您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
hadoop 2.7.7 安装(测试环境部署) hadoop2.x部署
系统环境(censtos 6.5 ):
172.16.57.97 namenodeyw 172.16.57.98 datanodeyw1 172.16.57.238 datanodeyw2
软件下载:
hadoop
wget http://mirrors.shu.edu.cn/apache/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
Zookeeper3.4.10
wget http://mirror.bit.edu.cn/apache/zookeeper/zookeeper-3.4.10/zookeeper-3.4.10.tar.gz
hbase2.0.2
wget http://mirror.bit.edu.cn/apache/hbase/2.0.2/hbase-2.0.2-bin.tar.gz
jdk1.8.0_92:
所有集群服务器ssh端口必须一致
一、环境配置
1、三台服务器修改hostname ,修改系统参数(limit.conf)
#hostname namenodeyw #vim /etc/sysconfig/network NETWORKING=yes HOSTNAME=namenodeyw #vim /etc/security/limits.conf * soft nofile 102400 * hard nofile 102400 * soft nproc 65536 * hard nproc 65536
检查 /etc/security/limits.d/90-nproc.conf 是否存在,如果存在则需要增加一下配置
* soft nproc 6553
2、创建hadoop用户并设置hadoop用户密码(将家目录设置到分区大的里面)
#useradd -d /opt/hadoop -g hadoop -m hadoop (#将hadoop家目录指定到/opt/下,指定hadoop用户群组及登录用户目录) #passwd hadoop (#设置密码)
3、三台hadoop用户下分别做免密钥登录
分别执行ssh-keygen -t rsa 进入.ssh 目录下 : cd /opt/hadoop/.ssh ssh-copy-id -i id_rsa.pub "-p 45685 hadoop@172.16.57.97" (两两互通ssh免密钥) ssh -p ssh端口 hostname (两两相互登录认证)
4、分别在三台服务器上安装jdk,版本jdk1.8.0_92
在/usr/java/中解压安装包
配置环境变量 /etc/profile 及hadoop用户下的 .bash_profile
#jdk export JAVA_HOME=/usr/java/jdk1.8.0_92 export CLASSPATH=.:$JAVA_HOME/lib/tools.jar export PATH=$JAVA_HOME/bin:$PATH
执行source /etc/profile 生效
5、设置/etc/selinux/config 为disable 重启系统
#vim /etc/selinux/config SELINUX=disabled
6、配置防火墙访问权限。
7、分别在三台服务器上添加主机名与IP地址映射 (通过root用户同步)
#vim /etc/hosts 172.16.57.97 namenodeyw 172.16.57.98 datanodeyw1 172.16.57.238 datanodeyw2
二、安装hadoop 2.7.7
1、使用hadoop用户登录后,将hadoop压缩包解压在当前目录下,然后配置环境变量
cd /opt/hadoop tar zxf hadoop-2.7.7.tar.gz
配置环境变量 /etc/profile 以及hadoop用户下的 .bash_profile 文件
#hadoop 2.7.7 export HADOOP_HOME=/opt/hadoop/hadoop-2.7.7 export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
执行命令source /etc/profile 使命令生效
2、hadoop配置修改
参照附件设置
3、配置修改
vi hadoop-env.sh export HADOOP_SSH_OPTS="-p 45685" #如果ssh端口默认不为22 则需要添加此行 export JAVA_HOME=/usr/java/jdk1.8.0_92
4、将namenode上修改完成的hadoop-2.7.7目录分别拷贝至其他节点上
$scp -r -P 45685 hadoop-2.7.7 datanodeyw1:/opt/hadoop/ $scp -r -P 45685 hadoop-2.7.7 datanodeyw2:/opt/hadoop/
5、在namenode上进行初始化设置
$cd /opt/hadoop/hadoop-2.7.7/bin $./hadoop namenode -format
6、执行启动命令:
启动hadoop之前jps查看进程为空
执行 start-all.sh 后 进程表为如下:
在namenode上启动的服务有以下
[hadoop@namenodeyw sbin]$ jps 1507 Jps 1079 ResourceManager 906 SecondaryNameNode 731 DataNode 1196 NodeManager 589 NameNode
[hadoop@namenodeyw sbin]$ jps -l 1524 sun.tools.jps.Jps 1079 org.apache.hadoop.yarn.server.resourcemanager.ResourceManager 906 org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode 731 org.apache.hadoop.hdfs.server.datanode.DataNode 1196 org.apache.hadoop.yarn.server.nodemanager.NodeManager 589 org.apache.hadoop.hdfs.server.namenode.NameNode
在datanodeyw1上启动的服务为:
[hadoop@datanodeyw1 ~]$ jps 24103 NodeManager 24346 Jps 23965 DataNode
