您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章将为大家详细讲解有关如何进行损失函数losses分析,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
一般来说,监督学习的目标函数由损失函数和正则化项组成。(Objective = Loss + Regularization)
对于keras模型,目标函数中的正则化项一般在各层中指定,例如使用Dense的 kernel_regularizer 和 bias_regularizer等参数指定权重使用l1或者l2正则化项,此外还可以用kernel_constraint 和 bias_constraint等参数约束权重的取值范围,这也是一种正则化手段。
损失函数在模型编译时候指定。对于回归模型,通常使用的损失函数是平方损失函数 mean_squared_error。
对于二分类模型,通常使用的是二元交叉熵损失函数 binary_crossentropy。
对于多分类模型,如果label是类别序号编码的,则使用类别交叉熵损失函数 categorical_crossentropy。如果label进行了one-hot编码,则需要使用稀疏类别交叉熵损失函数 sparse_categorical_crossentropy。
如果有需要,也可以自定义损失函数,自定义损失函数需要接收两个张量y_true,y_pred作为输入参数,并输出一个标量作为损失函数值。
对于keras模型,目标函数中的正则化项一般在各层中指定,损失函数在模型编译时候指定。
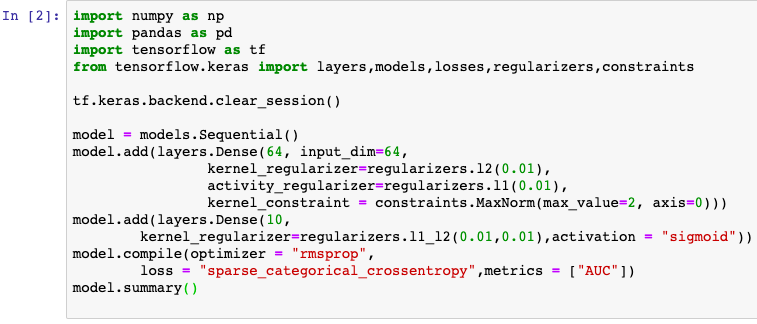

内置的损失函数一般有类的实现和函数的实现两种形式。
如:CategoricalCrossentropy 和 categorical_crossentropy 都是类别交叉熵损失函数,前者是类的实现形式,后者是函数的实现形式。
常用的一些内置损失函数说明如下。
mean_squared_error(平方差误差损失,用于回归,简写为 mse, 类实现形式为 MeanSquaredError 和 MSE)
mean_absolute_error (绝对值误差损失,用于回归,简写为 mae, 类实现形式为 MeanAbsoluteError 和 MAE)
mean_absolute_percentage_error (平均百分比误差损失,用于回归,简写为 mape, 类实现形式为 MeanAbsolutePercentageError 和 MAPE)
Huber(Huber损失,只有类实现形式,用于回归,介于mse和mae之间,对异常值比较鲁棒,相对mse有一定的优势)
binary_crossentropy(二元交叉熵,用于二分类,类实现形式为 BinaryCrossentropy)
categorical_crossentropy(类别交叉熵,用于多分类,要求label为onehot编码,类实现形式为 CategoricalCrossentropy)
sparse_categorical_crossentropy(稀疏类别交叉熵,用于多分类,要求label为序号编码形式,类实现形式为 SparseCategoricalCrossentropy)
hinge(合页损失函数,用于二分类,最著名的应用是作为支持向量机SVM的损失函数,类实现形式为 Hinge)
kld(相对熵损失,也叫KL散度,常用于最大期望算法EM的损失函数,两个概率分布差异的一种信息度量。类实现形式为 KLDivergence 或 KLD)
cosine_similarity(余弦相似度,可用于多分类,类实现形式为 CosineSimilarity)
自定义损失函数接收两个张量y_true,y_pred作为输入参数,并输出一个标量作为损失函数值。
也可以对tf.keras.losses.Loss进行子类化,重写call方法实现损失的计算逻辑,从而得到损失函数的类的实现。
下面是一个Focal Loss的自定义实现示范。Focal Loss是一种对binary_crossentropy的改进损失函数形式。
在类别不平衡和存在难以训练样本的情形下相对于二元交叉熵能够取得更好的效果。
详见《如何评价Kaiming的Focal Loss for Dense Object Detection?》
https://www.zhihu.com/question/63581984

关于如何进行损失函数losses分析就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。