгҖӮеҰӮжһңйӣҶз®—еҷЁйғЁзҪІдёәзӢ¬з«ӢжңҚеҠЎпјҢдёҺWebеә”з”ЁжІЎжңүе…ұз”ЁJVMпјҢйӮЈд№ҲеҸҜд»ҘдҪҝз”Ёж“ҚдҪңзі»з»ҹиҮӘеёҰзҡ„е®ҡж—¶е·Ҙе…·пјҲи®ЎеҲ’д»»еҠЎжҲ–crontabпјүпјҢдҪҝе…¶е®ҡж—¶жү§иЎҢйӣҶз®—еҷЁе‘Ҫд»Ө(esprocx.exeжҲ–esprocx.sh)гҖӮ
жңүдәӣwebеә”з”ЁжңүиҮӘе·ұзҡ„е®ҡж—¶д»»еҠЎз®ЎзҗҶе·Ҙе…·пјҢеҸҜе®ҡж—¶жү§иЎҢжҹҗдёӘJAVAзұ»пјҢиҝҷж—¶еҸҜд»Ҙзј–еҶҷJAVAзұ»пјҢз”ЁJDBCи°ғз”ЁйӣҶз®—еҷЁи„ҡжң¬гҖӮ
еҰӮжһңwebеә”з”ЁжІЎжңүе®ҡж—¶д»»еҠЎз®ЎзҗҶе·Ҙе…·пјҢйӮЈе°ұйңҖиҰҒжүӢе·Ҙе®һзҺ°е®ҡж—¶д»»еҠЎпјҢеҚізј–еҶҷJAVAзұ»пјҢ继жүҝjavaеҶ…зҪ®зҡ„е®ҡж—¶зұ»TimerTaskпјҢеңЁе…¶дёӯи°ғз”ЁйӣҶз®—еҷЁи„ҡжң¬пјҢеҶҚеңЁеҗҜеҠЁзұ»дёӯи°ғз”Ёе®ҡж—¶д»»еҠЎзұ»гҖӮ
е…¶дёӯеҗҜеҠЁзұ»myServle4дёәпјҡ
1. import java.io.IOException;
2. import java.util.Timer;
3. import javax.servlet.RequestDispatcher;
4. import javax.servlet.ServletContext;
5. import javax.servlet.ServletException;
6. import javax.servlet.http.HttpServlet;
7. import javax.servlet.http.HttpServletRequest;
8. import javax.servlet.http.HttpServletResponse;
9. import org.apache.commons.lang.StringUtils;
10. public class myServlet4 extends HttpServlet {
11. private static final long serialVersionUID = 1L;
12. private Timer timer1 = null;
13. private Task task1;
14. public ConvergeDataServlet() {
15. super();
16. }
17. public void destroy() {
18. super.destroy();
19. if(timer1!=null){
20. timer1.cancel();
21. }
22. }
23. public void doGet(HttpServletRequest request, HttpServletResponse response)
24. throws ServletException, IOException {
25. }
26. public void doPost(HttpServletRequest request, HttpServletResponse response)
27. throws ServletException, IOException {
28. doGet(request, response);
