您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章将为大家详细讲解有关大数据机器学习中的过拟合与解决办法,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
什么是过拟合
对于机器学习项目而言,过拟合(overfitting)这个问题一般都会遇到。什么是过拟合呢?
维基百科:
在统计学中,过拟合现象是指在拟合一个统计模型时,使用过多参数。对比于可获取的数据总量来说,一个荒谬的模型只要足够复杂,是可以完美地适应数据。过拟合一般可以视为违反奥卡姆剃刀原则。当可选择的参数的自由度超过数据所包含信息内容时,这会导致最后(拟合后)模型使用任意的参数,这会减少或破坏模型一般化的能力更甚于适应数据。过拟合的可能性不只取决于参数个数和数据,也跟模型架构与数据的一致性有关。此外对比于数据中预期的噪声或错误数量,跟模型错误的数量也有关。
过拟合现象的观念对机器学习也是很重要的。通常一个学习算法是借由训练示例来训练的。亦即预期结果的示例是可知的。而学习者则被认为须达到可以预测出其它示例的正确的结果,因此,应适用于一般化的情况而非只是训练时所使用的现有数据(根据它的归纳偏向)。然而,学习者却会去适应训练数据中太特化但又随机的特征,特别是在当学习过程太久或示例太少时。在过拟合的过程中,当预测训练示例结果的表现增加时,应用在未知数据的表现则变更差。
相对于过拟合是指,使用过多参数,以致太适应数据而非一般情况,另一种常见的现象是使用太少参数,以致于不适应数据,这则称为欠拟合(underfitting),或称:拟合不足现象。
