жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
еӨ§ж•°жҚ®зҡ„зғӯеәҰеңЁжҢҒз»ӯзҡ„еҚҮжё©пјҢ继дә‘и®Ўз®—д№ӢеҗҺеӨ§ж•°жҚ®жҲҗдёәеҸҲдёҖеӨ§дј—жүҖиҝҪжҚ§зҡ„ж–°жҳҹгҖӮжҲ‘们жҡӮдёҚеҺ»и®Ёи®әеӨ§ж•°жҚ®еҲ°еә•жҳҜеҗҰйҖӮз”ЁдәҺжӮЁзҡ„е…¬еҸёжҲ–з»„з»ҮпјҢиҮіе°‘еңЁдә’иҒ”зҪ‘дёҠе·Із»Ҹиў«еҗ№еҳҳжҲҗж— жүҖдёҚиғҪзҡ„и¶…зә§жҲҳиҲ°гҖӮ
еӨ§ж•°жҚ®зҡ„зғӯеәҰеңЁжҢҒз»ӯзҡ„еҚҮжё©пјҢ继дә‘и®Ўз®—д№ӢеҗҺеӨ§ж•°жҚ®жҲҗдёәеҸҲдёҖеӨ§дј—жүҖиҝҪжҚ§зҡ„ж–°жҳҹгҖӮжҲ‘们жҡӮдёҚеҺ»и®Ёи®әеӨ§ж•°жҚ®еҲ°еә•жҳҜеҗҰйҖӮз”ЁдәҺжӮЁзҡ„е…¬еҸёжҲ–з»„з»ҮпјҢиҮіе°‘еңЁдә’иҒ”зҪ‘дёҠе·Із»Ҹиў«еҗ№еҳҳжҲҗж— жүҖдёҚиғҪзҡ„и¶…зә§жҲҳиҲ°гҖӮеҘҪеғҸдёҖеӨңд№Ӣй—ҙжҲ‘们е°ұд»Һдә’иҒ”зҪ‘ж—¶д»Ји·іи·ғиҝӣдәҶеӨ§ж•°жҚ®ж—¶д»Ј!е…ідәҺеҲ°еә•д»Җд№ҲжҳҜеӨ§ж•°жҚ®пјҢиҜҙзңҹзҡ„пјҢеҲ°зӣ®еүҚдёәжӯўе°ұе’Ңдә‘и®Ўз®—дёҖж ·пјҢи®©жҲ‘жҖ»и§үеҫ—еғҸжҳҜеңЁзңӢз”өеҪұгҖҠдә‘еӣҫгҖӢвҖ”вҖ”дә‘йҮҢйӣҫйҮҢзҡ„ж„ҹи§үгҖӮжҲ–и®ёйӮЈдәӣжӯЈеңЁеҗ‘дҪ жҺЁй”ҖеӨ§ж•°жҚ®дә§е“Ғзҡ„е…¬еҸёдјҡеҜ№жӮЁжҸҸз»ҳдёҖе№…д№ҢжүҳйӮҰдјјзҡ„зҫҺдёҪз”»йқўпјҢдҪҶжҳҜжӮЁиҮіе°‘иҰҒдҝқжҢҒжё…йҶ’зҡ„еӨҙи„‘пјҢи®Өзңҹд»”з»Ҷзҡ„ж…Һй—®дёҖдёӢиҮӘе·ұпјҢжҲ‘们公еҸёзңҹзҡ„йңҖиҰҒеӨ§ж•°жҚ®еҗ—?
еҒҡдёәдёҖ家第дёүж–№ж”Ҝд»ҳе…¬еҸёпјҢж•°жҚ®зҡ„зЎ®жҳҜе…¬еҸёжңҖжңҖйҮҚиҰҒзҡ„ж ёеҝғиө„дә§гҖӮз”ұдәҺе…¬еҸёжҲҗз«ӢдёҚд№…пјҢйҡҸзқҖдёҡеҠЎзҡ„иҝ…йҖҹеҸ‘еұ•пјҢдәӨжҳ“ж•°жҚ®е‘ҲеҮ дҪ•зә§еўһеҠ пјҢйҡҸд№ӢиҖҢжқҘзҡ„жҳҜзі»з»ҹзҡ„дёҚе ӘйҮҚиҙҹгҖӮдёҡеҠЎйғЁй—ЁгҖҒйўҶеҜјгҖҒз”ҡиҮіжҳҜйӣҶеӣўиҖҒжҖ»ж•ҙеӨ©еҡ·еҡ·зҡ„иҰҒжҠҘиЎЁгҖҒиҰҒеҲҶжһҗгҖҒиҰҒжҸҗеҚҮз«һдәүеҠӣгҖӮиҖҢз ”еҸ‘йғЁй—ЁиғҪеҒҡзҡ„е”ҜдёҖдәӢжғ…е°ұжҳҜжү§иЎҢдёҖжқЎдёҖжқЎеӨҚжқӮеҲ°иҮӘе·ұйғҪйҡҫд»ҘжғіиұЎзҡ„SQLиҜӯеҸҘпјҢзҙ§жҺҘзқҖзі»з»ҹејҖе§ӢзҪўе·ҘпјҢеҶ…еӯҳжәўеҮәпјҢе®•жңә........з®Җзӣҙе°ұжҳҜеҷ©жўҰгҖӮOMG!please release me!!!
