жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
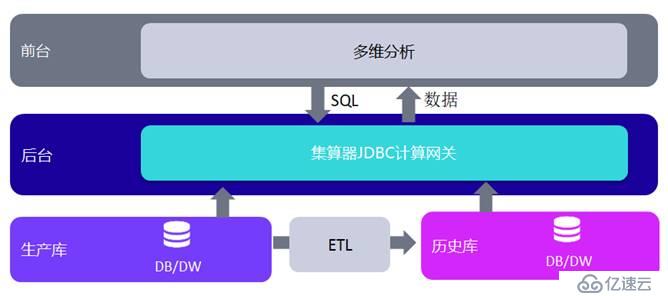
еӨҡз»ҙеҲҶжһҗпјҲBIпјүзі»з»ҹеҗҺеҸ°ж•°жҚ®еёёеёёеҸҜиғҪжқҘиҮӘеӨҡдёӘж•°жҚ®еә“пјҢиҝҷж—¶е°ұдјҡеҮәзҺ°и·Ёеә“еҸ–ж•°и®Ўз®—зҡ„й—®йўҳгҖӮ
дҫӢеҰӮпјҡд»ҺжҖ§иғҪе’ҢжҲҗжң¬иҖғиҷ‘пјҢеҫҖеҫҖдјҡйҷҗеҲ¶з”ҹдә§еә“зҡ„е®№йҮҸпјҢеҗҢж—¶е°ҶеҺҶеҸІж•°жҚ®еҲҶеә“еӯҳж”ҫпјҢз”ұETLе®ҡжңҹжҠҠз”ҹдә§еә“дёӯж–°дә§з”ҹзҡ„ж•°жҚ®еҗҢжӯҘеҲ°еҺҶеҸІеә“дёӯпјҢеҗҢжӯҘе‘Ёжңҹж №жҚ®ж•°жҚ®зҡ„з”ҹжҲҗйҮҸпјҢеҸҜиғҪжҳҜ1еӨ©гҖҒдёҖе‘ЁжҲ–иҖ…дёҖдёӘжңҲгҖӮеҰӮжһңеӨҡз»ҙеҲҶжһҗзі»з»ҹд»…д»…иҝһдёҠеҺҶеҸІеә“еҸ–ж•°пјҢйӮЈд№Ҳз”ЁжҲ·е°ұеҸӘиғҪеҜ№еҺҶеҸІж•°жҚ®еҒҡеҲҶжһҗпјҢд№ҹе°ұжҳҜе®һзҺ°T+1гҖҒT+7гҖҒT+30зҡ„еӨҡз»ҙеҲҶжһҗгҖӮеҰӮжһңжғіиҰҒе®һзҺ°T+0зҡ„е®һж—¶еҲҶжһҗпјҢе°ұиҰҒд»Һз”ҹдә§еә“е’ҢеҺҶеҸІеә“еҲҶеҲ«еҸ–еҫ—ж•°жҚ®иҝӣиЎҢ计算并жңҖз»ҲеҗҲ并结жһңгҖӮеҫҲеӨҡж—¶еҖҷпјҢз”ҹдә§еә“е’ҢеҺҶеҸІеә“иҝҳжҳҜејӮжһ„зҡ„ж•°жҚ®еә“пјҢеҫҲйҡҫзӣҙжҺҘеҒҡи·Ёеә“ж··еҗҲиҝҗз®—гҖӮ
еҚідҪҝдёҚжҳҜT+0еңәжҷҜпјҢеҺҶеҸІж•°жҚ®йҮҸеҫҲеӨ§ж—¶д№ҹеҸҜиғҪеҲҶжҲҗеӨҡдёӘж•°жҚ®еә“еӯҳеӮЁпјҢиҖҢдё”д№ҹдјҡжҳҜжҳҜејӮжһ„ж•°жҚ®еә“зҡ„жғ…еҶөгҖӮиҝҷж—¶пјҢеӨҡз»ҙеҲҶжһҗзі»з»ҹд№ҹйңҖиҰҒд»ҺеӨҡдёӘдёҚеҗҢж•°жҚ®д»“еә“дёӯеҸ–ж•°гҖҒи®Ўз®—гҖҒеҗҲ并结жһңеұ•зҺ°гҖӮ
дҪңдёәж•°жҚ®и®Ўз®—дёӯй—ҙ件пјҲDCMпјүпјҢжһ„е»әж•°жҚ®еүҚзҪ®еұӮжҳҜйӣҶз®—еҷЁзҡ„йҮҚиҰҒеә”з”ЁжЁЎејҸгҖӮйӣҶз®—еҷЁе…·еӨҮеҸҜзј–зЁӢзҪ‘е…іжңәеҲ¶пјҢеҸҜд»ҘеҗҢж—¶иҝһдёҠеӨҡдёӘж•°жҚ®еә“еҸ–ж•°пјҢ并е°Ҷз»“жһңеҗҲ并жҸҗдәӨз»ҷеүҚеҸ°еұ•зҺ°гҖӮ
