您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本篇内容主要讲解“怎么用Docker部署Scrapy”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“怎么用Docker部署Scrapy”吧!
1. 部署步骤
1.1 上传本地scrapy爬虫代码除了settings外到git 服务器
1.2 编写dockerfile文件,把settings和requirements.txt 也拷贝到image里,一起打包成一个image
dockerfile内容:
from ubuntu run apt-get update run apt-get install -y git run apt-get install -y nano run apt-get install -y redis-server run apt-get -y dist-upgrade run apt-get install -y openssh-server run apt-get install -y python3.5 python3-pip run apt-get install -y zlib1g-dev libffi-dev libssl-dev run apt-get install -y libxml2-dev libxslt1-dev run mkdir /code workdir /code add ./requirements.txt /code/ add ./settings.py /code/ run mkdir /code/myspider run pip3 install -r requirements.txt volume [ "/data" ]
requirements.txt 内容:
beautifulsoup4 scrapy setuptools scrapy_redis redis sqlalchemy pymysql pillow
整个目录结构:
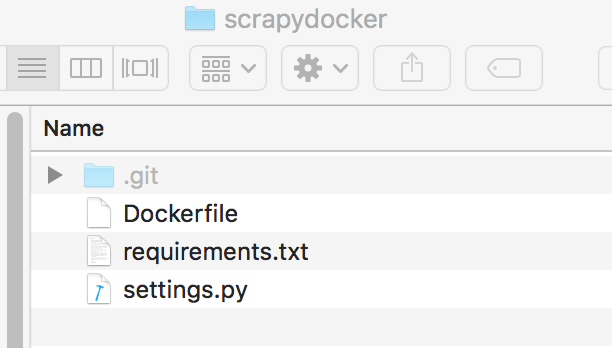
docker build -t fox6419/scrapy:scrapytag .
fox6419是用户名,scrapytag是tag
成功后,执行docker images可以在本地看到image
1.3 打包的image 上传到docker hub中
docker push username/repository:tag
push的命令格式是这样的,我这边就是:
docker push fox6419/scrapy:scrapytag
1.4 在digitalocean这种主机商创建带docker应用的ubuntu 16.04版本
1.5 登陆docker,拉下1.3的image,然后run起来
docker run -it fox6419/scrapy:scrapytag /bin/bash
1.6 命令进去后,git clone 1.1中的爬虫,然后复制images里的settings到爬虫目录,然后执行scrapy crawl xxx即可
到此,相信大家对“怎么用Docker部署Scrapy”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。