е…¶е®һж•°жҚ®йғЁй—Ёзҡ„еҺӢеҠӣеҸҜд»ҘиҜҙжҳҜеёёдәәйҡҫд»ҘжғіиұЎзҡ„пјҢдёәдәҶжҠҠжүҖжңүзҰ»ж•Јзҡ„ж•°жҚ®жұҮжҖ»жҲҗжңүд»·еҖјзҡ„жҠҘе‘ҠпјҢеҸҜиғҪдјҡйңҖиҰҒеҮ дёӘжҳҹжңҹзҡ„ж—¶й—ҙжҲ–жҳҜжӣҙй•ҝгҖӮиҝҷжҳҫ然е’ҢдёҡеҠЎйғЁй—ЁиҰҒжұӮзҡ„еҝ«йҖҹе“Қеә”зҗҶеҝөжҳҜж јж јдёҚе…Ҙзҡ„гҖӮдҝ—иҜқиҜҙпјҢе·Ҙж¬Іе–„е…¶дәӢпјҢеҝ…е…ҲеҲ©е…¶еҷЁгҖӮжҲ‘们д№ҹиҜҘйёҹжһӘжҚўзӮ®дәҶ......гҖӮ
зҪ‘дёҠжңүдёҖеӨ§е Ҷж–Үз« жҸҸиҝ°зқҖеӨ§ж•°жҚ®зҡ„з§Қз§ҚеҘҪеӨ„пјҢд№ҹжңүдёҖеӨ§зҫӨдәәдёҚеҺҢе…¶зғҰзҡ„иҜҙзқҖиҮӘе·ұеҜ№еӨ§ж•°жҚ®зҡ„з§Қз§ҚдҪ“йӘҢпјҢдёҚиҝҮжҲ‘жғій—®дёҖеҸҘпјҢеҲ°еә•жңүеӨҡе°‘дәәеӨҡе°‘з»„з»Үзңҹзҡ„еңЁеҒҡеӨ§ж•°жҚ®?е®һйҷ…зҡ„ж•ҲжһңеҸҲеҰӮдҪ•?зңҹзҡ„з»ҷе…¬еҸёеёҰжқҘд»·еҖјдәҶ?жҳҜеҗҰеҸҜд»Ҙе°Ҷд»·еҖјйҮҸеҢ–?е…ідәҺиҝҷдәӣй—®йўҳпјҢеҘҪеғҸжІЎзңӢеҲ°жңүеӨҡе°‘иҜ„и®әдјҡж¶үеҸҠпјҢеҸҜиғҪжҳҜеӨ§ж•°жҚ®еӨӘж–°дәҶ(е…¶е®һеә•еұӮзҡ„жҰӮеҝө并йқһж–°дәӢзү©пјҢиҖҒ酒装新瓶зҪўдәҶ)пјҢд»ҘиҮідәҺдәә们иҝҳжІүжөёеңЁеҗ„з§ҚзҫҺеҰҷзҡ„YYдёӯгҖӮ
еҒҡдёәдёҖеҗҚдёҘи°Ёзҡ„жҠҖжңҜдәәе‘ҳпјҢеңЁз»ҸиҝҮзҹӯжҡӮзӣІзӣ®зҡ„еҙҮжӢңд№ӢеҗҺпјҢеә”иҜҘеҝ«йҖҹзҡ„иҝӣе…ҘиҗҪең°еә”з”Ёзҡ„з ”з©¶дёӯпјҢиҝҷд№ҹжҳҜиё©зқҖвҖңдә‘еҪ©вҖқзҡ„жһ¶жһ„еёҲе’ҢйӘ‘зқҖиҮӘиЎҢиҪҰзҡ„жһ¶жһ„еёҲзҡ„жң¬иҙЁеҢәеҲ«гҖӮиҜҙдәҶдёҖдәӣзүўйӘҡиҜқпјҢеҪ“еҒҡеҸ‘жі„д№ҹеҘҪпјҢеҚҡзңјзҗғд№ҹеҘҪпјҢжҖ»д№ӢпјҢжҲ‘жғіиЎЁиҫҫзҡ„е…¶е®һеҫҲз®ҖеҚ•пјҡдёҚиҰҒиў«ж–°дәӢзү©жүҖиҝ·жғ‘пјҢд№ҹдёҚиҰҒзӣІзӣ®зҡ„еҙҮжӢңд»»дҪ•дёҖж ·ж–°дәӢзү©пјҢжӣҙдёҚиҰҒдәәдә‘дәҰдә‘пјҢиҝҷжҳҜжҲ‘们еҒҡз ”з©¶зҡ„дәәз»қеҜ№иҰҒдёҚеҫ—гҖӮ