29. }
30. public void init() throws ServletException {
31. ServletContext context = getServletContext();
32. // е®ҡж—¶еҲ·ж–°ж—¶й—ҙ(5еҲҶй’ҹ)
33. Long delay = new Long(5);
34. // еҗҜеҠЁе®ҡж—¶еҷЁ
35. timer1 = new Timer(true);
36. task1 = new Task(context);
37. timer1.schedule(task1, delay * 60 * 1000, delay * 60 * 1000);
38. }
39. }
е®ҡж—¶д»»еҠЎзұ»Taskдёәпјҡ
11. import java.util.TimerTask;
12. import javax.servlet.ServletContext;
13. import java.sql.*;
14. import com.esproc.jdbc.*;
15. public class Task extends TimerTask{
16. private ServletContext context;
17. private static boolean isRunning = true;
18. public Task(ServletContext context){
19. this.context = context;
20. }
21. @Override
22. public void run() {
23. if(!isRunning){
24. com.esproc.jdbc.InternalConnection con=null;
25. try {
26. Class.forName("com.esproc.jdbc.InternalDriver");
27. con =(com.esproc.jdbc.InternalConnection)DriverManager.getConnection("jdbc:esproc:local://");
28. ResultSet rs = con.executeQuery("call updatemem_4()");
29. }
30. catch (SQLException e){
31. out.println(e);
32. }finally{
33. //е…ій—ӯж•°жҚ®йӣҶ
34. if (con!=null) con.close();
35. }
36. }
37. }
38. }
дёӢйқўпјҢйҖҡиҝҮдёҖдёӘз»јеҗҲзӨәдҫӢжқҘзңӢдёҖдёӢеңЁж•°жҚ®жәҗеӨҡж ·гҖҒз®—жі•еӨҚжқӮзҡ„жғ…еҶөдёӢпјҢйӣҶз®—еҷЁеҰӮдҪ•еҫҲеҘҪең°е®һзҺ°еҶ…еӯҳи®Ўз®—пјҡ
жЎҲдҫӢжҸҸиҝ°пјҡжҹҗB2CзҪ‘з«ҷйңҖиҰҒиҜ•з®—и®ўеҚ•зҡ„йӮ®еҜ„жҖ»иҙ№з”ЁпјҢд»ҘдҫҝеңЁдёҖе®ҡжҲҗжң¬дёӢжҢ‘йҖүеҗҲйҖӮзҡ„йӮ®иҙ№и§„еҲҷгҖӮеӨ§йғЁеҲҶжғ…еҶөдёӢпјҢйӮ®иҙ№з”ұеҢ…иЈ№зҡ„жҖ»йҮҚйҮҸеҶіе®ҡпјҢдҪҶеҪ“и®ўеҚ•зҡ„д»·ж ји¶…иҝҮжҢҮе®ҡеҖјж—¶пјҲжҜ”еҰӮ300зҫҺе…ғпјүпјҢеҲҷжҸҗдҫӣе…Қиҙ№д»ҳиҝҗгҖӮз»“жһңйңҖиҫ“еҮәеҗ„и®ўеҚ•йӮ®еҜ„иҙ№з”Ёд»ҘеҸҠжҖ»иҙ№з”ЁгҖӮ