[hadoop@datanodeyw1 ~]$ jps -l 24103 org.apache.hadoop.yarn.server.nodemanager.NodeManager 24361 sun.tools.jps.Jps 23965 org.apache.hadoop.hdfs.server.datanode.DataNode
在datanodeyw2上启动的服务为:
[hadoop@datanodeyw2 hadoop]$ jps 23664 DataNode 23781 NodeManager 23902 Jps
[hadoop@datanodeyw2 hadoop]$ jps -l 23664 org.apache.hadoop.hdfs.server.datanode.DataNode 23781 org.apache.hadoop.yarn.server.nodemanager.NodeManager 23914 sun.tools.jps.Jps
7、在hadoop上创建目录并上传文件验证
hadoop fs -mkdir -p /data/test hadoop fs -put hadoop-2.7.7.tar.gz /data/test/ hadoop fs -ls /data/test #查看文件是否上传成功
8、web页面查询
http://172.16.57.97:8088/cluster/cluster #hadoop cluster http://172.16.57.97:50070/dfshealth.html#tab-overview #进入浏览文件查看上传文件是否存在
三 、安装 Zookeeper3.4.10
1、在namenode上将下载的 Zookeeper3.4.10 解压至/opt/hadoop目录下
2、分别在三台服务器上修改环境变量/etc/profile 及hadoop用户下的.bash_profile文件并使其生效
3、分别在三台服务器上创建目录
mkdir -p /opt/hadoop/zookeeper/{data,dataLog}4、分别在三台服务器上创建 myid 文件
namenodeyw: echo "1" >> /opt/hadoop/zookeeper/data/myid datanodeyw1: echo "2" >> /opt/hadoop/zookeeper/data/myid datanodeyw2: echo "3" >> /opt/hadoop/zookeeper/data/myid
说明:上面新建的目录可以不和我一样,myid中的数字编号也可以不一样,只要和下面zoo.cfg的配置对应即可,但是建成一样也无妨。
5、修改zookeeper配置zoo.cfg ()
进入/opt/hadoop/zookeeper-3.4.10/conf 下
$cd /opt/hadoop/zookeeper-3.4.10/conf $cp -r zoo_sample.cfg zoo.cfg $vim zoo.cfg dataDir=/opt/hadoop/zookeeper/data dataLogDir=/opt/hadoop/zookeeper/dataLog server.1=namenodeyw:2888:3888 server.2=datanodeyw1:2888:3888 server.3=datanodeyw2:2888:3888
6、将namenode上修改完成的 zookeeper-3.4.10目录分别拷贝至其他节点上
$scp -r -P 45685 zookeeper-3.4.10 datanodeyw1:/opt/hadoop/ $scp -r -P 45685 zookeeper-3.4.10 datanodeyw2:/opt/hadoop/
7、分别启动zookeeper集群
zookeeper用法:
Usage: /opt/hadoop/zookeeper-3.4.10/bin/zkServer.sh {start|start-foreground|stop|restart|status|upgrade|print-cmd}2. 命令:
/opt/hadoop/zookeeper-3.4.10/bin/zkServer.sh start #启动 /opt/hadoop/zookeeper-3.4.10/bin/zkServer.sh stop #停止 /opt/hadoop/zookeeper-3.4.10/bin/zkServer.sh status #查看状态(验证结果是否正常)
说明:dataDir和dataLogDir需要自己创建,目录可以自己制定,对应即可。server.1中的这个1需要和namenodeyw这个机器上的dataDir目录中的myid文件中的数值对应。server.2中的这个2需要和datanodeyw1这个机器上的dataDir目录中的myid文件中的数值对应。server.3中的这个3需要和datanodeyw2这个机器上的dataDir目录中的myid文件中的数值对应。当然,数值你可以随便用,只要对应即可。2888和3888的端口号也可以随便用,因为在不同机器上,用成一样也无所
谓。
8、zookeeper正常结果验证:
四、hbase 安装配置
1、在namenode服务器上将下载的hbase2.0.2.tar.gz 安装包解压至/opt/hadop/下
2、各个节点修改环境变量/etc/profile 及hadoop用户下的.bash_profile文件并使其生效
3、创建文件夹
mkdir -p /opt/hadoop/hbase/{tmp,pids}4、在nodename上修改hbase配置(参照附件 )
vim /opt/hadoop/hbase-2.0.2/conf/hbase-env.sh export HBASE_SSH_OPTS="-p 45685" #如果ssh端口默认不为22 则需要添加此行 export JAVA_HOME=/usr/java/jdk1.8.0_92 export HADOOP_HOME=/opt/hadoop/hadoop-2.7.7 export ZOOKEEPER_HOME=/opt/hadoop/zookeeper-3.4.10 export HBASE_HOME=/opt/hadoop/hbase-2.0.2 export HBASE_PID_DIR=/root/hbase/pids export HBASE_MANAGES_ZK=false
hbase-site.xml