иҜҙдәҶеҫҲеӨҡд№ҹжҳҜж—¶еҖҷиҝӣе…ҘжӯЈйўҳдәҶгҖӮе…¬еҸёй«ҳеұӮеҶіе®ҡпјҢжӯЈејҸеңЁйӣҶеӣўиҢғеӣҙеҶ…е®һж–ҪеӨ§ж•°жҚ®е№іеҸ°(иҝҳзү№ең°йӮҖиҜ·дәҶдёҖдәӣзӨҫеҢәзҡ„й«ҳжүӢпјҢеҫҲжңҹеҫ….......)пјҢеҒҡдёә第дёүж–№ж”Ҝд»ҳе…¬еҸёе®һж–ҪеӨ§ж•°жҚ®е№іеҸ°д№ҹж— еҸҜеҺҡйқһпјҢеӣ жӯӨд№ҹз§ҜжһҒзҡ„еҸӮдёҺеҲ°иҝҷдёӘйЎ№зӣ®дёӯжқҘгҖӮжӯЈеҘҪд№ӢеүҚе…ідәҺOSGiзҡ„дјҒдёҡзә§жЎҶжһ¶зҡ„з ”з©¶д№ҹе‘ҠдёҖж®өиҗҪпјҢжүҖд»ҘжғіеҲ©з”ЁCSDNиҝҷдёӘе№іеҸ°е°Ҷиҝҷж¬ЎеӨ§ж•°жҚ®е№іеҸ°е®һж–ҪиҝҮзЁӢи®°еҪ•дёӢжқҘгҖӮжҲ‘жғідёҖе®ҡиғҪдёәе…¶е®ғжңүзұ»дјјжғіжі•зҡ„дёӘдәәжҲ–е…¬еҸёжҸҗдҫӣеҫҲеҘҪзҡ„еҸӮиҖғиө„ж–ҷ!
第дёҖи®°пјҢеӨ§ж•°жҚ®е№іеҸ°зҡ„ж•ҙдҪ“жһ¶жһ„и®ҫи®Ў
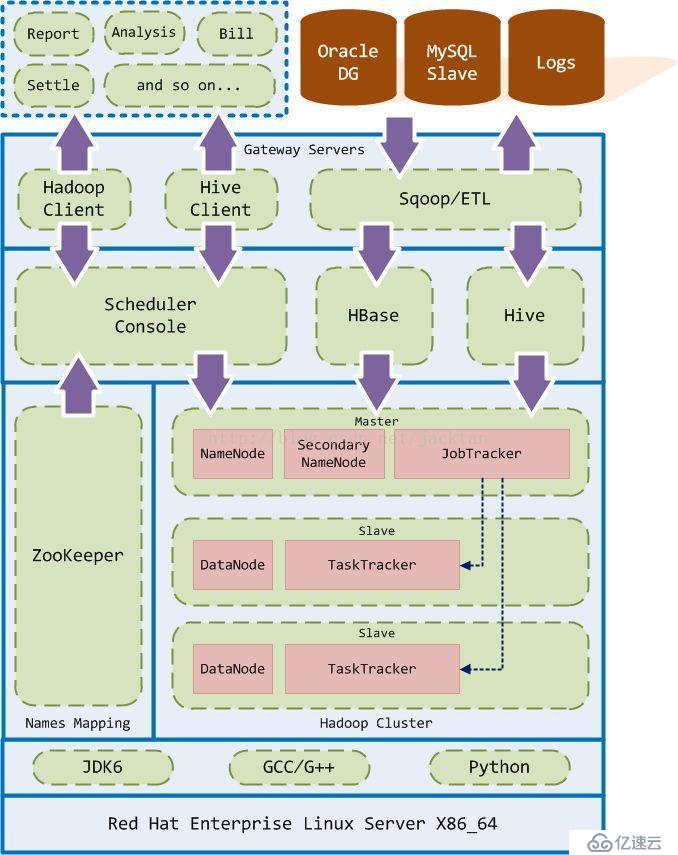
еӨ§ж•°жҚ®е№іеҸ°жһ¶жһ„и®ҫи®ЎжІҝиўӯдәҶеҲҶеұӮи®ҫи®Ўзҡ„жҖқжғіпјҢе°Ҷе№іеҸ°жүҖйңҖжҸҗдҫӣзҡ„жңҚеҠЎжҢүз…§еҠҹиғҪеҲ’еҲҶжҲҗдёҚеҗҢзҡ„жЁЎеқ—еұӮж¬ЎпјҢжҜҸдёҖжЁЎеқ—еұӮж¬ЎеҸӘдёҺдёҠеұӮжҲ–дёӢеұӮзҡ„жЁЎеқ—еұӮж¬ЎиҝӣиЎҢдәӨдә’(йҖҡиҝҮеұӮж¬Ўиҫ№з•Ңзҡ„жҺҘеҸЈ)пјҢйҒҝе…Қи·ЁеұӮзҡ„дәӨдә’пјҢиҝҷз§Қи®ҫи®Ўзҡ„еҘҪеӨ„жҳҜпјҡеҗ„еҠҹиғҪжЁЎеқ—зҡ„еҶ…йғЁжҳҜй«ҳеҶ…иҒҡзҡ„пјҢиҖҢжЁЎеқ—дёҺжЁЎеқ—д№Ӣй—ҙжҳҜжқҫиҖҰеҗҲзҡ„гҖӮиҝҷз§Қжһ¶жһ„жңүеҲ©дәҺе®һзҺ°е№іеҸ°зҡ„й«ҳеҸҜйқ жҖ§пјҢй«ҳжү©еұ•жҖ§д»ҘеҸҠжҳ“з»ҙжҠӨжҖ§гҖӮжҜ”еҰӮпјҢеҪ“жҲ‘们йңҖиҰҒжү©е®№HadoopйӣҶзҫӨж—¶пјҢеҸӘйңҖиҰҒеңЁеҹәзЎҖи®ҫж–ҪеұӮж·»еҠ дёҖеҸ°ж–°зҡ„HadoopиҠӮзӮ№жңҚеҠЎеҷЁеҚіеҸҜпјҢиҖҢеҜ№е…¶д»–жЁЎеқ—еұӮж— йңҖеҒҡд»»дҪ•зҡ„еҸҳеҠЁпјҢдё”еҜ№з”ЁжҲ·д№ҹжҳҜе®Ңе…ЁйҖҸжҳҺзҡ„гҖӮ