еңЁдёӢйқўзҡ„жЎҲдҫӢдёӯпјҢеӨҡз»ҙеҲҶжһҗзі»з»ҹиҰҒй’ҲеҜ№и®ўеҚ•ж•°жҚ®еҒҡиҮӘеҠ©еҲҶжһҗгҖӮдёәдәҶз®ҖеҢ–иө·и§ҒпјҢжҲ‘们йҮҮз”ЁдәҶд»ҘдёӢжЁЎжӢҹзҺҜеўғпјҡ
l еӨҡз»ҙеҲҶжһҗзі»з»ҹеүҚеҸ°з”ЁtomcatжңҚеҠЎеҷЁдёӯзҡ„jdbc.jspиҝӣиЎҢжЁЎжӢҹгҖӮTomcatе®үиЈ…еңЁwindowsж“ҚдҪңзі»з»ҹзҡ„C:\tomcat6гҖӮ
l йӣҶз®—еҷЁJDBCйӣҶжҲҗеңЁеӨҡз»ҙеҲҶжһҗеә”з”ЁдёӯгҖӮjdbc.jspжЁЎд»ҝеӨҡз»ҙеҲҶжһҗеә”з”Ёзі»з»ҹпјҢдә§з”ҹз¬ҰеҗҲйӣҶз®—еҷЁи§„иҢғзҡ„SQLпјҢйҖҡиҝҮйӣҶз®—еҷЁJDBCжҸҗдәӨз»ҷйӣҶз®—еҷЁSPLи„ҡжң¬еӨ„зҗҶгҖӮ
l еӨҡз»ҙеҲҶжһҗзі»з»ҹзҡ„ж•°жҚ®дёҖйғЁеҲҶжқҘиҮӘдәҺз”ҹдә§ж•°жҚ®еә“пјҲOracleж•°жҚ®еә“пјү demoдёӯзҡ„ORDERSиЎЁпјҢеҸҰдёҖйғЁеҲҶжқҘиҮӘеҺҶеҸІеә“пјҲMysqlж•°жҚ®еә“пјүtestгҖӮеҪ“еӨ©ж•°жҚ®иҝһжҺҘз”ҹдә§еә“еҸ–ж•°пјҢе®һзҺ°е®һж—¶еҲҶжһҗгҖӮ
l ETLиҝҮзЁӢжҜҸеӨ©е°ҶеҪ“еӨ©зҡ„жңҖж–°ж•°жҚ®еҗҢжӯҘеҲ°еҺҶеҸІеә“дёӯгҖӮж—Ҙжңҹд»Ҙи®ўиҙӯж—ҘжңҹORDERDATEдёәеҮҶпјҢеҒҮи®ҫеҪ“еүҚзҡ„ж—ҘжңҹжҳҜ2015-07-18гҖӮORDERDATEзҡ„ејҖе§Ӣе’Ңз»“жқҹж—ҘжңҹжҳҜеӨҡж–№дҪҚеҲҶжһҗзҡ„еҝ…йҖүжқЎд»¶гҖӮ
жЎҲдҫӢдёӯеҢ…еҗ«з”ҹдә§еә“е’Ң1дёӘеҺҶеҸІеә“пјҢе®һйҷ…дёҠйӣҶз®—еҷЁд№ҹж”ҜжҢҒдёҖдёӘз”ҹдә§еә“е’ҢеҗҢж—¶еӨҡдёӘеҺҶеҸІеә“пјҢжҲ–иҖ…жІЎжңүз”ҹдә§еә“дҪҶжңүеӨҡдёӘеҺҶеҸІеә“зҡ„жғ…еҶөгҖӮ
з”ЁдёӢйқўзҡ„sqlж–Ү件еңЁORACLEж•°жҚ®еә“дёӯе®ҢжҲҗORDERSиЎЁзҡ„е»әиЎЁе’Ңж•°жҚ®еҲқе§ӢеҢ–гҖӮ
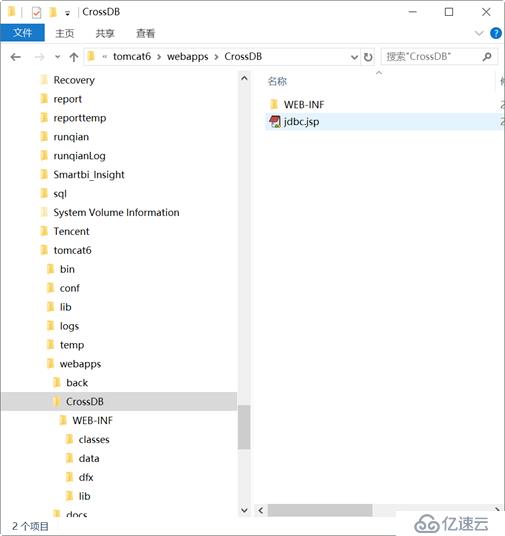
й…ҚзҪ®ж–Ү件еңЁ classes дёӯпјҢеңЁе®ҳзҪ‘дёҠиҺ·еҸ–зҡ„жҺҲжқғж–Ү件д№ҹиҰҒж”ҫеңЁ classes зӣ®еҪ•дёӯгҖӮйӣҶз®—еҷЁзҡ„ Jar еҢ…иҰҒж”ҫеңЁ lib зӣ®еҪ•дёӯпјҲйңҖиҰҒе“Әдәӣ jar иҜ·еҸӮз…§йӣҶз®—еҷЁж•ҷзЁӢпјүгҖӮ
