您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
如何读懂Ka及Ks,相信很多没有经验的人对此束手无策,为此本文总结了问题出现的原因和解决方法,通过这篇文章希望你能解决这个问题。
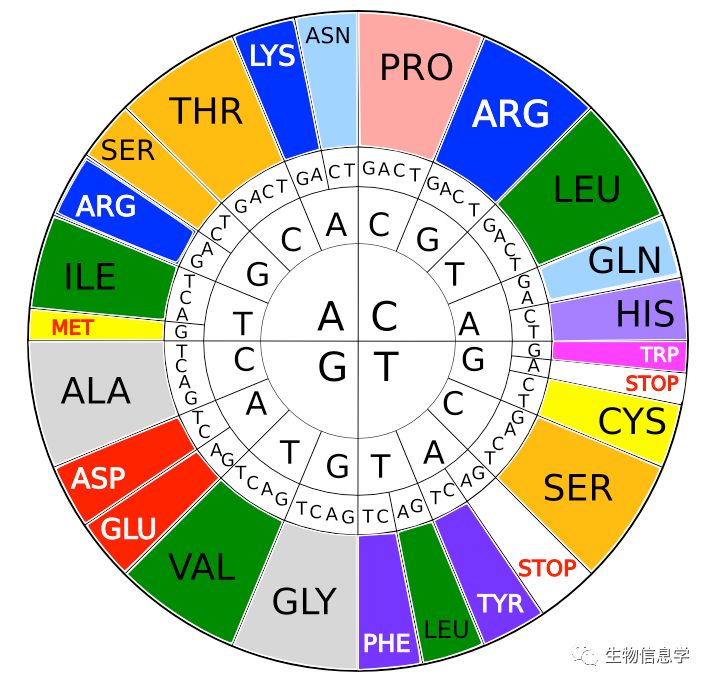
The ratio of the number of nonsynonymous substitutions per nonsynonymous site (Ka) to the number of synonymous substitutions per synonymous site (Ks)。
Ka/Ks表示非同义替换位点替换次数(Ka)与同义替换位点替换次数(Ks)的比值。
首先,假如你正在比对两个物种的一对同源基因序列。进化的力量通常使得这两条DNA序列有些差异。我们都知道密码子有简并性的特性,因此有的差异会导致翻译出不同的氨基酸(非同义突变,nonsynonymous changes),有的因为同义密码子的存在产生了相同的氨基酸(同义突变,synonymous changes)。统计出这两条序列直接发生的非同义与同义替换的所有次数,我们就可以观察到序列的变化情况了。接下来就是对数据做些调整了。
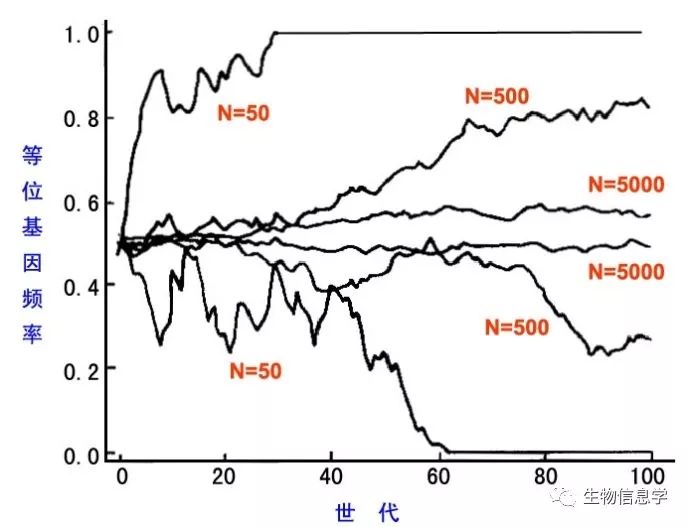
由于密码子的简并性,我们的序列中大概只有25%是同义突变的。假设基因并没有受到选择,即发生的是中性进化,基因的任何一个突变从稀有变成共有的机会是相同的,并不受其它外界因素的影响。大多数的突变的消失都是随机的,但是我们假设种群大小是N,一个等位基因刚刚通过突变而出现在种群中,那么它在2N个等位基因的种群中固定的可能性是p=1/(2N)(详见遗传漂变)。
在上面的例子中,每一个突变被固定的概率是一样的,那么发生非同义突变的可能性与发生同义突变的可能性也是一样的。所以,在中性进化的背景下,如果我们对密码子的简并性进行矫正后,就应该有一种方法得出非同义突变的次数等于同义突变的次数,即Ka/Ks=1。因为Ks可以告诉我们进化的背景速度,因此偏离1的比例将告诉我们作用于蛋白上面的选择情况。
很遗憾,并不是的。举个栗子,对于编码天冬氨酸和赖氨酸的密码子:他们都起始于AA,赖氨酸结束于A或者G,天冬氨酸结束于T或者C。所以如果C突变成T的机率大于C突变成A或G(通常就是这样子滴),那么第三个位置上的突变更可能是同义突变。因此许多计算Ka/Ks的方法,考虑到这部分因素,使用了的不同的转换模型,也会使得最后的Ka/Ks值有些不同。