ж•ҙдёӘеӨ§ж•°жҚ®е№іеҸ°жҢүе…¶иҒҢиғҪеҲ’еҲҶдёәдә”дёӘжЁЎеқ—еұӮж¬ЎпјҢд»ҺдёӢеҲ°дёҠдҫқж¬Ўдёәпјҡ
иҝҗиЎҢзҺҜеўғеұӮпјҡ
иҝҗиЎҢзҺҜеўғеұӮдёәеҹәзЎҖи®ҫж–ҪеұӮжҸҗдҫӣиҝҗиЎҢж—¶зҺҜеўғпјҢе®ғз”ұ2йғЁеҲҶжһ„жҲҗпјҢеҚіж“ҚдҪңзі»з»ҹе’ҢиҝҗиЎҢж—¶зҺҜеўғгҖӮ
(1)ж“ҚдҪңзі»з»ҹжҲ‘们жҺЁиҚҗе®үиЈ…REHL5.0д»ҘдёҠзүҲжң¬(64дҪҚ)гҖӮжӯӨеӨ–дёәдәҶжҸҗй«ҳзЈҒзӣҳзҡ„IOеҗһеҗҗйҮҸпјҢйҒҝе…Қе®үиЈ…RAIDй©ұеҠЁпјҢиҖҢжҳҜе°ҶеҲҶеёғејҸж–Ү件系з»ҹзҡ„ж•°жҚ®зӣ®еҪ•еҲҶеёғеңЁдёҚеҗҢзҡ„зЈҒзӣҳеҲҶеҢәдёҠпјҢд»ҘжӯӨжҸҗй«ҳзЈҒзӣҳзҡ„IOжҖ§иғҪгҖӮ
(2)иҝҗиЎҢж—¶зҺҜеўғзҡ„е…·дҪ“иҰҒжұӮеҰӮдёӢиЎЁпјҡ
еҗҚз§°зүҲжң¬иҜҙжҳҺ
JDK1.6жҲ–д»ҘдёҠзүҲжң¬HadoopйңҖиҰҒJavaиҝҗиЎҢж—¶зҺҜеўғпјҢеҝ…йЎ»е®үиЈ…JDKгҖӮ
gcc/g++3.xжҲ–д»ҘдёҠзүҲжң¬еҪ“дҪҝз”ЁHadoop PipesиҝҗиЎҢMapReduceд»»еҠЎж—¶пјҢйңҖиҰҒgccзј–иҜ‘еҷЁпјҢеҸҜйҖүгҖӮ
python2.xжҲ–д»ҘдёҠзүҲжң¬еҪ“дҪҝз”ЁHadoop StreamingиҝҗиЎҢMapReduceд»»еҠЎж—¶пјҢйңҖиҰҒpythonиҝҗиЎҢж—¶пјҢеҸҜйҖүгҖӮ
еҹәзЎҖи®ҫж–ҪеұӮпјҡ
еҹәзЎҖи®ҫж–ҪеұӮз”ұ2йғЁеҲҶз»„жҲҗпјҡZookeeperйӣҶзҫӨе’ҢHadoopйӣҶзҫӨгҖӮе®ғдёәеҹәзЎҖе№іеҸ°еұӮжҸҗдҫӣеҹәзЎҖи®ҫж–ҪжңҚеҠЎпјҢжҜ”еҰӮе‘ҪеҗҚжңҚеҠЎгҖҒеҲҶеёғејҸж–Ү件系з»ҹгҖҒMapReduceзӯүгҖӮ