дҝ®ж”№ raqsoftConfig.xml дёӯзҡ„дё»зӣ®еҪ•й…ҚзҪ®пјҡ
<mainPath>C:\tomcat6\webapps\CrossDB\WEB-INF\dfx</mainPath>
<JDBC>
<load>Runtime,Server</load>
<gateway> CrossDB.dfx</gateway>
</JDBC>
2гҖҒ зј–иҫ‘ CrossDB зӣ®еҪ•дёӯзҡ„ jdbc.jspпјҢжЁЎжӢҹеүҚеҸ°з•ҢйқўжҸҗдәӨ sql еұ•зҺ°з»“жһңгҖӮ
<%@ page language="java" import="java.util.*" pageEncoding="utf-8"%>
<%@ page import="java.sql.*" %>
<body>
<%
String driver = "com.esproc.jdbc.InternalDriver";
String url = "jdbc:esproc:local://";
try {
Class.forName(driver);
Connection conn = DriverManager.getConnection(url);
Statement statement = conn.createStatement();
String sql =" select top 10 ORDERID,CUSTOMERID,EMPLOYEEID,ORDERDATE,AMOUNT from ORDERS where ORDERDATE between date('2011-07-18') and date('2015-07-18') and AMOUNT>100 ";
out.println("Test page v1<br><br><br><pre>");
out.println("и®ўеҚ• ID"+"\t"+" е®ўжҲ· ID"+"\t"+" йӣҮе‘ҳ ID"+"\t"+" и®ўиҙӯж—Ҙжңҹ "+"\t"+" и®ўеҚ•йҮ‘йўқ "+"<br>");
ResultSet rs = statement.executeQuery(sql);
int f1,f6;
String f2,f3,f4;
float f5;
while (rs.next()) {
f1 = rs.getInt("ORDERID");
f2 = rs.getString("CUSTOMERID");
f3 = rs.getString("EMPLOYEEID");
f4 = rs.getString("ORDERDATE");
f5 = rs.getFloat("AMOUNT");
out.println(f1+"\t"+f2+"\t"+f3+"\t"+f4+"\t"+f5+"\t"+"<br>");
}
out.println("</pre>");
rs.close();
conn.close();
} catch (ClassNotFoundException e) {