е…¶дёӯи®ўеҚ•иЎЁе·ІеҠ иҪҪеҲ°еҶ…еӯҳпјҢеҰӮдёӢпјҡ
Id | cost | weight |
Josh2 | 150 | 6 |
Drake | 100 | 3 |
Megan | 100 | 1 |
Josh3 | 200 | 3 |
Josh4 | 500 | 1 |
йӮ®иҙ№и§„еҲҷжҜҸж¬ЎиҜ•з®—ж—¶йғҪдёҚеҗҢпјҢеӣ жӯӨз”ұеҸӮж•°вҖңpRuleвҖқдёҙж—¶дј е…ҘпјҢж јејҸдёәjsonеӯ—з¬ҰдёІпјҢжҹҗ次规еҲҷеҰӮдёӢпјҡ
[{"field":"cost","minVal":300,"maxVal":1000000,"Charge":0}, {"field":"weight","minVal":0,"maxVal":1,"Charge":10}, {"field":"weight","minVal":1,"maxVal":5,"Charge":20}, {"field":"weight","minVal":5,"maxVal":10,"Charge":25}, {"field":"weight","minVal":10,"maxVal":1000000,"Charge":40}] |
дёҠиҝ°jsonдёІиЎЁзӨәеҗ„еӯ—ж®өеңЁеҗ„з§ҚеҸ–еҖјиҢғеӣҙеҶ…ж—¶зҡ„йӮ®иҙ№гҖӮ第дёҖжқЎи®°еҪ•иЎЁзӨәпјҢcostеӯ—ж®өеҸ–еҖјеңЁ300дёҺ1000000д№Ӣй—ҙзҡ„ж—¶еҖҷпјҢйӮ®иҙ№дёә0пјҲе…Қиҙ№д»ҳиҝҗпјүпјӣ第дәҢжқЎи®°еҪ•иЎЁзӨәпјҢweightеӯ—ж®өеҸ–еҖјеңЁ0еҲ°1пјҲkgпјүд№Ӣй—ҙж—¶пјҢйӮ®иҙ№дёә10пјҲзҫҺе…ғпјүгҖӮ
жҖқи·Ҝпјҡе°ҶjsonдёІиҪ¬дёәдәҢз»ҙиЎЁпјҢеҲҶеҲ«жүҫеҮәfiledеӯ—ж®өдёәcostе’Ңweightзҡ„и®°еҪ•пјҢеҶҚеҜ№ж•ҙдёӘи®ўеҚ•иЎЁиҝӣиЎҢеҫӘзҺҜгҖӮеҫӘзҺҜдёӯе…ҲеҲӨж–ӯи®ўеҚ•и®°еҪ•дёӯзҡ„costеҖјжҳҜеҗҰж»Ўи¶іе…Қиҙ№ж ҮеҮҶпјҢдёҚж»Ўи¶іеҲҷж №жҚ®йҮҚйҮҸеҲӨж–ӯйӮ®иҙ№жЎЈж¬ЎпјҢд№ӢеҗҺи®Ўз®—йӮ®иҙ№гҖӮз®—е®Ңеҗ„и®ўеҚ•йӮ®иҙ№еҗҺеҶҚи®Ўз®—жҖ»йӮ®иҙ№пјҢ并е°ҶжұҮжҖ»з»“жһңйҷ„еҠ дёәи®ўеҚ•иЎЁзҡ„жңҖеҗҺдёҖжқЎи®°еҪ•гҖӮ
ж•°жҚ®еҠ иҪҪиҝҮзЁӢеҫҲз®ҖеҚ•пјҢиҝҷйҮҢдёҚеҶҚиөҳиҝ°пјҢеҚіпјҡиҜ»ж•°жҚ®еә“иЎЁпјҢ并е‘ҪеҗҚдёәвҖңи®ўеҚ•иЎЁвҖқгҖӮ
дёҡеҠЎз®—жі•зӣёеҜ№еӨҚжқӮпјҢе…·дҪ“еҰӮдёӢпјҡ
A | B | C | D | |
1 | = pRule.export@j() | /и§ЈжһҗjsonпјҢиҪ¬дәҢз»ҙиЎЁ | ||
2 | =е…Қиҙ№=A1.select(field=="cost") | /еҸ–е…Қиҙ№ж ҮеҮҶпјҢеҚ•жқЎ | ||
3 | =收иҙ№=A1.select(field=="weight").sort(-minVal) | /еҸ–收иҙ№йҳ¶жўҜпјҢеӨҡжқЎ | ||
