жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
еҰӮдҪ•дҪҝз”ЁPythonз»ҹи®Ў180зҸӯQQзҫӨиҒҠж–Үжң¬еҸҜи§ҶеҢ–еҲҶжһҗпјҢй’ҲеҜ№иҝҷдёӘй—®йўҳпјҢиҝҷзҜҮж–Үз« иҜҰз»Ҷд»Ӣз»ҚдәҶзӣёеҜ№еә”зҡ„еҲҶжһҗе’Ңи§Јзӯ”пјҢеёҢжңӣеҸҜд»Ҙеё®еҠ©жӣҙеӨҡжғіи§ЈеҶіиҝҷдёӘй—®йўҳзҡ„е°ҸдјҷдјҙжүҫеҲ°жӣҙз®ҖеҚ•жҳ“иЎҢзҡ„ж–№жі•гҖӮ




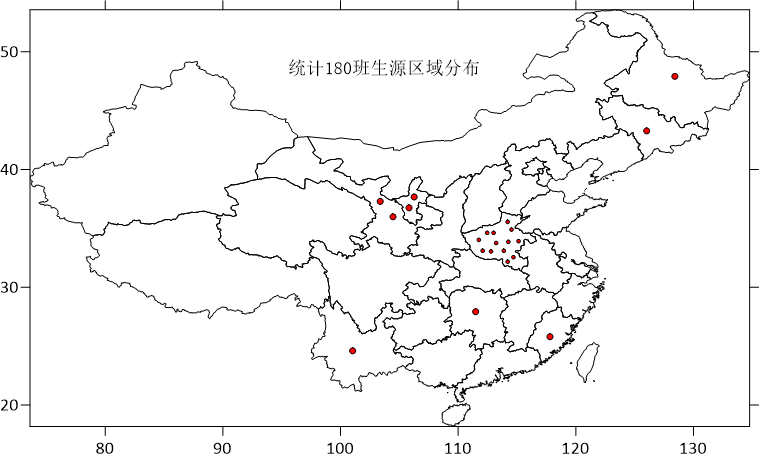
иҪ¬зңје°ұеҲ°еӨ§еӣӣе№ҙзә§пјҢз•ҷеңЁеӯҰж Ўзҡ„ж—¶ж—ҘдёҚеӨҡдәҶ
еҲҶдёәзҪ‘з«ҷиҜ·жұӮгҖҒдјӘиЈ…гҖҒи§ЈжһҗгҖҒеӯҳеӮЁеӣӣдёӘиҝҮзЁӢ
жӣҙдёәиҜҰз»Ҷзҡ„зҲ¬еҸ–жөҒзЁӢеҰӮдёӢжүҖзӨә
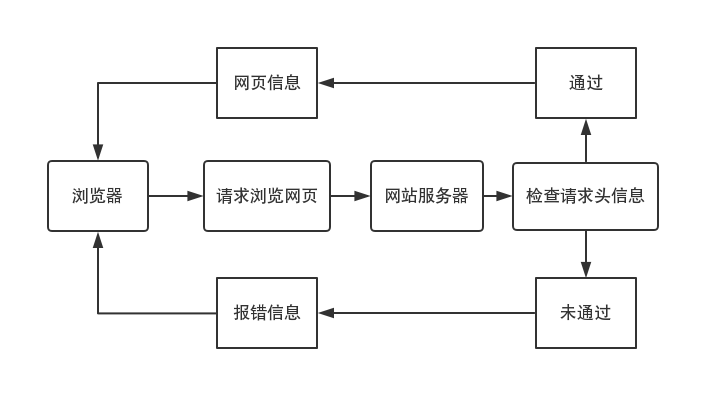
йңҖиҰҒж·»еҠ дёҖдәӣ规еҲҷ
然иҖҢпјҢжң¬ж–Үзҡ„ж–Үжң¬ж•°жҚ®
жҳҜжҲ‘д»ҺQQз”өи„‘з«ҜеҗҺеҸ°еҜјеҮәзҡ„
зӣ®еүҚеҜ№дәҺзҪ‘з»ңзҲ¬иҷ«зҡ„еӯҰд№
жҲ‘еҸӘдјҡиұҶз“ЈеҪұиҜ„гҖҒд№ҰиҜ„гҖҒж·ҳе®қд»·ж јзҡ„зҲ¬еҸ–
зӯүе…·дҪ“еӯҰд№ жҲҗзҶҹдәҶ
еҸ‘дёҖзҜҮзҪ‘з»ңзҲ¬иҷ«зҡ„жҺЁж–Ү
敬иҜ·жңҹеҫ…
еҜјеҮәж–Үжң¬ж•°жҚ®еҗҺ
зј–еҶҷзЁӢеәҸпјҢи°ғиҜ•д»Јз ҒпјҢеҒҡеҸҜи§ҶеҢ–еҲҶжһҗ
иҜҰз»Ҷд»Јз ҒеҰӮдёӢжүҖзӨә
#QQзҫӨиҒҠж•°жҚ®еҲҶжһҗд»Јз Ғimport reimport datetimeimport seaborn as snsimport matplotlib.pyplot as pltimport jiebafrom wordcloud import WordCloud, STOPWORDSfrom scipy.misc import imread# ж—Ҙжңҹdef get_date(data): # ж—Ҙжңҹ dates = re.findall(r'\d{4}-\d{2}-\d{2}', data) # еӨ© days = [date[-2:] for date in dates] plt.subplot(221) sns.countplot(days) plt.title('Days') # е‘ЁеҮ weekdays = [datetime.date(int(date[:4]), int(date[5:7]), int(date[-2:])).isocalendar()[-1] for date in dates] plt.subplot(222) sns.countplot(weekdays) plt.title('WeekDays')# ж—¶й—ҙdef get_time(data): times = re.findall(r'\d{2}:\d{2}:\d{2}', data) # е°Ҹж—¶ hours = [time[:2] for time in