您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
爬取链家二手房源信息
import requests
import re
from bs4 import BeautifulSoup
import csv
url = ['https://cq.lianjia.com/ershoufang/']
for i in range(2,101):
url.append('https://cq.lianjia.com/ershoufang/pg%s/'%(str(i)))
# 模拟谷歌浏览器
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}
for u in url:
r = requests.get(u,headers=headers)
soup = BeautifulSoup(r.text,'lxml').find_all('li', class_='clear LOGCLICKDATA')
for i in soup:
ns = i.select('div[class="positionInfo"]')[0].get_text()
region = ns.split('-')[1].replace(' ','').encode('gbk')
rem = ns.split('-')[0].replace(' ','').encode('gbk')
ns = i.select('div[class="houseInfo"]')[0].get_text()
xiaoqu_name = ns.split('|')[0].replace(' ','').encode('gbk')
huxing = ns.split('|')[1].replace(' ','').encode('gbk')
pingfang = ns.split('|')[2].replace(' ','').encode('gbk')
chaoxiang = ns.split('|')[3].replace(' ','').encode('gbk')
zhuangxiu = ns.split('|')[4].replace(' ','').encode('gbk')
danjia = re.findall("\d+",i.select('div[class="unitPrice"]')[0].string)[0]
zongjia = i.select('div[class="totalPrice"]')[0].get_text().encode('gbk')
out=open("/data/data.csv",'a')
csv_write=csv.writer(out)
data = [region,xiaoqu_name,rem,huxing,pingfang,chaoxiang,zhuangxiu,danjia,zongjia]
csv_write.writerow(data)
out.close()数据结果
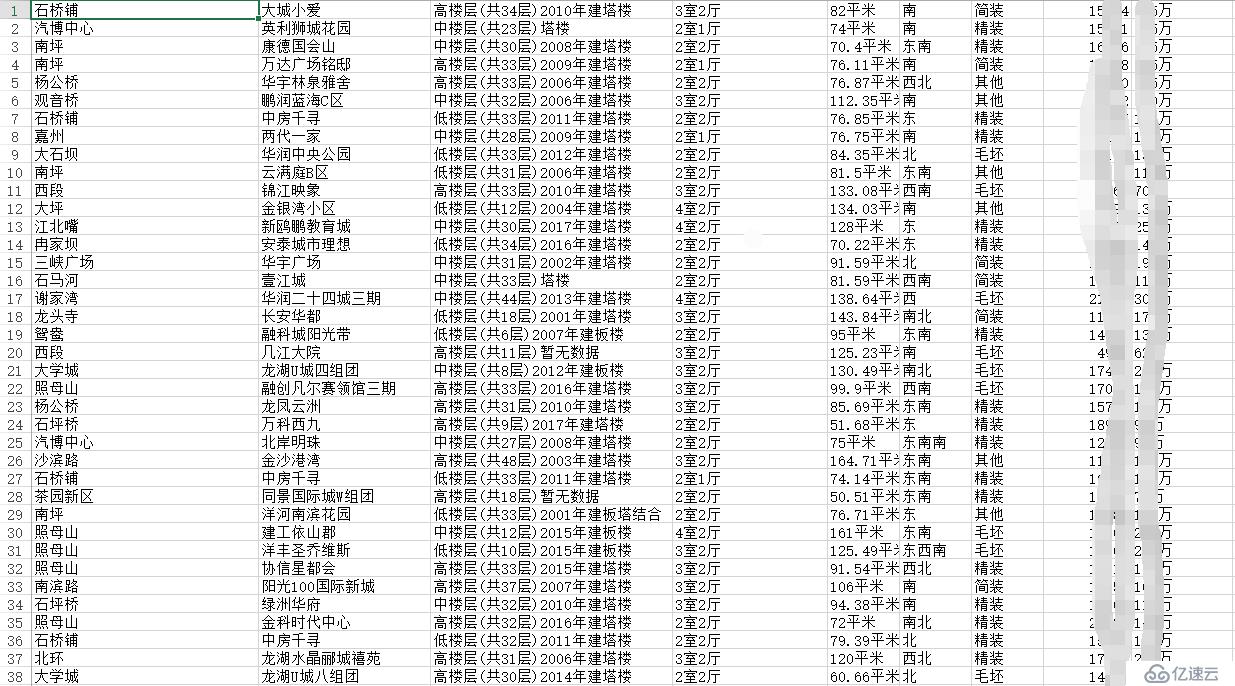
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。