(1)ZooKeeperйӣҶзҫӨз”ЁдәҺе‘ҪеҗҚжҳ е°„пјҢеҒҡдёәHadoopйӣҶзҫӨзҡ„е‘ҪеҗҚжңҚеҠЎеҷЁпјҢеҹәзЎҖе№іеҸ°еұӮзҡ„д»»еҠЎи°ғеәҰжҺ§еҲ¶еҸ°еҸҜд»ҘйҖҡиҝҮе‘ҪеҗҚжңҚеҠЎеҷЁи®ҝй—®HadoopйӣҶзҫӨдёӯзҡ„NameNodeпјҢеҗҢж—¶е…·еӨҮfailoverзҡ„еҠҹиғҪгҖӮ
(2)HadoopйӣҶзҫӨжҳҜеӨ§ж•°жҚ®е№іеҸ°зҡ„ж ёеҝғпјҢжҳҜеҹәзЎҖе№іеҸ°еұӮзҡ„еҹәзЎҖи®ҫж–ҪгҖӮе®ғжҸҗдҫӣдәҶHDFSгҖҒMapReduceгҖҒJobTrackerе’ҢTaskTrackerзӯүжңҚеҠЎгҖӮзӣ®еүҚжҲ‘们йҮҮз”ЁеҸҢдё»иҠӮзӮ№жЁЎејҸпјҢд»ҘжӯӨйҒҝе…ҚHadoopйӣҶзҫӨзҡ„еҚ•зӮ№ж•…йҡңй—®йўҳгҖӮ
еҹәзЎҖе№іеҸ°еұӮпјҡ
еҹәзЎҖе№іеҸ°еұӮз”ұ3дёӘйғЁеҲҶз»„жҲҗпјҡд»»еҠЎи°ғеәҰжҺ§еҲ¶еҸ°гҖҒHBaseе’ҢHiveгҖӮе®ғдёәз”ЁжҲ·зҪ‘е…іеұӮжҸҗдҫӣеҹәзЎҖжңҚеҠЎи°ғз”ЁжҺҘеҸЈгҖӮ
(1)д»»еҠЎи°ғеәҰжҺ§еҲ¶еҸ°жҳҜMapReduceд»»еҠЎзҡ„и°ғеәҰдёӯеҝғпјҢеҲҶй…Қеҗ„з§Қд»»еҠЎжү§иЎҢзҡ„йЎәеәҸе’Ңдјҳе…Ҳзә§гҖӮз”ЁжҲ·йҖҡиҝҮи°ғеәҰжҺ§еҲ¶еҸ°жҸҗдәӨдҪңдёҡд»»еҠЎпјҢ并йҖҡиҝҮз”ЁжҲ·зҪ‘е…іеұӮзҡ„Hadoopе®ўжҲ·з«Ҝиҝ”еӣһе…¶д»»еҠЎжү§иЎҢзҡ„з»“жһңгҖӮе…¶е…·дҪ“жү§иЎҢжӯҘйӘӨеҰӮдёӢпјҡ
д»»еҠЎи°ғеәҰжҺ§еҲ¶еҸ°жҺҘ收еҲ°з”ЁжҲ·жҸҗдәӨзҡ„дҪңдёҡеҗҺпјҢеҢ№й…Қе…¶и°ғеәҰз®—жі•;
иҜ·жұӮZooKeeperиҝ”еӣһеҸҜз”Ёзҡ„HadoopйӣҶзҫӨзҡ„JobTrackerиҠӮзӮ№ең°еқҖ;
жҸҗдәӨMapReduceдҪңдёҡд»»еҠЎ;
иҪ®иҜўдҪңдёҡд»»еҠЎжҳҜеҗҰе®ҢжҲҗ;
еҰӮжһңдҪңдёҡе®ҢжҲҗеҸ‘йҖҒж¶ҲжҒҜ并и°ғз”Ёеӣһи°ғеҮҪж•°;
继з»ӯжү§иЎҢдёӢдёҖдёӘдҪңдёҡд»»еҠЎгҖӮ