<configuration> <property> <name>hbase.rootdir</name> <value>hdfs://namenodeyw:9000/hbase</value> <description>The directory shared byregion servers.</description> </property> <property> <name>hbase.zookeeper.property.clientPort</name> <value>2181</value> <description>Property from ZooKeeper'sconfig zoo.cfg. The port at which the clients will connect. </description> </property> <property> <name>zookeeper.session.timeout</name> <value>120000</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>namenodeyw,datanodeyw1,datanodeyw2</value> </property> <property> <name>hbase.tmp.dir</name> <value>/opt/hadoop/hbase/tmp</value> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> </configuration>
regionservers (根据配置regionservers,文件中缺少datanodeyw1,则在datanodeyw1上启动hbase,datanodeyw1作为hmaster服务)
namenodeyw datanodeyw2
5、如果系统ssh端口不为22 则需要修改配置
vim hbase-env.sh export HBASE_SSH_OPTS="-p 45685"
6、将namenodeyw上修改完成的hbase-2.0.2 目录同步至其他节点/opt/hadoop 路径下
$scp -r -P 45685 hbase-2.0.2 datanodeyw1:/opt/hadoop/ $scp -r -P 45685 hbase-2.0.2 datanodeyw2:/opt/hadoop/
7、在datanodeyw1启动hbase服务(根据配置regionservers线上,文件中缺少datanodeyw1,则在datanodeyw1上启动hbase文件,则该节点作为hmaster服务)
cd /opt/hadoop/hbase-2.0.2/bin ./start-hbase.sh
8、验证启动完成后查看进程
datanodeyw1:
[hadoop@datanodeyw1 bin]$ jps 4835 HMaster #hbase 主节点 6667 Jps 25675 DataNode 30862 QuorumPeerMain #zookeeper 25807 NodeManager
datanodeyw2:
[hadoop@datanodeyw2 home]$ jps 24805 HRegionServer #hbase 守护进程 24485 QuorumPeerMain #zookeeper 24983 Jps 24057 DataNode 24171 NodeManager
namenodeyw:
[hadoop@namenodeyw ~]$ jps 2832 NodeManager 2387 DataNode 2248 NameNode 4072 HRegionServer 4251 Jps 3596 QuorumPeerMain #zookeeper 2716 ResourceManager 2558 SecondaryNameNode
9、web页面查询状态
http://172.16.57.98:16010/master-status
五、zabbix监控添加
1. 任意一台hadoop节点上,hadoop用户下添加crontab -e
*/5 * * * * /opt/hadoop/hadoop-2.7.7/bin/hadoop dfsadmin -report > /tmp/hadoop.status */5 * * * * /bin/echo "status" |/opt/hadoop/hbase-2.0.2/bin/hbase shell > /tmp/hbase.status
2. 修改zabbix配置文件zabbix_agentd.conf.d/hadoop.conf
hadoop1.x
vi zabbix_agentd.conf.d/hadoop.conf #状态监控key UserParameter=dfs.status,cat /tmp/hadoop-status |grep "dead" |cut -d ' ' -f 6 UserParameter=hbase.status,cat /tmp/hbase-status |grep "server" |cut -d ' ' -f 1
hadoop2.7x
vi zabbix_agentd.conf.d/hadoop.conf
#状态监控key
UserParameter=dfs.status,cat /tmp/hadoop.status |grep "Live datanodes"|awk -F"[()]" '{print $2}'
UserParameter=hbase.status,cat /tmp/hbase.status |grep "dead" |cut -d ',' -f 4|cut -d ' ' -f 23. 重启zabbix-agentd服务
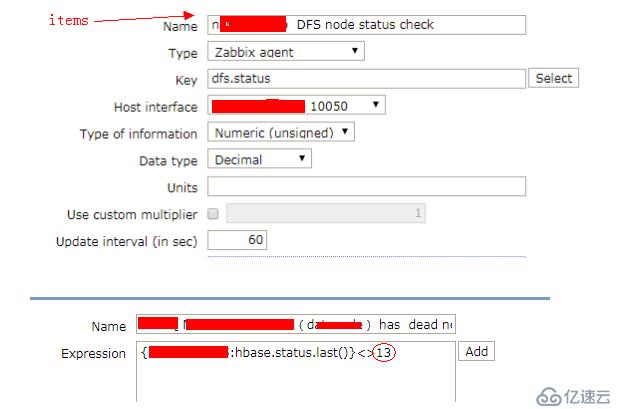
4. zabbix添加监控项
dfs.status 监控参数为datanode 节点挂掉后的告警
zabbix监控添加
dfs存在死亡节点处理
http://172.16.57.97:50070/dfshealth.html#tab-overview (#namenode)
点击页面上的 Dead Nodes 进入:
启动方式:
hadoop-daemon.sh start datanode
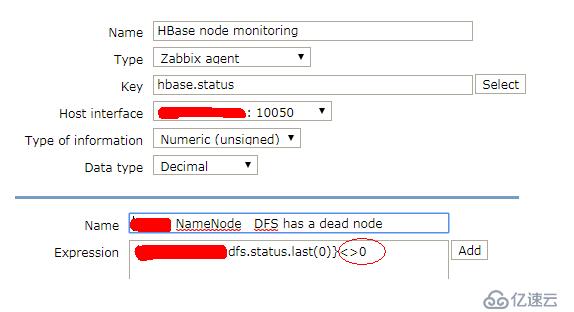
hbase.status 监控参数为hbase进程节点挂掉后的告警
zabbix监控添加
hbase 存在死亡节点处理
http://172.16.57.98:16010/master-status #(该链接地址为hmaster 进程所在服务器IP及端口)