System.out.println("Sorry,can`t find the Driver!");
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
%>
</body>
еңЁ jsp дёӯпјҢе…ҲиҝһжҺҘйӣҶз®—еҷЁзҡ„ JDBCпјҢ然еҗҺжҸҗдәӨжү§иЎҢ SQLгҖӮжӯҘйӘӨе’ҢдёҖиҲ¬зҡ„ж•°жҚ®еә“е®Ңе…ЁдёҖж ·пјҢе…·жңүеҫҲй«ҳзҡ„е…је®№жҖ§е’ҢйҖҡз”ЁжҖ§гҖӮеҜ№дәҺеӨҡз»ҙеҲҶжһҗе·Ҙе…·жқҘиҜҙпјҢиҷҪ然жҳҜз•Ңйқўж“ҚдҪңжқҘиҝһжҺҘ JDBC е’ҢжҸҗдәӨ SQLпјҢдҪҶжҳҜеҹәжң¬еҺҹзҗҶе’Ң jsp е®Ңе…ЁдёҖж ·гҖӮ
3гҖҒ жү“ејҖ dfx зӣ®еҪ•дёӯзҡ„ CrossDB.dfxпјҢи§ӮеҜҹзҗҶи§Ј SPL д»Јз ҒгҖӮ
дј е…ҘеҸӮж•°жҳҜ sql дҫӢеҰӮпјҡ
select top 10 ORDERID,CUSTOMERID,EMPLOYEEID,ORDERDATE,AMOUNT from ORDERS where ORDERDATE between date('2011-07-18') and date('2015-07-18') and AMOUNT>100гҖӮ
SPLи„ҡжң¬еҰӮдёӢпјҡ
A | B | C | |
1 | =sql.sqlparse@aw() | =A1.pselect("ORDERDATE between*") | |
2 | =substr(A1(B1),"date(") | =substr(A1(B1+1),"date(") | |
3 | =mid(A2,2,10) | =mid(B2,2,10) | |
4 | if between(date(now()),date(A3):date(B3)) | ||
5 | =connect("orcl") | =B5.cursor@dx("select ORDERID,CUSTOMERID,EMPLOYEEID,ORDERDATE,AMOUNT from orders where orderdate=?",date(now())) | |
6 | =connect("mysql") | =B6.cursor@x("select ORDERID,CUSTOMERID,EMPLOYEEID,ORDERDATE,AMOUNT from orders") | |
7 | =mcs=[C5,C6].mcursor() | =connect().cursor@x("with orders as(mcs)"+sql) | |
8 | return C7 | ||
9 | else | =connect("mysql") | =B9.cursor@x(sql.sqltranslate("MYSQL")) |
