您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
今天就跟大家聊聊有关数据清洗常用的2个小trick分别是什么,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。
str.split 和 str.cat因为以上两个方法,直接按列操作,所以省掉一层 for 循环,下面直接看例子。
df = pd.DataFrame({'names':["Geordi La Forge", "Deanna Troi", "Jack"],'IDs':[1,2,3]})
df

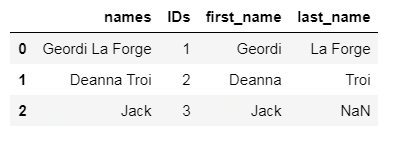
对 names 列,按照第一个空格分割为两列:
df["first_name"] = df["names"].str.split(n = 1).str[0]
df["last_name"] = df["names"].str.split(n = 1).str[1]
df
结果如下:
分割列搞定,接下来再合并回去,使用 cat 方法:
df["names_copy"] = df["first_name"].str.cat(df["last_name"], sep = " ")
df
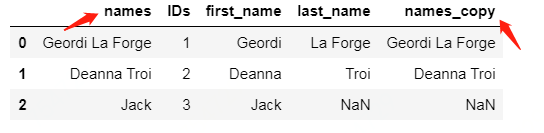
合并两列得到一个新列 names_copy 搞定!
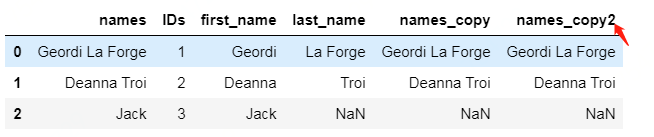
还有别的合并方法吗,直接使用 + 连接字符串:
df["names_copy2"] = df["first_name"] + " "+ df["last_name"]
df
效果是一样的:
有特征上百个,根据多个特征筛选 DataFrame 时,如果这么做,可读性不太友好:
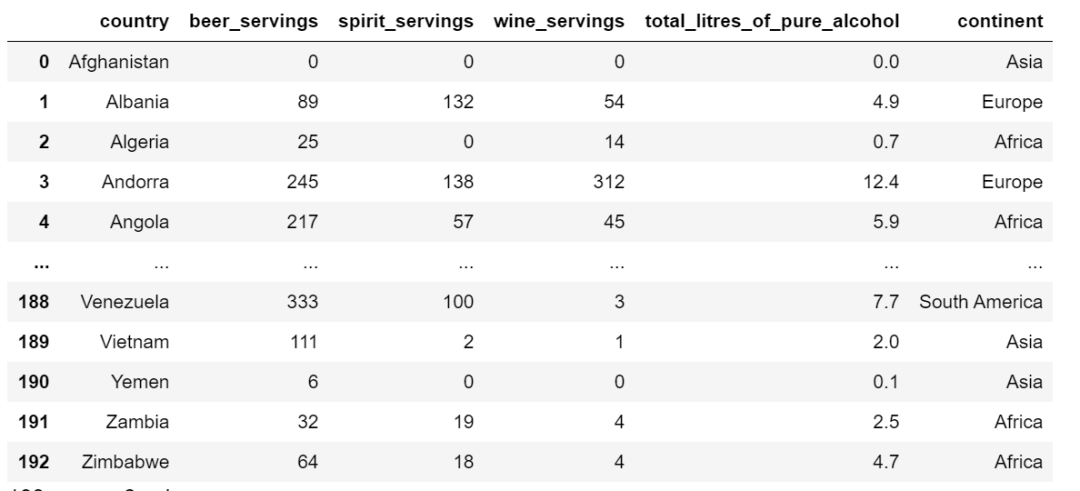
df[(df["continent"] == "Europe") & (df["beer_servings"] > 150) & (df["wine_servings"] > 50) & (df["spirit_servings"] < 60)]
连续多个筛选条件写到一行里。
cr1 = df["continent"] == "Europe"
cr2 = df["beer_servings"] > 150
cr3 = df["wine_servings"] > 50
cr4 = df["spirit_servings"] < 60
df[cr1 & cr2 & cr3 & cr4]
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。