这里不展开说明欠拟合现象,后续补上。总的来说,是学习得过头了,死记硬背的那种学习,对于训练数据预测得非常准确,但当遇到新的问题时候,泛化能力不行,无法作出正确的预测。
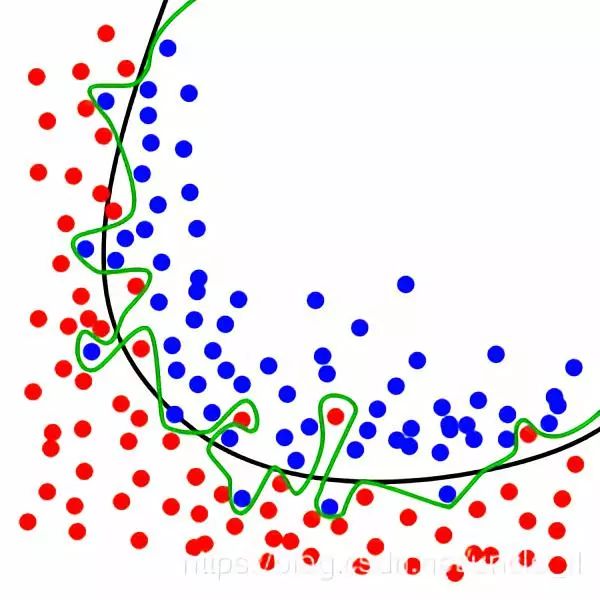
绿线代表过拟合模型,黑线代表正则化模型。虽然绿线完美的匹配训练数据,但太过依赖,并且与黑线相比,对于新的测试数据上具有更高的错误率。
知乎
知乎上有个帖子:用简单易懂的语言描述「过拟合 overfitting」?
过拟合其实就是一种机器学习没找到正确的规律情况,所以要搞懂什么是过拟合首先得搞懂为什么机器学习能找出正确规律。
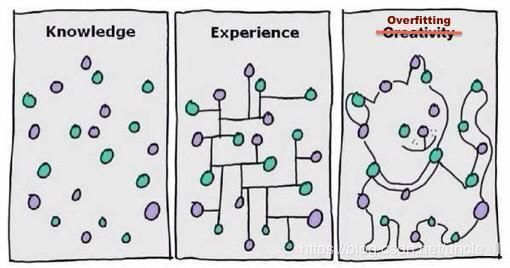
具体情况
实际中遇到的问题,训练和测试曲线如下:
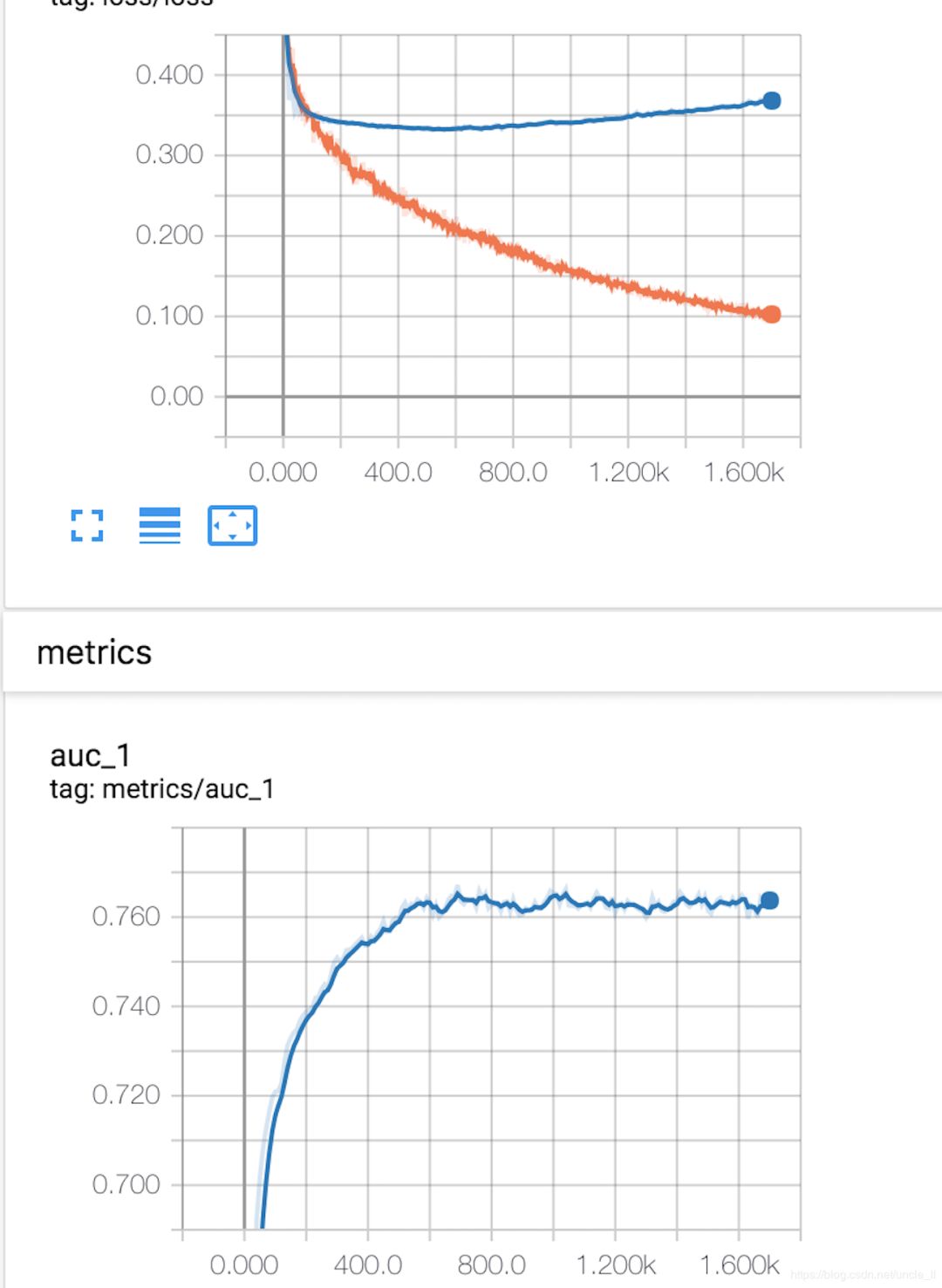
可以看到训练损失一直下降,但测试损失先下降后上升。
解决办法
在统计和机器学习中,为了避免过拟合现象,须要使用额外的技巧,以指出何时会有更多训练而没有导致更好的一般化。具体有以下几种方法:
获取更多数据;
使用合适的模型;
结合多种模型;
贝叶斯方法;

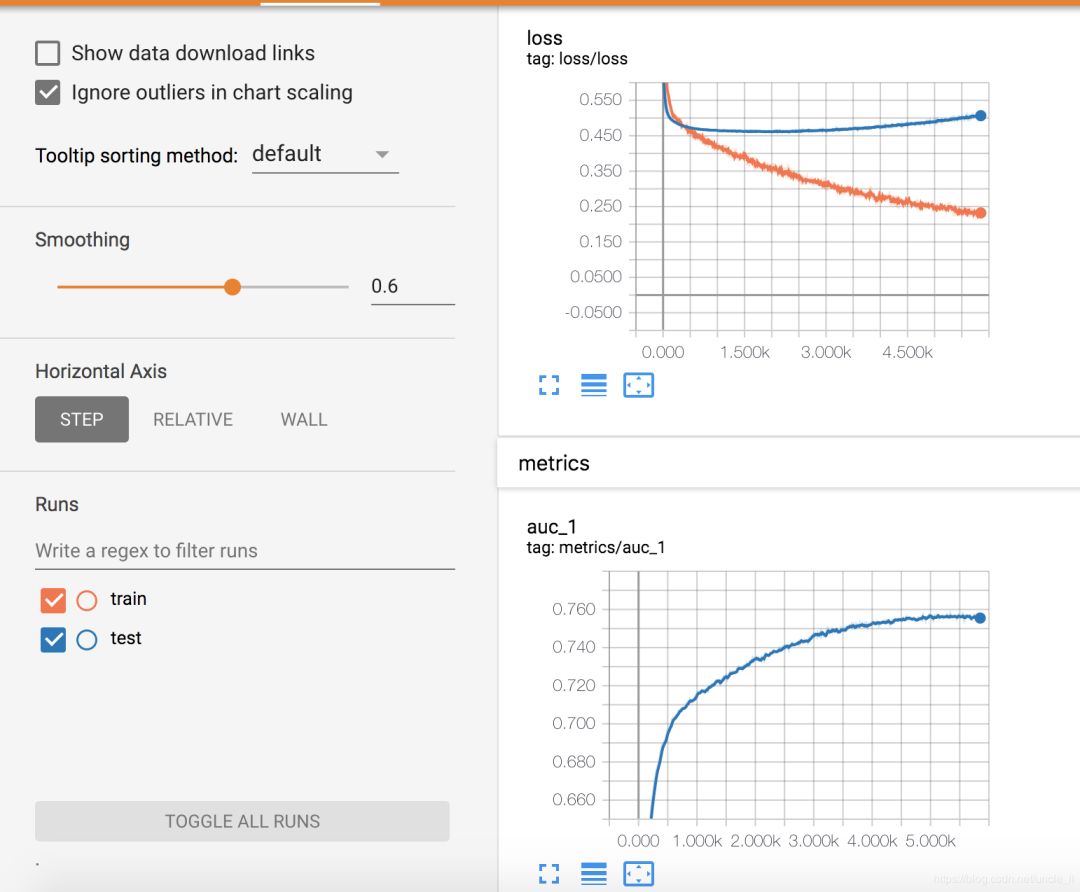
增大训练数据后,加入earlystopping,曲线稍微好点。
关于大数据机器学习中的过拟合与解决办法就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。