页面显示 Dead Region Servers 中 hostname 即故障点服务器。
启动方式:
hbase-daemon.sh start regionserver
6、FAQ
1 执行 start-all.sh 报错
[hadoop@namenodeyw sbin]$ ./start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
18/09/10 12:12:27 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting namenodes on [namenodeyw]
namenodeyw: starting namenode, logging to /opt/hadoop/hadoop-2.7.7/logs/hadoop-hadoop-namenode-namenodeyw.out
namenodeyw: starting datanode, logging to /opt/hadoop/hadoop-2.7.7/logs/hadoop-hadoop-datanode-namenodeyw.out
datanodeyw2: starting datanode, logging to /home/hadoop/hadoop-2.7.7/logs/hadoop-hadoop-datanode-datanodeyw2.out
datanodeyw1: starting datanode, logging to /opt/hadoop/hadoop-2.7.7/logs/hadoop-hadoop-datanode-datanodeyw1.out
datanodeyw2: [Fatal Error] core-site.xml:24:5: The markup in the document following the root element must be well-formed.
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /opt/hadoop/hadoop-2.7.7/logs/hadoop-hadoop-secondarynamenode-namenodeyw.out
18/09/10 12:12:42 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
starting yarn daemons
starting resourcemanager, logging to /opt/hadoop/hadoop-2.7.7/logs/yarn-hadoop-resourcemanager-namenodeyw.out
datanodeyw2: starting nodemanager, logging to /home/hadoop/hadoop-2.7.7/logs/yarn-hadoop-nodemanager-datanodeyw2.out
namenodeyw: starting nodemanager, logging to /opt/hadoop/hadoop-2.7.7/logs/yarn-hadoop-nodemanager-namenodeyw.out
datanodeyw1: starting nodemanager, logging to /opt/hadoop/hadoop-2.7.7/logs/yarn-hadoop-nodemanager-datanodeyw1.out
datanodeyw2: [Fatal Error] core-site.xml:24:5: The markup in the document following the root element must be well-formed.
配置文件格式错误导致:
2、zookeeper 状态查询报错的问题
[hadoop@namenodeyw conf]$ /opt/hadoop/zookeeper-3.4.10/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/hadoop/zookeeper-3.4.10/bin/../conf/zoo.cfg
Error contacting service. It is probably not running.
解决:检查myid 及zoo.cfg文件是否配置错误
正常结果输出:
2、问题描述
该问题转自:https://www.cnblogs.com/zlslch/p/6418248.html
Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[hadoop@djt002 native]$ pwd
/usr/local/hadoop/hadoop-2.6.0/lib/native
[hadoop@djt002 native]$ ls
libhadoop.a libhadooppipes.a libhadoop.so libhadoop.so.1.0.0 libhadooputils.a libhdfs.a libhdfs.so libhdfs.so.0.0.0
其实,这个问题,要解决很简单,我这里是hadoop-2.6.0版本。
如果你也是hadoop2.6的可以下载下面这个:
http://dl.bintray.com/sequenceiq/sequenceiq-bin/hadoop-native-64-2.6.0.tar
若是其他的hadoop版本,下载下面这个:
http://dl.bintray.com/sequenceiq/sequenceiq-bin/hadoop-native-64-2.*.0.tar
[hadoop@djt002 native]$ tar -xvf hadoop-native-64-2.6.0.tar -C $HADOOP_HOME/lib/native
[hadoop@djt002 native]$ tar -xvf hadoop-native-64-2.6.0.tar -C $HADOOP_HOME/lib
以上,这两个命令都要执行。
然后增加环境变量
[root@djt002 native]# vim /etc/profile
增加下面的内容:
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
让环境变量生效
[root@djt002 native]# source /etc/profile
结果
最后,这个问题成功解决了!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。