好问题!由于序列随着时间会不断的变化,因此我们观察到的变化次数可能小于实际发生的变化次数。如果一个碱基最开始是A,在一个分支中,他被替换成了C,然后又被替换成了T,然后在我们的比对结果上面只能看到一次替换。同样,可能我们看到的完全比对上位点,也可能已经替换了很多次,只不过最后变成了原来的碱基。幸运的是,实际的分歧程度可以从观察到的总的分歧程度来估算。然而,没有人能完美的解决这个问题:随着变化数量的增加,来自于对齐序列的那部分信息将会减少,并逐渐接近于饱和,在这种情况下数据是没用的,得到的结果也是不准确的。因此计算Ka/Ks时,遗传距离较近的序列往往得到的结果更准确。
Well,你现在已经有了表征蛋白进化次数的值(Ka)。假设进化选择并不出现在silent site(发生同义突变可能性很低的位点),从进化的中性理论来看,Ks值应该与基因的突变率成正比。这是因为,假设μ是每代的中性突变率,虽然新的中性突变进入固定的概率是1 / 2N,但是它们以2Nμ的速率每代产生,因此中性进化的速率应该是2Nμ/2N = μ,这个值就是Ka所表征的。如果这样去计算,那么Ka与Ks的比值也告诉了我们基因进化的方式。从图中,我们发现通常Ka是小于Ks。因为改变蛋白质的突变在两个物种之间的差异远小于沉默的物种。也就是说,在大多数的情况下,选择消除了有害突变,并保持蛋白质不变(即纯化选择,purifyingselection)。
在少数情况下(通常当免疫系统基因与寄生虫共同进化时),我们发现Ka远大于Ks(即Ka / Ks >> 1)。这是有力的证据表明选择已经改变了蛋白质(正向选择,positive selection)。
没那么简单。中性进化是一种不可排除的可能性。但是,如果该基因的一部分(例如一个蛋白质结构域)处于正选择状态,而其他部分处于净化选择范围内,那么你也会得到Ka/Ks等于1的结果。不过,也有很多方法可以容许进行多序列比对之后,通过考虑物种的系统发育,计算出序列中每个codon的Ka/Ks(位点模型)。另外,可以检测基因在一个谱系中是否存在不同的比率,这表明该物种特有的事情发生了(分支模型)。这些分析方法能揭示出更多的正向选择,提供了更多的分析方向。
现在已经有很多种不同的方法供我们选择,最常用最方便的是MEGA。当然老牌的杨子恒老师的PAML也同样十分优秀。Hyphy软件除了提供全局的Ka/Ks计算外,也支持分支位点等各种模型,不过我比较喜欢Hyphy的一点是可以多线程计算。这些软件的使用方法我在之后的推送中出。
看完上述内容,你们掌握如何读懂Ka及Ks的方法了吗?如果还想学到更多技能或想了解更多相关内容,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。