10 | return C9 | ||
иҜҙжҳҺпјҡ
A1пјҡи§Јжһҗ SQLпјҢиҺ·еҸ– where еӯҗеҸҘпјҢ并用з©әж јжқҘжӢҶеҲҶжҲҗеәҸеҲ—гҖӮ
B1пјҢA2-B3пјҡеңЁ A1 еәҸеҲ—жүҫеҲ°еҝ…йҖүжқЎд»¶и®ўиҙӯж—ҘжңҹпјҢиҺ·еҸ–ејҖе§Ӣе’Ңз»“жқҹж—ҘжңҹеҖјгҖӮ
A4пјҡеҲӨж–ӯжҹҘиҜўиҢғеӣҙжҳҜеҗҰеҢ…еҗ«еҪ“еүҚж—ҘжңҹгҖӮ
B5-C6пјҡеҰӮжһңеҢ…еҗ«еҪ“еүҚж—ҘжңҹпјҢе°ұиҝһжҺҘз”ҹдә§еә“е’ҢеҺҶеҸІеә“пјҢе»әз«ӢеҸ–ж•°жёёж ҮгҖӮ
B7пјҡз”Ёз”ҹдә§еә“е’ҢеҺҶеҸІеә“жёёж Үе»әз«ӢеӨҡи·Ҝжёёж ҮгҖӮ
C7гҖҒB8пјҡеҜ№еӨҡи·Ҝжёёж ҮиҝӣиЎҢ sql жҹҘиҜўе№¶иҝ”еӣһз»“жһңгҖӮ
A9-C10пјҡеҰӮжһңдёҚеҢ…еҗ«еҪ“еүҚж—ҘжңҹпјҢе°ұеҸӘиҝһжҺҘеҺҶеҸІж•°жҚ®еә“гҖӮе°Ҷ SQL зҝ»иҜ‘жҲҗз¬ҰеҗҲ MYSQL ж•°жҚ®еә“规иҢғзҡ„ SQL, жү§иЎҢ SQL еҫ—еҲ°жёёж Ү并иҝ”еӣһгҖӮ
е®һйҷ…дёҡеҠЎдёӯпјҢз”ҹдә§еә“дёҖиҲ¬йғҪжңүеҝ…иҰҒдҝқжҢҒдёҖдәӣеҺҶеҸІж•°жҚ®пјҢиҝҷж ·з”ҹдә§еә“е’ҢеҺҶеҸІеә“дјҡжңүйҮҚеӨҚж•°жҚ®пјҢжүҖд»Ҙд»Јз ҒдёӯйңҖиҰҒз»ҷз”ҹдә§еә“еҶҚеҠ дёҠж—ҘжңҹжқЎд»¶гҖӮеҰӮжһңжҳҜеӨҡдёӘеҺҶеҸІеә“еҲҶеә“зҡ„жғ…еҶөпјҢдёҖиҲ¬жқҘи®ІпјҢиҝҷдәӣеә“д№Ӣй—ҙе°ұжІЎжңүйҮҚеӨҚзҡ„ж•°жҚ®пјҢд»Јз ҒиғҪеӨҹз®ҖеҢ–дёҖдәӣгҖӮжҜ”еҰӮпјҢеҒҮи®ҫдҫӢдёӯзҡ„ ORACLE е’Ң MYSQL жІЎжңүйҮҚеӨҚж•°жҚ®пјҢеҲҷ CrossDB.dfx зҡ„д»Јз ҒеҸҜд»Ҙз®ҖеҢ–еҰӮдёӢпјҡ
A | B | |
1 | =connect("orcl") | =A1.cursor@dx("select ORDERID,CUSTOMERID,EMPLOYEEID,ORDERDATE,AMOUNT from orders") |
2 | =connect("mysql") | =A2.cursor@x("select ORDERID,CUSTOMERID,EMPLOYEEID,ORDERDATE,AMOUNT from orders") |
3 | =mcs=[B1,B2].mcursor() | =connect().cursor@x("with orders as(mcs)"+sql) |