дҪңдёәдёҖдёӘе®Ңе–„зҡ„HadoopйӣҶзҫӨе®һзҺ°пјҢд»»еҠЎи°ғеәҰжҺ§еҲ¶еҸ°е°ҪйҮҸиҮӘе·ұејҖеҸ‘е®һзҺ°пјҢиҝҷж ·зҒөжҙ»жҖ§е’ҢжҺ§еҲ¶еҠӣдјҡжӣҙеҠ зҡ„ејәгҖӮ
(2)HBaseжҳҜеҹәдәҺHadoopзҡ„еҲ—ж•°жҚ®еә“пјҢдёәз”ЁжҲ·жҸҗдҫӣеҹәдәҺиЎЁзҡ„ж•°жҚ®и®ҝй—®жңҚеҠЎгҖӮ
(3)HiveжҳҜеңЁHadoopдёҠзҡ„дёҖдёӘжҹҘиҜўжңҚеҠЎпјҢз”ЁжҲ·йҖҡиҝҮз”ЁжҲ·зҪ‘е…іеұӮзҡ„Hiveе®ўжҲ·з«ҜжҸҗдәӨзұ»SQLзҡ„жҹҘиҜўиҜ·жұӮпјҢ并йҖҡиҝҮе®ўжҲ·з«Ҝзҡ„UIжҹҘзңӢиҝ”еӣһзҡ„жҹҘиҜўз»“жһңпјҢиҜҘжҺҘеҸЈеҸҜжҸҗдҫӣж•°жҚ®йғЁй—ЁеҮҶеҚіж—¶зҡ„ж•°жҚ®жҹҘиҜўз»ҹи®ЎжңҚеҠЎгҖӮ
з”ЁжҲ·зҪ‘е…іеұӮпјҡ
з”ЁжҲ·зҪ‘е…іеұӮз”ЁдәҺдёәз»Ҳз«Ҝе®ўжҲ·жҸҗдҫӣдёӘжҖ§еҢ–зҡ„и°ғз”ЁжҺҘеҸЈд»ҘеҸҠз”ЁжҲ·зҡ„иә«д»Ҫи®ӨиҜҒпјҢжҳҜз”ЁжҲ·е”ҜдёҖеҸҜи§Ғзҡ„еӨ§ж•°жҚ®е№іеҸ°ж“ҚдҪңе…ҘеҸЈгҖӮз»Ҳз«Ҝз”ЁжҲ·еҸӘжңүйҖҡиҝҮз”ЁжҲ·зҪ‘е…іеұӮжҸҗдҫӣзҡ„жҺҘеҸЈжүҚеҸҜд»ҘдёҺеӨ§ж•°жҚ®е№іеҸ°иҝӣиЎҢдәӨдә’гҖӮзӣ®еүҚзҪ‘е…іеұӮжҸҗдҫӣдәҶ3дёӘдёӘжҖ§еҢ–и°ғз”ЁжҺҘеҸЈпјҡ
(1)Hadoopе®ўжҲ·з«ҜжҳҜз”ЁжҲ·жҸҗдәӨMapReduceдҪңдёҡзҡ„е…ҘеҸЈпјҢ并еҸҜд»Һе…¶UIз•ҢйқўжҹҘзңӢиҝ”еӣһзҡ„еӨ„зҗҶз»“жһңгҖӮ
(2)Hiveе®ўжҲ·з«ҜжҳҜз”ЁжҲ·жҸҗдәӨHQLжҹҘиҜўжңҚеҠЎзҡ„е…ҘеҸЈпјҢ并еҸҜд»Һе…¶UIз•ҢйқўжҹҘзңӢжҹҘиҜўз»“жһңгҖӮ
(3)SqoopжҳҜе…ізі»еһӢж•°жҚ®еә“дёҺHBaseжҲ–HiveдәӨдә’ж•°жҚ®зҡ„жҺҘеҸЈгҖӮеҸҜд»Ҙе°Ҷе…ізі»еһӢж•°жҚ®еә“дёӯзҡ„ж•°жҚ®жҢүз…§иҰҒжұӮеҜје…ҘеҲ°HBaseжҲ–HiveдёӯпјҢд»ҘжҸҗдҫӣз”ЁжҲ·еҸҜйҖҡиҝҮHQLиҝӣиЎҢжҹҘиҜўгҖӮеҗҢж—¶HBaseжҲ–HiveжҲ–HDFSд№ҹеҸҜд»Ҙе°Ҷж•°жҚ®еҜјеӣһеҲ°е…ізі»еһӢж•°жҚ®еә“дёӯпјҢд»Ҙдҫҝе…¶д»–зҡ„еҲҶжһҗзі»з»ҹиҝӣиЎҢиҝӣдёҖжӯҘзҡ„ж•°жҚ®еҲҶжһҗгҖӮ