4 | =и®ўеҚ•иЎЁ.derive(postage) | /еӨҚеҲ¶е№¶ж–°еўһеӯ—ж®ө | ||
5 | for A4 | if е…Қиҙ№.minVal < A5.cost | >A5. postage= е…Қиҙ№.Charge | |
6 | next | |||
7 | for 收иҙ№ | if A5.weight > B7.minVal | >A5.postage=B7.Charge | |
8 | next A5 | |||
9 | =A4.record(["sum",,,A4.sum(postage)]) |
A1:и§ЈжһҗjsonпјҢе°Ҷе…¶иҪ¬дёәдәҢз»ҙиЎЁгҖӮйӣҶз®—еҷЁж”ҜжҢҒеӨҡж•°жҚ®жәҗпјҢдёҚд»…ж”ҜжҢҒRDBпјҢд№ҹж”ҜжҢҒNOSQLгҖҒж–Ү件гҖҒwebServiceгҖӮ
A2-A3пјҡжҹҘиҜўйӮ®иҙ№и§„еҲҷпјҢеҲҶдёәе…Қиҙ№е’Ң收иҙ№дёӨз§ҚгҖӮ
A4пјҡж–°еўһз©әеӯ—ж®өpostageгҖӮ
A5-D8пјҡжҢүдёӨз§Қ规еҲҷеҫӘзҺҜи®ўеҚ•иЎЁпјҢи®Ўз®—зӣёеә”зҡ„йӮ®иҙ№пјҢ并填е…Ҙpostageеӯ—ж®өгҖӮиҝҷйҮҢеӨҡеӨ„з”ЁеҲ°жөҒзЁӢжҺ§еҲ¶пјҢйӣҶз®—еҷЁз”Ёзј©иҝӣиЎЁзӨәпјҢе…¶дёӯA5гҖҒB7дёәеҫӘзҺҜиҜӯеҸҘпјҢC6гҖҒD8и·іе…ҘдёӢдёҖиҪ®еҫӘзҺҜпјҢB5гҖҒC7дёәеҲӨж–ӯиҜӯеҸҘ
A9:еңЁи®ўеҚ•иЎЁиҝҪеҠ ж–°зәӘеҪ•пјҢеЎ«е…ҘжұҮжҖ»еҖјгҖӮ
и®Ўз®—з»“жһңеҰӮдёӢпјҡ
Id | cost | weight | postage |
Josh2 | 150 | 6 | 25 |
Drake | 100 | 3 | 20 |
Megan | 100 | 1 | 10 |
Josh3 | 200 | 3 | 20 |
Josh4 | 500 | 1 | 0 |
sum | 75 |
иҮіжӯӨпјҢжң¬ж–ҮиҜҰз»Ҷд»Ӣз»ҚдәҶйӣҶз®—еҷЁз”ЁдҪңеҶ…еӯҳи®Ўз®—еј•ж“Һзҡ„е®Ңж•ҙиҝҮзЁӢпјҢеҗҢж—¶еҢ…жӢ¬дәҶеёёз”Ёи®Ўз®—ж–№жі•е’Ңй«ҳзә§иҝҗз®—жҠҖе·§гҖӮеҸҜд»ҘзңӢеҲ°пјҢйӣҶз®—еҷЁе…·жңүд»ҘдёӢжҳҫи‘—дјҳзӮ№пјҡ
l з»“жһ„з®ҖеҚ•е®һж–Ҫж–№дҫҝпјҢеҸҜеҝ«йҖҹе®һзҺ°еҶ…еӯҳи®Ўз®—пјӣ
l ж”ҜжҢҒеӨҡз§Қи°ғз”ЁжҺҘеҸЈпјҢеә”з”ЁйӣҶжҲҗжІЎжңүйҡңзўҚпјӣ
l ж”ҜжҢҒйҖҸжҳҺдјҳеҢ–пјҢеҸҜжҳҫи‘—жҸҗеҚҮи®Ўз®—жҖ§иғҪпјӣ
l ж”ҜжҢҒеӨҡз§Қж•°жҚ®жәҗпјҢдҫҝдәҺе®һзҺ°ж··еҗҲи®Ўз®—пјӣ
l иҜӯжі•ж•ҸжҚ·зІҫеҰҷпјҢеҸҜиҪ»жқҫе®һзҺ°еӨҚжқӮдёҡеҠЎйҖ»иҫ‘гҖӮ
е…ідәҺеҶ…еӯҳи®Ўз®—пјҢиҝҳжңүдёӘеӨҡжңәеҲҶеёғејҸи®Ўз®—зҡ„иҜқйўҳпјҢе°ҶеңЁеҗҺз»ӯж–Үз« дёӯиҝӣиЎҢд»Ӣз»ҚгҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