4 | return B3 |
4гҖҒ еҗҜеҠЁ tomcatпјҢеңЁжөҸи§ҲеҷЁдёӯи®ҝй—®http://localhost:8080/CrossDB/jdbc.jspпјҢжҹҘзңӢз»“жһңгҖӮ
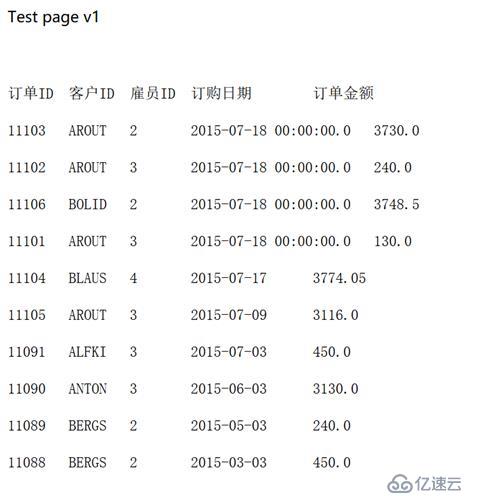
з»“жһңдёӯи®ўиҙӯж—Ҙжңҹж јејҸз•ҘжңүдёҚеҗҢпјҢиҝҷеҸӘйңҖиҰҒеңЁеӨҡз»ҙеҲҶжһҗеүҚз«Ҝи®ҫзҪ®дёҖдёӢжҳҫзӨәж јејҸеҚіеҸҜгҖӮ
жҲ‘们иҝҳеҸҜд»Ҙ继з»ӯжөӢиҜ•еҰӮдёӢжғ…еҶөпјҡ
1гҖҒ д»…д»…жҹҘиҜўеҺҶеҸІеә“
sql ="select top 10 ORDERID,CUSTOMERID,EMPLOYEEID,ORDERDATE,AMOUNT from ORDERS where ORDERDATE between date('2011-07-18') and date('2015-07-18') and AMOUNT>100";
2гҖҒ еҲҶз»„жҹҘиҜў
sql ="select CUSTOMERID,EMPLOYEEID,sum(AMOUNT) S,count(1) C from ORDERS where ORDERDATE between date('2011-07-18') and date('2015-07-18') group by CUSTOMERID,EMPLOYEEID"
еңЁиҝҷдёӘжЎҲдҫӢдёӯпјҢйӣҶз®—еҷЁSPLи„ҡжң¬иҝҳеҸҜд»ҘжүҝжӢ…ETLзҡ„е·ҘдҪңгҖӮ
еӨҡз»ҙеҲҶжһҗзі»з»ҹдёҠзәҝд№ӢеҗҺпјҢиҰҒжҜҸеӨ©жҷҡдёҠе®ҡж—¶еҗҢжӯҘеҪ“еӨ©жңҖж–°зҡ„ж•°жҚ®гҖӮжҲ‘们еҒҮи®ҫеҪ“еӨ©ж—ҘжңҹжҳҜ2015-07-18гҖӮ
SPLиҜӯиЁҖи„ҡжң¬etl.dfxе°ҶеҪ“еӨ©ж•°жҚ®еўһйҮҸиЎҘе……еҲ°еҺҶеҸІеә“дёӯпјҢе…·дҪ“и„ҡжң¬еҰӮдёӢпјҡ
A | |
1 | =connect("orcl") |
2 | =A1.cursor@xd("select ORDERDATE,CUSTOMERID,EMPLOYEEID,ORDERID,AMOUNT from ORDERS where ORDERDATE=?",etlDate) |
3 | =connect("mysql") |
4 | =A3.update@i(B2, ORDERS,ORDERDATE,CUSTOMERID,EMPLOYEEID,ORDERID,AMOUNT) |
5 | >A3.close() |
etl.dfxзҡ„иҫ“е…ҘеҸӮж•°жҳҜetlDateпјҢд№ҹе°ұжҳҜйңҖиҰҒж–°еўһзҡ„еҪ“еӨ©ж—ҘжңҹгҖӮ