з”ЁжҲ·зҪ‘е…іеұӮеҸҜд»Ҙж №жҚ®е®һйҷ…зҡ„йңҖжұӮж— йҷҗзҡ„жү©еұ•пјҢд»Ҙж»Ўи¶ідёҚеҗҢз”ЁжҲ·зҡ„йңҖжұӮгҖӮ
е®ўжҲ·еә”з”ЁеұӮпјҡ
е®ўжҲ·еә”з”ЁеұӮжҳҜеҗ„з§ҚдёҚеҗҢзҡ„з»Ҳз«Ҝеә”з”ЁзЁӢеәҸпјҢеҸҜд»ҘеҢ…жӢ¬пјҡеҗ„з§Қе…ізі»еһӢж•°жҚ®еә“пјҢжҠҘиЎЁпјҢдәӨжҳ“иЎҢдёәеҲҶжһҗпјҢеҜ№иҙҰеҚ•пјҢжё…з»“з®—зӯүгҖӮ
зӣ®еүҚжҲ‘иғҪжғіеҲ°зҡ„еҸҜд»ҘиҗҪең°еҲ°еӨ§ж•°жҚ®е№іеҸ°зҡ„еә”з”Ёжңүпјҡ
1.иЎҢдёәеҲҶжһҗпјҡе°ҶдәӨжҳ“ж•°жҚ®д»Һе…ізі»еһӢж•°жҚ®еә“еҜје…ҘеҲ°HadoopйӣҶзҫӨдёӯпјҢ然еҗҺж №жҚ®ж•°жҚ®жҢ–жҺҳз®—жі•зј–еҶҷMapReduceдҪңдёҡд»»еҠЎе№¶жҸҗдәӨеҲ°JobTrackerдёӯиҝӣиЎҢеҲҶеёғејҸи®Ўз®—пјҢ然еҗҺе°Ҷе…¶и®Ўз®—з»“жһңж”ҫе…ҘHiveдёӯгҖӮз»Ҳз«Ҝз”ЁжҲ·йҖҡиҝҮHiveе®ўжҲ·з«ҜжҸҗдәӨHQLжҹҘиҜўз»ҹи®ЎеҲҶжһҗзҡ„з»“жһңгҖӮ
2.еҜ№иҙҰеҚ•пјҡе°ҶдәӨжҳ“ж•°жҚ®д»Һе…ізі»еһӢж•°жҚ®еә“еҜје…ҘеҲ°HadoopйӣҶзҫӨпјҢ然еҗҺж №жҚ®дёҡеҠЎи§„еҲҷзј–еҶҷMapReduceдҪңдёҡд»»еҠЎе№¶жҸҗдәӨеҲ°JobTrackerдёӯиҝӣиЎҢеҲҶеёғејҸи®Ўз®—пјҢз»Ҳз«Ҝз”ЁжҲ·йҖҡиҝҮHadoopе®ўжҲ·з«ҜжҸҗеҸ–еҜ№иҙҰеҚ•з»“жһңж–Ү件(Hadoopжң¬иә«д№ҹжҳҜдёҖдёӘеҲҶеёғејҸж–Ү件系з»ҹпјҢе…·еӨҮйҖҡеёёзҡ„ж–Ү件еӯҳеҸ–иғҪеҠӣ)гҖӮ