times] plt.subplot(223) sns.countplot(hours, order=['06', '07', '08', '09', '10', '11', '12', '13', '14', '15', '16', '17', '18', '19', '20', '21', '22', '23', '00', '01', '02', '03', '04', '05']) plt.title('Hours')д»Јз Ғжј”зӨәпјҡ# иҜҚдә‘def get_wordclound(text_data): word_list = [" ".join(jieba.cut(sentence)) for sentence in text_data] new_text = ' '.join(word_list) pic_path = 'QQ.jpg' mang_mask = imread(pic_path) plt.subplot(224) wordcloud = WordCloud(background_color="white", font_path='/home/shen/Downloads/fonts/msyh.ttc', mask=mang_mask, stopwords=STOPWORDS).generate(new_text) plt.imshow(wordcloud) plt.axis("off")# еҶ…е®№еҸҠиҜҚдә‘def get_content(data): pa = re.compile(r'\d{4}-\d{2}-\d{2}.*?\(\d+\)\n(.*?)\n\n', re.DOTALL) content = re.findall(pa, data) get_wordclound(content)def run(): filename = 'ж–°е»әж–Үжң¬ж–ҮжЎЈ.txt' with open(filename) as f: data = f.read() get_date(data) get_time(data) get_content(data) plt.show()
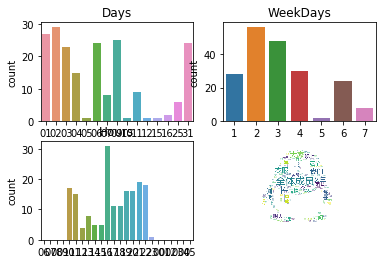
еҒҡеҮәж–Үжң¬еҸҜи§ҶиҜқеӣҫеҗҺпјҢеҸҜд»Ҙеҫ—еҮәеҰӮдёӢз»“и®ә
еңЁ2018е№ҙ1жңҲ1ж—Ҙ~1жңҲ31ж—Ҙз»ҹи®Ў180зҸӯзҫӨиҒҠдёӯ
1жңҲ2ж—ҘиҝҷдёҖеӨ©зҫӨиҒҠж¬Ўж•°жңҖеӨҡ
жҜҸе‘Ёзҡ„жҳҹжңҹдәҢзҫӨиҒҠж¬Ўж•°еҒҡеӨҡ
жҜҸеӨ©зҡ„16ж—¶зҫӨиҒҠж¬Ўж•°жңҖеӨҡ
еҒҡиҜҚдә‘еӣҫеҸ‘зҺ°
вҖңе…ЁдҪ“жҲҗе‘ҳвҖқеҮәзҺ°зҡ„иҜҚйў‘жңҖеӨҡ
е…ідәҺеҰӮдҪ•дҪҝз”ЁPythonз»ҹи®Ў180зҸӯQQзҫӨиҒҠж–Үжң¬еҸҜи§ҶеҢ–еҲҶжһҗй—®йўҳзҡ„и§Јзӯ”е°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢеҰӮжһңдҪ иҝҳжңүеҫҲеӨҡз–‘жғ‘жІЎжңүи§ЈејҖпјҢеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“дәҶи§ЈжӣҙеӨҡзӣёе…ізҹҘиҜҶгҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