etl.dfxи„ҡжң¬еҸҜд»Ҙз”ЁwindowsжҲ–иҖ…linuxе‘Ҫд»ӨиЎҢзҡ„ж–№ејҸжү§иЎҢпјҢз»“еҗҲе®ҡж—¶д»»еҠЎпјҢеҸҜд»Ҙе®ҡж—¶жү§иЎҢгҖӮд№ҹеҸҜд»Ҙз”ЁETLе·Ҙе…·жқҘе®ҡж—¶и°ғз”ЁгҖӮ
windowsе‘Ҫд»ӨиЎҢзҡ„и°ғз”Ёж–№ејҸжҳҜпјҡ
C:\Program Files\raqsoft\esProc\bin>esprocx.exe C: \etl.dfx 2015-07-18
linuxе‘Ҫд»ӨжҳҜ:
/raqsoft/esProc/bin/esprocx.sh /esproc/ etl.dfx 2015-07-18
дҪңдёәж•°жҚ®и®Ўз®—дёӯй—ҙ件пјҲDCMпјүпјҢз”ұйӣҶз®—еҷЁжҸҗдҫӣзҡ„еҗҺеҸ°ж•°жҚ®жәҗеҸҜд»Ҙж”ҜжҢҒеҗ„з§ҚеүҚз«Ҝеә”з”ЁпјҢдёҚд»…йҷҗдәҺеүҚз«ҜжҳҜеӨҡз»ҙеҲҶжһҗзҡ„жғ…еҶөпјҢиҝҳеҸҜд»ҘеҢ…жӢ¬дҫӢеҰӮеӨ§еұҸеұ•зӨәгҖҒз®ЎзҗҶй©ҫ驶иҲұгҖҒе®һж—¶жҠҘиЎЁгҖҒеӨ§ж•°жҚ®йҮҸжё…еҚ•жҠҘиЎЁгҖҒжҠҘиЎЁжү№йҮҸи®ўйҳ…зӯүзӯүеңәжҷҜгҖӮ
еҸҰеӨ–пјҢйӣҶз®—еҷЁеҪўжҲҗзҡ„еҗҺеҸ°ж•°жҚ®жәҗд№ҹеҸҜд»Ҙе°Ҷж•°жҚ®зј“еӯҳи®Ўз®—гҖӮиҝҷж—¶пјҢйҮҮз”ЁйӣҶз®—еҷЁе®һзҺ°зҡ„ж•°жҚ®и®Ўз®—зҪ‘е…іе’Ңи·Ҝз”ұпјҢе°ұеҸҜд»ҘеңЁйӣҶз®—еҷЁзј“еӯҳж•°жҚ®е’Ңж•°жҚ®д»“еә“д№Ӣй—ҙжҷәиғҪеҲҮжҚўпјҢд»ҺиҖҢи§ЈеҶіж•°жҚ®д»“еә“ж— жі•ж»Ўи¶ізҡ„жҖ§иғҪиҰҒжұӮй—®йўҳпјҢдҫӢеҰӮеёёи§Ғзҡ„еҶ·зғӯж•°жҚ®еҲҶејҖи®Ўз®—зҡ„еңәжҷҜгҖӮпјҲе…·дҪ“еҒҡжі•еҸӮи§ҒгҖҠйӣҶз®—еҷЁе®һзҺ°и®Ўз®—и·Ҝз”ұдјҳеҢ–BIеҗҺеҸ°жҖ§иғҪгҖӢпјүгҖӮ
еңЁеҸҰдёҖдәӣеә”з”ЁдёӯпјҢйӣҶз®—еҷЁд№ҹеҸҜд»Ҙе®Ңе…Ёи„ұзҰ»ж•°жҚ®еә“пјҢиө·еҲ°иҪ»йҮҸзә§еӨҡз»ҙеҲҶжһҗеҗҺеҸ°зҡ„дҪңз”ЁпјҢиҝҷж—¶зҡ„йӣҶз®—еҷЁе°ұзӣёеҪ“дәҺзӢ¬з«Ӣзҡ„дёӯе°ҸеһӢж•°жҚ®д»“еә“жҲ–иҖ…ж•°жҚ®йӣҶеёӮдәҶгҖӮпјҲе…·дҪ“еҒҡжі•еҸӮи§ҒгҖҠйӣҶз®—еҷЁе®һзҺ°иҪ»йҮҸзә§еӨҡз»ҙеҲҶжһҗеҗҺеҸ°гҖӢгҖӮпјү
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