3.жё…з»“з®—пјҡе°Ҷ银иҒ”ж–Ү件еҜје…ҘHDFSдёӯпјҢ然еҗҺе°Ҷд№ӢеүҚд»Һе…ізі»еһӢж•°жҚ®еә“дёӯеҜје…Ҙзҡ„POSPдәӨжҳ“ж•°жҚ®иҝӣиЎҢMapReduceи®Ўз®—(еҚіеҜ№иҙҰж“ҚдҪң)пјҢ然еҗҺе°Ҷи®Ўз®—з»“жһңиҝһжҺҘеҲ°еҸҰеӨ–дёҖдёӘMapReduceдҪңдёҡдёӯиҝӣиЎҢиҙ№зҺҮеҸҠеҲҶж¶Ұзҡ„и®Ўз®—(еҚіз»“з®—ж“ҚдҪң)пјҢжңҖеҗҺе°Ҷи®Ўз®—з»“жһңеҜјеӣһеҲ°е…ізі»еһӢж•°жҚ®еә“дёӯз”ұз”ЁжҲ·и§ҰеҸ‘е•ҶжҲ·еҲ’ж¬ҫ(еҚіеҲ’ж¬ҫж“ҚдҪң)гҖӮ
йғЁзҪІжһ¶жһ„и®ҫи®Ў
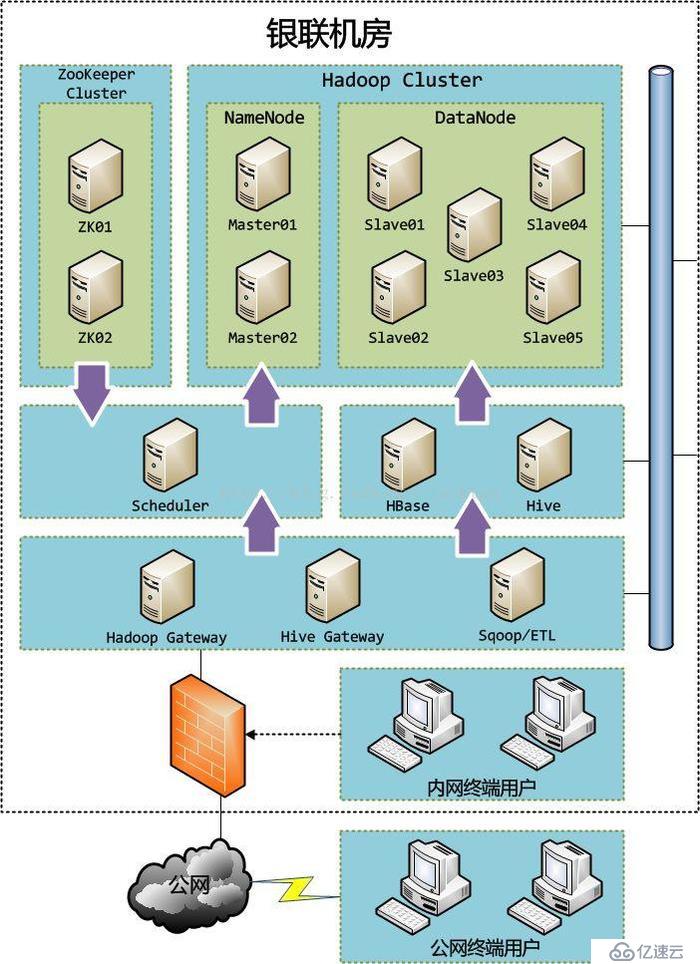
е…ій”®зӮ№иҜҙжҳҺпјҡ
1.зӣ®еүҚж•ҙдёӘHadoopйӣҶзҫӨеқҮж”ҫзҪ®еңЁй“¶иҒ”жңәжҲҝдёӯгҖӮ
2.HadoopйӣҶзҫӨдёӯжңү2дёӘMasterиҠӮзӮ№е’Ң5дёӘSlaveиҠӮзӮ№пјҢ2дёӘMasterиҠӮзӮ№дә’дёәеӨҮд»ҪйҖҡиҝҮZooKeeperеҸҜе®һзҺ°failoverеҠҹиғҪгҖӮжҜҸдёӘMasterиҠӮзӮ№е…ұдә«жүҖжңүзҡ„SlaveиҠӮзӮ№пјҢдҝқиҜҒеҲҶеёғејҸж–Ү件系з»ҹзҡ„еӨҮд»ҪеӯҳеңЁдәҺжүҖжңүзҡ„DataNodeиҠӮзӮ№д№ӢдёӯгҖӮHadoopйӣҶзҫӨдёӯзҡ„жүҖжңүдё»жңәеҝ…йЎ»дҪҝз”ЁеҗҢдёҖзҪ‘ж®ө并ж”ҫзҪ®еңЁеҗҢдёҖжңәжһ¶дёҠпјҢд»ҘжӯӨдҝқиҜҒйӣҶзҫӨзҡ„IOжҖ§иғҪгҖӮ
3.ZooKeeperйӣҶзҫӨиҮіе°‘й…ҚзҪ®2еҸ°дё»жңәпјҢд»ҘйҒҝе…Қе‘ҪеҗҚжңҚеҠЎзҡ„еҚ•иҠӮзӮ№ж•…йҡңгҖӮйҖҡиҝҮZooKeeperжҲ‘们еҸҜд»ҘдёҚеҶҚйңҖиҰҒF5еҒҡиҙҹиҪҪеқҮиЎЎпјҢзӣҙжҺҘз”ұд»»еҠЎи°ғеәҰжҺ§еҲ¶еҸ°йҖҡиҝҮZKе®һзҺ°HadoopеҗҚз§°иҠӮзӮ№зҡ„иҙҹиҪҪеқҮиЎЎи®ҝй—®гҖӮ
4.жүҖжңүжңҚеҠЎеҷЁд№Ӣй—ҙеҝ…йЎ»й…ҚзҪ®дёәж— еҜҶй’ҘSSHи®ҝй—®гҖӮ
5.еӨ–йғЁжҲ–еҶ…йғЁз”ЁжҲ·еқҮйңҖиҰҒйҖҡиҝҮзҪ‘е…іжүҚиғҪи®ҝй—®HadoopйӣҶзҫӨпјҢзҪ‘е…іеңЁз»ҸиҝҮдёҖдәӣиә«д»Ҫи®ӨиҜҒд№ӢеҗҺжүҚиғҪжҸҗдҫӣжңҚеҠЎпјҢд»ҘжӯӨдҝқиҜҒHadoopйӣҶзҫӨзҡ„и®ҝй—®е®үе…ЁгҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